Optimera transformeringar
Använd följande strategier för att optimera prestanda för transformeringar vid mappning av dataflöden i Azure Data Factory och Azure Synapse Analytics-pipelines.
Optimera kopplingar, finns och sökningar
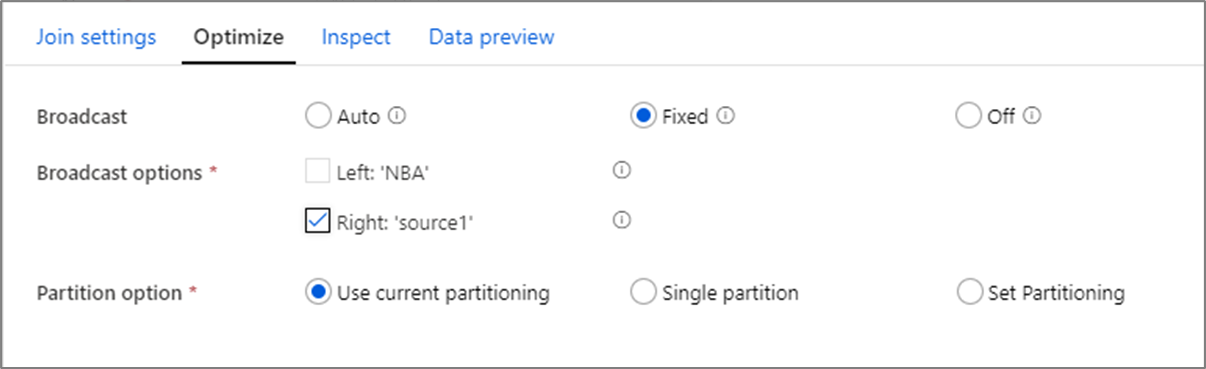
Sänder
I kopplingar, sökningar och finns transformeringar, om en eller båda dataströmmarna är tillräckligt små för att passa in i arbetsnodminnet, kan du optimera prestanda genom att aktivera Sändning. Sändning sker när du skickar små dataramar till alla noder i klustret. Detta gör att Spark-motorn kan utföra en koppling utan att omfördefingera data i den stora strömmen. Som standard avgör Spark-motorn automatiskt om en sida av en koppling ska sändas eller inte. Om du är bekant med dina inkommande data och vet att den ena strömmen är mindre än den andra kan du välja Fast sändning. Fast sändning tvingar Spark att sända den valda strömmen.
Om storleken på de utsända data är för stor för Spark-noden kan du få ett minnesfel. Använd minnesoptimerade kluster för att undvika minnesfel. Om du får tidsgränser för sändning under dataflödeskörningar kan du stänga av sändningsoptimeringen. Detta resulterar dock i långsammare dataflöden.
När du arbetar med datakällor som kan ta längre tid att fråga, till exempel stora databasfrågor, rekommenderar vi att du inaktiverar sändning för kopplingar. Källa med långa frågetider kan orsaka Spark-timeouter när klustret försöker sända till beräkningsnoder. Ett annat bra val för att stänga av sändning är när du har en ström i ditt dataflöde som aggregerar värden för användning i en uppslagstransformering senare. Det här mönstret kan förvirra Spark-optimeraren och orsaka timeouter.
Korskopplingar
Om du använder literalvärden i kopplingsvillkoren eller har flera matchningar på båda sidor av en koppling kör Spark kopplingen som en korskoppling. En korskoppling är en fullständig kartesisk produkt som sedan filtrerar bort de kopplade värdena. Det här är långsammare än andra kopplingstyper. Se till att du har kolumnreferenser på båda sidor av kopplingsvillkoren för att undvika prestandapåverkan.
Sortering före kopplingar
Till skillnad från sammanslagningskoppling i verktyg som SSIS är kopplingstransformeringen inte en obligatorisk kopplingsåtgärd. Kopplingsnycklarna kräver inte sortering före omvandlingen. Att använda sorteringstransformeringar i mappning av dataflöden rekommenderas inte.
Prestanda för fönstertransformering
Fönstertransformeringen i mappning av dataflödet partitioner dina data efter värde i kolumner som du väljer som en del av over() -satsen i transformeringsinställningarna. Det finns många populära aggregerings- och analysfunktioner som exponeras i Windows-omvandlingen. Men om ditt användningsfall är att generera ett fönster över hela datauppsättningen för rangordning rank() eller radnummer rowNumber()rekommenderar vi att du i stället använder omvandlingen Rank transformation och Surrogate Key. Dessa transformeringar utför bättre fullständiga datauppsättningsåtgärder igen med hjälp av dessa funktioner.
Ompartitionera skeva data
Vissa transformeringar, till exempel kopplingar och aggregeringar, omdelar dina datapartitioner och kan ibland leda till skeva data. Skeva data innebär att data inte är jämnt fördelade över partitionerna. Kraftigt skeva data kan leda till långsammare nedströmstransformeringar och skrivning av mottagare. Du kan kontrollera att dina data är skeva när som helst i ett dataflöde som körs genom att klicka på omvandlingen i övervakningsvisningen.
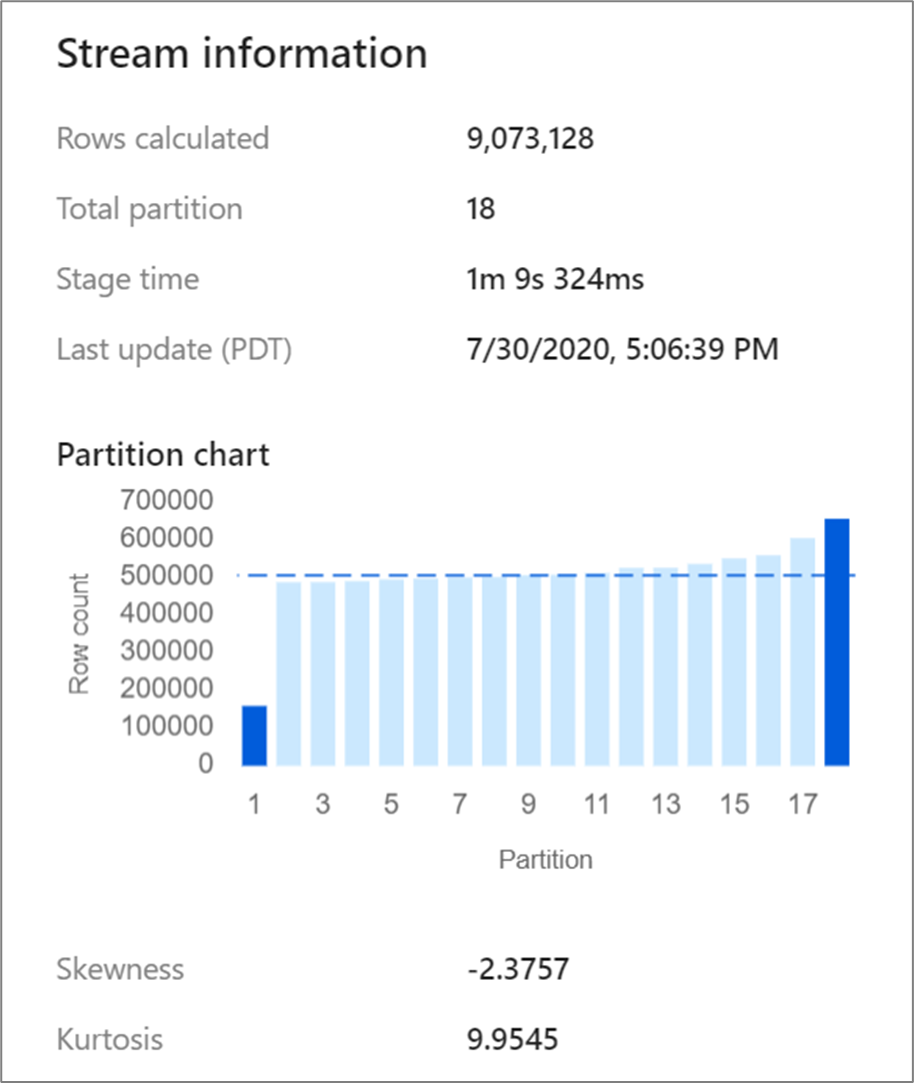
Övervakningsvisningen visar hur data distribueras över varje partition tillsammans med två mått, skevhet och kurtos. Skevhet är ett mått på hur asymmetriska data är och kan ha ett positivt, noll, negativt eller odefinierat värde. Negativ snedställning innebär att vänster svans är längre än höger. Kurtosis är måttet på om data är tungstjärtade eller lättstjärtade. Höga kurtosvärden är inte önskvärda. Idealiska intervall av skevhet ligger mellan -3 och 3 och intervall av kurtosis är mindre än 10. Ett enkelt sätt att tolka dessa tal är att titta på partitionsdiagrammet och se om 1 stapel är större än resten.
Om dina data inte är jämnt partitionerade efter en transformering kan du använda fliken optimera för att partitionera om. Ombildning av data tar tid och kanske inte förbättrar dataflödesprestandan.
Dricks
Om du partitionerar om dina data, men har underordnade transformeringar som omdelar dina data, använder du hashpartitionering på en kolumn som används som kopplingsnyckel.
Kommentar
Transformeringar i dataflödet (med undantag för transformering av mottagare) ändrar inte fil- och mapppartitionering av vilande data. Partitionering i varje transformering ompartitionerar data i dataramarna i det tillfälliga serverlösa Spark-klustret som ADF hanterar för var och en av dina dataflödeskörningar.
Relaterat innehåll
Se andra Dataflöde artiklar om prestanda: