Översikt över indexering i Azure Cosmos DB
GÄLLER FÖR:![]() Nosql
Nosql![]() Mongodb
Mongodb![]() Cassandra
Cassandra![]() Gremlin
Gremlin![]() Tabell
Tabell
Azure Cosmos DB är en schemaagnostisk databas som gör att du kan iterera i ditt program utan att behöva hantera schema- eller indexhantering. Som standard indexerar Azure Cosmos DB automatiskt varje egenskap för alla objekt i containern utan att behöva definiera något schema eller konfigurera sekundära index.
Målet med den här artikeln är att förklara hur Azure Cosmos DB indexerar data samt hur det använder index för att förbättra frågeprestanda. Vi rekommenderar att du går igenom det här avsnittet innan du utforskar hur du anpassar indexeringsprinciper.
Från objekt till träd
Varje gång ett objekt lagras i en container projiceras dess innehåll som ett JSON-dokument och konverteras sedan till en trädrepresentation. Den här konverteringen innebär att varje egenskap för objektet representeras som en nod i ett träd. En pseudorotnod skapas som överordnad till alla egenskaper på första nivån för objektet. Lövnoderna innehåller de faktiska skalärvärdena som transporteras av ett objekt.
Tänk till exempel på det här objektet:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
Det här trädet representerar JSON-exempelobjektet:
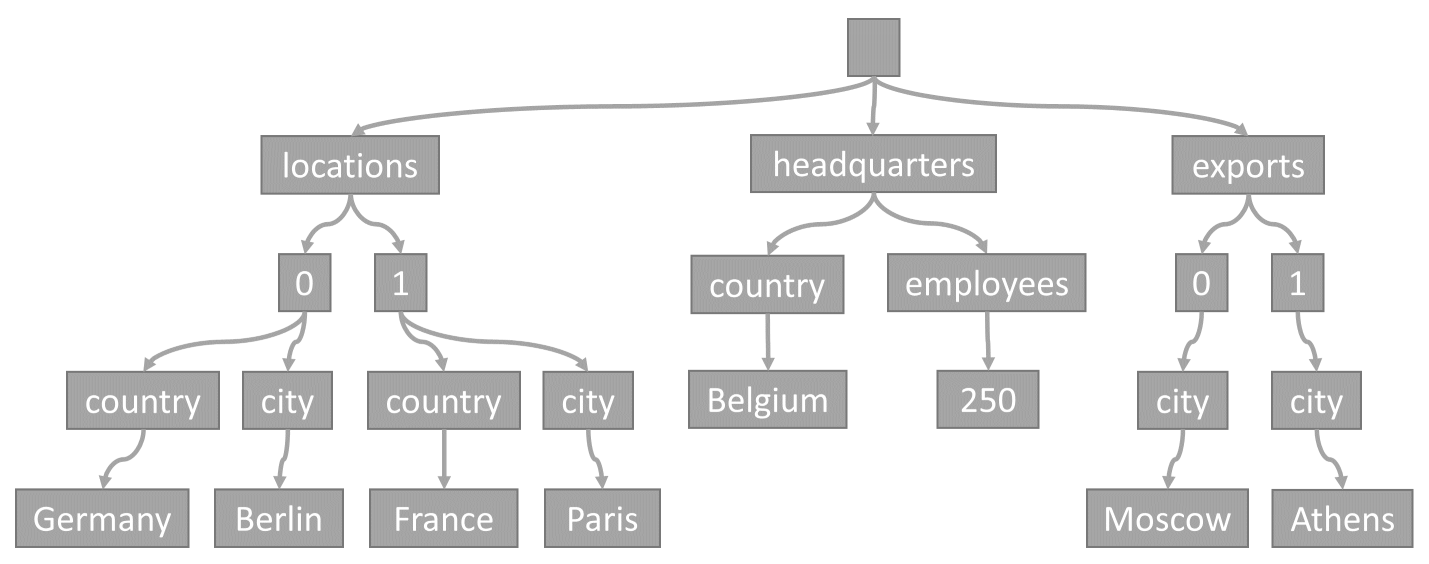
Observera hur matriser kodas i trädet: varje post i en matris får en mellanliggande nod märkt med indexet för den posten i matrisen (0, 1 osv.).
Från träd till egenskapsvägar
Anledningen till att Azure Cosmos DB omvandlar objekt till träd är att det gör att systemet kan referera till egenskaper med hjälp av deras sökvägar i dessa träd. För att hämta sökvägen för en egenskap kan vi bläddra i trädet från rotnoden till den egenskapen och sammanfoga etiketterna för varje bläddrade nod.
Här är sökvägarna för varje egenskap från exempelobjektet som beskrevs tidigare:
/locations/0/country: "Tyskland"/locations/0/city: "Berlin"/locations/1/country: "Frankrike"/locations/1/city: "Paris"/headquarters/country: "Belgien"/headquarters/employees: 250/exports/0/city: "Moskva"/exports/1/city: "Aten"
Azure Cosmos DB indexerar effektivt varje egenskaps sökväg och dess motsvarande värde när ett objekt skrivs.
Typer av index
Azure Cosmos DB stöder för närvarande tre typer av index. Du kan konfigurera dessa indextyper när du definierar indexeringsprincipen.
Intervallindex
Intervallindex baseras på en ordnad trädliknande struktur. Intervallindextypen används för:
Likhetsfrågor:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")Likhetsmatchning för ett matriselement
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Intervallfrågor:
SELECT * FROM container c WHERE c.property > 'value'Anteckning
(fungerar för
>,<,>=,<=,!=)Kontrollerar förekomsten av en egenskap:
SELECT * FROM c WHERE IS_DEFINED(c.property)Strängsystemfunktioner:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BYFrågor:SELECT * FROM container c ORDER BY c.propertyJOINFrågor:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
Intervallindex kan användas på skalära värden (sträng eller tal). Standardprincipen för indexering för nyligen skapade containrar framtvingar intervallindex för strängar eller nummer. Information om hur du konfigurerar intervallindex finns i Exempel på intervallindexeringsprincip
Anteckning
En ORDER BY sats som beställer efter en enskild egenskap behöver alltid ett intervallindex och misslyckas om sökvägen som den refererar till inte har något. På samma sätt behöver en ORDER BY fråga som beställer efter flera egenskaper alltid ett sammansatt index.
Rumsligt index
Rumsliga index möjliggör effektiva frågor om geospatiala objekt som - punkter, linjer, polygoner och multipolygon. De här frågorna använder nyckelorden ST_DISTANCE, ST_WITHIN och ST_INTERSECTS. Följande är några exempel som använder rumslig indextyp:
Geospatiala avståndsfrågor:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Geospatial i frågor:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Geospatiala intersektera frågor:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
Rumsliga index kan användas på korrekt formaterade GeoJSON-objekt . Points, LineStrings, Polygons och MultiPolygons stöds för närvarande. Information om hur du konfigurerar rumsliga index finns i Exempel på rumslig indexeringsprincip
Sammansatta index
Sammansatta index ökar effektiviteten när du utför åtgärder på flera fält. Den sammansatta indextypen används för:
ORDER BYfrågor om flera egenskaper:SELECT * FROM container c ORDER BY c.property1, c.property2Frågor med ett filter och
ORDER BY. Dessa frågor kan använda ett sammansatt index om filteregenskapen läggs till iORDER BY-satsen.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2Frågor med ett filter på två eller flera egenskaper där minst en egenskap är ett likhetsfilter
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
Så länge ett filterpredikat använder en av indextypen utvärderar frågemotorn det först innan resten genomsöks. Om du till exempel har en SQL-fråga, till exempel SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
Ovanstående fråga filtrerar först efter poster där firstName = "Andrew" med hjälp av indexet. Den skickar sedan alla firstName = "Andrew"-poster via en efterföljande pipeline för att utvärdera CONTAINS-filterpredikatet.
Du kan påskynda frågor och undvika fullständiga containergenomsökningar när du använder funktioner som utför en fullständig genomsökning som CONTAINS. Du kan lägga till fler filterpredikat som använder indexet för att påskynda dessa frågor. Ordningen på filtersatser är inte viktig. Frågemotorn räknar ut vilka predikat som är mer selektiva och kör frågan därefter.
Information om hur du konfigurerar sammansatta index finns i Exempel på sammansatt indexeringsprincip
Indexanvändning
Det finns fem sätt som frågemotorn kan utvärdera frågefilter, sorterade efter mest effektiva till minst effektiva:
- Indexsökning
- Exakt indexgenomsökning
- Utökad indexgenomsökning
- Fullständig indexgenomsökning
- Fullständig genomsökning
När du indexerar egenskapssökvägar använder frågemotorn automatiskt indexet så effektivt som möjligt. Förutom att indexera nya egenskapssökvägar behöver du inte konfigurera något för att optimera hur frågor använder indexet. En frågas RU-avgift är en kombination av både RU-avgiften från indexanvändningen och RU-avgiften från inläsning av objekt.
Här är en tabell som sammanfattar de olika sätt som index används i Azure Cosmos DB:
| Indexsökningstyp | Description | Vanliga exempel | RU-debitering från indexanvändning | RU-avgifter från inläsning av objekt från transaktionsdatalager |
|---|---|---|---|---|
| Indexsökning | Skrivskyddade obligatoriska indexerade värden och läs endast in matchande objekt från transaktionsdatalagret | Likhetsfilter, IN | Konstant per likhetsfilter | Ökningar baserat på antalet objekt i frågeresultat |
| Exakt indexgenomsökning | Binär sökning efter indexerade värden och läs endast in matchande objekt från transaktionsdatalagret | Intervalljämförelser (>, <, <=eller >=), StartsWith | Jämförbar med indexsökning, ökningar något baserat på kardinaliteten för indexerade egenskaper | Ökningar baserat på antalet objekt i frågeresultat |
| Utökad indexgenomsökning | Optimerad sökning (men mindre effektiv än en binär sökning) av indexerade värden och läs in endast matchande objekt från transaktionsdatalagret | StartsWith (skiftlägesokänslig), StringEquals (skiftlägesokänslig) | Ökar något baserat på kardinaliteten för indexerade egenskaper | Ökningar baserat på antalet objekt i frågeresultat |
| Fullständig indexgenomsökning | Läs distinkt uppsättning indexerade värden och läs endast in matchande objekt från transaktionsdatalagret | Contains, EndsWith, RegexMatch, LIKE | Ökar linjärt baserat på kardinaliteten för indexerade egenskaper | Ökningar baserat på antalet objekt i frågeresultat |
| Fullständig genomsökning | Läs in alla objekt från transaktionsdatalagret | Övre, nedre | Ej tillämpligt | Ökningar baserat på antalet objekt i containern |
När du skriver frågor bör du använda filterpredikat som använder indexet så effektivt som möjligt. Om antingen StartsWith eller Contains skulle fungera för ditt användningsfall bör du till exempel välja eftersom det gör en exakt indexgenomsökning i stället för StartsWith en fullständig indexgenomsökning.
Information om indexanvändning
I det här avsnittet går vi igenom mer information om hur frågor använder index. Den här detaljnivån är inte nödvändig för att lära dig att komma igång med Azure Cosmos DB, men den dokumenteras i detalj för nyfikna användare. Vi refererar till exempelobjektet som delades tidigare i det här dokumentet:
Exempelobjekt:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB använder ett inverterat index. Indexet fungerar genom att mappa varje JSON-sökväg till den uppsättning objekt som innehåller det värdet. Objekt-ID-mappningen representeras på många olika indexsidor för containern. Här är ett exempeldiagram över ett inverterat index för en container som innehåller de två exempelobjekten:
| Sökväg | Värde | Lista över objekt-ID:t |
|---|---|---|
| /locations/0/country | Tyskland | 1 |
| /locations/0/country | Irland | 2 |
| /locations/0/city | Berlin | 1 |
| /locations/0/city | Dublin | 2 |
| /locations/1/country | Frankrike | 1 |
| /locations/1/city | Paris | 1 |
| /huvudkontor/land | Belgien | 1, 2 |
| /huvudkontor/anställda | 200 | 2 |
| /huvudkontor/anställda | 250 | 1 |
Det inverterade indexet har två viktiga attribut:
- För en viss sökväg sorteras värdena i stigande ordning. Därför kan frågemotorn enkelt hantera
ORDER BYfrån indexet. - För en viss sökväg kan frågemotorn söka igenom den distinkta uppsättningen möjliga värden för att identifiera indexsidorna där det finns resultat.
Frågemotorn kan använda det inverterade indexet på fyra olika sätt:
Indexsökning
Överväg följande fråga:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'`
Frågepredikatet (filtrering på objekt där en plats har "Frankrike" som land/region) matchar sökvägen som markeras i det här diagrammet:

Eftersom den här frågan har ett likhetsfilter kan vi snabbt identifiera de indexsidor som innehåller frågeresultatet efter att ha bläddrat i det här trädet. I det här fallet skulle frågemotorn läsa indexsidor som innehåller objekt 1. En indexsökning är det effektivaste sättet att använda indexet. Med en indexsökning läser vi bara de nödvändiga indexsidorna och läser bara in objekten i frågeresultatet. Därför är indexuppslagstiden och RU-avgiften från indexsökningen otroligt låg, oavsett den totala datavolymen.
Exakt indexgenomsökning
Överväg följande fråga:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
Frågepredikatet (filtrering av objekt där det finns fler än 200 anställda) kan utvärderas med en exakt indexgenomsökning av headquarters/employees sökvägen. När du gör en exakt indexgenomsökning börjar frågemotorn med en binär sökning av den distinkta uppsättningen möjliga värden för att hitta platsen för värdet 200 för headquarters/employees sökvägen. Eftersom värdena för varje sökväg sorteras i stigande ordning är det enkelt för frågemotorn att göra en binär sökning. När frågemotorn hittar värdet 200börjar den läsa alla återstående indexsidor (i stigande riktning).
Eftersom frågemotorn kan göra en binär sökning för att undvika genomsökning av onödiga indexsidor tenderar exakta indexgenomsökningar att ha jämförbara svarstider och RU-avgifter för indexsökningsåtgärder.
Utökad indexgenomsökning
Överväg följande fråga:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
Frågepredikatet (filtrering av objekt som har huvudkontor på en plats som börjar med skiftlägesokänsliga "United") kan utvärderas med en utökad indexgenomsökning av headquarters/country sökvägen. Åtgärder som utför en utökad indexgenomsökning har optimeringar som kan hjälpa dig att undvika behov av att söka igenom varje indexsida, men som är något dyrare än en exakt indexgenomsöknings binära sökning.
När du till exempel utvärderar skiftlägesokänsligt StartsWithkontrollerar frågemotorn indexet efter olika möjliga kombinationer av versaler och gemener. Med den här optimeringen kan frågemotorn undvika att läsa de flesta indexsidor. Olika systemfunktioner har olika optimeringar som de kan använda för att undvika att läsa varje indexsida, så de kategoriseras brett som expanderad indexgenomsökning.
Fullständig indexgenomsökning
Överväg följande fråga:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Frågepredikatet (filtrering av objekt som har huvudkontor på en plats som innehåller "United") kan utvärderas med en indexgenomsökning av headquarters/country sökvägen. Till skillnad från en exakt indexgenomsökning genomsöker en fullständig indexgenomsökning alltid genom den distinkta uppsättningen möjliga värden för att identifiera indexsidorna där det finns resultat. I det här fallet Contains körs på indexet. Indexsökningstiden och RU-avgiften för indexgenomsökningar ökar när sökvägens kardinalitet ökar. Med andra ord, ju mer möjliga distinkta värden som frågemotorn behöver för att genomsöka, desto högre svarstid och RU-debitering krävs för att utföra en fullständig indexgenomsökning.
Överväg till exempel två egenskaper: town och country. Kardinaliteten av townen är 5.000 och kardinaliteten av country är 200. Här är två exempelfrågor som var och en har en Contains-systemfunktion som utför en fullständig indexgenomsökning på town egenskapen . Den första frågan använder fler RU:er än den andra frågan eftersom kardinaliteten för staden är högre än country.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Fullständig genomsökning
I vissa fall kanske frågemotorn inte kan utvärdera ett frågefilter med hjälp av indexet. I det här fallet måste frågemotorn läsa in alla objekt från transaktionsarkivet för att kunna utvärdera frågefiltret. Fullständiga genomsökningar använder inte indexet och har en RU-avgift som ökar linjärt med den totala datastorleken. Lyckligtvis är åtgärder som kräver fullständiga genomsökningar sällsynta.
Frågor med komplexa filteruttryck
I de tidigare exemplen övervägde vi bara frågor som hade enkla filteruttryck (till exempel frågor med bara ett enda likhets- eller intervallfilter). I verkligheten har de flesta frågor mycket mer komplexa filteruttryck.
Överväg följande fråga:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
För att köra den här frågan måste frågemotorn utföra en indexsökning på headquarters/employees och en fullständig indexgenomsökning på headquarters/country. Frågemotorn har intern heuristik som används för att utvärdera frågefilteruttrycket så effektivt som möjligt. I det här fallet skulle frågemotorn undvika att behöva läsa onödiga indexsidor genom att göra indexsökningen först. Om till exempel endast 50 objekt matchade likhetsfiltret skulle frågemotorn bara behöva utvärdera Contains på indexsidorna som innehöll de 50 objekten. En fullständig indexgenomsökning av hela containern skulle inte vara nödvändig.
Indexanvändning för skalära mängdfunktioner
Frågor med mängdfunktioner måste uteslutande förlita sig på indexet för att kunna använda det.
I vissa fall kan indexet returnera falska positiva identifieringar. När du till exempel utvärderar Contains indexet kan antalet matchningar i indexet överskrida antalet frågeresultat. Frågemotorn läser in alla indexmatchningar, utvärderar filtret på de inlästa objekten och returnerar endast rätt resultat.
För de flesta frågor har inläsning av falska positiva indexmatchningar ingen märkbar effekt på indexanvändningen.
Tänk dig följande fråga:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Systemfunktionen Contains kan returnera vissa falska positiva matchningar, så frågemotorn måste kontrollera om varje inläst objekt matchar filteruttrycket. I det här exemplet kanske frågemotorn bara behöver läsa in några extra objekt, så effekten på indexanvändningen och RU-avgiften är minimal.
Frågor med mängdfunktioner måste dock uteslutande förlita sig på indexet för att kunna använda det. Tänk dig till exempel följande fråga med en Count aggregering:
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Precis som i det första exemplet Contains kan systemfunktionen returnera några falska positiva matchningar. Till skillnad från frågan SELECT * kan frågan dock Count inte utvärdera filteruttrycket på de inlästa objekten för att verifiera alla indexmatchningar. Frågan Count måste förlita sig uteslutande på indexet, så om det finns en chans att ett filteruttryck returnerar falska positiva matchningar, så får frågemotorn en fullständig genomsökning.
Frågor med följande mängdfunktioner måste förlita sig uteslutande på indexet, så utvärdering av vissa systemfunktioner kräver en fullständig genomsökning.
Nästa steg
Läs mer om indexering i följande artiklar: