Federation med flera platser och flera regioner
Många avancerade lösningar kräver att samma händelseströmmar görs tillgängliga för förbrukning på flera platser, eller så kräver de att händelseströmmar samlas in på flera platser och sedan konsolideras till en specifik plats för förbrukning. Det finns också ofta ett behov av att utöka eller minska händelseströmmar eller konvertera händelseformat, även för inom en enda region och lösning.
Praktiskt taget innebär det att din lösning underhåller flera händelsehubbar, ofta i olika regioner och Event Hubs-namnrymder, och sedan replikerar händelser mellan dem. Du kan också utbyta händelser med källor och mål som Azure Service Bus, Azure IoT Hub eller Apache Kafka.
Att underhålla flera aktiva händelsehubbar i olika regioner gör det också möjligt för klienter att välja och växla mellan dem om deras innehåll slås samman, vilket gör det övergripande systemet mer motståndskraftigt mot regionala tillgänglighetsproblem.
Det här federationskapitlet beskriver federationsmönster och hur du kan realisera dessa mönster med hjälp av serverlös Azure Stream Analytics eller Azure Functions-körningar, med alternativet att ha din egen transformerings- eller berikningskod direkt i händelseflödessökvägen.
Federationsmönster
Det finns många möjliga motiveringar till varför du kanske vill flytta händelser mellan olika händelsehubbar eller andra källor och mål, och vi räknar upp de viktigaste mönstren i det här avsnittet och länkar även till mer detaljerad vägledning för respektive mönster.
- Återhämtning mot regionala tillgänglighetshändelser
- Optimering av svarstid
- Validering, minskning och berikning
- Integrering med analystjänster
- Konsolidering och normalisering av händelseströmmar
- Delning och routning av händelseströmmar
- Loggprojektioner
Återhämtning mot regionala tillgänglighetshändelser
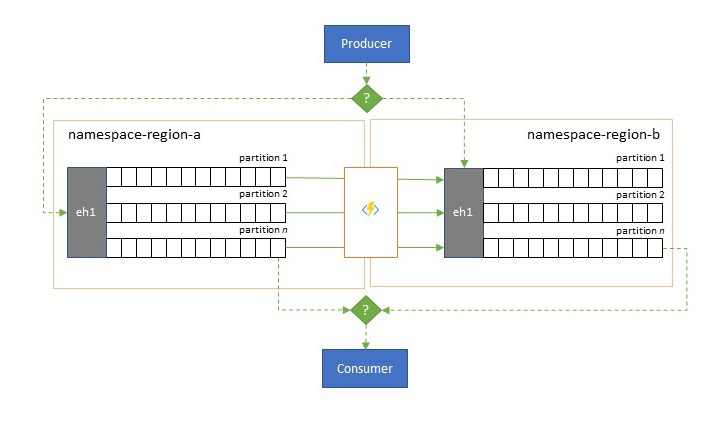
Även om maximal tillgänglighet och tillförlitlighet är de främsta operativa prioriteringarna för Event Hubs, finns det ändå många sätt på vilka en producent eller konsument kan hindras från att prata med sina tilldelade "primära" händelsehubbar på grund av problem med nätverks- eller namnmatchning, eller där en händelsehubb faktiskt tillfälligt inte svarar eller returnerar fel.
Sådana villkor är inte "katastrofala" så att du vill överge den regionala distributionen helt och hållet som i en haveriberedskapssituation , men affärsscenariot för vissa program kan redan påverkas av tillgänglighetshändelser som varar i högst några minuter eller till och med sekunder.
Det finns två grundläggande mönster för att hantera sådana scenarier:
- Replikeringsmönstret handlar om att replikera innehållet i en primär händelsehubb till en sekundär händelsehubb, där de primära händelsehubbarna vanligtvis används av programmet för både skapande och användning av händelser och den sekundära fungerar som reservalternativ om de primära händelsehubbarna blir otillgängliga. Eftersom replikeringen är enkelriktad, från den primära till den sekundära, kommer en växling av både producenter och konsumenter från en otillgänglig primär till sekundär att göra att den gamla primära inte längre tar emot nya händelser och därför inte längre är aktuell. Ren replikering är därför endast lämplig för enkelriktade redundansscenarier. När redundansväxlingen har utförts avbryts den gamla primära och en ny sekundär händelsehubb måste skapas i en annan målregion.
- Sammanslagningsmönstret utökar replikeringsmönstret genom att utföra en kontinuerlig sammanslagning av innehållet i två eller flera händelsehubbar. Varje händelse som ursprungligen producerades till en av de händelsehubbar som ingår i schemat replikeras till de andra händelsehubbarna. När händelser replikeras kommenteras de så att de sedan ignoreras av replikeringsprocessen för replikeringsmålet. Resultatet av att använda sammanslagningsmönstret är två eller flera händelsehubbar som kommer att innehålla samma uppsättning händelser på ett så småningom konsekvent sätt.
I båda fallen är innehållet i Event Hubs inte identiskt. Händelser från en producent och grupperade efter samma partitionsnyckel visas i samma relativa ordning som ursprungligen skickades, men den absoluta ordningen för händelser kan skilja sig åt. Detta gäller särskilt för scenarier där antalet partitioner för käll- och målhändelsehubbar skiljer sig åt, vilket är önskvärt för flera av de utökade mönster som beskrivs här. En splitter eller router kan få en del av en mycket större Händelsehubb med hundratals partitioner och tratt till en mindre Event Hubs med bara en handfull partitioner, vilket är mer lämpligt för hantering av delmängden med begränsade bearbetningsresurser. Å andra sidan kan en konsolidering trattdata från flera mindre händelsehubbar till en enda större händelsehubb med fler partitioner för att hantera det konsoliderade dataflödet och bearbetningsbehoven.
Kriteriet för att hålla ihop händelser är partitionsnyckeln och inte det ursprungliga partitions-ID:t. Ytterligare överväganden om relativ ordning och hur du utför en redundansväxling från en händelsehubb till en annan utan att förlita dig på samma omfång för strömförskjutningar beskrivs i beskrivningen av replikeringsmönstret .
Vägledning:
Optimering av svarstid
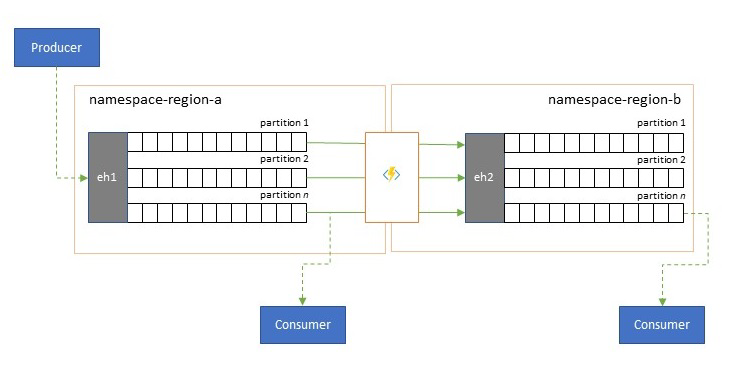
Händelseströmmar skrivs en gång av producenter, men kan läsas valfritt antal gånger av händelsekonsumenter. För scenarier där en händelseström i en region delas av flera konsumenter och måste nås upprepade gånger under analysbearbetning som finns i en annan region, eller med krav som skulle svälta ut samtidiga konsumenter, kan det vara fördelaktigt att placera en kopia av händelseströmmen nära analysprocessorn för att minska svarstiden tur och retur.
Bra exempel på när replikering bör föredras framför att konsumera händelser på distans från olika regioner är särskilt de där regionerna är extremt långt ifrån varandra, till exempel Europa och Australien är nästan antipoder, geografiskt och nätverksfördröjningar kan lätt överstiga 250 ms för varje tur och retur. Du kan inte påskynda ljusets hastighet, men du kan minska antalet turer med långa svarstider för att interagera med data.
Vägledning:
Validering, minskning och berikning
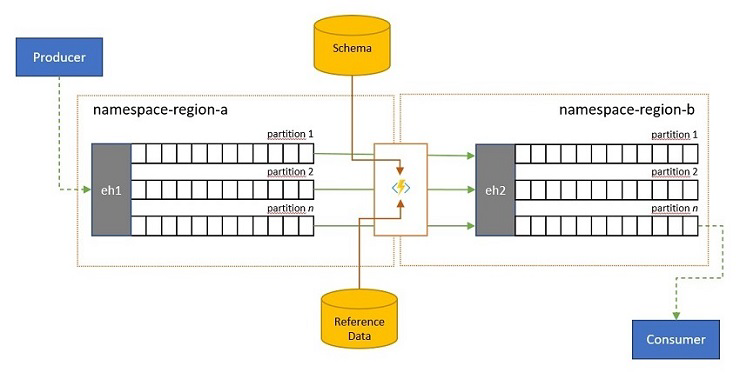
Händelseströmmar kan skickas till en händelsehubb av klienter utanför din egen lösning. Sådana händelseströmmar kan kräva att externt skickade händelser kontrolleras för kompatibilitet med ett visst schema och för att icke-kompatibla händelser ska tas bort.
I scenarier där klienter är extremt bandbreddsbegränsade som i många "Sakernas Internet"-scenarier med mätbandbredd, eller där händelser ursprungligen skickas via icke-IP-nätverk med begränsade paketstorlekar, kan händelserna behöva utökas med referensdata för att ytterligare kontext ska kunna användas av underordnade händelseprocessorer.
I andra fall, särskilt när strömmar konsolideras, kan händelsedata behöva minskas i komplexitet eller storlek genom att utelämna vissa detaljer.
Alla dessa åtgärder kan utföras som en del av replikerings-, konsoliderings- eller sammanslagningsflöden.
Vägledning:
Integrering med analystjänster
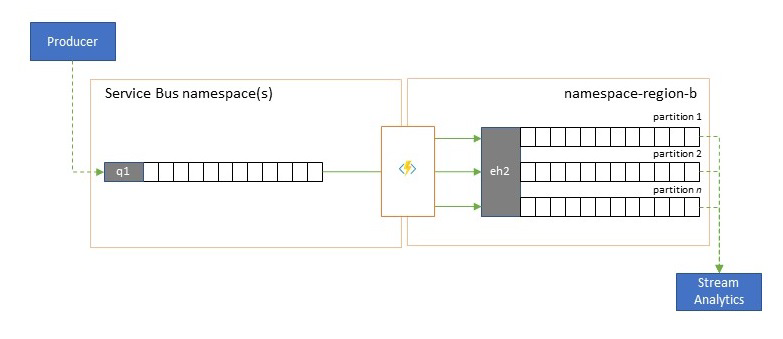
Flera av Azures molnbaserade analystjänster som Azure Stream Analytics eller Azure Synapse fungerar bäst med strömmade eller förlagrade data som hanteras från Azure Event Hubs, och Azure Event Hubs möjliggör även integrering med flera analyspaket med öppen källkod som Apache Samza, Apache Flink, Apache Spark och Apache Storm.
Om din lösning främst använder Service Bus eller Event Grid kan du göra dessa händelser lättillgängliga för sådana analyssystem och även för arkivering med Event Hubs Capture om du skickar dem till Event Hubs. Event Grid kan göra det internt med sin Event Hubs-integrering. För Service Bus följer du replikeringsvägledningen för Service Bus.
Azure Stream Analytics integreras direkt med Event Hubs.
Vägledning:
Konsolidering och normalisering av händelseströmmar
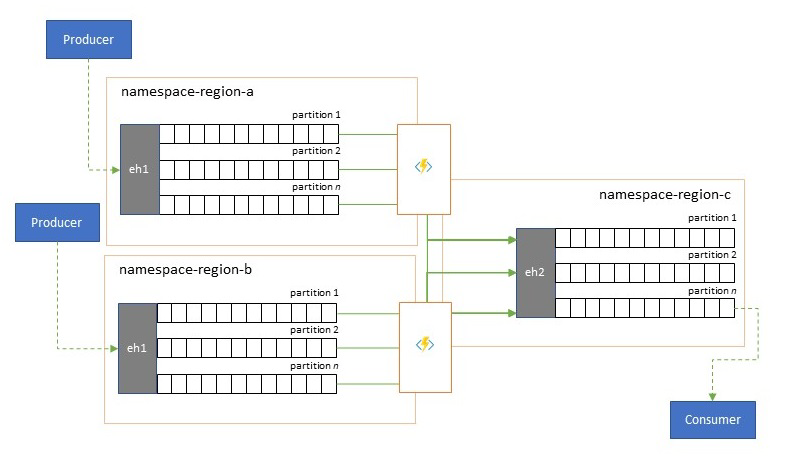
Globala lösningar består ofta av regionala fotavtryck som till stor del är oberoende, inklusive egna analysfunktioner, men överregionala och globala analysperspektiv kräver ett integrerat perspektiv och det är därför en central konsolidering av samma händelseströmmar som utvärderas i respektive regional fotavtryck för det lokala perspektivet.
Normalisering är en variant av konsolideringsscenariot, där två eller flera inkommande händelseströmmar har samma typ av händelser, men med olika strukturer eller olika kodningar, och de händelser som mest kodas eller transformeras innan de kan användas.
Normalisering kan också omfatta kryptografiskt arbete, till exempel dekryptering av krypterade nyttolaster från slutpunkt till slutpunkt och omkryptering med olika nycklar och algoritmer för den underordnade konsumentpubliken.
Vägledning:
Delning och routning av händelseströmmar
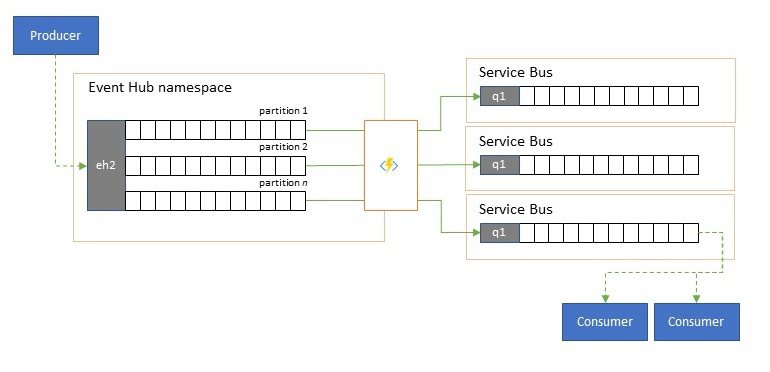
Azure Event Hubs används ibland i scenarier i "publicera-prenumerera"-stil där en inkommande ström av inmatade händelser vida överskrider kapaciteten för Azure Service Bus eller Azure Event Grid, som båda har interna funktioner för filtrering och distribution av publiceringsprenumeranter och som föredras för det här mönstret.
Även om en sann "publicera-prenumerera"-funktion lämnar det till prenumeranter att välja de händelser de vill ha, har delningsmönstret producentkartahändelser till partitioner av en fördefinierad distributionsmodell och utsedda konsumenter hämtar sedan exklusivt från "sin" partition. När Event Hubs buffrar den övergripande trafiken kan innehållet i en viss partition, som representerar en bråkdel av den ursprungliga dataflödesvolymen, sedan replikeras till en kö för tillförlitlig, transaktionell, konkurrerande konsumentförbrukning.
Många scenarier där Event Hubs främst används för att flytta händelser inom ett program inom en region har vissa fall där utvalda händelser, kanske bara från en enda partition, också måste göras tillgängliga någon annanstans. Det här scenariot liknar delningsscenariot, men kan använda en skalbar router som tar hänsyn till alla meddelanden som kommer till en händelsehubb och cherry-picks bara några få för vidare routning och kan skilja routningsmål efter händelsemetadata eller innehåll.
Vägledning:
Loggprojektioner
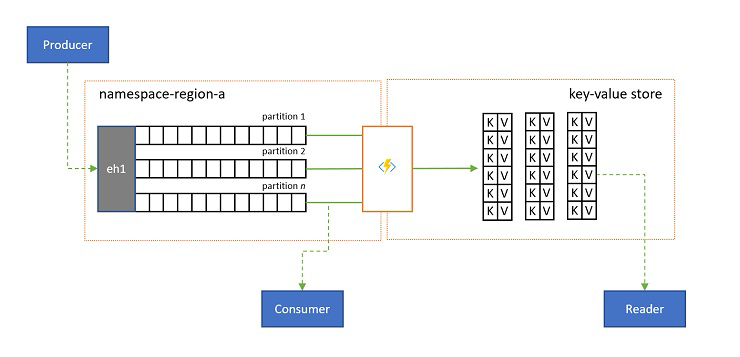
I vissa fall vill du ha åtkomst till det senaste värdet som skickas för en underström av en händelse och som ofta särskiljs av partitionsnyckeln. I Apache Kafka uppnås detta ofta genom att aktivera "loggkomprimering" i ett ämne, vilket tar bort alla utom den senaste händelsen märkt med en unik nyckel. Loggkomprimeringsmetoden har tre sammansatta nackdelar:
- Komprimeringen kräver en kontinuerlig omorganisering av loggen, vilket är en alltför dyr åtgärd för en asynkron meddelandekö som är optimerad för endast tilläggsarbetsbelastningar.
- Komprimering är destruktivt och tillåter inte ett komprimerat och icke-komprimerat perspektiv av samma ström.
- En komprimerad dataström har fortfarande en sekventiell åtkomstmodell, vilket innebär att du måste läsa hela loggen i värsta fall för att hitta önskat värde i loggen, vilket vanligtvis leder till optimeringar som implementerar det exakta mönstret som visas här: att projicera logginnehållet till en databas eller cache.
I slutändan är en komprimerad logg ett nyckelvärdeslager och därför är det det sämsta möjliga implementeringsalternativet för ett sådant arkiv. Det är mycket mer effektivt för sökningar och för frågor att skapa och använda en permanent projektion av loggen till ett korrekt nyckel/värde-lager eller någon annan databas.
Eftersom händelser är oföränderliga och ordningen alltid bevaras i en logg, ger alla projektioner av en logg till ett nyckelvärdearkiv alltid identiska för samma händelseintervall, vilket innebär att en projektion som du håller uppdaterad alltid ger en auktoritativ vy och det finns aldrig någon bra anledning att återskapa den från logginnehållet när den väl har skapats.
Vägledning:
Replikeringsprogramtekniker
Implementering av mönstren ovan kräver en skalbar och tillförlitlig körningsmiljö för de replikeringsuppgifter som du vill konfigurera och köra. I Azure är de körningsmiljöer som passar bäst för sådana uppgifter tillståndslösa uppgifter i Azure Stream Analytics för tillståndskänsliga dataströmsreplikeringsuppgifter och Azure Functions för tillståndslösa replikeringsuppgifter.
Tillståndskänsliga replikeringsprogram i Azure Stream Analytics
För tillståndskänsliga replikeringsprogram som behöver överväga relationer mellan händelser, skapa sammansatta händelser, berika händelser eller minska händelser, skapa dataaggregeringar och transformera händelsenyttolaster är Azure Stream Analytics det bästa implementeringsalternativet.
I Azure Stream Analytics skapar du jobb som integrerar indata och utdata och integrerar data från indata via frågor som ger ett resultat som sedan görs tillgängligt för utdata.
Frågor baseras på SQL-frågespråket och kan användas för att enkelt filtrera, sortera, aggregera och koppla strömmande data under en tidsperiod. Du kan också utöka det här SQL-språket med användardefinierade javascript- och C#-funktioner (UDF:er). Du kan enkelt justera alternativ för händelseordning och varaktighet för tidsfönster när du utför aggregeringsåtgärder via enkla språkkonstruktioner och/eller konfigurationer.
Varje jobb har en eller flera utdata för transformerade data och du kan styra vad som händer som svar på den information som du har analyserat. Du kan till exempel:
- Skicka data till tjänster som Azure Functions, Service Bus-ämnen eller köer för att utlösa kommunikation eller anpassade arbetsflöden nedströms.
- Skicka data till en Power BI-instrumentpanel för instrumentpaneler i realtid.
- Lagra data i andra Azure Storage-tjänster (till exempel Azure Data Lake, Azure Synapse Analytics osv.) för att utföra batchanalys eller träna maskininlärningsmodeller baserat på mycket stora, indexerade pooler med historiska data.
- Lagra projektioner (kallas även "materialiserade vyer") i databaser (SQL Database, Azure Cosmos DB).
Tillståndslösa replikeringsprogram i Azure Functions
För tillståndslösa replikeringsuppgifter där du vill vidarebefordra händelser utan att överväga deras nyttolaster eller bearbetar dem singly utan att behöva överväga relationerna mellan händelser (förutom deras relativa ordning), kan du använda Azure Functions, vilket ger enorm flexibilitet.
Azure Functions har fördefinierade, skalbara utlösare och utdatabindningar för Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid och Azure Queue Storage samt anpassade tillägg för RabbitMQ och Apache Kafka. De flesta utlösare anpassar sig dynamiskt efter dataflödesbehoven genom att skala upp och ned antalet instanser som körs samtidigt baserat på dokumenterade mått.
För att skapa loggprojektioner stöder Azure Functions utdatabindningar för Azure Cosmos DB och Azure Table Storage.
Azure Functions kan köras under en Hanterad Azure-identitet och med det kan den lagra konfigurationsvärdena för autentiseringsuppgifter i strikt åtkomstkontrollerad lagring i Azure Key Vault.
Azure Functions gör dessutom att replikeringsuppgifterna kan integreras direkt med virtuella Azure-nätverk och tjänstslutpunkter för alla Azure-meddelandetjänster, och de integreras enkelt med Azure Monitor.
Med den Azure Functions förbrukningsplanen kan de fördefinierade utlösarna till och med skalas ned till noll medan inga meddelanden är tillgängliga för replikering, vilket innebär att du inte medför några kostnader för att hålla konfigurationen redo att skalas upp igen. Den viktigaste nackdelen med att använda förbrukningsplanen är att svarstiden för replikeringsuppgifter som "vaknar upp" från det här tillståndet är betydligt högre än med de värdplaner där infrastrukturen fortsätter att köras.
Till skillnad från allt detta kräver de vanligaste replikeringsmotorerna för meddelanden och händelser, till exempel Apache Kafkas MirrorMaker , att du tillhandahåller en värdmiljö och skalar replikeringsmotorn själv. Det omfattar att konfigurera och integrera säkerhets- och nätverksfunktionerna och underlätta flödet av övervakningsdata, och sedan har du fortfarande inte möjlighet att mata in anpassade replikeringsuppgifter i flödet.
Välja mellan Azure Functions och Azure Stream Analytics
Azure Stream Analytics (ASA) är det bästa alternativet när du behöver bearbeta nyttolasten för dina händelser när du replikerar dem. ASA kan kopiera händelser en i taget eller skapa aggregeringar som komprimerar informationen om händelseströmmar innan den vidarebefordras. Den kan enkelt luta sig mot att komplettera referensdata som lagras i Azure Blob Storage eller Azure SQL Database utan att behöva importera sådana data till en dataström.
Med ASA kan du enkelt skapa beständiga, materialiserade vyer av strömmar i hyperskala-databaser. Det är en mycket överlägsen metod för den klumpiga "log compaction"-modellen för Apache Kafka och de flyktiga tabellprojektionerna på klientsidan i Kafka Streams.
ASA kan enkelt bearbeta händelser med nyttolaster kodade i CSV-, JSON- och Apache Avro-format och du kan ansluta anpassade deserialiserare för andra format.
För alla replikeringsuppgifter där du vill kopiera händelseströmmar "i förekommande fall" och utan att röra nyttolasterna, eller om du behöver implementera en router, utföra kryptografiskt arbete, ändra kodningen av nyttolaster eller om du på annat sätt behöver fullständig kontroll över dataströminnehållet är Azure Functions det bästa alternativet.
Nästa steg
I den här artikeln utforskade vi en rad federationsmönster och förklarade rollen för Azure Functions som körning av händelse- och meddelandereplikering i Azure.
Därefter kanske du vill läsa om hur du konfigurerar ett replikatorprogram med Azure Stream Analytics eller Azure Functions och sedan hur du replikerar händelseflöden mellan Event Hubs och olika andra händelse- och meddelandesystem: