Delta table streaming reads and writes
Delta Lake är djupt integrerat med Spark Structured Streaming via readStream och writeStream. Delta Lake övervinner många av de begränsningar som vanligtvis är associerade med strömningssystem och filer, inklusive:
- Sammansejsa små filer som genereras av inmatning med låg svarstid.
- Underhåll av "exakt en gång"-bearbetning med mer än en ström (eller samtidiga batchjobb).
- Identifiera effektivt vilka filer som är nya när du använder filer som källa för en dataström.
Kommentar
Den här artikeln beskriver hur du använder Delta Lake-tabeller som strömmande källor och mottagare. Information om hur du läser in data med hjälp av strömmande tabeller i Databricks SQL finns i Läsa in data med hjälp av strömmande tabeller i Databricks SQL.
Deltatabell som källa
Strukturerad direktuppspelning läser inkrementellt Delta-tabeller. Medan en direktuppspelningsfråga är aktiv mot en Delta-tabell bearbetas nya poster idempotently när nya tabellversioner checkas in i källtabellen.
I följande kodexempel visas hur du konfigurerar en direktuppspelningsläsning med antingen tabellnamnet eller filsökvägen.
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Viktigt!
Om schemat för en Delta-tabell ändras efter att en direktuppspelningsläsning börjar mot tabellen misslyckas frågan. För de flesta schemaändringar kan du starta om strömmen för att lösa matchningsfel för schema och fortsätta bearbetningen.
I Databricks Runtime 12.2 LTS och nedan kan du inte strömma från en Delta-tabell med kolumnmappning aktiverat som har genomgått icke-additiv schemautveckling som att byta namn på eller släppa kolumner. Mer information finns i Strömning med kolumnmappning och schemaändringar.
Begränsa indatahastighet
Följande alternativ är tillgängliga för att styra mikrobatch:
maxFilesPerTrigger: Hur många nya filer som ska beaktas i varje mikrobatch. Standardvärdet är 1000.maxBytesPerTrigger: Hur mycket data som bearbetas i varje mikrobatch. Det här alternativet anger ett "mjukt maxvärde", vilket innebär att en batch bearbetar ungefär den här mängden data och kan bearbeta mer än gränsen för att få strömningsfrågan att gå framåt i de fall då den minsta indataenheten är större än den här gränsen. Detta anges inte som standard.
Om du använder maxBytesPerTrigger tillsammans med maxFilesPerTriggerbearbetar mikrobatchdata tills antingen maxFilesPerTrigger gränsen eller maxBytesPerTrigger har nåtts.
Kommentar
I de fall då källtabelltransaktionerna rensas på grund av konfigurationen logRetentionDuration och strömningsfrågan försöker bearbeta dessa versioner kan frågan som standard inte undvika dataförlust. Du kan ange alternativet failOnDataLoss för att false ignorera förlorade data och fortsätta bearbetningen.
Strömma ett CDC-flöde (Change Data Capture) i Delta Lake
Delta Lake ändrar dataflödesposter ändringar i en Delta-tabell, inklusive uppdateringar och borttagningar. När du är aktiverad kan du strömma från en ändringsdatafeed och skriva logik för att bearbeta infogningar, uppdateringar och borttagningar i underordnade tabeller. Även om datautdata för ändringsdataflöde skiljer sig något från deltatabellen som beskrivs, ger detta en lösning för att sprida inkrementella ändringar till underordnade tabeller i en medaljongarkitektur.
Viktigt!
I Databricks Runtime 12.2 LTS och nedan kan du inte strömma från ändringsdataflödet för en Delta-tabell med kolumnmappning aktiverat som har genomgått icke-additiv schemautveckling, till exempel byta namn på eller ta bort kolumner. Mer information finns i Strömning med kolumnmappning och schemaändringar.
Ignorera uppdateringar och borttagningar
Strukturerad direktuppspelning hanterar inte indata som inte är ett tillägg och genererar ett undantag om några ändringar sker i tabellen som används som källa. Det finns två huvudsakliga strategier för att hantera ändringar som inte kan spridas automatiskt nedströms:
- Du kan ta bort utdata och kontrollpunkter och starta om strömmen från början.
- Du kan ange något av följande två alternativ:
ignoreDeletes: ignorera transaktioner som tar bort data vid partitionsgränser.skipChangeCommits: ignorera transaktioner som tar bort eller ändrar befintliga poster.skipChangeCommitsundersummorignoreDeletes.
Kommentar
I Databricks Runtime 12.2 LTS och senare skipChangeCommits inaktuella föregående inställning ignoreChanges. I Databricks Runtime 11.3 LTS och lägre ignoreChanges är det enda alternativet som stöds.
Semantiken för ignoreChanges skiljer sig mycket från skipChangeCommits. Med ignoreChanges aktiverad genereras omskrivna datafiler i källtabellen igen efter en dataändringsåtgärd som UPDATE, MERGE INTO, DELETE (inom partitioner) eller OVERWRITE. Oförändrade rader genereras ofta tillsammans med nya rader, så nedströmsanvändare måste kunna hantera dubbletter. Borttagningar sprids inte nedströms. ignoreChanges undersummor ignoreDeletes.
skipChangeCommits ignorerar filändringsåtgärder helt och hållet. Datafiler som skrivs om i källtabellen på grund av dataändringsåtgärder som UPDATE, MERGE INTO, DELETEoch OVERWRITE ignoreras helt. För att återspegla ändringar i uppströms källtabeller måste du implementera separat logik för att sprida dessa ändringar.
Arbetsbelastningar som konfigurerats med ignoreChanges fortsätter att fungera med hjälp av kända semantik, men Databricks rekommenderar att du använder skipChangeCommits för alla nya arbetsbelastningar. Att migrera arbetsbelastningar med till ignoreChangesskipChangeCommits kräver refaktoriseringslogik.
Exempel
Anta till exempel att du har en tabell user_events med date, user_emailoch action kolumner som partitioneras av date. Du strömmar ut ur user_events tabellen och måste ta bort data från den på grund av GDPR.
När du tar bort vid partitionsgränser (dvs WHERE . är på en partitionskolumn) segmenteras filerna redan efter värde, så borttagningen släpper bara dessa filer från metadata. När du tar bort en hel partition med data kan du använda följande:
spark.readStream.format("delta")
.option("ignoreDeletes", "true")
.load("/tmp/delta/user_events")
Om du tar bort data i flera partitioner (i det här exemplet filtrering på user_email) använder du följande syntax:
spark.readStream.format("delta")
.option("skipChangeCommits", "true")
.load("/tmp/delta/user_events")
Om du uppdaterar en user_email med -instruktionen UPDATE skrivs filen som innehåller den user_email aktuella filen om. Använd skipChangeCommits för att ignorera de ändrade datafilerna.
Ange inledande position
Du kan använda följande alternativ för att ange startpunkten för Delta Lake-strömningskällan utan att bearbeta hela tabellen.
startingVersion: Delta Lake-versionen att börja från. Databricks rekommenderar att du utelämnar det här alternativet för de flesta arbetsbelastningar. När den inte har angetts startar strömmen från den senaste tillgängliga versionen, inklusive en fullständig ögonblicksbild av tabellen vid den tidpunkten.Om det anges läser strömmen alla ändringar i Delta-tabellen från och med den angivna versionen (inklusive). Om den angivna versionen inte längre är tillgänglig startar inte strömmen. Du kan hämta incheckningsversionerna
versionfrån kolumnen i kommandoutdata för DESCRIBE HISTORY .Om du bara vill returnera de senaste ändringarna anger du
latest.startingTimestamp: Tidsstämpeln som ska startas från. Alla tabelländringar som har checkats in vid eller efter tidsstämpeln (inklusive) läss av den strömmande läsaren. Om den angivna tidsstämpeln föregår alla tabellincheckningar börjar strömningsläsningen med den tidigaste tillgängliga tidsstämpeln. En av:- En tidsstämpelsträng. Exempel:
"2019-01-01T00:00:00.000Z" - En datumsträng. Exempel:
"2019-01-01"
- En tidsstämpelsträng. Exempel:
Du kan inte ange båda alternativen samtidigt. De börjar gälla endast när du startar en ny direktuppspelningsfråga. Om en direktuppspelningsfråga har startats och förloppet har registrerats i kontrollpunkten ignoreras dessa alternativ.
Viktigt!
Även om du kan starta strömningskällan från en angiven version eller tidsstämpel är schemat för strömningskällan alltid det senaste schemat i Delta-tabellen. Du måste se till att det inte finns någon inkompatibel schemaändring i Delta-tabellen efter den angivna versionen eller tidsstämpeln. Annars kan strömningskällan returnera felaktiga resultat när data läss med ett felaktigt schema.
Exempel
Anta till exempel att du har en tabell user_events. Om du vill läsa ändringar sedan version 5 använder du:
spark.readStream.format("delta")
.option("startingVersion", "5")
.load("/tmp/delta/user_events")
Om du vill läsa ändringar sedan 2018-10-18 använder du:
spark.readStream.format("delta")
.option("startingTimestamp", "2018-10-18")
.load("/tmp/delta/user_events")
Bearbeta den första ögonblicksbilden utan att data tas bort
Kommentar
Den här funktionen är tillgänglig på Databricks Runtime 11.3 LTS och senare. Den här funktionen finns som allmänt tillgänglig förhandsversion.
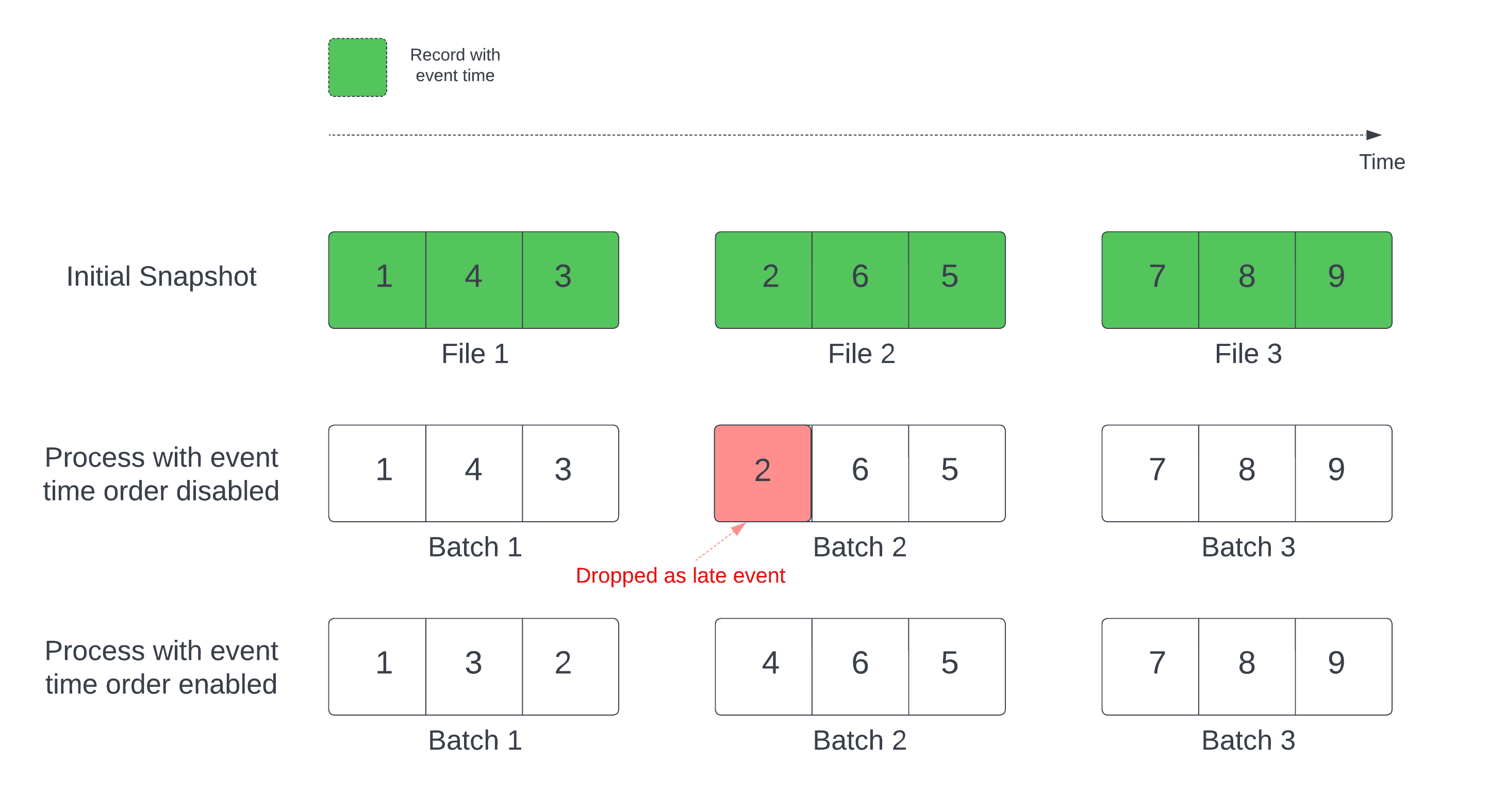
När du använder en Delta-tabell som en dataströmkälla bearbetar frågan först alla data som finns i tabellen. Delta-tabellen i den här versionen kallas den första ögonblicksbilden. Som standard bearbetas Delta-tabellens datafiler baserat på vilken fil som senast ändrades. Den senaste ändringstiden representerar dock inte nödvändigtvis posthändelsens tidsordning.
I en tillståndskänslig strömningsfråga med en definierad vattenstämpel kan bearbetning av filer efter ändringstid leda till att poster bearbetas i fel ordning. Detta kan leda till att poster släpps som sena händelser av vattenstämpeln.
Du kan undvika problemet med dataminskningen genom att aktivera följande alternativ:
- withEventTimeOrder: Om den första ögonblicksbilden ska bearbetas med händelsetidsordning.
När händelsetidsordningen är aktiverad delas händelsetidsintervallet för inledande ögonblicksbildsdata in i tids bucketar. Varje mikrobatch bearbetar en bucket genom att filtrera data inom tidsintervallet. Konfigurationsalternativen maxFilesPerTrigger och maxBytesPerTrigger är fortfarande tillämpliga för att styra mikrobatchstorleken, men endast på ett ungefärligt sätt på grund av bearbetningens natur.
Bilden nedan visar den här processen:
Viktig information om den här funktionen:
- Problemet med dataminskning sker bara när den första Delta-ögonblicksbilden av en tillståndskänslig direktuppspelningsfråga bearbetas i standardordningen.
- Du kan inte ändra
withEventTimeOrdernär dataströmfrågan har startats medan den första ögonblicksbilden fortfarande bearbetas. Om du vill starta om medwithEventTimeOrderändrat måste du ta bort kontrollpunkten. - Om du kör en dataströmfråga med medEventTimeOrder aktiverat kan du inte nedgradera den till en DBR-version som inte stöder den här funktionen förrän den första bearbetningen av ögonblicksbilder har slutförts. Om du behöver nedgradera kan du vänta tills den första ögonblicksbilden har slutförts eller ta bort kontrollpunkten och starta om frågan.
- Den här funktionen stöds inte i följande ovanliga scenarier:
- Händelsetidskolumnen är en genererad kolumn och det finns icke-projektiontransformeringar mellan Delta-källan och vattenstämpeln.
- Det finns en vattenstämpel som har mer än en Delta-källa i strömfrågan.
- När händelsetidsordningen är aktiverad kan prestandan för den inledande bearbetningen av deltaögonblicksbilder vara långsammare.
- Varje mikrobatch genomsöker den första ögonblicksbilden för att filtrera data inom motsvarande händelsetidsintervall. För snabbare filteråtgärd rekommenderar vi att du använder en deltakällkolumn som händelsetid så att datahoppning kan tillämpas (kontrollera datahopp för Delta Lake för när det är tillämpligt). Dessutom kan tabellpartitionering längs händelsetidskolumnen påskynda bearbetningen ytterligare. Du kan kontrollera Spark-användargränssnittet för att se hur många deltafiler som genomsöks efter en specifik mikrobatch.
Exempel
Anta att du har en tabell user_events med en event_time kolumn. Din direktuppspelningsfråga är en aggregeringsfråga. Om du vill se till att inga data släpps under den första bearbetningen av ögonblicksbilder kan du använda:
spark.readStream.format("delta")
.option("withEventTimeOrder", "true")
.load("/tmp/delta/user_events")
.withWatermark("event_time", "10 seconds")
Kommentar
Du kan också aktivera detta med Spark-konfiguration i klustret som gäller för alla strömmande frågor: spark.databricks.delta.withEventTimeOrder.enabled true
Deltatabell som mottagare
Du kan också skriva data till en Delta-tabell med strukturerad direktuppspelning. Transaktionsloggen gör det möjligt för Delta Lake att garantera bearbetning exakt en gång, även om det finns andra strömmar eller batchfrågor som körs samtidigt mot tabellen.
Kommentar
Funktionen Delta Lake VACUUM tar bort alla filer som inte hanteras av Delta Lake, men hoppar över alla kataloger som börjar med _. Du kan lagra kontrollpunkter på ett säkert sätt tillsammans med andra data och metadata för en Delta-tabell med hjälp av en katalogstruktur som <table-name>/_checkpoints.
Mått
Du kan ta reda på antalet byte och antalet filer som ännu inte har bearbetats i en strömmande frågeprocess som numBytesOutstanding mått och numFilesOutstanding . Ytterligare mått är:
numNewListedFiles: Antal Delta Lake-filer som listades för att beräkna kvarvarande uppgifter för den här batchen.backlogEndOffset: Den tabellversion som används för att beräkna kvarvarande uppgifter.
Om du kör dataströmmen i en notebook-fil kan du se dessa mått under fliken Rådata på instrumentpanelen för strömningsfrågans förlopp:
{
"sources" : [
{
"description" : "DeltaSource[file:/path/to/source]",
"metrics" : {
"numBytesOutstanding" : "3456",
"numFilesOutstanding" : "8"
},
}
]
}
Tilläggsläge
Som standard körs strömmar i tilläggsläge, vilket lägger till nya poster i tabellen.
Du kan använda sökvägsmetoden:
Python
(events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/_checkpoints/")
.start("/delta/events")
)
Scala
events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.start("/tmp/delta/events")
toTable eller -metoden enligt följande:
Python
(events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Fullständigt läge
Du kan också använda Structured Streaming för att ersätta hela tabellen med varje batch. Ett exempel på användningsfall är att beräkna en sammanfattning med aggregering:
Python
(spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
)
Scala
spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
I föregående exempel uppdateras kontinuerligt en tabell som innehåller det aggregerade antalet händelser per kund.
För program med mer överseende svarstidskrav kan du spara beräkningsresurser med engångsutlösare. Använd dessa för att uppdatera sammanfattningsaggregeringstabeller enligt ett visst schema och bearbeta endast nya data som har kommit sedan den senaste uppdateringen.
Utföra ström-statiska kopplingar
Du kan förlita dig på transaktionsgarantierna och versionsprotokollet för Delta Lake för att utföra ström-statiska kopplingar. En ström-statisk koppling kopplar den senaste giltiga versionen av en Delta-tabell (statiska data) till en dataström med hjälp av en tillståndslös koppling.
När Azure Databricks bearbetar en mikrobatch med data i en strömstatisk koppling ansluter den senaste giltiga versionen av data från den statiska Delta-tabellen till posterna som finns i den aktuella mikrobatchen. Eftersom kopplingen är tillståndslös behöver du inte konfigurera vattenstämpel och kan bearbeta resultat med låg svarstid. Data i den statiska Delta-tabellen som används i kopplingen bör ändras långsamt.
streamingDF = spark.readStream.table("orders")
staticDF = spark.read.table("customers")
query = (streamingDF
.join(staticDF, streamingDF.customer_id==staticDF.id, "inner")
.writeStream
.option("checkpointLocation", checkpoint_path)
.table("orders_with_customer_info")
)
Upsert från strömmande frågor med hjälp av foreachBatch
Du kan använda en kombination av merge och foreachBatch för att skriva komplexa upserts från en strömmande fråga till en Delta-tabell. Se Använda foreachBatch för att skriva till godtyckliga datamottagare.
Det här mönstret har många program, inklusive följande:
- Skriv strömningsaggregeringar i uppdateringsläge: Det här är mycket effektivare än slutfört läge.
- Skriva en dataström med databasändringar till en Delta-tabell: Sammanslagningsfrågan för att skriva ändringsdata kan användas i
foreachBatchför att kontinuerligt tillämpa en dataström med ändringar i en Delta-tabell. - Skriva en dataström till Delta-tabellen med deduplicering: Sammanfogningsfrågan för deduplicering kan användas i
foreachBatchför att kontinuerligt skriva data (med dubbletter) till en Delta-tabell med automatisk deduplicering.
Kommentar
- Kontrollera att din
mergeinstruktion inutiforeachBatchär idempotent eftersom omstarter av strömningsfrågan kan tillämpa åtgärden på samma databatch flera gånger. - När
mergeanvänds iforeachBatchkan indatahastigheten för strömningsfrågan (rapporteras viaStreamingQueryProgressoch visas i diagrammet för notebook-hastighet) rapporteras som en multipel av den faktiska hastighet med vilken data genereras vid källan. Detta beror på attmergeläser indata flera gånger vilket gör att indatamåtten multipliceras. Om det här är en flaskhals kan du cachelagra batchens dataram föremergeoch sedan ta bort cachelagring eftermerge.
I följande exempel visas hur du kan använda SQL inom foreachBatch för att utföra den här uppgiften:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Du kan också välja att använda Delta Lake-API:erna för att utföra strömmande upserts, som i följande exempel:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Idempotent tabellskrivningar i foreachBatch
Kommentar
Databricks rekommenderar att du konfigurerar en separat direktuppspelningsskrivning för varje mottagare som du vill uppdatera. Om du använder foreachBatch för att skriva till flera tabeller serialiseras skrivningar, vilket minskar parallellizaiton och ökar den totala svarstiden.
Deltatabeller stöder följande DataFrameWriter alternativ för att göra skrivningar till flera tabeller i foreachBatch idempotent:
txnAppId: En unik sträng som du kan skicka på varje DataFrame-skrivning. Du kan till exempel använda StreamingQuery-ID:t somtxnAppId.txnVersion: Ett monotont ökande tal som fungerar som transaktionsversion.
Delta Lake använder kombinationen av txnAppId och txnVersion för att identifiera duplicerade skrivningar och ignorera dem.
Om en batchskrivning avbryts med ett fel använder omkörning av batchen samma program och batch-ID för att hjälpa körningen att identifiera duplicerade skrivningar korrekt och ignorera dem. Program-ID (txnAppId) kan vara en användargenererad unik sträng och behöver inte vara relaterad till ström-ID:t. Se Använda foreachBatch för att skriva till godtyckliga datamottagare.
Varning
Om du tar bort kontrollpunkten för direktuppspelning och startar om frågan med en ny kontrollpunkt måste du ange en annan txnAppId. Nya kontrollpunkter börjar med ett batch-ID för 0. Delta Lake använder batch-ID:t och txnAppId som en unik nyckel och hoppar över batchar med redan sedda värden.
Följande kodexempel visar det här mönstret:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}