Operationalisera en pipeline för dataanalys
Datapipelines innehåller många dataanalyslösningar. Som namnet antyder tar en datapipeline in rådata, rensar och omformar den efter behov och utför sedan vanligtvis beräkningar eller aggregeringar innan de bearbetade data lagras. Bearbetade data används av klienter, rapporter eller API:er. En datapipeline måste ge upprepningsbara resultat, oavsett om det är enligt ett schema eller när den utlöses av nya data.
Den här artikeln beskriver hur du operationaliserar dina datapipelines för repeterbarhet med hjälp av Oozie som körs i HDInsight Hadoop-kluster. Exempelscenariot vägleder dig genom en datapipeline som förbereder och bearbetar flygtidsseriedata.
I följande scenario är indata en platt fil som innehåller en batch med flygdata i en månad. Dessa flygdata innehåller information som ursprung och målflygplats, de mil som flygs, avgångs- och ankomsttider och så vidare. Målet med den här pipelinen är att sammanfatta det dagliga flygbolagets prestanda, där varje flygbolag har en rad för varje dag med genomsnittlig avgång och ankomstförseningar i minuter och det totala antalet mil som flögs den dagen.
| YEAR | MONTH | DAY_OF_MONTH | BÄRARE | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
Exempelpipelinen väntar tills en ny tidsperiods flygdata kommer och lagrar sedan den detaljerade flyginformationen i ditt Apache Hive-informationslager för långsiktiga analyser. Pipelinen skapar också en mycket mindre datamängd som sammanfattar bara de dagliga flygdata. Denna dagliga flygsammanfattningsdata skickas till en SQL Database för att tillhandahålla rapporter, till exempel för en webbplats.
Följande diagram illustrerar exempelpipelinen.
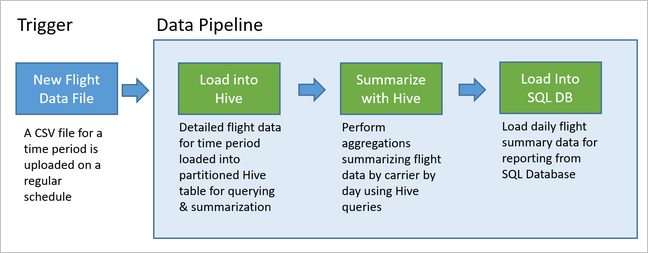
Översikt över Apache Oozie-lösningen
Den här pipelinen använder Apache Oozie som körs på ett HDInsight Hadoop-kluster.
Oozie beskriver sina pipelines när det gäller åtgärder, arbetsflöden och koordinatorer. Åtgärder avgör det faktiska arbete som ska utföras, till exempel att köra en Hive-fråga. Arbetsflöden definierar sekvensen med åtgärder. Koordinatorer definierar schemat för när arbetsflödet körs. Koordinatorer kan också vänta på tillgängligheten för nya data innan de startar en instans av arbetsflödet.
Följande diagram visar den övergripande designen av den här exempelpipelinen Oozie.
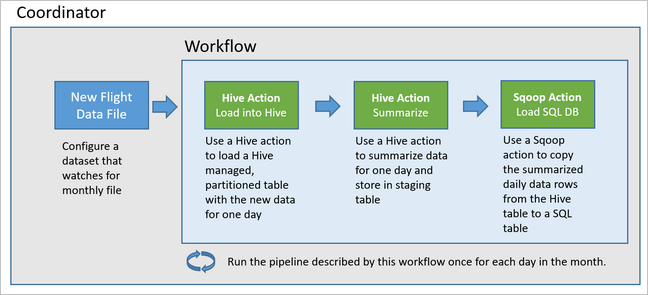
Etablera Azure-resurser
Den här pipelinen kräver en Azure SQL Database och ett HDInsight Hadoop-kluster på samma plats. Azure SQL Database lagrar både sammanfattningsdata som produceras av pipelinen och Oozie Metadata Store.
Etablera Azure SQL Database
Skapa en Azure SQL Database. Se Skapa en Azure SQL Database i Azure-portalen.
För att säkerställa att HDInsight-klustret kan komma åt den anslutna Azure SQL Database konfigurerar du Azure SQL Database-brandväggsregler så att Azure-tjänster och resurser får åtkomst till servern. Du kan aktivera det här alternativet i Azure-portalen genom att välja Ange serverbrandvägg och välja PÅ under Tillåt Att Azure-tjänster och resurser får åtkomst till den här servern för Azure SQL Database. Mer information finns i Skapa och hantera IP-brandväggsregler.
Använd Frågeredigeraren för att köra följande SQL-instruktioner för att skapa tabellen
dailyflightssom lagrar sammanfattade data från varje körning av pipelinen.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
Azure SQL Database är nu klar.
Etablera ett Apache Hadoop-kluster
Skapa ett Apache Hadoop-kluster med ett anpassat metaarkiv. När klustret skapas från portalen ser du till att du väljer din SQL Database under Metaarkivinställningar på fliken Lagring. Mer information om hur du väljer ett metaarkiv finns i Välj ett anpassat metaarkiv när klustret skapas. Mer information om hur du skapar kluster finns i Komma igång med HDInsight i Linux.
Verifiera konfigurationen av SSH-tunnlar
Om du vill använda Oozie-webbkonsolen för att visa status för dina koordinator- och arbetsflödesinstanser konfigurerar du en SSH-tunnel till DITT HDInsight-kluster. Mer information finns i SSH-tunneln.
Kommentar
Du kan också använda Chrome med Foxy Proxy-tillägget för att bläddra i klustrets webbresurser i SSH-tunneln. Konfigurera den till proxy för alla förfrågningar via värden localhost på tunnelns port 9876. Den här metoden är kompatibel med Windows-undersystem för Linux, även kallat Bash på Windows 10.
Kör följande kommando för att öppna en SSH-tunnel till klustret, där
CLUSTERNAMEär namnet på klustret:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netKontrollera att tunneln fungerar genom att navigera till Ambari på huvudnoden genom att bläddra till:
http://headnodehost:8080Om du vill komma åt Oozie-webbkonsolen inifrån Ambari går du till Oozie>Quick Links> [Active server] >Oozie Web UI.
Konfigurera Hive
Ladda upp data
Ladda ned en CSV-exempelfil som innehåller flygdata i en månad. Ladda ned zip-filen
2017-01-FlightData.zipfrån HDInsight GitHub-lagringsplatsen och packa upp den till CSV-filen2017-01-FlightData.csv.Kopiera den här CSV-filen till Det Azure Storage-konto som är kopplat till ditt HDInsight-kluster och placera den i
/example/data/flightsmappen.Använd SCP för att kopiera filerna från den lokala datorn till den lokala lagringen av hdinsight-klustrets huvudnod.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvAnvänd ssh-kommandot för att ansluta till klustret. Redigera kommandot nedan genom att
CLUSTERNAMEersätta med namnet på klustret och ange sedan kommandot:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netFrån ssh-sessionen använder du HDFS-kommandot för att kopiera filen från din lokala huvudnodlagring till Azure Storage.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
Skapa tabeller
Exempeldata är nu tillgängliga. Pipelinen kräver dock två Hive-tabeller för bearbetning, en för inkommande data (rawFlights) och en för sammanfattade data (flights). Skapa dessa tabeller i Ambari på följande sätt.
Logga in på Ambari genom att navigera till
http://headnodehost:8080.I listan över tjänster väljer du Hive.

Välj Gå till Visa bredvid etiketten Hive View 2.0.
I frågetextområdet klistrar du in följande instruktioner för att skapa
rawFlightstabellen. TabellenrawFlightsinnehåller ett schema på läsning för CSV-filerna i/example/data/flightsmappen i Azure Storage.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'Välj Kör för att skapa tabellen.

Om du vill skapa
flightstabellen ersätter du texten i frågetextområdet med följande instruktioner. Tabellenflightsär en Hive-hanterad tabell som partitionerar data som läses in i den efter år, månad och dag i månaden. Den här tabellen innehåller alla historiska flygdata, med den lägsta kornigheten som finns i källdata för en rad per flygning.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );Välj Kör för att skapa tabellen.
Skapa Oozie-arbetsflödet
Pipelines bearbetar vanligtvis data i batchar med ett visst tidsintervall. I det här fallet bearbetar pipelinen flygdata dagligen. Med den här metoden kan csv-indatafilerna tas emot dagligen, varje vecka, varje månad eller varje år.
Exempelarbetsflödet bearbetar flygdata dag för dag i tre huvudsteg:
- Kör en Hive-fråga för att extrahera data för dagens datumintervall från csv-källfilen som representeras av
rawFlightstabellen och infoga data iflightstabellen. - Kör en Hive-fråga för att dynamiskt skapa en mellanlagringstabell i Hive för dagen, som innehåller en kopia av flygdata som sammanfattas per dag och operatör.
- Använd Apache Sqoop för att kopiera alla data från den dagliga mellanlagringstabellen i Hive till måltabellen
dailyflightsi Azure SQL Database. Sqoop läser källraderna från data bakom Hive-tabellen som finns i Azure Storage och läser in dem i SQL Database med hjälp av en JDBC-anslutning.
Dessa tre steg samordnas av ett Oozie-arbetsflöde.
Skapa en fil med namnet
job.propertiesfrån din lokala arbetsstation. Använd texten nedan som startinnehåll för filen. Uppdatera sedan värdena för din specifika miljö. Tabellen under texten sammanfattar var och en av egenskaperna och anger var du kan hitta värdena för din egen miljö.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03Property Värdekälla nameNode Den fullständiga sökvägen till Azure Storage-containern som är kopplad till ditt HDInsight-kluster. jobTracker Det interna värdnamnet för det aktiva klustrets YARN-huvudnod. På Ambari-startsidan väljer du YARN i listan över tjänster och väljer sedan Active Resource Manager. Värdnamnets URI visas överst på sidan. Lägg till port 8050. queueName Namnet på YARN-kön som användes vid schemaläggning av Hive-åtgärderna. Lämna som standard. oozie.use.system.libpath Lämna som sant. appBase Sökvägen till undermappen i Azure Storage där du distribuerar Oozie-arbetsflödet och stödfiler. oozie.wf.application.path Platsen för det Oozie-arbetsflöde som workflow.xmlska köras.hiveScriptLoadPartition Sökvägen i Azure Storage till Hive-frågefilen hive-load-flights-partition.hql.hiveScriptCreateDailyTable Sökvägen i Azure Storage till Hive-frågefilen hive-create-daily-summary-table.hql.hiveDailyTableName Det dynamiskt genererade namn som ska användas för mellanlagringstabellen. hiveDataFolder Sökvägen i Azure Storage till data som ingår i mellanlagringstabellen. sqlDatabase Anslut ionString JDBC-syntaxen anslutningssträng till din Azure SQL Database. sqlDatabaseTableName Namnet på tabellen i Azure SQL Database som sammanfattningsrader infogas i. Lämna som dailyflights.år Årskomponenten för den dag då flygsammanfattningar beräknas. Lämna som det är. månad Månadskomponenten för den dag då flygsammanfattningar beräknas. Lämna som det är. dag Komponenten day of month för den dag för vilken flygsammanfattningar beräknas. Lämna som det är. Skapa en fil med namnet
hive-load-flights-partition.hqlfrån din lokala arbetsstation. Använd koden nedan som innehåll för filen.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Oozie-variabler använder syntaxen
${variableName}. Dessa variabler anges ijob.propertiesfilen. Oozie ersätter de faktiska värdena vid körning.Skapa en fil med namnet
hive-create-daily-summary-table.hqlfrån din lokala arbetsstation. Använd koden nedan som innehåll för filen.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};Den här frågan skapar en mellanlagringstabell som endast lagrar sammanfattade data för en dag. Anteckna SELECT-instruktionen som beräknar de genomsnittliga fördröjningarna och det totala antalet avstånd som flygs per transportör per dag. Data som infogas i den här tabellen lagras på en känd plats (sökvägen som anges av variabeln hiveDataFolder) så att de kan användas som källa för Sqoop i nästa steg.
Skapa en fil med namnet
workflow.xmlfrån din lokala arbetsstation. Använd koden nedan som innehåll för filen. De här stegen ovan uttrycks som separata åtgärder i Oozie-arbetsflödesfilen.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
De två Hive-frågorna nås via deras sökväg i Azure Storage och de återstående variabelvärdena tillhandahålls av job.properties filen. Den här filen konfigurerar arbetsflödet så att det körs för datumet den 3 januari 2017.
Distribuera och kör Oozie-arbetsflödet
Använd SCP från bash-sessionen för att distribuera ditt Oozie-arbetsflöde (workflow.xml), Hive-frågorna (hive-load-flights-partition.hql och hive-create-daily-summary-table.hql) och jobbkonfigurationen (job.properties). I Oozie kan endast job.properties filen finnas på den lokala lagringen av huvudnoden. Alla andra filer måste lagras i HDFS, i det här fallet Azure Storage. Den Sqoop-åtgärd som används av arbetsflödet beror på en JDBC-drivrutin för kommunikation med din SQL Database, som måste kopieras från huvudnoden till HDFS.
Skapa undermappen
load_flights_by_dayunder användarens sökväg i den lokala lagringen av huvudnoden. Kör följande kommando från den öppna SSH-sessionen:mkdir load_flights_by_dayKopiera alla filer i den aktuella katalogen (
workflow.xmlochjob.propertiesfilerna) upp till undermappenload_flights_by_day. Kör följande kommando från din lokala arbetsstation:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_dayKopiera arbetsflödesfiler till HDFS. Kör följande kommandon från den öppna ssh-sessionen:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_dayKopiera
mssql-jdbc-7.0.0.jre8.jarfrån den lokala huvudnoden till arbetsflödesmappen i HDFS. Ändra kommandot efter behov om klustret innehåller en annan jar-fil.workflow.xmlÄndra efter behov för att återspegla en annan jar-fil. Kör följande kommando från den öppna SSH-sessionen:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_dayKör arbetsflödet. Kör följande kommando från den öppna SSH-sessionen:
oozie job -config job.properties -runObservera statusen med hjälp av Oozie-webbkonsolen. Från Ambari väljer du Oozie, Snabblänkar och sedan Oozie-webbkonsolen. Under fliken Arbetsflödesjobb väljer du Alla jobb.
När statusen är SUCCEEDED frågar du SQL Database-tabellen för att visa de infogade raderna. Gå till fönstret för din SQL Database med hjälp av Azure-portalen, välj Verktyg och öppna Power Query-redigeraren.
SELECT * FROM dailyflights
Nu när arbetsflödet körs för den enda testdagen kan du omsluta arbetsflödet med en koordinator som schemalägger arbetsflödet så att det körs dagligen.
Kör arbetsflödet med en koordinator
Om du vill schemalägga det här arbetsflödet så att det körs dagligen (eller alla dagar i ett datumintervall) kan du använda en koordinator. En koordinator definieras av en XML-fil, till exempel coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
Som du ser skickar majoriteten av koordinatorn bara konfigurationsinformation till arbetsflödesinstansen. Det finns dock några viktiga saker att ta upp.
Punkt 1: Attributen
startochendpå själva elementetcoordinator-appstyr det tidsintervall som koordinatorn körs över.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>En koordinator ansvarar för schemaläggningsåtgärder inom datumintervallet
startochendenligt det intervall som anges avfrequencyattributet. Varje schemalagd åtgärd kör i sin tur arbetsflödet enligt konfigurationen. I koordinatordefinitionen ovan är koordinatorn konfigurerad att köra åtgärder från 1 januari 2017 till 5 januari 2017. Frekvensen anges till en dag av Oozie Expression Language-frekvensuttrycket${coord:days(1)}. Detta resulterar i att koordinatorn schemalägger en åtgärd (och därmed arbetsflödet) en gång per dag. För datumintervall som är tidigare, som i det här exemplet, kommer åtgärden att schemaläggas att köras utan fördröjning. Början av det datum från vilket en åtgärd är schemalagd att köras kallas nominell tid. Om du till exempel vill bearbeta data för den 1 januari 2017 schemalägger koordinatorn åtgärden med en nominell tid 2017-01-01T00:00:00 GMT.Punkt 2: Inom arbetsflödets datumintervall anger elementet
datasetvar du ska leta efter data i HDFS för ett visst datumintervall och konfigurerar hur Oozie avgör om data är tillgängliga ännu för bearbetning.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>Sökvägen till data i HDFS skapas dynamiskt enligt det uttryck som anges i elementet
uri-template. I den här koordinatorn används också en frekvens på en dag med datauppsättningen. Även om start- och slutdatumen för koordinatorelementet styr när åtgärderna schemaläggs (och definierar deras nominella tider) styr datamängdeninitial-instanceochfrequencyberäkningen av det datum som används för atturi-templatekonstruera . I det här fallet anger du den första instansen till en dag före koordinatorns start för att säkerställa att den hämtar data för den första dagen (1 januari 2017). Datauppsättningens datumberäkning flyttas framåt från värdetinitial-instance(12/31/2016) som avancerar i steg av datamängdsfrekvensen (en dag) tills den hittar det senaste datumet som inte passerar den nominella tid som angetts av koordinatorn (2017-01-01T00:00:00 GMT för den första åtgärden).Det tomma
done-flagelementet anger att när Oozie söker efter förekomst av indata vid den angivna tidpunkten avgör Oozie data om de är tillgängliga genom närvaro av en katalog eller fil. I det här fallet är det förekomsten av en csv-fil. Om det finns en csv-fil förutsätter Oozie att data är klara och startar en arbetsflödesinstans för att bearbeta filen. Om det inte finns någon csv-fil förutsätter Oozie att data ännu inte är klara och att körningen av arbetsflödet hamnar i vänteläge.Punkt 3: Elementet
data-inanger den specifika tidsstämpel som ska användas som nominell tid när värdena iuri-templateersätts för den associerade datamängden.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>I det här fallet anger du instansen till uttrycket
${coord:current(0)}, som översätts till att använda den nominella tiden för åtgärden som ursprungligen schemalagts av koordinatorn. Med andra ord, när koordinatorn schemalägger åtgärden att köras med en nominell tid på 2017-01-01, är det 01/01/2017 som används för att ersätta variablerna YEAR (2017) och MONTH (01) i URI-mallen. När URI-mallen har beräknats för den här instansen kontrollerar Oozie om den förväntade katalogen eller filen är tillgänglig och schemalägger nästa körning av arbetsflödet i enlighet med detta.
De tre föregående punkterna kombineras för att ge en situation där koordinatorn schemalägger bearbetningen av källdata dag för dag.
Punkt 1: Koordinatorn börjar med ett nominellt datum 2017-01-01.
Punkt 2: Oozie söker efter tillgängliga data i
sourceDataFolder/2017-01-FlightData.csv.Punkt 3: När Oozie hittar filen schemalägger den en instans av arbetsflödet som bearbetar data för den 1 januari 2017. Oozie fortsätter sedan bearbetningen för 2017-01-02. Den här utvärderingen upprepas till men inkluderar inte 2017-01-05.
Precis som med arbetsflöden definieras konfigurationen av en koordinator i en job.properties fil, som har en superuppsättning av de inställningar som används av arbetsflödet.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
De enda nya egenskaperna som introduceras i den här job.properties filen är:
| Property | Värdekälla |
|---|---|
| oozie.coord.application.path | Anger platsen för coordinator.xml filen som innehåller Oozie-koordinatorn som ska köras. |
| hiveDailyTableNamePrefix | Prefixet som används när du dynamiskt skapar tabellnamnet för mellanlagringstabellen. |
| hiveDataFolderPrefix | Prefixet för sökvägen där alla mellanlagringstabeller ska lagras. |
Distribuera och kör Oozie-koordinatorn
Om du vill köra pipelinen med en koordinator fortsätter du på ett liknande sätt som för arbetsflödet, förutom att du arbetar från en mapp en nivå ovanför mappen som innehåller arbetsflödet. Den här mappkonventionen separerar koordinatorerna från arbetsflödena på disken, så att du kan associera en koordinator med olika underordnade arbetsflöden.
Använd SCP från den lokala datorn för att kopiera koordinatorfilerna till den lokala lagringen av huvudnoden i klustret.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~SSH till huvudnoden.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netKopiera koordinatorfilerna till HDFS.
hdfs dfs -put ./* /oozie/Kör koordinatorn.
oozie job -config job.properties -runKontrollera statusen med hjälp av Oozie-webbkonsolen, den här gången väljer du fliken Koordinatorjobb och sedan Alla jobb.

Välj en koordinatorinstans för att visa listan över schemalagda åtgärder. I det här fallet bör du se fyra åtgärder med nominella tider i intervallet från 1 januari 2017 till 4 januari 2017.

Varje åtgärd i den här listan motsvarar en instans av arbetsflödet som bearbetar en dags datavärde, där starten på den dagen indikeras av den nominella tiden.