Så här modellerar och partitionerar du data i Azure Cosmos DB med ett verkligt exempel
GÄLLER FÖR: ![]() NoSQL
NoSQL
Den här artikeln bygger på flera Azure Cosmos DB-begrepp som datamodellering, partitionering och etablerat dataflöde för att demonstrera hur du hanterar en verklig datadesignövning.
Om du vanligtvis arbetar med relationsdatabaser har du förmodligen skapat vanor och intuitioner för hur du utformar en datamodell. På grund av de specifika begränsningarna, men även de unika fördelarna med Azure Cosmos DB, översätter de flesta av dessa metodtips inte bra och kan dra dig till icke-optimala lösningar. Målet med den här artikeln är att vägleda dig genom hela processen med att modellera ett verkligt användningsfall i Azure Cosmos DB, från objektmodellering till entitetssamlokalisering och containerpartitionering.
Ladda ned eller visa en community-genererad källkod som illustrerar begreppen i den här artikeln.
Viktigt
En community-deltagare bidrog med det här kodexemplet och Azure Cosmos DB-teamet stöder inte underhåll.
Scenariot
I den här övningen ska vi överväga domänen för en bloggplattform där användare kan skapa inlägg. Användarna kan också gilla och lägga till kommentarer i dessa inlägg.
Tips
Vi har belyst några ord i kursiv stil. dessa ord identifierar vilken typ av "saker" som vår modell måste manipulera.
Lägga till fler krav i vår specifikation:
- En förstasida visar ett flöde med nyligen skapade inlägg,
- Vi kan hämta alla inlägg för en användare, alla kommentarer för ett inlägg och alla gillar för ett inlägg,
- Inlägg returneras med användarnamnet för sina författare och antalet kommentarer och gilla-markeringar de har,
- Kommentarer och gilla-markeringar returneras också med användarnamnet för de användare som har skapat dem,
- När inlägg visas som listor behöver de bara visa en trunkerad sammanfattning av innehållet.
Identifiera de viktigaste åtkomstmönstren
Till att börja med ger vi en viss struktur till vår ursprungliga specifikation genom att identifiera vår lösnings åtkomstmönster. När du utformar en datamodell för Azure Cosmos DB är det viktigt att förstå vilka begäranden vår modell måste hantera för att se till att modellen hanterar dessa begäranden effektivt.
För att göra den övergripande processen enklare att följa kategoriserar vi dessa olika begäranden som antingen kommandon eller frågor och lånar en del vokabulär från CQRS. I CQRS är kommandon skrivbegäranden (d.v.s. avsikter att uppdatera systemet) och frågor är skrivskyddade begäranden.
Här är listan över begäranden som vår plattform exponerar:
- [C1] Skapa/redigera en användare
- [Q1] Hämta en användare
- [C2] Skapa/redigera ett inlägg
- [Q2] Hämta ett inlägg
- [Q3] Visa en lista över en användares inlägg i kortformat
- [C3] Skapa en kommentar
- [Q4] Visa en lista över kommentarer i ett inlägg
- [C4] Gilla ett inlägg
- [Q5] Visa en lista över gilla-markeringar för ett inlägg
- [Q6] Visa en lista över de x senaste inläggen som skapats i kortformat (feed)
I det här skedet har vi inte tänkt på informationen om vad varje entitet (användare, inlägg osv.) innehåller. Det här steget är vanligtvis bland de första som ska hanteras när du utformar mot ett relationsarkiv. Vi börjar med det här steget först eftersom vi måste ta reda på hur dessa entiteter översätts i termer av tabeller, kolumner, sekundärnycklar osv. Det är mycket mindre problem med en dokumentdatabas som inte tillämpar något schema vid skrivning.
Den främsta anledningen till att det är viktigt att identifiera våra åtkomstmönster från början är att den här listan över begäranden kommer att bli vår testsvit. Varje gång vi itererar över vår datamodell går vi igenom var och en av begäranden och kontrollerar dess prestanda och skalbarhet. Vi beräknar de enheter för programbegäran som förbrukas i varje modell och optimerar dem. Alla dessa modeller använder standardindexeringsprincipen och du kan åsidosätta den genom att indexera specifika egenskaper, vilket ytterligare kan förbättra RU-förbrukningen och svarstiden.
V1: En första version
Vi börjar med två containrar: users och posts.
Användarcontainer
Den här containern lagrar endast användarobjekt:
{
"id": "<user-id>",
"username": "<username>"
}
Vi partitioneras den här containern med id, vilket innebär att varje logisk partition i containern bara innehåller ett objekt.
Inläggscontainer
Den här containern är värd för entiteter som inlägg, kommentarer och gilla-markeringar:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
Vi partitioneras den här containern med postId, vilket innebär att varje logisk partition i containern innehåller ett inlägg, alla kommentarer för det inlägget och alla likes för det inlägget.
Vi har introducerat en type egenskap i objekten som lagras i den här containern för att skilja mellan de tre typerna av entiteter som den här containern är värd för.
Vi har också valt att referera till relaterade data i stället för att bädda in dem (se det här avsnittet för information om dessa begrepp) eftersom:
- Det finns ingen övre gräns för hur många inlägg en användare kan skapa,
- inlägg kan vara godtyckligt långa,
- det finns ingen övre gräns för hur många kommentarer och gillar ett inlägg kan ha,
- Vi vill kunna lägga till en kommentar eller liknande till ett inlägg utan att behöva uppdatera själva inlägget.
Hur bra presterar modellen?
Nu är det dags att utvärdera prestanda och skalbarhet för vår första version. För var och en av de begäranden som tidigare identifierats mäter vi dess svarstid och hur många enheter för programbegäran den förbrukar. Den här mätningen görs mot en dummydatauppsättning som innehåller 100 000 användare med 5 till 50 inlägg per användare och upp till 25 kommentarer och 100 gilla-markeringar per inlägg.
[C1] Skapa/redigera en användare
Den här begäran är enkel att implementera eftersom vi bara skapar eller uppdaterar ett objekt i containern users . Begäranden sprids fint över alla partitioner tack vare partitionsnyckeln id .
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
7 Ms |
5.71 RU |
✅ |
[Q1] Hämta en användare
Du hämtar en användare genom att läsa motsvarande objekt från containern users .

| Svarstid | RU-avgift | Prestanda |
|---|---|---|
2 Ms |
1 RU |
✅ |
[C2] Skapa/redigera ett inlägg
På samma sätt som [C1] behöver vi bara skriva till containern posts .
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
9 Ms |
8.76 RU |
✅ |
[Q2] Hämta ett inlägg
Vi börjar med att hämta motsvarande dokument från containern posts . Men det räcker inte, enligt vår specifikation måste vi också aggregera användarnamnet för inläggets författare, antal kommentarer och antal gilla-markeringar för inlägget. Aggregeringarna i listan kräver att ytterligare tre SQL-frågor utfärdas.
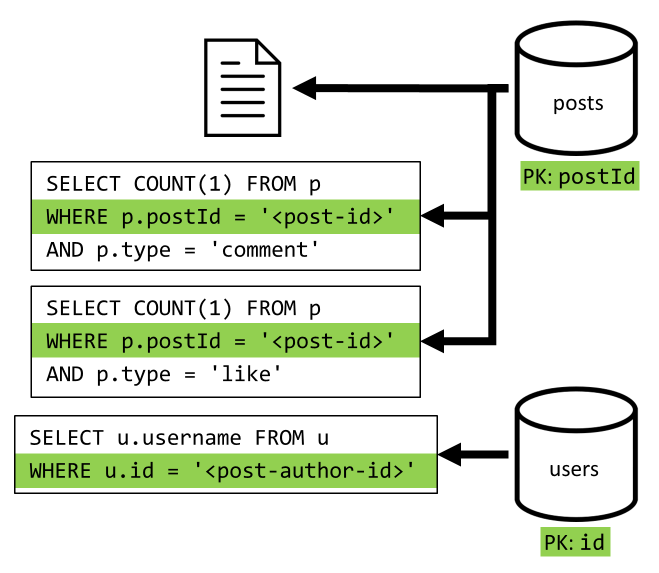
Var och en av de fler frågorna filtrerar partitionsnyckeln för respektive container, vilket är precis vad vi vill maximera prestanda och skalbarhet. Men så småningom måste vi utföra fyra åtgärder för att returnera ett enda inlägg, så vi kommer att förbättra det i en nästa iteration.
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
9 Ms |
19.54 RU |
⚠ |
[Q3] Visa en lista över en användares inlägg i kortformat
Först måste vi hämta önskade inlägg med en SQL-fråga som hämtar de inlägg som motsvarar den specifika användaren. Men vi måste också utfärda fler frågor för att aggregera författarens användarnamn och antalet kommentarer och gilla-markeringar.

Den här implementeringen har många nackdelar:
- frågorna som aggregerar antalet kommentarer och gilla-markeringar måste utfärdas för varje inlägg som returneras av den första frågan.
- huvudfrågan filtrerar inte på partitionsnyckeln för containern
posts, vilket leder till en utgrening och en partitionsgenomsökning i containern.
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
130 Ms |
619.41 RU |
⚠ |
[C3] Skapa en kommentar
En kommentar skapas genom att motsvarande objekt skrivs i containern posts .
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
7 Ms |
8.57 RU |
✅ |
[Q4] Visa en lista över kommentarer i ett inlägg
Vi börjar med en fråga som hämtar alla kommentarer för det inlägget och återigen måste vi även aggregera användarnamn separat för varje kommentar.

Även om huvudfrågan filtrerar på containerns partitionsnyckel, så straffar aggregering av användarnamnen separat den övergripande prestandan. Vi förbättrar det senare.
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
23 Ms |
27.72 RU |
⚠ |
[C4] Gilla ett inlägg
Precis som [C3] skapar vi motsvarande objekt i containern posts .
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
6 Ms |
7.05 RU |
✅ |
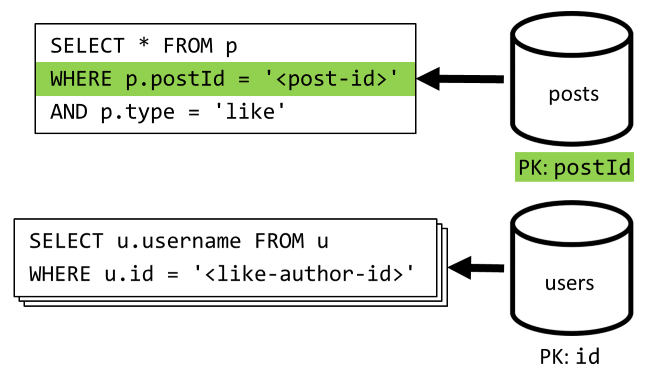
[Q5] Visa en lista över gilla-markeringar för ett inlägg
Precis som [Q4] frågar vi likes för det inlägget och aggregerar sedan deras användarnamn.
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
59 Ms |
58.92 RU |
⚠ |
[Q6] Visa en lista över de x senaste inläggen som skapats i kortformat (feed)
Vi hämtar de senaste inläggen genom att fråga containern posts sorterat efter fallande skapandedatum och sedan aggregera användarnamn och antal kommentarer och gilla-markeringar för var och en av inläggen.
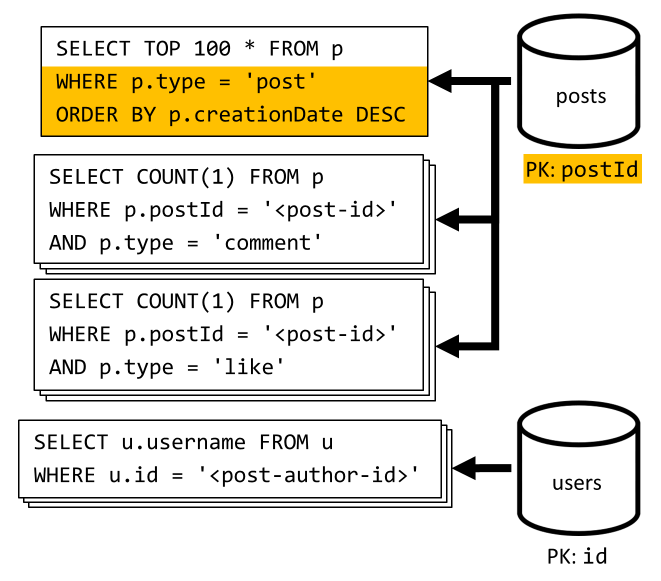
Återigen filtrerar inte vår första fråga på containerns posts partitionsnyckel, vilket utlöser en kostsam utloggning. Den här är ännu sämre eftersom vi riktar in oss på en större resultatuppsättning och sorterar resultatet med en ORDER BY -sats, vilket gör det dyrare när det gäller enheter för programbegäran.
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
306 Ms |
2063.54 RU |
⚠ |
Reflekterar över prestanda för V1
Om vi tittar på prestandaproblemen i föregående avsnitt kan vi identifiera två huvudklasser av problem:
- vissa begäranden kräver att flera frågor utfärdas för att samla in alla data som vi behöver returnera,
- vissa frågor filtrerar inte på partitionsnyckeln för de containrar som de riktar in sig på, vilket leder till en utgrening som hindrar vår skalbarhet.
Vi löser vart och ett av dessa problem och börjar med det första.
V2: Introduktion till avnormalisering för att optimera läsfrågor
Anledningen till att vi måste utfärda fler begäranden i vissa fall är att resultatet av den första begäran inte innehåller alla data som vi behöver returnera. Avnormalisering av data löser den här typen av problem i vår datauppsättning när du arbetar med ett icke-relationellt datalager som Azure Cosmos DB.
I vårt exempel ändrar vi inläggsobjekt för att lägga till användarnamnet för inläggets författare, antalet kommentarer och antalet gilla-markeringar:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Vi ändrar även kommentarer och liknande objekt för att lägga till användarnamnet för användaren som har skapat dem:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Avnormalisera kommentarer och like-antal
Vad vi vill uppnå är att varje gång vi lägger till en kommentar eller liknande ökar commentCount vi också eller likeCount i motsvarande inlägg. När postId partitioner vår posts container finns det nya objektet (kommentar eller liknande) och dess motsvarande inlägg i samma logiska partition. Därför kan vi använda en lagrad procedur för att utföra den åtgärden.
När du skapar en kommentar ([C3]) anropar vi i stället för att bara lägga till ett nytt objekt i containern posts följande lagrade procedur på containern:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Den här lagrade proceduren tar ID:t för inlägget och brödtexten i den nya kommentaren som parametrar och gör sedan följande:
- hämtar inlägget
- ökar
commentCount - ersätter posten
- lägger till den nya kommentaren
När lagrade procedurer körs som atomiska transaktioner förblir värdet commentCount för och det faktiska antalet kommentarer alltid synkroniserade.
Vi anropar uppenbarligen en liknande lagrad procedur när du lägger till nya gilla-markeringar för att öka likeCount.
Avnormalisera användarnamn
Användarnamn kräver en annan metod eftersom användarna inte bara finns i olika partitioner, utan i en annan container. När vi måste avnormalisera data mellan partitioner och containrar kan vi använda källcontainerns ändringsflöde.
I vårt exempel använder vi containerns users ändringsflöde för att reagera när användarna uppdaterar sina användarnamn. När det händer sprider vi ändringen genom att anropa en annan lagrad procedur i containern posts :
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Den här lagrade proceduren tar ID:t för användaren och användarens nya användarnamn som parametrar och gör sedan följande:
- hämtar alla objekt som matchar
userId(som kan vara inlägg, kommentarer eller gilla-markeringar) - för vart och ett av dessa objekt
- ersätter
userUsername - ersätter objektet
- ersätter
Viktigt
Den här åtgärden är kostsam eftersom den här lagrade proceduren måste köras på varje partition i containern posts . Vi förutsätter att de flesta användare väljer ett lämpligt användarnamn under registreringen och aldrig ändrar det, så den här uppdateringen kommer att köras mycket sällan.
Vilka är prestandafördelarna med V2?
Låt oss prata om några av prestandafördelarna med V2.
[Q2] Hämta ett inlägg
Nu när avnormaliseringen är på plats behöver vi bara hämta ett enda objekt för att hantera begäran.
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
2 Ms |
1 RU |
✅ |
[Q4] Visa en lista över kommentarer i ett inlägg
Här kan vi återigen spara de extra begäranden som hämtade användarnamnen och sluta med en enda fråga som filtrerar på partitionsnyckeln.
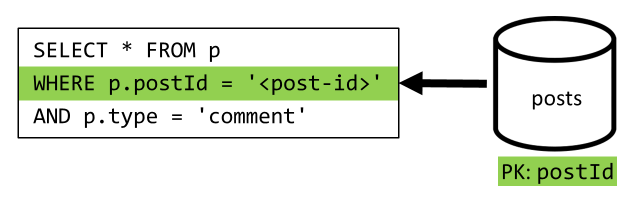
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
4 Ms |
7.72 RU |
✅ |
[Q5] Visa en lista över gilla-markeringar för ett inlägg
Exakt samma situation när du listar gilla-markeringar.
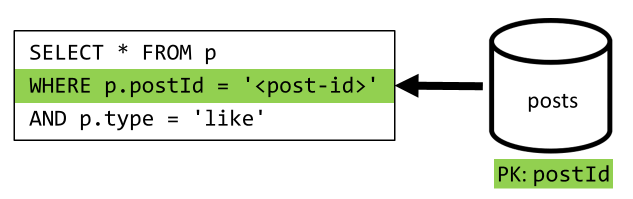
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
4 Ms |
8.92 RU |
✅ |
V3: Kontrollera att alla begäranden är skalbara
Det finns fortfarande två begäranden som vi inte har optimerat fullt ut när vi tittar på våra övergripande prestandaförbättringar. Dessa begäranden är [Q3] och [Q6]. Det är begäranden som rör frågor som inte filtrerar på partitionsnyckeln för de containrar som de riktar in sig på.
[Q3] Visa en lista över en användares inlägg i kortformat
Den här begäran drar redan nytta av de förbättringar som introducerades i V2, vilket sparar fler frågor.

Men den återstående frågan filtrerar fortfarande inte på containerns posts partitionsnyckel.
Sättet att tänka på den här situationen är enkelt:
- Den här begäran måste filtrera på
userIdeftersom vi vill hämta alla inlägg för en viss användare. - Den fungerar inte bra eftersom den körs mot containern
posts, som inte haruserIdpartitionering. - Om vi anger det uppenbara skulle vi lösa vårt prestandaproblem genom att köra den här begäran mot en container som partitionerats med
userId. - Det visar sig att vi redan har en sådan container: containern
users!
Därför introducerar vi en andra nivå av avnormalisering genom att duplicera hela inlägg till containern users . Genom att göra det får vi effektivt en kopia av våra inlägg, endast partitionerade längs en annan dimension, vilket gör dem mycket mer effektiva att hämta med deras userId.
Containern users innehåller nu två typer av objekt:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
I det här exemplet:
- Vi har introducerat ett
typefält i användarobjektet för att skilja användare från inlägg, - Vi har också lagt till ett
userIdfält i användarobjektet, som är redundant medidfältet men krävs eftersom containernusersnu är partitionerad meduserId(och inteidsom tidigare)
För att uppnå den avnormaliseringen använder vi återigen ändringsflödet. Den här gången reagerar vi på containerns posts ändringsflöde för att skicka nya eller uppdaterade inlägg till containern users . Och eftersom listning av inlägg inte kräver att de returnerar sitt fullständiga innehåll kan vi trunkera dem i processen.
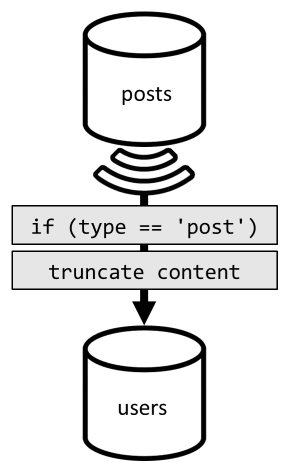
Nu kan vi dirigera frågan till containern users och filtrera containerns partitionsnyckel.

| Svarstid | RU-avgift | Prestanda |
|---|---|---|
4 Ms |
6.46 RU |
✅ |
[Q6] Visa en lista över de x senaste inläggen som skapats i kortformat (feed)
Vi måste hantera en liknande situation här: även efter att ha sparat de fler frågor som lämnas onödiga av den avnormalisering som introducerades i V2 filtrerar inte den återstående frågan på containerns partitionsnyckel:
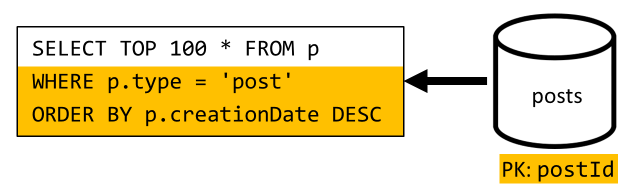
Om du använder samma metod kräver en maximering av den här begärans prestanda och skalbarhet att den bara når en partition. Det går bara att nå en enda partition eftersom vi bara behöver returnera ett begränsat antal objekt. För att fylla vår bloggplattforms startsida behöver vi bara få de 100 senaste inläggen, utan att behöva sidnumrera genom hela datauppsättningen.
För att optimera den senaste begäran introducerar vi därför en tredje container i vår design, helt dedikerad för att hantera den här begäran. Vi avnormaliserar våra inlägg till den nya feed containern:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Fältet type partitioner den här containern, som alltid post finns i våra objekt. Detta säkerställer att alla objekt i den här containern finns i samma partition.
För att uppnå avnormaliseringen behöver vi bara haka på den pipeline för ändringsflöde som vi tidigare har introducerat för att skicka inläggen till den nya containern. En viktig sak att tänka på är att vi måste se till att vi bara lagrar de 100 senaste inläggen; Annars kan innehållet i containern växa utöver den maximala storleken på en partition. Den här begränsningen kan implementeras genom att anropa en efterutlösare varje gång ett dokument läggs till i containern:
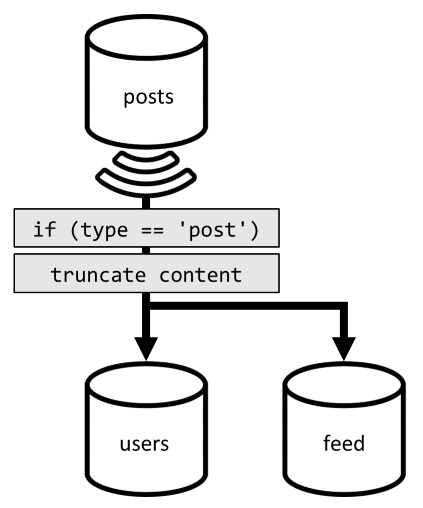
Här är brödtexten i efterutlösaren som trunkerar samlingen:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
Det sista steget är att omdirigera frågan till vår nya feed container:
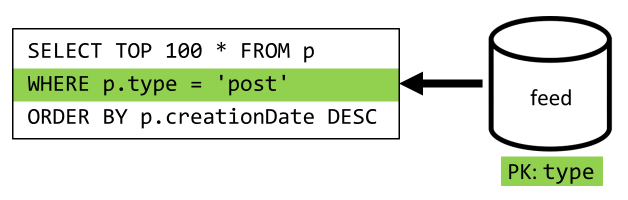
| Svarstid | RU-avgift | Prestanda |
|---|---|---|
9 Ms |
16.97 RU |
✅ |
Slutsats
Låt oss ta en titt på de övergripande prestanda- och skalbarhetsförbättringarna som vi har introducerat i de olika versionerna av vår design.
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms/ 5.71 RU |
7 ms/ 5.71 RU |
7 ms/ 5.71 RU |
| [Q1] | 2 ms/ 1 RU |
2 ms/ 1 RU |
2 ms/ 1 RU |
| [C2] | 9 ms/ 8.76 RU |
9 ms/ 8.76 RU |
9 ms/ 8.76 RU |
| [Q2] | 9 ms/ 19.54 RU |
2 ms/ 1 RU |
2 ms/ 1 RU |
| [Q3] | 130 ms/ 619.41 RU |
28 ms/ 201.54 RU |
4 ms/ 6.46 RU |
| [C3] | 7 ms/ 8.57 RU |
7 ms/ 15.27 RU |
7 ms/ 15.27 RU |
| [Q4] | 23 ms/ 27.72 RU |
4 ms/ 7.72 RU |
4 ms/ 7.72 RU |
| [C4] | 6 ms/ 7.05 RU |
7 ms/ 14.67 RU |
7 ms/ 14.67 RU |
| [Q5] | 59 ms/ 58.92 RU |
4 ms/ 8.92 RU |
4 ms/ 8.92 RU |
| [Q6] | 306 ms/ 2063.54 RU |
83 ms/ 532.33 RU |
9 ms/ 16.97 RU |
Vi har optimerat ett läsintensivt scenario
Du kanske har märkt att vi har koncentrerat våra ansträngningar på att förbättra prestandan för läsbegäranden (frågor) på bekostnad av skrivbegäranden (kommandon). I många fall utlöser skrivåtgärder nu efterföljande denormalisering via ändringsflöden, vilket gör dem mer beräkningsmässigt dyra och längre att materialisera.
Vi motiverar detta fokus på läsprestanda med det faktum att en bloggplattform (som de flesta sociala appar) är läsintensiv. En läsintensiv arbetsbelastning anger att mängden läsbegäranden som den måste hantera vanligtvis är större än antalet skrivbegäranden. Så det är vettigt att göra skrivförfrågningar dyrare att köra för att låta läsbegäranden vara billigare och bättre presterande.
Om vi tittar på den mest extrema optimering vi har gjort gick [Q6] från 2000+ RU:er till bara 17 RU:er; vi har uppnått detta genom att avnormalisera inlägg till en kostnad av cirka 10 RU:er per objekt. Eftersom vi skulle hantera mycket fler feedbegäranden än att skapa eller uppdatera inlägg är kostnaden för den här avnormaliseringen försumbar med tanke på de totala besparingarna.
Avormalisering kan tillämpas stegvis
De skalbarhetsförbättringar som vi har utforskat i den här artikeln omfattar avormalisering och duplicering av data i datauppsättningen. Det bör noteras att dessa optimeringar inte behöver införas dag 1. Frågor som filtrerar på partitionsnycklar fungerar bättre i stor skala, men frågor mellan partitioner kan accepteras om de anropas sällan eller mot en begränsad datauppsättning. Om du bara skapar en prototyp eller lanserar en produkt med en liten och kontrollerad användarbas kan du förmodligen spara dessa förbättringar till senare. Det viktiga är sedan att övervaka modellens prestanda så att du kan bestämma om och när det är dags att ta in dem.
Ändringsflödet som vi använder för att distribuera uppdateringar till andra containrar lagrar alla dessa uppdateringar beständigt. Den här beständigheten gör det möjligt att begära alla uppdateringar eftersom containern och bootstrap-avnormaliserade vyer skapas som en engångsåtgärd även om systemet redan har många data.
Nästa steg
Efter den här introduktionen till praktisk datamodellering och partitionering kanske du vill kontrollera följande artiklar för att granska de begrepp som vi har gått igenom: