Använda selektiv loggning med en skriptåtgärd i Azure HDInsight
Azure Monitor-loggar är en Azure Monitor-tjänst som övervakar dina molnmiljöer och lokala miljöer. Övervakningen hjälper till att upprätthålla deras tillgänglighet och prestanda.
Azure Monitor-loggar samlar in data som genereras av resurser i molnet, resurser i lokala miljöer och andra övervakningsverktyg. Den använder data för att tillhandahålla analys över flera källor. För att hämta analysen aktiverar du funktionen för selektiv loggning med hjälp av en skriptåtgärd för HDInsight i Azure-portalen.
Om selektiv loggning
Selektiv loggning är en del av det övergripande övervakningssystemet i Azure. När du har anslutit klustret till en Log Analytics-arbetsyta och aktiverat selektiv loggning kan du se loggar och mått som HDInsight-säkerhetsloggar, Yarn Resource Manager och systemmått. Du kan övervaka arbetsbelastningar och se hur de påverkar klusterstabiliteten.
Med selektiv loggning kan du aktivera eller inaktivera alla tabeller, eller aktivera valda tabeller, på Log Analytics-arbetsytan. Du kan justera källtypen för varje tabell.
Kommentar
Om Log Analytics installeras om i ett kluster måste du inaktivera alla tabeller och loggtyper igen. Ominstallationen återställer alla konfigurationsfiler till sitt ursprungliga tillstånd.
Överväganden för skriptåtgärder
- Övervakningssystemet använder Metadata Server Daemon (en övervakningsagent) och Fluentd för att samla in loggar med hjälp av ett enhetligt loggningslager.
- Selektiv loggning använder en skriptåtgärd för att inaktivera eller aktivera tabeller och deras loggtyper. Eftersom selektiv loggning inte öppnar några nya portar eller ändrar befintliga säkerhetsinställningar finns det inga säkerhetsändringar.
- Skriptåtgärden körs parallellt på alla angivna noder och ändrar konfigurationsfilerna för att inaktivera eller aktivera tabeller och deras loggtyper.
Förutsättningar
- En Log Analytics-arbetsyta. Du kan se den här arbetsytan som en unik Azure Monitor-loggmiljö med en egen datalagringsplats, datakällor och lösningar. Anvisningar finns i Skapa en Log Analytics-arbetsyta.
- Ett Azure HDInsight-kluster. För närvarande kan du använda funktionen selektiv loggning med följande HDInsight-klustertyper:
- Hadoop
- HBase
- Interaktiv fråga
- Spark
Anvisningar om hur du skapar ett HDInsight-kluster finns i Komma igång med Azure HDInsight.
Aktivera eller inaktivera loggar med hjälp av en skriptåtgärd för flera tabeller och loggtyper
Gå till Skriptåtgärder i klustret och välj Skicka nytt för att starta processen med att skapa en skriptåtgärd.
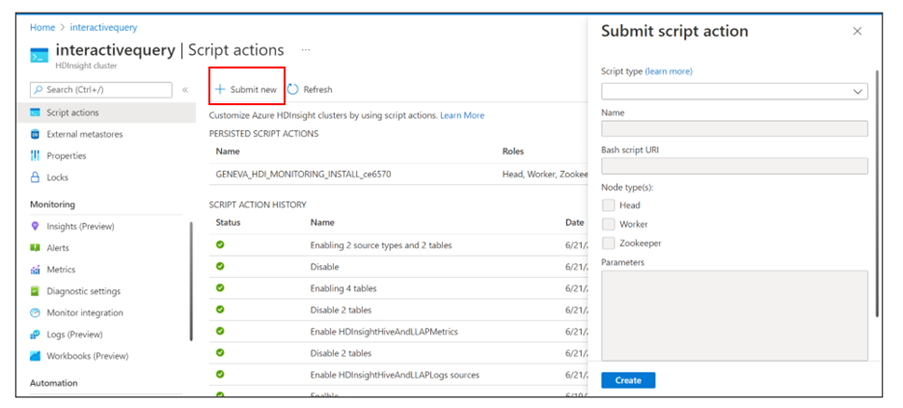
Åtgärdsfönstret Skicka skript visas.
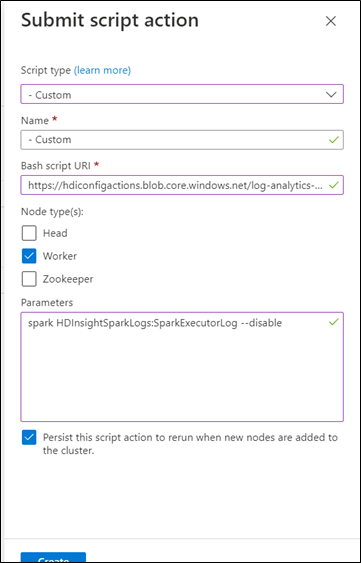
Som skripttyp väljer du Anpassad.
Namnge skriptet. Till exempel: Inaktivera två tabeller och två källor.
Bash-skript-URI:n måste vara en länk till selectiveLoggingScript.sh.
Välj alla nodtyper som gäller för klustret. Alternativen är huvudnod, arbetsnod och ZooKeeper-nod.
Definiera parametrarna. Till exempel:
- Gnista:
spark HDInsightSparkLogs:SparkExecutorLog --disable - Interaktiv fråga:
interactivehive HDInsightSparkLogs:SparkExecutorLog --enable - Hadoop:
hadoop HDInsightSparkLogs:SparkExecutorLog --disable - HBase:
hbase HDInsightSparkLogs: HDInsightHBaseLogs --enable
Mer information finns i avsnittet Parametersyntax .
- Gnista:
Välj Skapa.
Efter några minuter visas en grön bock bredvid skriptåtgärdshistoriken. Det innebär att skriptet har körts.

Du ser dina ändringar på Log Analytics-arbetsytan.
Felsökning
Inga ändringar visas på Log Analytics-arbetsytan
Om du skickar skriptåtgärden men det inte finns några ändringar på Log Analytics-arbetsytan:
Under Instrumentpaneler väljer du Ambari home för att kontrollera felsökningsinformationen.
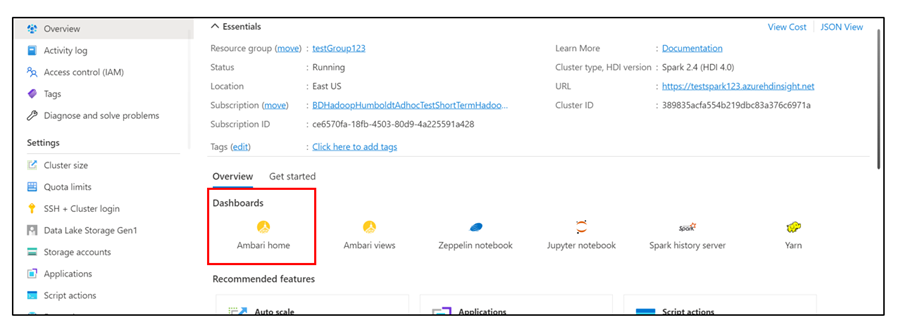
Välj knappen Inställningar.
Välj den senaste skriptkörningen överst i listan över bakgrundsåtgärder.
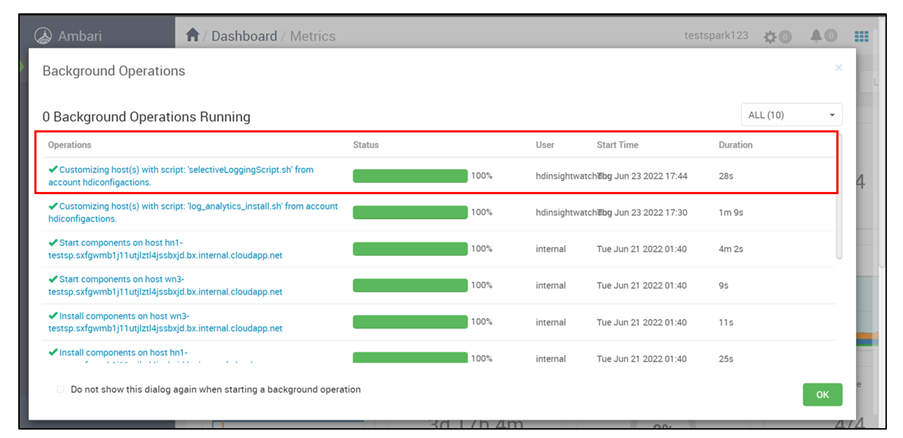
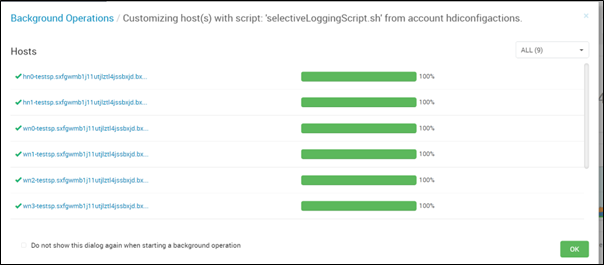
Kontrollera skriptkörningsstatusen i alla noder individuellt.
Kontrollera att parametersyntaxen från avsnittet parametersyntax är korrekt.
Kontrollera att Log Analytics-arbetsytan är ansluten till klustret och att Log Analytics-övervakning är aktiverat.
Kontrollera att du har valt åtgärden Spara det här skriptet för att köra igen när nya noder läggs till i kluster-kryssrutan för den skriptåtgärd som du körde.
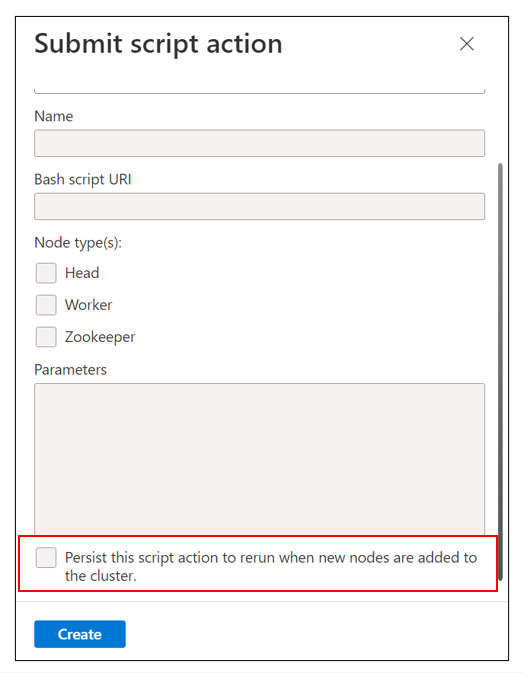
Se om en ny nod har lagts till i klustret nyligen.
Kommentar
Skriptet måste finnas kvar för att skriptet ska kunna köras i det senaste klustret.
Kontrollera att du har valt alla nodtyper som du ville använda för skriptåtgärden.

Skriptåtgärden misslyckades
Om skriptåtgärden visar felstatus i skriptets åtgärdshistorik:
- Kontrollera att parametersyntaxen från avsnittet parametersyntax är korrekt.
- Kontrollera att skriptlänken är korrekt. Det bör vara:
https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/selectiveLoggingScripts/selectiveLoggingScript.sh.
Tabellnamn
Spark-kluster
Följande tabellnamn gäller för olika loggtyper (källor) i Spark-tabeller.
| Källnummer | Tabellnamn | Loggtyper | Description |
|---|---|---|---|
| 1. | HDInsightAmbariCluster-aviseringar | Inga loggtyper | Den här tabellen innehåller Ambari-klusteraviseringar från varje nod i klustret (förutom gränsnoder). Varje avisering är en post i den här tabellen. |
| 2. | HDInsightAmbariSystem-mått | Inga loggtyper | Den här tabellen innehåller systemmått som samlats in från Ambari. Måtten kommer nu från varje nod i klustret (förutom kantnoder) i stället för bara de två huvudnoderna. Varje mått är nu en kolumn och varje mått rapporteras en gång per post. |
| 3. | HDInsightHadoopAnd YarnLogs | Huvudnod: MRJobSummary, Resource Manager, TimelineServer Worker-nod: NodeManager | Den här tabellen innehåller alla loggar som genereras från Hadoop- och YARN-ramverken. |
| 4. | HDInsightSecurityLogs | AmbariAuditLog, AuthLog | Den här tabellen innehåller poster från Ambari-gransknings- och autentiseringsloggarna. |
| 5. | HDInsightSparkLogs | Huvudnod: JupyterLog, LivyLog, SparkThriftDriverLog Worker-nod: SparkExecutorLog, SparkDriverLog | Den här tabellen innehåller alla loggar relaterade till Spark och dess relaterade komponenter: Livy och Jupyter. |
| 6. | HDInsightHadoopAnd YarnMetrics | Inga loggtyper | Den här tabellen innehåller JMX-mått från Hadoop- och YARN-ramverken. Den innehåller samma JMX-mått som de gamla tabellerna för anpassade loggar, plus fler mått som vi ansåg vara viktiga. Vi har lagt till måtten Tidslinjeserver, Node Manager och Jobbhistorikserver. Den innehåller ett mått per post. |
| 7. | HDInsightOozieLogs | Oozie | Den här tabellen innehåller alla loggar som genereras från Oozie-ramverket. |
Interaktiv fråga kluster
Följande tabellnamn är för olika loggtyper (källor) i Interaktiv fråga tabeller.
| Källnummer | Tabellnamn | Loggtyper | Description |
|---|---|---|---|
| 1. | HDInsightAmbariClusterAlerts | Inga loggtyper | Den här tabellen innehåller Ambari-klusteraviseringar från varje nod i klustret (förutom gränsnoder). Varje avisering är en post i den här tabellen. |
| 2. | HDInsightAmbariSystem-mått | Inga loggtyper | Den här tabellen innehåller systemmått som samlats in från Ambari. Måtten kommer nu från varje nod i klustret (förutom kantnoder) i stället för bara de två huvudnoderna. Varje mått är nu en kolumn och varje mått rapporteras en gång per post. |
| 3. | HDInsightHadoopAndYarnLogs | Huvudnod: MRJobSummary, Resource Manager, TimelineServer Worker-nod: NodeManager | Den här tabellen innehåller alla loggar som genereras från Hadoop- och YARN-ramverken. |
| 4. | HDInsightHadoopAndYarnMetrics | Inga loggtyper | Den här tabellen innehåller JMX-mått från Hadoop- och YARN-ramverken. Den innehåller samma JMX-mått som de gamla tabellerna för anpassade loggar, plus fler mått som vi ansåg vara viktiga. Vi har lagt till måtten Tidslinjeserver, Node Manager och Jobbhistorikserver. Den innehåller ett mått per post. |
| 5. | HDInsightHiveAndLLAPLogs | Huvudnod: InteractiveHiveHSILog, InteractiveHiveMetastoreLog, ZeppelinLog | Den här tabellen innehåller loggar som genererats från Hive, LLAP och deras relaterade komponenter: WebHCat och Zeppelin. |
| 6. | HDInsightHiveAndLLAPmetrics | Inga loggtyper | Den här tabellen innehåller JMX-mått från Hive- och LLAP-ramverken. Den innehåller samma JMX-mått som de gamla tabellerna för anpassade loggar. Den innehåller ett mått per post. |
| 7. | HDInsightHiveTezAppStats | Inga loggtyper | |
| 8. | HDInsightSecurityLogs | Huvudnod: AmbariAuditLog, AuthLog ZooKeeper-nod, arbetsnod: AuthLog | Den här tabellen innehåller poster från Ambari-gransknings- och autentiseringsloggarna. |
HBase-kluster
Följande tabellnamn är för olika loggtyper (källor) i HBase-tabeller.
| Källnummer | Tabellnamn | Loggtyper | Description |
|---|---|---|---|
| 1. | HDInsightAmbariClusterAlerts | Inga andra loggtyper | Den här tabellen innehåller Ambari-klusteraviseringar från varje nod i klustret (förutom gränsnoder). Varje avisering är en post i den här tabellen. |
| 2. | HDInsightAmbariSystem-mått | Inga andra loggtyper | Den här tabellen innehåller systemmått som samlats in från Ambari. Måtten kommer nu från varje nod i klustret (förutom kantnoder) i stället för bara de två huvudnoderna. Varje mått är nu en kolumn och varje mått rapporteras en gång per post. |
| 3. | HDInsightHadoopAndYarnLogs | Huvudnod: MRJobSummary, Resource Manager, TimelineServer Worker-nod: NodeManager | Den här tabellen innehåller alla loggar som genereras från Hadoop- och YARN-ramverken. |
| 4. | HDInsightSecurityLogs | Huvudnod: AmbariAuditLog, AuthLog Worker-nod: AuthLog ZooKeeper-nod: AuthLog | Den här tabellen innehåller poster från Ambari-gransknings- och autentiseringsloggarna. |
| 5. | HDInsightHBaseLogs | Huvudnod: HDFSGarbageCollectorLog, HDFSNameNodeLog Worker-nod: PhoenixServerLog, HBaseRegionServerLog, HBaseRestServerLog ZooKeeper-nod: HBaseMasterLog | Den här tabellen innehåller loggar från HBase och dess relaterade komponenter: Phoenix och HDFS. |
| 6. | HDInsightHBaseMetrics | Inga loggtyper | Den här tabellen innehåller JMX-mått från HBase. Den innehåller samma JMX-mått från tabellerna i kolumnen Gammalt schema. Till skillnad från de gamla tabellerna innehåller varje rad ett mått. |
| 7. | HDInsightHadoopAndYarn-mått | Inga loggtyper | Den här tabellen innehåller JMX-mått från Hadoop- och YARN-ramverken. Den innehåller samma JMX-mått som de gamla tabellerna för anpassade loggar, plus fler mått som vi ansåg vara viktiga. Vi har lagt till måtten Tidslinjeserver, Node Manager och Jobbhistorikserver. Den innehåller ett mått per post. |
Hadoop-kluster
Följande tabellnamn är för olika loggtyper (källor) i Hadoop-tabeller.
| Källnummer | Tabellnamn | Loggtyper | Description |
|---|---|---|---|
| 1. | HDInsightAmbariClusterAlerts | Inga loggtyper | Den här tabellen innehåller Ambari-klusteraviseringar från varje nod i klustret (förutom gränsnoder). Varje avisering är en post i den här tabellen. |
| 2. | HDInsightAmbariSystem-mått | Inga loggtyper | Den här tabellen innehåller systemmått som samlats in från Ambari. Måtten kommer nu från varje nod i klustret (förutom kantnoder) i stället för bara de två huvudnoderna. Varje mått är nu en kolumn och varje mått rapporteras en gång per post. |
| 3. | HDInsightHadoopAndYarnLogs | Huvudnod: MRJobSummary, Resource Manager, TimelineServer Worker-nod: NodeManager | Den här tabellen innehåller alla loggar som genereras från Hadoop- och YARN-ramverken. |
| 4. | HDInsightHadoopAndYarnMetrics | Inga loggtyper | Den här tabellen innehåller JMX-mått från Hadoop- och YARN-ramverken. Den innehåller samma JMX-mått som de gamla tabellerna för anpassade loggar, plus fler mått som vi ansåg vara viktiga. Vi har lagt till måtten Tidslinjeserver, Node Manager och Jobbhistorikserver. Den innehåller ett mått per post. |
| 5. | HDInsightHiveAndLLAPLogs | Huvudnod: HiveMetastoreLog, HiveServer2Log, WebHcatLog | Den här tabellen innehåller loggar som genererats från Hive, LLAP och deras relaterade komponenter: WebHCat och Zeppelin. |
| 6. | HDInsight Hive- och LLAP-mått | Inga loggtyper | Den här tabellen innehåller JMX-mått från Hive- och LLAP-ramverken. Den innehåller samma JMX-mått som de gamla tabellerna för anpassade loggar. Den innehåller ett mått per post. |
| 7. | HDInsight-säkerhetsloggar | Huvudnod: AmbariAuditLog, AuthLog ZooKeeper-nod: AuthLog | Den här tabellen innehåller poster från Ambari-gransknings- och autentiseringsloggarna. |
Parametersyntax
Parametrar definierar klustertyp, tabellnamn, källnamn och åtgärd.
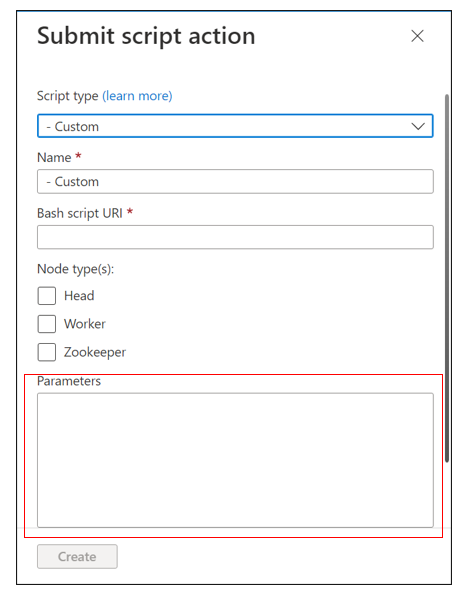
En parameter innehåller tre delar:
- Klustertyp
- Tabeller och loggtyper
- Åtgärd (antingen
--disableeller--enable)
Syntax för flera tabeller
När du har flera tabeller avgränsas de med kommatecken. Till exempel:
spark HDInsightSecurityLogs, HDInsightAmbariSystemMetrics --disable
hbase HDInsightSecurityLogs, HDInsightAmbariSystemMetrics --enable
Syntax för flera källtyper eller loggtyper
När du har flera källtyper eller loggtyper separeras de med ett blanksteg.
Om du vill inaktivera en källa skriver du tabellnamnet som innehåller loggtyperna, följt av ett kolon och sedan namnet på den riktiga loggtypen:
TableName : LogTypeName
Anta till exempel att det spark HDInsightSecurityLogs är en tabell som har två loggtyper: AmbariAuditLog och AuthLog. Om du vill inaktivera båda loggtyperna skulle rätt syntax vara:
spark HDInsightSecurityLogs: AmbariAuditLog AuthLog --disable
Syntax för flera tabeller och källtyper
Om du behöver inaktivera två tabeller och två källtyper använder du följande syntax:
- Spark:
InteractiveHiveMetastoreLogloggtyp iHDInsightHiveAndLLAPLogstabellen - Hbase:
InteractiveHiveHSILogloggtyp iHDInsightHiveAndLLAPLogstabellen - Hadoop:
HDInsightHiveAndLLAPMetricstable - Hadoop:
HDInsightHiveTezAppStatstable
Avgränsa tabellerna med kommatecken. Ange källor med hjälp av ett kolon efter tabellnamnet där de finns.
Rätt parametersyntax för dessa fall är:
interactivehive HDInsightHiveAndLLAPLogs: InteractiveHiveMetastoreLog, HDInsightHiveAndLLAPMetrics, HDInsightHiveTezAppStats, HDInsightHiveAndLLAPLogs: InteractiveHiveHSILog --enable