Dataobjekt i Databricks lakehouse
Databricks lakehouse organiserar data som lagras med Delta Lake i molnobjektlagring med välbekanta relationer som databas, tabeller och vyer. Den här modellen kombinerar många av fördelarna med ett informationslager för företag med skalbarhet och flexibilitet för en datasjö. Läs mer om hur den här modellen fungerar och relationen mellan objektdata och metadata så att du kan använda metodtips när du utformar och implementerar Databricks lakehouse för din organisation.
Vilka dataobjekt finns i Databricks lakehouse?
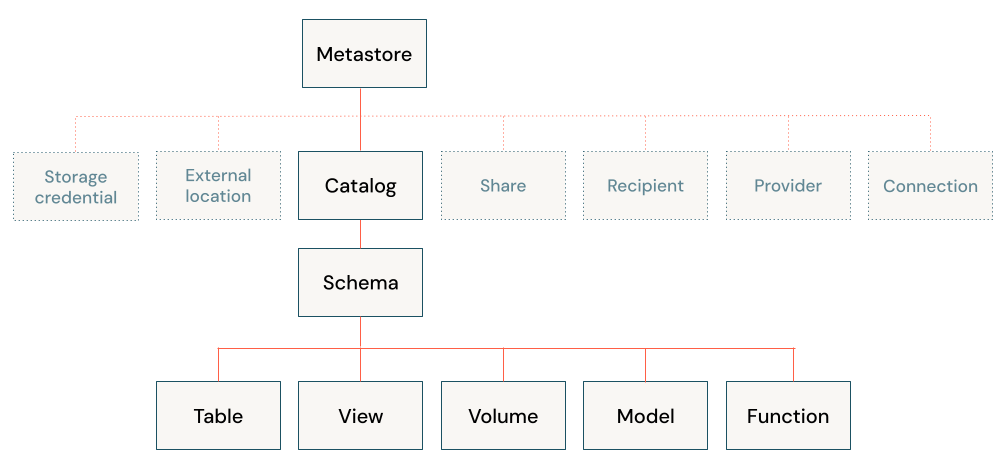
Databricks lakehouse-arkitekturen kombinerar data som lagras med Delta Lake-protokollet i molnobjektlagring med metadata som är registrerade i ett metaarkiv. Det finns fem primära objekt i Databricks lakehouse:
- Katalog: en gruppering av databaser.
- Databas eller schema: en gruppering av objekt i en katalog. Databaser innehåller tabeller, vyer och funktioner.
- Tabell: en samling rader och kolumner som lagras som datafiler i objektlagring.
- Vy: en sparad fråga vanligtvis mot en eller flera tabeller eller datakällor.
- Funktion: sparad logik som returnerar ett skalärt värde eller en uppsättning rader.
Information om hur du skyddar objekt med Unity Catalog finns i modellen för skyddsbara objekt.
Vad är ett metaarkiv?
Metaarkivet innehåller alla metadata som definierar dataobjekt i lakehouse. Azure Databricks innehåller följande metaarkivalternativ:
Unity Catalog-metaarkiv: Unity Catalog tillhandahåller centraliserade funktioner för åtkomstkontroll, granskning, ursprung och dataidentifiering. Du skapar Unity Catalog-metaarkiv på Azure Databricks-kontonivå och ett enda metaarkiv kan användas på flera arbetsytor.
Varje Unity Catalog-metaarkiv konfigureras med en rotlagringsplats i en Azure Data Lake Storage Gen2-container i ditt Azure-konto. Den här lagringsplatsen används som standard för att lagra data för hanterade tabeller.
I Unity Catalog är data säkra som standard. Inledningsvis har användarna ingen åtkomst till data i ett metaarkiv. Åtkomst kan beviljas av antingen en metaarkivadministratör eller ägaren av ett objekt. Skyddsbara objekt i Unity-katalogen är hierarkiska och privilegierna ärvs nedåt. Unity Catalog erbjuder en enda plats för att administrera dataåtkomstprinciper. Användare kan komma åt data i Unity Catalog från alla arbetsytor som metaarkivet är kopplat till. Mer information finns i Hantera privilegier i Unity Catalog.
Inbyggt Hive-metaarkiv (äldre): Varje Azure Databricks-arbetsyta innehåller ett inbyggt Hive-metaarkiv som en hanterad tjänst. En instans av metaarkivet distribueras till varje kluster och får säker åtkomst till metadata från en central lagringsplats för varje kundarbetsyta.
Hive-metaarkivet tillhandahåller en mindre centraliserad datastyrningsmodell än Unity Catalog. Som standard tillåter ett kluster alla användare att komma åt alla data som hanteras av arbetsytans inbyggda Hive-metaarkiv om inte tabellåtkomstkontroll är aktiverad för klustret. Mer information finns i Åtkomstkontroll för Hive-metaarkivtabell (äldre).
Tabellåtkomstkontroller lagras inte på kontonivå och därför måste de konfigureras separat för varje arbetsyta. För att dra nytta av den centraliserade och strömlinjeformade datastyrningsmodellen som tillhandahålls av Unity Catalog rekommenderar Databricks att du uppgraderar tabellerna som hanteras av arbetsytans Hive-metaarkiv till Unity Catalog-metaarkivet.
Externt Hive-metaarkiv (äldre): Du kan också ta med ditt eget metaarkiv till Azure Databricks. Azure Databricks-kluster kan ansluta till befintliga externa Apache Hive-metaarkiv. Du kan använda tabellåtkomstkontroll för att hantera behörigheter i ett externt metaarkiv. Tabellåtkomstkontroller lagras inte i det externa metaarkivet, och därför måste de konfigureras separat för varje arbetsyta. Databricks rekommenderar att du använder Unity Catalog i stället för dess enkelhet och kontocentrerade styrningsmodell.
Oavsett vilket metaarkiv du använder lagrar Azure Databricks alla tabelldata i objektlagring i ditt molnkonto.
Vad är en katalog?
En katalog är den högsta abstraktionen (eller det grovaste kornet) i relationsmodellen Databricks lakehouse. Varje databas kommer att associeras med en katalog. Kataloger finns som objekt i ett metaarkiv.
Innan Unity Catalog introducerades använde Azure Databricks ett namnområde på två nivåer. Kataloger är den tredje nivån i unity-katalogens namnavståndsmodell:
catalog_name.database_name.table_name
Det inbyggda Hive-metaarkivet stöder bara en enda katalog, hive_metastore.
Vad är en databas?
En databas är en samling dataobjekt, till exempel tabeller eller vyer (kallas även "relationer") och funktioner. I Azure Databricks används termerna "schema" och "databas" omväxlande (medan en databas i många relationssystem är en samling scheman).
Databaser kommer alltid att associeras med en plats i molnobjektlagring. Du kan också ange en LOCATION när du registrerar en databas, med följande i åtanke:
- Den
LOCATIONassocierade med en databas betraktas alltid som en hanterad plats. - När du skapar en databas skapas inga filer på målplatsen.
- För
LOCATIONen databas avgörs standardplatsen för data för alla tabeller som är registrerade i databasen. - Om du släpper en databas tas alla data och filer som lagras på en hanterad plats rekursivt bort.
Den här interaktionen mellan platser som hanteras av databas- och datafiler är mycket viktig. Så här undviker du att ta bort data av misstag:
- Dela inte databasplatser mellan flera databasdefinitioner.
- Registrera inte en databas på en plats som redan innehåller data.
- Om du vill hantera datalivscykeln oberoende av databasen sparar du data på en plats som inte är kapslad under några databasplatser.
Vad är en tabell?
En Azure Databricks-tabell är en samling strukturerade data. En Delta-tabell lagrar data som en katalog med filer i molnobjektlagring och registrerar tabellmetadata till metaarkivet i en katalog och ett schema. Eftersom Delta Lake är standardlagringsprovidern för tabeller som skapats i Azure Databricks är alla tabeller som skapats i Databricks Delta-tabeller som standard. Eftersom Delta-tabeller lagrar data i molnobjektlagring och tillhandahåller referenser till data via ett metaarkiv kan användare i en organisation komma åt data med hjälp av sina önskade API:er. i Databricks omfattar detta SQL, Python, PySpark, Scala och R.
Observera att det är möjligt att skapa tabeller på Databricks som inte är Delta-tabeller. Dessa tabeller backas inte upp av Delta Lake och tillhandahåller inte ACID-transaktioner och optimerade prestanda för Delta-tabeller. Tabeller som ingår i den här kategorin inkluderar tabeller som registrerats mot data i externa system och tabeller som registrerats mot andra filformat i datasjön. Se Anslut till datakällor.
Det finns två typer av tabeller i Databricks, hanterade och ohanterade (eller externa) tabeller.
Kommentar
Skillnaden mellan livetabeller och strömmande livetabeller tillämpas inte ur tabellperspektiv.
Vad är en hanterad tabell?
Azure Databricks hanterar både metadata och data för en hanterad tabell. När du släpper en tabell tar du också bort underliggande data. Dataanalytiker och andra användare som främst arbetar i SQL kanske föredrar det här beteendet. Hanterade tabeller är standard när du skapar en tabell. Data för en hanterad tabell finns i den LOCATION databas som den är registrerad på. Den här hanterade relationen mellan dataplatsen och databasen innebär att du måste skriva om alla data till den nya platsen för att kunna flytta en hanterad tabell till en ny databas.
Det finns ett antal sätt att skapa hanterade tabeller, bland annat:
CREATE TABLE table_name AS SELECT * FROM another_table
CREATE TABLE table_name (field_name1 INT, field_name2 STRING)
df.write.saveAsTable("table_name")
Vad är en ohanterad tabell?
Azure Databricks hanterar endast metadata för ohanterade (externa) tabeller. När du släpper en tabell påverkar du inte underliggande data. Ohanterade tabeller anger alltid en LOCATION när tabellen skapas. Du kan antingen registrera en befintlig katalog med datafiler som en tabell eller ange en sökväg när en tabell först definieras. Eftersom data och metadata hanteras oberoende av varandra kan du byta namn på en tabell eller registrera den till en ny databas utan att behöva flytta några data. Datatekniker föredrar ofta ohanterade tabeller och den flexibilitet de tillhandahåller för produktionsdata.
Det finns ett antal sätt att skapa ohanterade tabeller, bland annat:
CREATE TABLE table_name
USING DELTA
LOCATION '/path/to/existing/data'
CREATE TABLE table_name
(field_name1 INT, field_name2 STRING)
LOCATION '/path/to/empty/directory'
df.write.option("path", "/path/to/empty/directory").saveAsTable("table_name")
Vad är en vy?
En vy lagrar texten för en fråga vanligtvis mot en eller flera datakällor eller tabeller i metaarkivet. I Databricks motsvarar en vy en Spark DataFrame som sparats som ett objekt i en databas. Till skillnad från DataFrames kan du fråga vyer från vilken del av Databricks-produkten som helst, förutsatt att du har behörighet att göra det. När du skapar en vy bearbetas eller skrivs inga data. endast frågetexten är registrerad i metaarkivet i den associerade databasen.
Vad är en tillfällig vy?
En tillfällig vy har ett begränsat omfång och beständighet och är inte registrerad i ett schema eller en katalog. Livslängden för en tillfällig vy skiljer sig beroende på vilken miljö du använder:
- I notebook-filer och jobb begränsas tillfälliga vyer till notebook- eller skriptnivå. De kan inte refereras utanför anteckningsboken där de deklareras och kommer inte längre att finnas när notebook-filen kopplas från klustret.
- I Databricks SQL begränsas tillfälliga vyer till frågenivån. Flera instruktioner i samma fråga kan använda vyn temp, men det kan inte refereras till i andra frågor, inte ens på samma instrumentpanel.
- Globala tillfälliga vyer är begränsade till klusternivå och kan delas mellan notebook-filer eller jobb som delar databehandlingsresurser. Databricks rekommenderar att du använder vyer med lämpliga tabell-ACL:er i stället för globala tillfälliga vyer.
Vad är en funktion?
Med funktioner kan du associera användardefinierad logik med en databas. Funktioner kan returnera antingen skalära värden eller uppsättningar med rader. Funktioner används för att aggregera data. Med Azure Databricks kan du spara funktioner på olika språk beroende på din körningskontext, och SQL stöds i stort sett. Du kan använda funktioner för att ge hanterad åtkomst till anpassad logik i en mängd olika kontexter på Databricks-produkten.
Hur fungerar relationsobjekt i Delta Live Tables?
Delta Live Tables använder deklarativ syntax för att definiera och hantera DDL-, DML- och infrastrukturdistribution. Delta Live Tables använder begreppet "virtuellt schema" under logikplanering och körning. Delta Live Tables kan interagera med andra databaser i Din Databricks-miljö, och Delta Live Tables kan publicera och spara tabeller för att fråga någon annanstans genom att ange en måldatabas i konfigurationsinställningarna för pipelinen.
Alla tabeller som skapas i Delta Live Tables är Delta-tabeller. När du använder Unity Catalog med Delta Live Tables är alla tabeller hanterade tabeller i Unity Catalog. Om Unity Catalog inte är aktivt kan tabeller deklareras som antingen hanterade eller ohanterade tabeller.
Även om vyer kan deklareras i Delta Live Tables bör dessa betraktas som tillfälliga vyer som är begränsade till pipelinen. Temporära tabeller i Delta Live Tables är ett unikt begrepp: dessa tabeller bevarar data till lagring men publicerar inte data till måldatabasen.
Vissa åtgärder, till exempel APPLY CHANGES INTO, registrerar både en tabell och vy i databasen. Tabellnamnet börjar med ett understreck (_) och vyn har tabellnamnet deklarerat som målet för APPLY CHANGES INTO åtgärden. Vyn frågar motsvarande dolda tabell för att materialisera resultatet.