Introduktion till Azure Databricks-arbetsflöden
Azure Databricks-arbetsflöden samordnar databearbetning, maskininlärning och analyspipelines på Databricks Data Intelligence Platform. Arbetsflöden har fullständigt hanterade orkestreringstjänster integrerade med Databricks-plattformen, inklusive Azure Databricks-jobb för att köra icke-interaktiv kod på din Azure Databricks-arbetsyta och Delta Live Tables för att skapa tillförlitliga och underhållsbara ETL-pipelines.
Mer information om fördelarna med att samordna dina arbetsflöden med Databricks-plattformen finns i Databricks-arbetsflöden.
Ett exempel på Azure Databricks-arbetsflöde
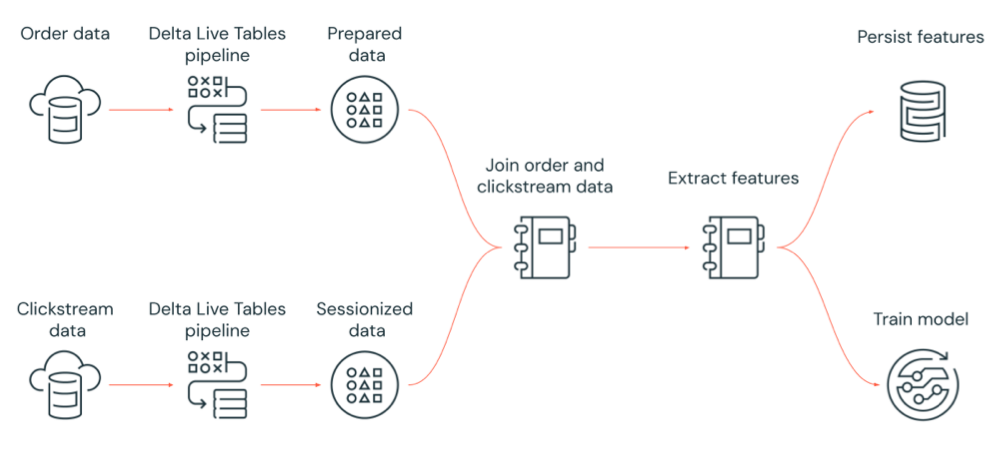
Följande diagram illustrerar ett arbetsflöde som samordnas av ett Azure Databricks-jobb för att:
- Kör en Delta Live Tables-pipeline som matar in rådata från molnlagring, rensar och förbereder data, sessioniserar data och bevarar den slutliga sessionsbaserade datauppsättningen till Delta Lake.
- Kör en Delta Live Tables-pipeline som matar in orderdata från molnlagring, rensar och transformerar data för bearbetning och bevarar den slutliga datauppsättningen till Delta Lake.
- Anslut till ordningen och sessionsbaserade klickströmsdata för att skapa en ny datauppsättning för analys.
- Extrahera funktioner från förberedda data.
- Utför uppgifter parallellt för att bevara funktionerna och träna en maskininlärningsmodell.
Vad är Azure Databricks-jobb?
Ett Azure Databricks-jobb är ett sätt att köra dina databearbetnings- och analysprogram på en Azure Databricks-arbetsyta. Jobbet kan bestå av en enda uppgift eller vara ett stort arbetsflöde med flera uppgifter och komplexa beroenden. Azure Databricks hanterar uppgiftsorkestrering, klusterhantering, övervakning och felrapportering för alla dina jobb. Du kan köra dina jobb omedelbart, regelbundet via ett lätthanterligt schemaläggningssystem, när nya filer kommer till en extern plats eller kontinuerligt för att säkerställa att en instans av jobbet alltid körs. Du kan också köra jobb interaktivt i notebook-användargränssnittet.
Du kan skapa och köra ett jobb med hjälp av jobbgränssnittet, Databricks CLI eller genom att anropa jobb-API:et. Du kan reparera och köra ett misslyckat eller avbrutet jobb igen med hjälp av användargränssnittet eller API:et. Du kan övervaka jobbkörningsresultat med hjälp av UI, CLI, API och meddelanden (till exempel e-post, webhook-mål eller Slack-meddelanden).
Mer information om hur du använder Databricks CLI finns i Vad är Databricks CLI?. Mer information om hur du använder jobb-API:et finns i Jobb-API:et.
Följande avsnitt beskriver viktiga funktioner i Azure Databricks-jobb.
Viktigt!
- En arbetsyta är begränsad till 1 000 samtidiga aktivitetskörningar. Ett
429 Too Many Requests-svar returneras när du begär en körning som inte kan starta omedelbart. - Antalet jobb som en arbetsyta kan skapa på en timme är begränsat till 1 0000 (inklusive "kör skicka"). Den här gränsen påverkar även jobb som skapas av REST API och notebook-flöden.
Implementera databearbetning och analys med jobbuppgifter
Du implementerar arbetsflödet för databearbetning och analys med hjälp av uppgifter. Ett jobb består av en eller flera uppgifter. Du kan skapa jobbuppgifter som kör notebook-filer, JARS-, Delta Live Tables-pipelines eller Python-, Scala-, Spark-och Java-program. Dina jobbuppgifter kan också samordna Databricks SQL-frågor, aviseringar och instrumentpaneler för att skapa analyser och visualiseringar, eller så kan du använda dbt-uppgiften för att köra dbt-transformeringar i arbetsflödet. Äldre Spark-sändningsprogram stöds också.
Du kan också lägga till en uppgift i ett jobb som kör ett annat jobb. Med den här funktionen kan du dela upp en stor process i flera mindre jobb eller skapa generaliserade moduler som kan återanvändas av flera jobb.
Du styr körningsordningen för aktiviteter genom att ange beroenden mellan aktiviteterna. Du kan konfigurera aktiviteter så att de körs i följd eller parallellt.
Köra jobb interaktivt, kontinuerligt eller med jobbutlösare
Du kan köra dina jobb interaktivt från jobbgränssnittet, API:et eller CLI eller köra ett kontinuerligt jobb. Du kan skapa ett schema för att köra jobbet regelbundet eller köra jobbet när nya filer kommer till en extern plats, till exempel Amazon S3, Azure Storage eller Google Cloud Storage.
Övervaka jobbframsteg med meddelanden
Du kan få meddelanden när ett jobb eller en uppgift startar, slutförs eller misslyckas. Du kan skicka meddelanden till en eller flera e-postadresser eller systemmål (till exempel webhookmål eller Slack). Se Lägga till e-post- och systemaviseringar för jobbhändelser.
Köra dina jobb med Azure Databricks-beräkningsresurser
Databricks-kluster och SQL-lager tillhandahåller beräkningsresurser för dina jobb. Du kan köra dina jobb med ett jobbkluster, ett kluster för alla syften eller ett SQL-lager:
- Ett jobbkluster är ett dedikerat kluster för ditt jobb eller enskilda jobbuppgifter. Jobbet kan använda ett jobbkluster som delas av alla aktiviteter eller så kan du konfigurera ett kluster för enskilda uppgifter när du skapar eller redigerar en uppgift. Ett jobbkluster skapas när jobbet eller aktiviteten startar och avslutas när jobbet eller aktiviteten slutar.
- Ett kluster för alla syften är ett delat kluster som startas och avslutas manuellt och kan delas av flera användare och jobb.
För att optimera resursanvändningen rekommenderar Databricks att du använder ett jobbkluster för dina jobb. Om du vill minska den tid som ägnas åt att vänta på klusterstart bör du överväga att använda ett kluster för alla syften. Se Använda Azure Databricks-beräkning med dina jobb.
Du använder ett SQL-lager för att köra Databricks SQL-uppgifter, till exempel frågor, instrumentpaneler eller aviseringar. Du kan också använda ett SQL-lager för att köra dbt-transformeringar med dbt-aktiviteten.
Nästa steg
Så här kommer du igång med Azure Databricks-jobb:
Lär dig hur du skapar och kör arbetsflöden med användargränssnittet för Azure Databricks-jobb.
Lär dig hur du kör ett jobb utan att behöva konfigurera Azure Databricks-beräkningsresurser med serverlösa arbetsflöden.
Lär dig mer om att övervaka jobbkörningar i användargränssnittet för Azure Databricks-jobb.
Läs mer om konfigurationsalternativ för jobb.
Läs mer om att skapa, hantera och felsöka arbetsflöden med Azure Databricks-jobb:
- Lär dig hur du kommunicerar information mellan aktiviteter i ett Azure Databricks-jobb med uppgiftsvärden.
- Lär dig hur du skickar kontext om jobbkörningar till jobbaktiviteter med aktivitetsparametervariabler.
- Lär dig hur du konfigurerar dina jobbaktiviteter så att de körs villkorligt baserat på statusen för aktivitetens beroenden.
- Lär dig hur du felsöker och åtgärdar misslyckade jobb.
- Få aviseringar när jobbet körs startar, slutförs eller misslyckas med jobbkörningsaviseringar.
- Utlös dina jobb enligt ett anpassat schema eller kör ett kontinuerligt jobb.
- Lär dig hur du kör ditt Azure Databricks-jobb när nya data kommer med utlösare för fil ankomst.
- Lär dig hur du använder Databricks-beräkningsresurser för att köra dina jobb.
- Lär dig mer om uppdateringar av jobb-API: et för att skapa och hantera arbetsflöden med Azure Databricks-jobb.
- Använd instruktionsguider och självstudier för att lära dig mer om hur du implementerar dataarbetsflöden med Azure Databricks-jobb.
Vad är Delta Live Tables?
Kommentar
Delta Live Tables kräver Premium-planen. Kontakta databricks-kontoteamet om du vill ha mer information.
Delta Live Tables är ett ramverk som förenklar ETL- och dataströmningsbearbetning. Delta Live Tables ger effektiv inmatning av data med inbyggt stöd för gränssnitten Auto Loader, SQL och Python som stöder deklarativ implementering av datatransformeringar och stöd för att skriva transformerade data till Delta Lake. Du definierar de omvandlingar som ska utföras på dina data, och Delta Live Tables hanterar uppgiftsorkestrering, klusterhantering, övervakning, datakvalitet och felhantering.
Information om hur du kommer igång finns i Vad är Delta Live Tables?.
Azure Databricks-jobb och Delta Live Tables
Azure Databricks-jobb och Delta Live Tables tillhandahåller ett omfattande ramverk för att skapa och distribuera arbetsflöden för databearbetning och analys från slutpunkt till slutpunkt.
Använd Delta Live Tables för all inmatning och transformering av data. Använd Azure Databricks-jobb för att samordna arbetsbelastningar som består av en enda uppgift eller flera databearbetnings- och analysuppgifter på Databricks-plattformen, inklusive Delta Live Tables-inmatning och transformering.
Som ett arbetsflödesorkestreringssystem stöder Azure Databricks Jobs även:
- Att köra jobb på utlöst basis, till exempel att köra ett arbetsflöde enligt ett schema.
- Dataanalys via SQL-frågor, maskininlärning och dataanalys med notebook-filer, skript eller externa bibliotek och så vidare.
- Köra ett jobb som består av en enda uppgift, till exempel att köra ett Apache Spark-jobb som paketerats i en JAR.
Arbetsflödesorkestrering med Apache AirFlow
Även om Databricks rekommenderar att du använder Azure Databricks-jobb för att samordna dina dataarbetsflöden kan du också använda Apache Airflow för att hantera och schemalägga dina dataarbetsflöden. Med Airflow definierar du arbetsflödet i en Python-fil och Airflow hanterar schemaläggning och körning av arbetsflödet. Se Dirigera Azure Databricks-jobb med Apache Airflow.
Arbetsflödesorkestrering med Azure Data Factory
Azure Data Factory (ADF) är en molndataintegreringstjänst som gör att du kan skapa datalagring, förflyttning och bearbetning av tjänster till automatiserade datapipelines. Du kan använda ADF för att orkestrera ett Azure Databricks-jobb som en del av en ADF-pipeline.
Information om hur du kör ett jobb med hjälp av ADF-webbaktiviteten, inklusive hur du autentiserar till Azure Databricks från ADF, finns i Använda Azure Databricks-jobborkestrering från Azure Data Factory.
ADF ger också inbyggt stöd för att köra Databricks-notebook-filer, Python-skript eller kod som paketeras i JAR:er i en ADF-pipeline.
Information om hur du kör en Databricks-notebook-fil i en ADF-pipeline finns i Köra en Databricks-notebook-fil med databricks notebook-aktiviteten i Azure Data Factory, följt av Transformera data genom att köra en Databricks-notebook-fil.
Information om hur du kör ett Python-skript i en ADF-pipeline finns i Transformera data genom att köra en Python-aktivitet i Azure Databricks.
Information om hur du kör kod som paketerats i en JAR i en ADF-pipeline finns i Transformera data genom att köra en JAR-aktivitet i Azure Databricks.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för