Utdata och resultat för notebook-filer
När du har bifogat en notebook-fil till ett kluster och kört en eller flera celler har anteckningsboken tillstånd och visar utdata. I det här avsnittet beskrivs hur du hanterar notebook-tillstånd och utdata.
Rensa notebooks-tillstånd och utdata
Om du vill rensa anteckningsbokens tillstånd och utdata väljer du något av alternativen Rensa längst ned på Menyn Kör .
| Menyalternativ | beskrivning |
|---|---|
| Rensa alla cellutdata | Rensar cellutdata. Det här är användbart om du delar anteckningsboken och inte vill ta med några resultat. |
| Rensa tillstånd | Rensar notebook-tillståndet, inklusive funktions- och variabeldefinitioner, data och importerade bibliotek. |
| Rensa tillstånd och utdata | Rensar både cellutdata och notebook-tillståndet. |
| Rensa tillstånd och kör alla | Rensar notebook-tillståndet och startar en ny körning. |
Visa resultat
När en cell körs returnerar tabellresultaten högst 10 000 rader eller 2 MB, beroende på vilket som är mindre.
Som standard returnerar textresultatet högst 50 000 tecken. Med Databricks Runtime 12.2 LTS och senare kan du öka den här gränsen genom att ange spark-konfigurationsegenskapen spark.databricks.driver.maxReplOutputLength.
Utforska SQL-cellresultat i Python-notebook-filer internt med hjälp av Python
Du kan läsa in data med HJÄLP av SQL och utforska dem med hjälp av Python. I en Databricks Python-notebook-fil görs tabellresultat från en SQL-språkcell automatiskt tillgängliga som en Python DataFrame. Mer information finns i Utforska SQL-cellresultat i Python-notebook-filer.
Resultattabell för ny cell
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Nu kan du välja en ny cellresultattabellåtergivning. Med den nya resultattabellen kan du göra följande:
- Kopiera en kolumn eller en annan delmängd av tabellresultatet till Urklipp.
- Gör en textsökning över resultattabellen.
- Sortera och filtrera data.
- Navigera mellan tabellceller med hjälp av tangentbordspiltangenterna.
- Välj en del av ett kolumnnamn eller cellvärde genom att dubbelklicka och dra för att markera önskad text.
Om du vill aktivera den nya resultattabellen klickar du på Ny resultattabell i det övre högra hörnet av cellresultatet och ändrar växlingsväljaren från AV till PÅ.
När funktionen är aktiverad kan du klicka på kolumn- eller radrubriker för att välja hela kolumner eller rader, och du kan klicka i den övre vänstra cellen i tabellen för att välja hela tabellen. Du kan dra markören över valfri rektangulär uppsättning celler för att markera dem.
Om du vill kopiera markerade data till Urklipp trycker du Cmd + c på MacOS eller Ctrl + c i Windows, eller högerklickar och väljer Kopiera på den nedrullningsbara menyn.
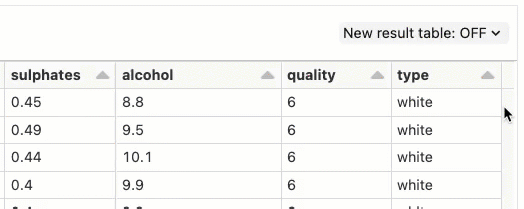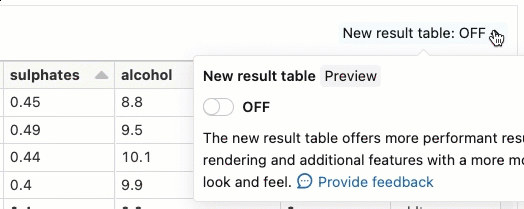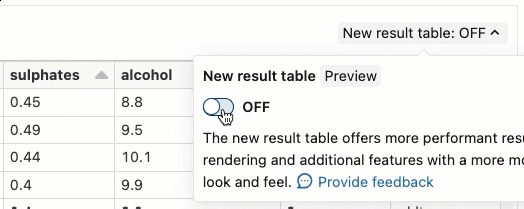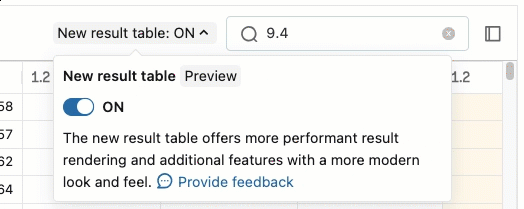
Om du vill söka efter text i resultattabellen anger du texten i sökrutan. Matchande celler är markerade.
Om du vill öppna en sidopanel som visar information om markeringen klickar du på panelikonen ![]() i det övre högra hörnet bredvid sökrutan.
i det övre högra hörnet bredvid sökrutan.
![]()
Kolumnrubriker anger kolumnens datatyp. Anger till exempel  heltalsdatatyp. Hovra över indikatorn för att se datatypen.
heltalsdatatyp. Hovra över indikatorn för att se datatypen.
Sortera och filtrera resultat
När du använder den nya cellresultattabellen kan du sortera och filtrera resultat.
Om du vill sortera tabellen efter värdena i en kolumn hovra markören över kolumnnamnet. Till höger om cellen som innehåller kolumnnamnet visas en ikon. Klicka på pilen för att sortera kolumnen. Efterföljande klick växlar mellan sortering i stigande ordning, fallande ordning eller osorterad.

Om du vill sortera efter flera kolumner håller du ned Skift-tangenten när du klickar på sorteringspilen för kolumnerna.
Om du vill skapa ett filter klickar du ![]() längst upp till höger i cellresultatet. I dialogrutan som visas väljer du den kolumn som ska filtreras på och filterregeln och värdet som ska tillämpas. Till exempel:
längst upp till höger i cellresultatet. I dialogrutan som visas väljer du den kolumn som ska filtreras på och filterregeln och värdet som ska tillämpas. Till exempel:
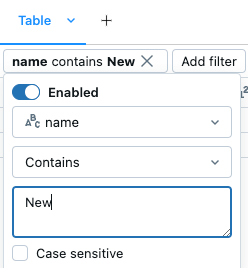
Om du vill lägga till ytterligare ett filter klickar du på  .
.
Om du tillfälligt vill aktivera eller inaktivera ett filter ändrar du knappen Aktiverad/Inaktiverad i dialogrutan. Om du vill ta bort ett filter klickar du på X bredvid filternamnet  .
.
Om du vill filtrera efter ett visst värde högerklickar du på en cell med det värdet och väljer Filtrera efter det här värdet i den nedrullningsbara menyn.
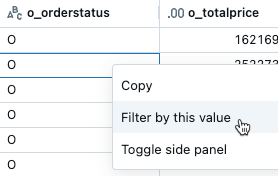
Du kan också skapa ett filter från menyn för kebab i kolumnnamnet:
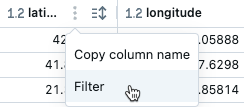
Filter tillämpas endast på de resultat som visas i resultattabellen. Om data som returneras trunkeras (till exempel när en fråga returnerar fler än 64 000 rader) tillämpas filtret endast på de returnerade raderna.
Hämta resultat
Som standard är nedladdning av resultat aktiverat. Om du vill växla den här inställningen läser du Hantera möjligheten att ladda ned resultat från notebook-filer.
Du kan ladda ned ett cellresultat som innehåller tabellutdata till den lokala datorn. Klicka på den nedåtriktade pilen bredvid flikens rubrik. Menyalternativen beror på antalet rader i resultatet och på Databricks Runtime-versionen. Nedladdade resultat sparas på den lokala datorn som en CSV-fil med namnet export.csv.
Visa flera utdata per cell
Python-notebook-filer och %python -celler i icke-Python-notebook-filer stöder flera utdata per cell. Till exempel innehåller utdata från följande kod både diagrammet och tabellen:
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
iris = pd.DataFrame(data=data.data, columns=data.feature_names)
ax = iris.plot()
print("plot")
display(ax)
print("data")
display(iris)
Checka in notebook-utdata i Databricks Git-mappar
Mer information om hur du checkar in .ipynb notebook-utdata finns i Tillåt incheckning av .ipynb notebook-utdata.
- Notebook-filen måste vara en .ipynb-fil
- Administratörsinställningarna för arbetsytan måste tillåta att notebook-utdata checkas in.