2018 juni
Dessa funktioner och förbättringar av Databricks-plattformen släpptes i juni 2018.
RStudio-integrering
19 juni 2018: Version 2.74
Azure Databricks integreras nu med RStudio Server, den populära IDE för R. Med den här kraftfulla nya integreringen kan du:
- Starta RStudio-användargränssnittet direkt från Azure Databricks.
- Importera SparkR- och sparklyr-paket i RStudio IDE.
- Få åtkomst till, utforska och transformera stora datamängder från RStudio IDE med Apache Spark.
- Köra och övervaka Spark-jobb i ett Azure Databricks-kluster.
- Hantera din kod med hjälp av versionskontroll.
- Använd antingen open source- eller Pro-utgåvorna av RStudio Server på Azure Databricks.
RStudio-integrering kräver Premium-planen. Du måste installera integreringen i ett kluster med hög samtidighet. Mer information finns i RStudio på Azure Databricks.
Rensning av klusterlogg
19 juni 2018: Version 2.74
Som standard behålls klusterloggar i 30 dagar. Du kan nu ta bort dem permanent och omedelbart genom att gå till fliken Lagring av arbetsyta i administratörskonsolen. Se Rensa arbetsytelagring.
Nya regioner
den 7 juni 2018
Azure Databricks är nu tillgängligt i följande regioner:
- Australien, östra
- Sydöstra Australien
- Storbritannien, södra
- Storbritannien, västra
Papperskorgsmapp
7 juni 2018: Version 2.73
En ny ![]() papperskorg innehåller alla notebook-filer, bibliotek och mappar som du har tagit bort. Papperskorgen rensas automatiskt efter 30 dagar. Du kan återställa ett borttaget objekt genom att dra det från papperskorgen till en annan mapp.
papperskorg innehåller alla notebook-filer, bibliotek och mappar som du har tagit bort. Papperskorgen rensas automatiskt efter 30 dagar. Du kan återställa ett borttaget objekt genom att dra det från papperskorgen till en annan mapp.
Mer information finns i Ta bort ett objekt.
Minskad kvarhållningsperiod för loggar
7 juni 2018: Version 2.73
Klusterloggar behålls nu i 30 dagar. De brukade behållas på obestämd tid.
Gzip-komprimerade API-svar
7 juni 2018: Version 2.73
Begäranden som skickas med Accept-Encoding: gzip rubriken returnerar gzipped-svar.
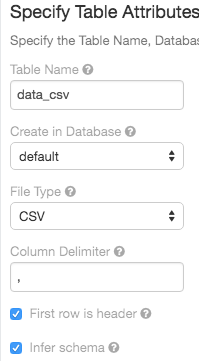
Användargränssnitt för tabellimport
7 juni 2018: Version 2.73
Användargränssnittet för skapa tabell stöder nu ett alternativ för att härleda schemat för CSV-filer: