Hälsokontroller
CycleCloud erbjuder två mekanismer för att kontrollera hälsotillståndet för virtuella datorer: Node Health Checks är en nyare funktion som utför kontrollerna under etableringsfasen och förhindrar att de virtuella datorerna med fel ansluts, medan HealthCheck kör dem regelbundet när den virtuella datorn har anslutit klustret som en nod.
Hälsokontroller för nod
Node Health-kontroller kan identifiera felaktig maskinvara innan en virtuell dator tillåts ansluta till CycleCloud-kluster. Den aktuella versionen av den här funktionen kör hälsokontrollskript som är inbyggda i de officiella AzureHPC-avbildningarna som finns under /opt/azurehpc/test/azurehpc-health-checks/. Källan för dessa skript finns på lagringsplatsen AzureHPC Node Health Checks, men observera att den version som är inbyggd i klustrets version av AzureHPC-avbildningen kanske inte är den senaste som är tillgänglig på lagringsplatsen.
Krav
Den aktuella versionen av Node Health Checks stöder endast AzureHPC-avbildningar som släppts efter den 7 november 2023 (som innehåller azurehpc-health-checks version v2.0.6 eller senare) och anpassade avbildningar som härletts från dem. Node Health Checks stöds för närvarande inte i Windows.
Aktivera nodhälsokontroller för Slurm-kluster
Formuläret För att skapa Slurm-kluster finns en kryssruta för att aktivera Hälsokontroller för nod under fliken Avancerade inställningar . Om du markerar kryssrutan aktiveras Node Health Checks i klustrets HPC-nodmatris. Om du vill aktivera Nodhälsokontroller på andra nodmatriser (eller för andra klustertyper) måste du använda en anpassad klustermall.
Node Health-kontroller kan inaktiveras i ett kluster som körs genom att helt enkelt avmarkera rutan. Nodmatrisen behöver inte skalas ned för att ändringarna ska börja gälla.
Förstå resultat från Node Health-kontroller
När en virtuell dator har godkänt hälsokontroller går den vidare till programkonfigurationsfasen.
Om en virtuell dator misslyckas med något av hälsokontrollskripten skickas ett felmeddelande till CycleCloud och den virtuella datorn förhindras automatiskt från att ansluta till klustret.
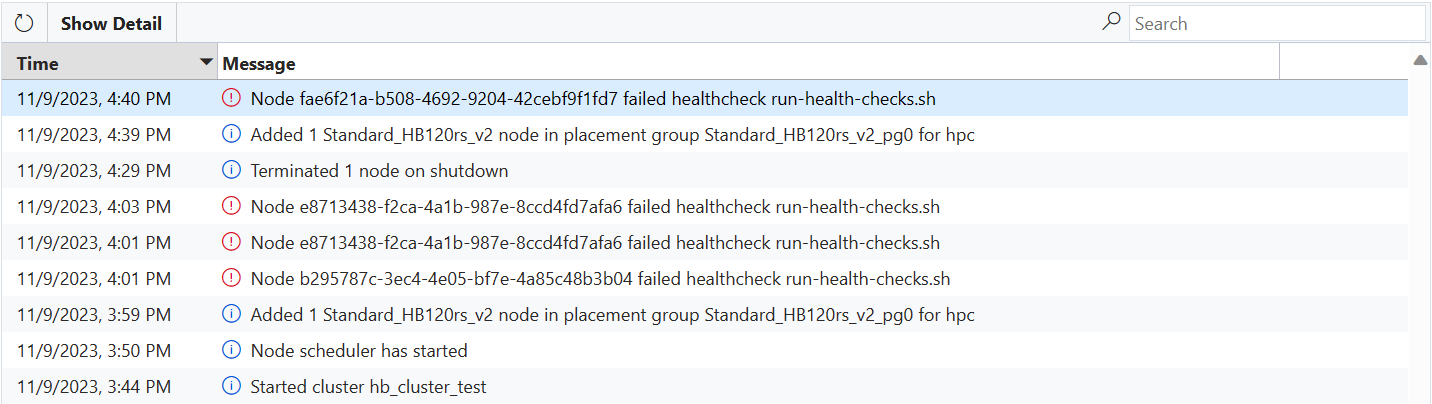
Om den virtuella datorn startas i en NodeArray med överetablering aktiverat (t.ex. Slurm hpc Node Array) bör den virtuella datorn ersättas automatiskt som en del av överetablering. I så fall krävs ingen åtgärd och de felfria virtuella datorerna väljs för att ansluta till klustret (även om du ser ett felmeddelande på klustersidan som anger att en eller flera virtuella datorer misslyckades med kontrollerna).
Om den virtuella datorn startas för en enskild nod, en nodmatris med överetablering inaktiverad (till exempel Slurm htc Node Array), eller om fler virtuella datorer misslyckas med hälsokontroller än vad som stöds av överetablering, flyttas noden till tillståndet Misslyckades och allokeringen misslyckas. CycleCloud kan försöka avbildninga den virtuella datorn igen för att åtgärda problemet, men om avbildningen misslyckas måste noden avslutas och ersättas (manuellt av en administratör eller automatiskt av autoskalningen).
Anteckning
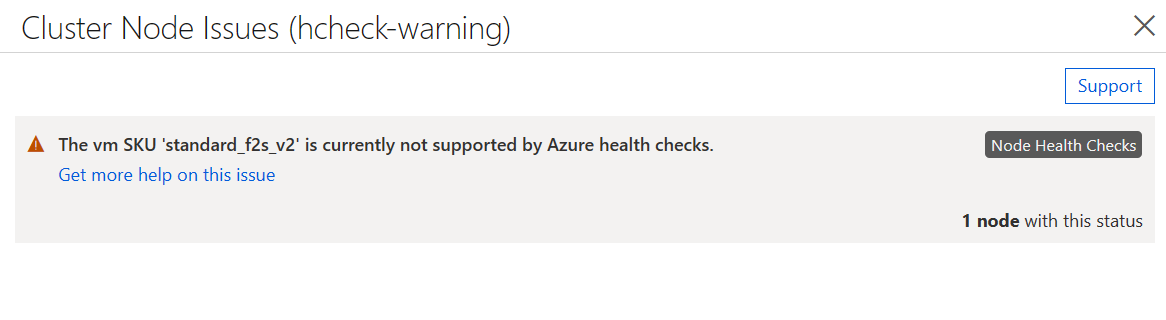
Om du har aktiverat Hälsokontroller för nod, men VM-avbildningen inte uppfyller kraven ovan, tillåts alla virtuella datorer att ansluta till klustret, men statusen innehåller en varning som anger att kontroller inte stöds.
Attributreferens
| Attribut | Typ | Definition |
|---|---|---|
| EnableNodeHealthChecks | Boolesk | (Valfritt) Aktivera hälsokontroller på startnoden för den här noden eller nodmatrisen |
Hälsokontroll
Azure CycleCloud tillhandahåller en mekanism för att avsluta virtuella datorer (VM) som är i ett feltillstånd som kallas HealthCheck. Både system- och användardefinierade skript (Python och Bash) körs regelbundet (5 minuter i Windows, 10 minuter i Linux) för att fastställa den övergripande hälsan för en virtuell dator. Med HealthCheck kan administratörer definiera villkor under vilka virtuella datorer ska avslutas utan att behöva övervaka och åtgärda dem manuellt.
Inbyggda HealthCheck-skript
CycleCloud-aktiverade virtuella datorer har två standardskript för HealthCheck:
- Skriptet converge_timeout avslutar en instans som inte har slutfört programvarukonfigurationen inom fyra timmar efter starten. Den här tidsgränsperioden kan styras med
cyclecloud.keepalive.timeoutinställningen (definieras i sekunder). - Skriptet scheduled_shutdown söker efter maker-filer i $JETPACK_HOME/run/scheduled_shutdown som innehåller en enda rad som ger en avstängningstid i Unix-tidsstämpelsekunder och en valfri andra rad med en förklaring. När den aktuella tiden är senare än den tidigaste tidsstämpeln i filerna anses den virtuella datorn vara felaktig.
Så här fungerar det
HealthCheck-skripten finns i katalogen $JETPACK_HOME/config/healthcheck.d . Linux stöder både Python- och Bash-skript, medan Windows endast stöder Python-skript. Skriptet ska bestämma hälsotillståndet för den virtuella datorn. Om den virtuella datorn inte är felfri ska skriptet avslutas med statusen 254, vilket indikerar för CycleCloud att den virtuella datorn inte är felfri och bör avslutas.
När du är inloggad på en virtuell dator som kör HealthCheck kan du förhindra att den virtuella datorn stängs av genom att köra kommandot jetpack keepalive. På Linux-instanser kan du ange en tidsram i timmar eller forever när du använder Windows forever är det enda alternativet.
Anteckning
När en virtuell dator bedöms vara skadad skickar HealthCheck-agenten en begäran om att CycleCloud ska avsluta den virtuella datorn. Den virtuella datorn stängs aldrig av lokalt via shutdown kommandot. Om den virtuella datorn inte kan kommunicera med CycleCloud kommer den virtuella datorn att vara igång även om den inte är felfri förrän en tidpunkt då CycleCloud kan nås.
Exempel
Som ett enkelt exempel skriver vi ett HealthCheck-skript som ser till att en virtuell Linux-dator inte är aktiv på mer än 24 timmar. Det här skriptet kan användas för att simulera borttagningar med låg prioritet för att testa hur ett arbetsflöde reagerar på en borttagen virtuell dator. Det här skriptet placeras i /opt/cycle/jetpack/config/healthcheck.d/healthcheck_example.sh
#!/bin/bash
# Get the uptime of the system (in seconds) and check to see if it is
# greater than 86,400 (24 hours in seconds). If it is, exit 254 to
# signal that the VM is unhealthy.
if (( $(cat /proc/uptime | awk '{print ($1 > 86400)}'))); then
exit 254
fi
Anteckning
Det här skriptet kan placeras på en virtuell dator via CycleCloud-projekt eller genom att lägga till det direkt när du skapar en anpassad avbildning.