Använda Apache Spark Structured Streaming med Apache Kafka och Azure Cosmos DB
Lär dig hur du använder Apache SparkStructured Streaming för att läsa data från Apache Kafka i Azure HDInsight och sedan lagra data i Azure Cosmos DB.
Azure Cosmos DB är en globalt distribuerad databas med flera modeller. I det här exemplet används en Azure Cosmos DB för NoSQL-databasmodell. Mer information finns i dokumentet Välkommen till Azure Cosmos DB .
Apache Spark Structured Streaming är en bearbetningsmotor för dataströmmar som bygger på Apache Spark SQL. Med den kan du uttrycka strömmande beräkningar på samma sätt som batchberäkningar av statiska data. Mer information om strukturerad direktuppspelning finns i programmeringsguiden för strukturerad direktuppspelning på Apache.org.
Viktigt!
I det här exemplet används Spark 2.4 på HDInsight 4.0.
Stegen i det här dokumentet skapar en Azure-resursgrupp som innehåller både en Apache Spark på HDInsight och en Kafka på HDInsight-klustret. Båda dessa kluster finns i ett virtuellt Azure-nätverk, vilket innebär att Apache Spark-klustret kan kommunicera direkt med Kafka-klustret.
Kom ihåg att ta bort klustren för att undvika onödiga avgifter när du är klar med stegen i det här dokumentet.
Skapa kluster
Apache Kafka på HDInsight ger inte åtkomst till Kafka-mäklarna via det offentliga Internet. Allt som pratar med Kafka måste finnas i samma virtuella Azure-nätverk som noderna i Kafka-klustret. I det här exemplet finns både Kafka- och Spark-kluster i ett virtuellt Azure-nätverk. Följande diagram visar hur kommunikationen flödar mellan klustren:
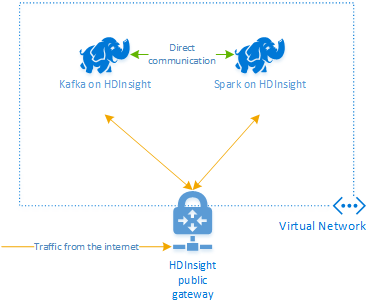
Kommentar
Kafka-tjänsten är begränsad till kommunikation inom det virtuella nätverket. Andra tjänster på klustret, till exempel SSH och Ambari, kan nås via Internet. Mer information om de offentliga portar som är tillgängliga med HDInsight finns i Portar och URI:er som används av HDInsight.
Även om du kan skapa ett virtuellt Azure-nätverk, Kafka- och Spark-kluster manuellt, är det enklare att använda en Azure Resource Manager-mall. Använd följande steg för att distribuera ett virtuellt Azure-nätverk, Kafka- och Spark-kluster till din Azure-prenumeration.
Använd följande knapp för att logga in på Azure och öppna mallen i Azure Portal.

Azure Resource Manager-mallen finns på GitHub-lagringsplatsen för det här projektet (https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb).
Den här mallen skapar följande resurser:
Ett Kafka på HDInsight 4.0-kluster.
Ett Spark på HDInsight 4.0-kluster.
Ett virtuellt Azure-nätverk som innehåller HDInsight-klustren. Det virtuella nätverk som skapas av mallen använder adressutrymmet 10.0.0.0/16.
En Azure Cosmos DB för NoSQL-databas.
Viktigt!
Den strukturerade notebook-filen för direktuppspelning som används i det här exemplet kräver Spark på HDInsight 4.0. Om du använder en tidigare version av Apache Spark i HDInsight får du ett felmeddelande när du använder anteckningsboken.
Använd följande information för att fylla i posterna i avsnittet Anpassad distribution :
Property Värde Prenumeration Välj din Azure-prenumerationen. Resursgrupp Skapa en grupp eller välj en befintlig. Den här gruppen innehåller HDInsight-klustret. Azure Cosmos DB-kontonamn Det här värdet används som namn på Azure Cosmos DB-kontot. Namnet får endast innehålla gemener, siffror och bindestreck (-). Det måste innehålla 3–31 tecken. Namn på baskluster Det här värdet används som basnamn för Spark- och Kafka-kluster. Om du till exempel anger myhdi skapas ett Spark-kluster med namnet spark-myhdi och ett Kafka-kluster med namnet kafka-myhdi. Klusterversion HDInsight-klusterversionen. Det här exemplet testas med HDInsight 4.0 och kanske inte fungerar med andra klustertyper. Användarnamn för klusterinloggning Administratörsanvändarnamnet för Spark- och Kafka-kluster. Lösenord för klusterinloggning Administratörsanvändarlösenordet för Spark- och Kafka-kluster. SSH-användarnamn Den SSH-användare som ska skapas för Spark- och Kafka-kluster. SSH-lösenord Lösenordet för SSH-användaren för Spark- och Kafka-klustren. 
Granska villkoren och välj sedan Jag godkänner villkoren ovan.
Välj slutligen Köp. Det kan ta upp till 45 minuter att skapa klustren, det virtuella nätverket och Azure Cosmos DB-kontot.
Skapa Azure Cosmos DB-databasen och samlingen
Projektet som används i det här dokumentet lagrar data i Azure Cosmos DB. Innan du kör koden måste du först skapa en databas och samling i din Azure Cosmos DB-instans. Du måste också hämta dokumentslutpunkten och nyckeln som används för att autentisera begäranden till Azure Cosmos DB.
Ett sätt att göra detta är att använda Azure CLI. Följande skript skapar en databas med namnet kafkadata och en samling med namnet kafkacollection. Den returnerar sedan primärnyckeln.
#!/bin/bash
# Replace 'myresourcegroup' with the name of your resource group
resourceGroupName='myresourcegroup'
# Replace 'mycosmosaccount' with the name of your Azure Cosmos DB account name
name='mycosmosaccount'
# WARNING: If you change the databaseName or collectionName
# then you must update the values in the Jupyter Notebook
databaseName='kafkadata'
collectionName='kafkacollection'
# Create the database
az cosmosdb sql database create --account-name $name --name $databaseName --resource-group $resourceGroupName
# Create the collection
az cosmosdb sql container create --account-name $name --database-name $databaseName --name $collectionName --partition-key-path "/my/path" --resource-group $resourceGroupName
# Get the endpoint
az cosmosdb show --name $name --resource-group $resourceGroupName --query documentEndpoint
# Get the primary key
az cosmosdb keys list --name $name --resource-group $resourceGroupName --type keys
Dokumentslutpunkten och primärnyckelinformationen liknar följande text:
# endpoint
"https://mycosmosaccount.documents.azure.com:443/"
# key
"YqPXw3RP7TsJoBF5imkYR0QNA02IrreNAlkrUMkL8EW94YHs41bktBhIgWq4pqj6HCGYijQKMRkCTsSaKUO2pw=="
Viktigt!
Spara slutpunkts- och nyckelvärdena när de behövs i Jupyter Notebooks.
Hämta anteckningsböckerna
Koden för exemplet som beskrivs i det här dokumentet finns på https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb.
Ladda upp anteckningsböckerna
Använd följande steg för att ladda upp notebook-filerna från projektet till spark-klustret i HDInsight:
I webbläsaren ansluter du till Jupyter Notebook i Spark-klustret. I följande URL ersätter du
CLUSTERNAMEmed namnet på ditt Apache Spark-kluster:https://CLUSTERNAME.azurehdinsight.net/jupyterAnge klusterinloggningen (administratör) och det lösenord som användes när du skapade klustret.
Längst upp till höger på sidan använder du knappen Ladda upp för att ladda upp filen Stream-taxi-data-to-kafka.ipynb till klustret. Välj Öppna för att påbörja uppladdningen.
Leta upp posten Stream-taxi-data-to-kafka.ipynb i listan med notebook-filer och välj knappen Ladda upp bredvid den.
Upprepa steg 1-3 för att läsa in notebook-filen Stream-data-from-Kafka-to-Cosmos-DB.ipynb .
Läsa in taxidata i Kafka
När filerna har laddats upp väljer du posten Stream-taxi-data-to-kafka.ipynb för att öppna anteckningsboken. Följ stegen i notebook-filen för att läsa in data till Kafka.
Bearbeta taxidata med Spark Structured Streaming
På startsidan för Jupyter Notebook väljer du posten Stream-data-from-Kafka-to-Cosmos-DB.ipynb. Följ stegen i notebook-filen för att strömma data från Kafka och till Azure Cosmos DB med Spark Structured Streaming.
Nästa steg
Nu när du har lärt dig hur du använder Apache Spark Structured Streaming kan du läsa följande dokument för att lära dig mer om att arbeta med Apache Spark, Apache Kafka och Azure Cosmos DB: