Aktivera konfiguration av dataåtkomst
I den här artikeln beskrivs konfigurationer för dataåtkomst som utförs av Azure Databricks-administratörer för alla SQL-lager med hjälp av användargränssnittet.
Kommentar
Om din arbetsyta är aktiverad för Unity Catalog behöver du inte utföra stegen i den här artikeln. Unity Catalog har som standard stöd för SQL-lager.
Databricks rekommenderar att du använder Unity Catalog-volymer eller externa platser för att ansluta till molnobjektlagring i stället för instansprofiler. Unity Catalog förenklar säkerheten och styrningen av dina data genom att tillhandahålla en central plats för att administrera och granska dataåtkomst över flera arbetsytor i ditt konto. Se Vad är Unity Catalog? och Rekommendationer för att använda externa platser.
Information om hur du konfigurerar alla SQL-lager med hjälp av REST-API:et finns i SQL Warehouses API.
Viktigt!
Om du ändrar de här inställningarna startas alla SQL-lager som körs om.
En allmän översikt över hur du aktiverar åtkomst till data finns i Åtkomstkontrollistor.
Krav
- Du måste vara administratör för Azure Databricks-arbetsytan för att konfigurera inställningar för alla SQL-lager.
Konfigurera ett huvudnamn för tjänsten
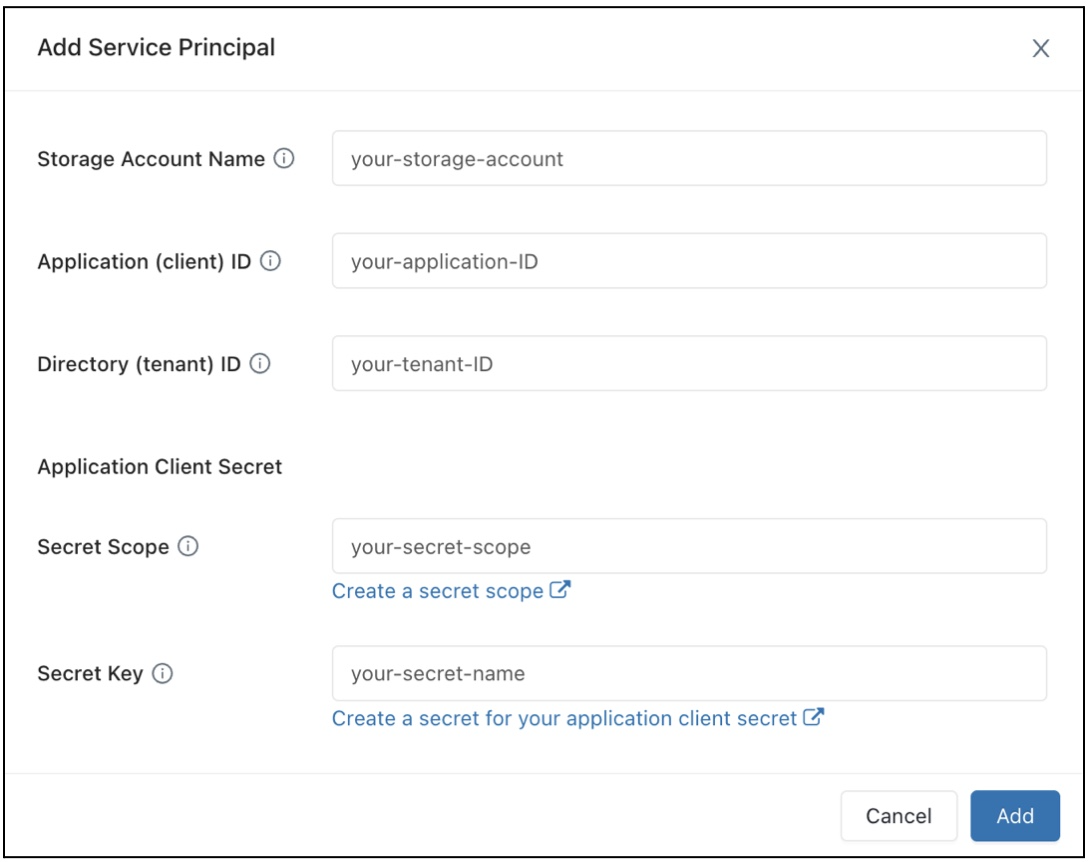
Följ dessa steg för att konfigurera åtkomst för dina SQL-lager till ett Azure Data Lake Storage Gen2-lagringskonto med hjälp av tjänstens huvudnamn:
Registrera ett Microsoft Entra-ID (tidigare Azure Active Directory) och registrera följande egenskaper:
- Program-ID (klient): Ett ID som unikt identifierar Microsoft Entra-ID:t (tidigare Azure Active Directory).
- Katalog-ID (klientorganisation): Ett ID som unikt identifierar Microsoft Entra ID-instansen (kallas katalog-ID (klientorganisation) i Azure Databricks).
- Klienthemlighet: Värdet för en klienthemlighet som skapats för den här programregistreringen. Programmet använder den här hemliga strängen för att bevisa sin identitet.
På ditt lagringskonto lägger du till en rolltilldelning för programmet som registrerades i föregående steg för att ge det åtkomst till lagringskontot.
Skapa ett Azure Key Vault-säkerhetskopierat hemligt omfång eller ett Databricks-omfångsbegränsat hemlighetsomfång och registrera värdet för egenskapen omfångsnamn:
- Omfångsnamn: Namnet på det skapade hemliga omfånget.
Om du använder Azure Key Vault går du till avsnittet Hemligheter och Se Skapa en hemlighet i ett Azure Key Vault-backat omfång. Använd sedan den "klienthemlighet" som du fick i steg 1 för att fylla i fältet "värde" i den här hemligheten. Föra ett register över det hemliga namn som du precis valde.
- Hemligt namn: Namnet på den skapade Azure Key Vault-hemligheten.
Om du använder ett Databricks-säkerhetskopierat omfång skapar du en ny hemlighet med Hjälp av Databricks CLI och använder den för att lagra den klienthemlighet som du har fått i steg 1. Behåll en post för den hemliga nyckel som du angav i det här steget.
- Hemlig nyckel: Nyckeln för den databricks-säkerhetskopierade hemligheten som skapats.
Kommentar
Du kan också skapa ytterligare en hemlighet för att lagra klient-ID:t som erhölls i steg 1.
Klicka på ditt användarnamn i arbetsytans övre stapel och välj Inställningar i listrutan.
Klicka på fliken Beräkning .
Klicka på Hantera bredvid SQL-lager.
I fältet Konfiguration av dataåtkomst klickar du på knappen Lägg till tjänstens huvudnamn .
Konfigurera egenskaperna för ditt Azure Data Lake Storage Gen2-lagringskonto.
Klicka på Lägg till.
Du ser att nya poster har lagts till i textrutan Konfiguration av dataåtkomst.
Klicka på Spara.
Du kan också redigera textrutan Data Access Configuration direkt.
Konfigurera dataåtkomstegenskaper för SQL-lager
Så här konfigurerar du alla lager med dataåtkomstegenskaper:
Klicka på ditt användarnamn i arbetsytans övre stapel och välj Inställningar i listrutan.
Klicka på fliken Beräkning .
Klicka på Hantera bredvid SQL-lager.
I textrutan Konfiguration av dataåtkomst anger du nyckel/värde-par som innehåller metaarkivegenskaper.
Viktigt!
Om du vill ange en Spark-konfigurationsegenskap till värdet för en hemlighet utan att exponera det hemliga värdet för Spark anger du värdet till
{{secrets/<secret-scope>/<secret-name>}}. Ersätt<secret-scope>med hemlighetsomfånget och<secret-name>med det hemliga namnet. Värdet måste börja med{{secrets/och sluta med}}. Mer information om den här syntaxen finns i Syntax för att referera till hemligheter i en Spark-konfigurationsegenskap eller miljövariabel.Klicka på Spara.
Du kan också konfigurera dataåtkomstegenskaper med databricks Terraform-providern och databricks_sql_global_config.
Egenskaper som stöds
För en post som slutar med
*stöds alla egenskaper inom prefixet.Indikerar till exempel
spark.sql.hive.metastore.*att bådespark.sql.hive.metastore.jarsochspark.sql.hive.metastore.versionstöds och andra egenskaper som börjar medspark.sql.hive.metastore.För egenskaper vars värden innehåller känslig information kan du lagra känslig information i en hemlighet och ange egenskapens värde till det hemliga namnet med hjälp av följande syntax:
secrets/<secret-scope>/<secret-name>.
Följande egenskaper stöds för SQL-lager:
spark.sql.hive.metastore.*spark.sql.warehouse.dirspark.hadoop.datanucleus.*spark.hadoop.fs.*spark.hadoop.hive.*spark.hadoop.javax.jdo.option.*spark.hive.*
Mer information om hur du anger dessa egenskaper finns i Externt Hive-metaarkiv.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för