Använd de utökade funktionerna i Apache Spark-historikservern för att felsöka och diagnostisera Spark-program
Den här artikeln visar hur du använder de utökade funktionerna i Apache Spark-historikservern för att felsöka och diagnostisera slutförda eller köra Spark-program. Tillägget innehåller fliken Data , fliken Graph och fliken Diagnos . På fliken Data kan du kontrollera indata och utdata för Spark-jobbet. På fliken Graph kan du kontrollera dataflödet och spela upp jobbdiagrammet igen. På fliken Diagnos kan du referera till funktionerna Förskjutning av data, Tidsförskjutning och Användningsanalys för körverktyg.
Få åtkomst till Spark-historikservern
Spark-historikservern är webbgränssnittet för slutförda och köra Spark-program. Du kan öppna den antingen från Azure-portalen eller från en URL.
Öppna webbgränssnittet för Spark-historikservern från Azure-portalen
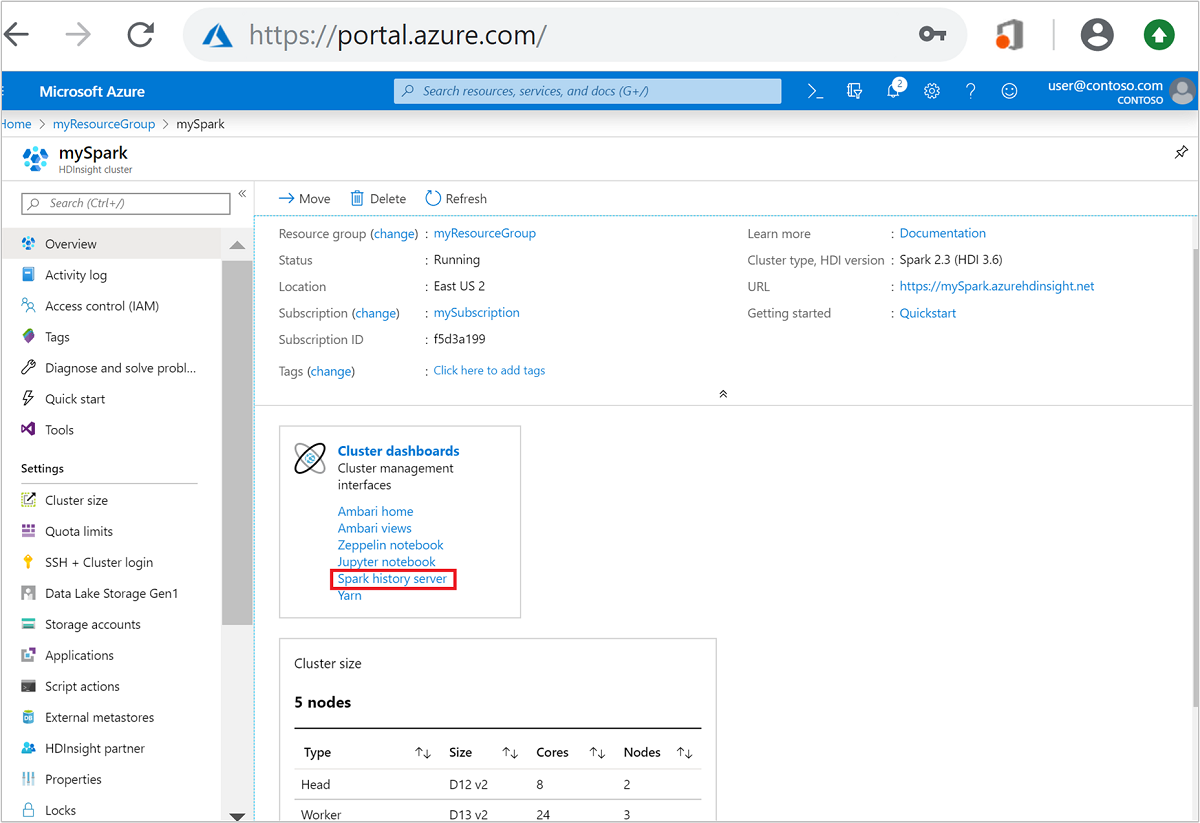
Öppna Spark-klustret från Azure-portalen. Mer information finns i Lista och visa kluster.
Välj Spark-historikserver från Klusterinstrumentpaneler. När du uppmanas till det anger du administratörsautentiseringsuppgifterna för Spark-klustret.
 azure-portalen." border="true":::
azure-portalen." border="true":::
Öppna webbgränssnittet för Spark-historikservern efter URL
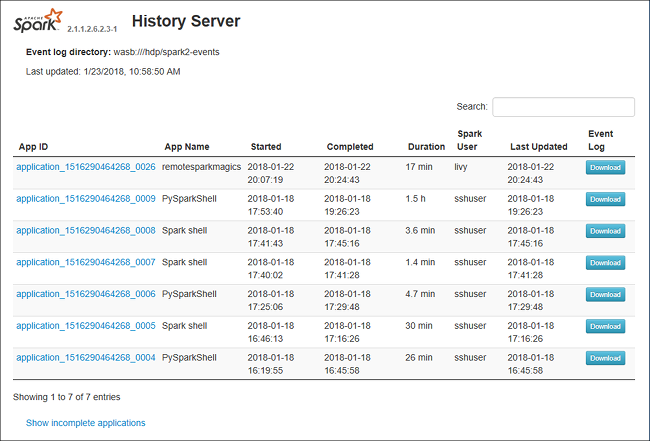
Öppna Spark-historikservern genom att bläddra till https://CLUSTERNAME.azurehdinsight.net/sparkhistory, där CLUSTERNAME är namnet på ditt Spark-kluster.
Spark History Server-webbgränssnittet kan se ut ungefär så här:
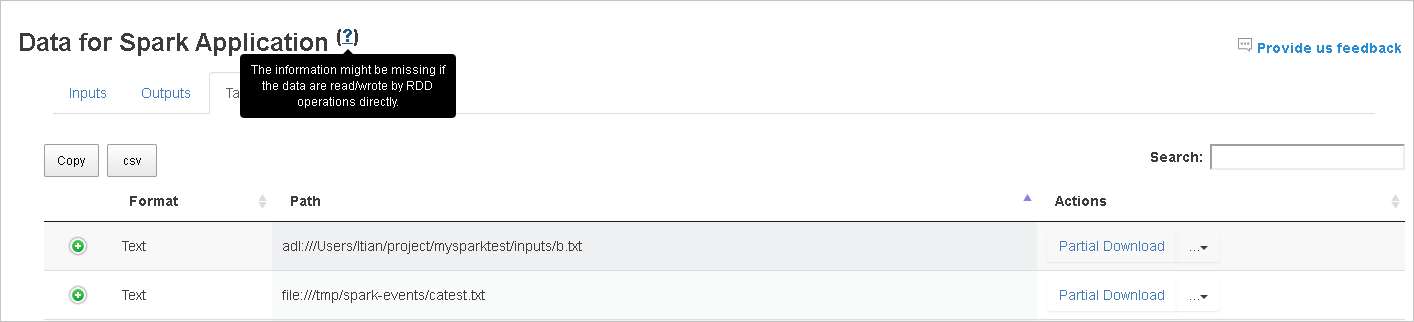
Använd fliken Data i Spark-historikservern
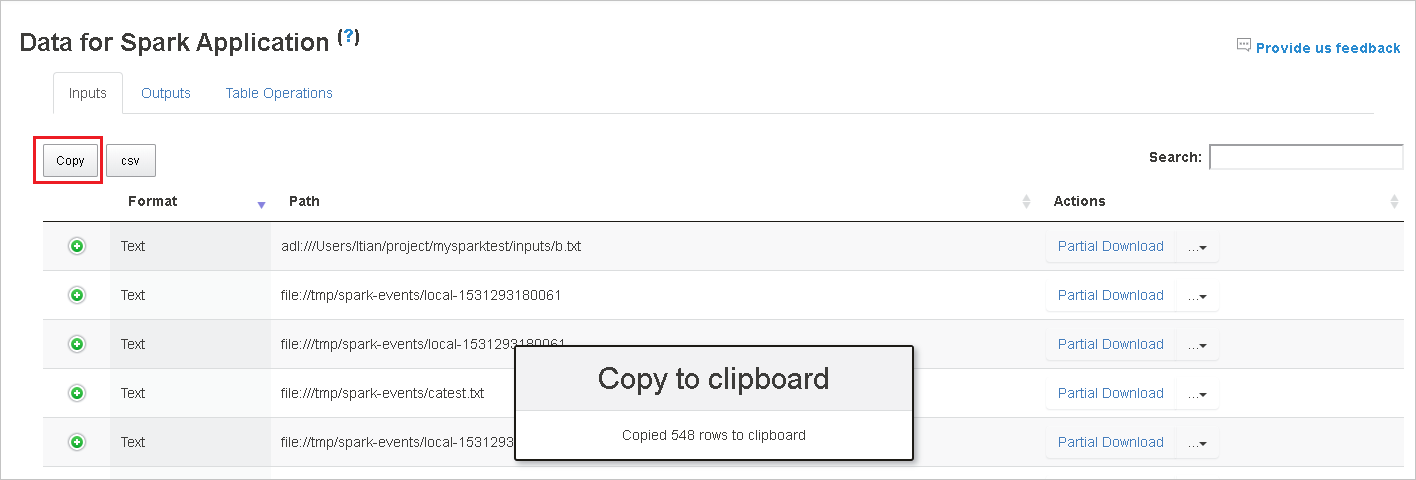
Välj jobb-ID:t och välj sedan Data på verktygsmenyn för att se datavyn.
Granska indata, utdata och tabellåtgärder genom att välja de enskilda flikarna.

Kopiera alla rader genom att välja knappen Kopiera .
Spara alla data som en . CSV-fil genom att välja csv-knappen .
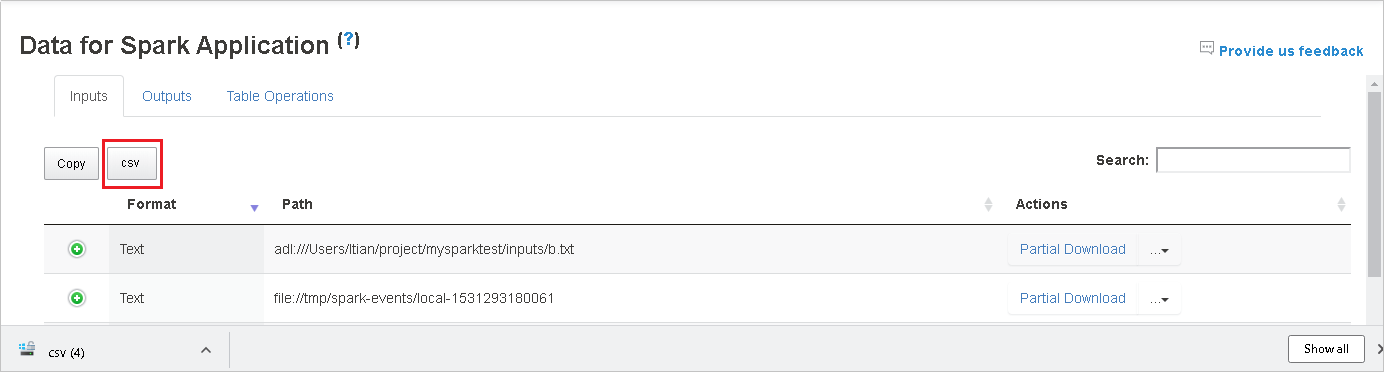
Sök efter data genom att ange nyckelord i fältet Sök . Sökresultaten visas omedelbart.
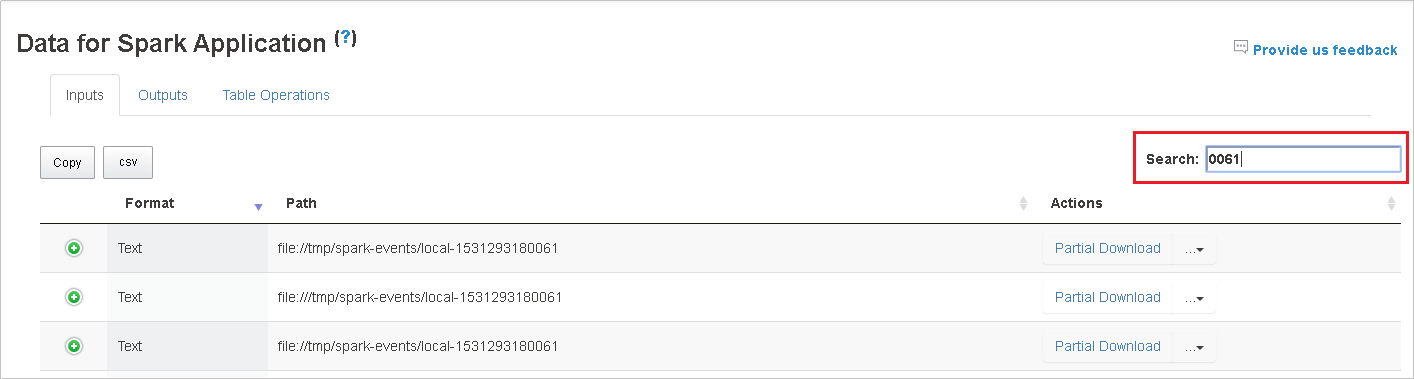
Välj kolumnrubriken för att sortera tabellen. Välj plustecknet för att expandera en rad för att visa mer information. Välj minustecknet för att dölja en rad.
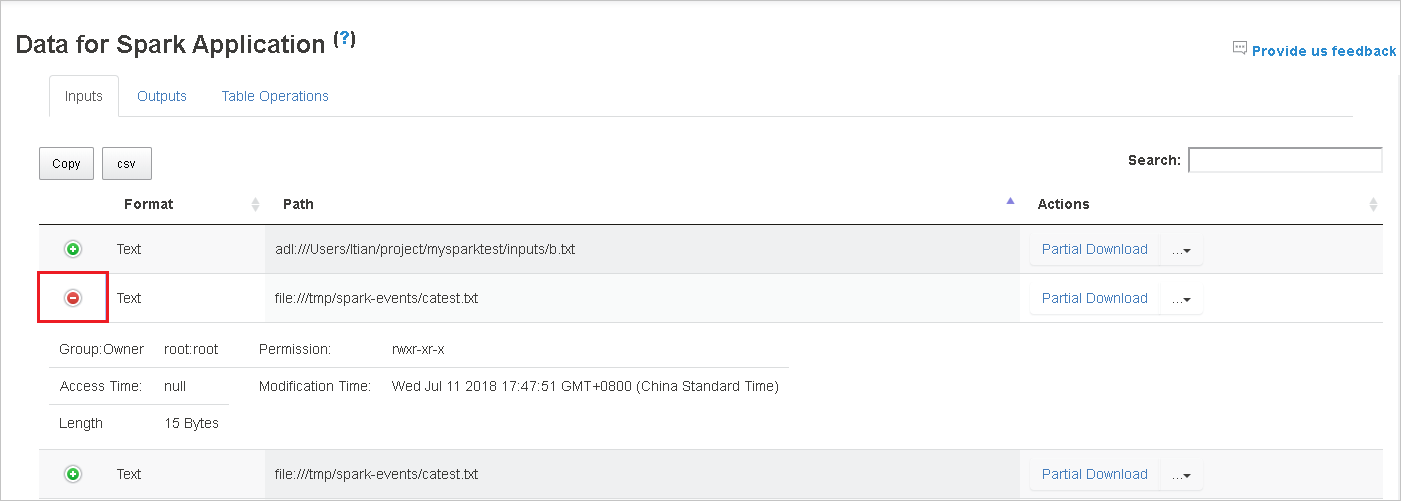
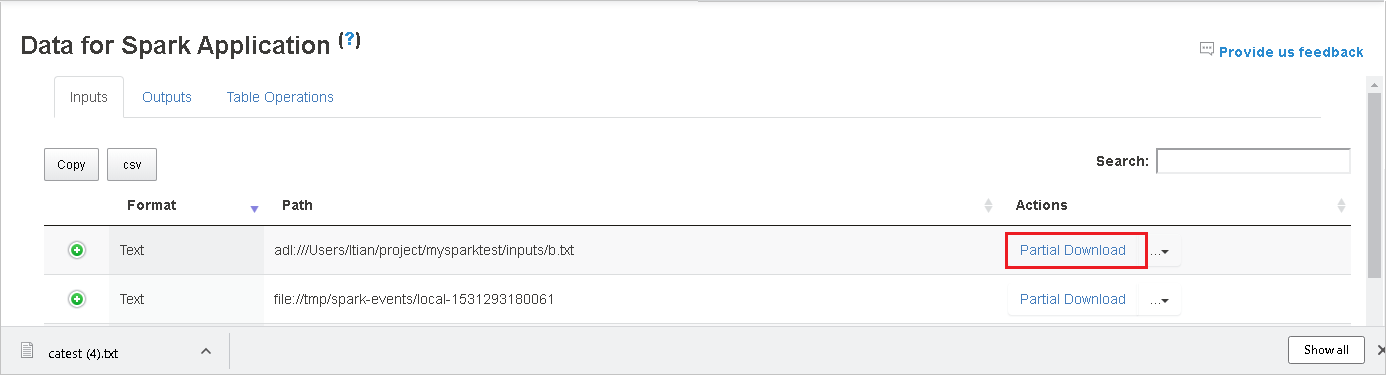
Ladda ned en enskild fil genom att välja knappen Partiell nedladdning till höger. Den valda filen laddas ned lokalt. Om filen inte längre finns öppnas en ny flik för att visa felmeddelandena.
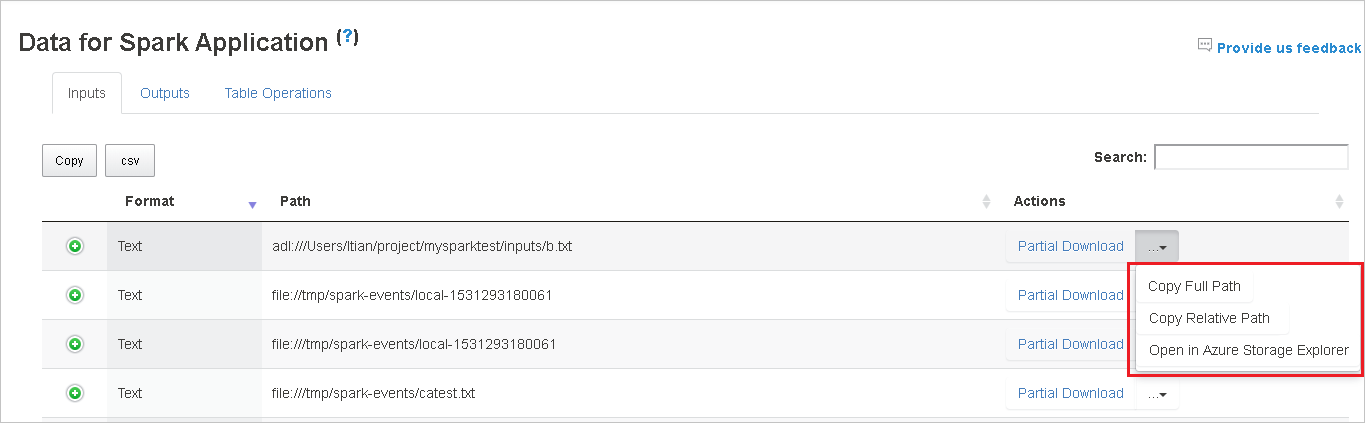
Kopiera en fullständig sökväg eller en relativ sökväg genom att välja alternativet Kopiera fullständig sökväg eller Kopiera relativ sökväg , som expanderar från nedladdningsmenyn. För Azure Data Lake Storage-filer väljer du Öppna i Azure Storage Explorer för att starta Azure Storage Explorer och leta upp mappen efter inloggningen.
Om det finns för många rader att visa på en enda sida väljer du sidnumren längst ned i tabellen för att navigera.

Om du vill ha mer information hovra över eller välj frågetecknet bredvid Data för Spark-programmet för att visa knappbeskrivningen.
Om du vill skicka feedback om problem väljer du Ge oss feedback.
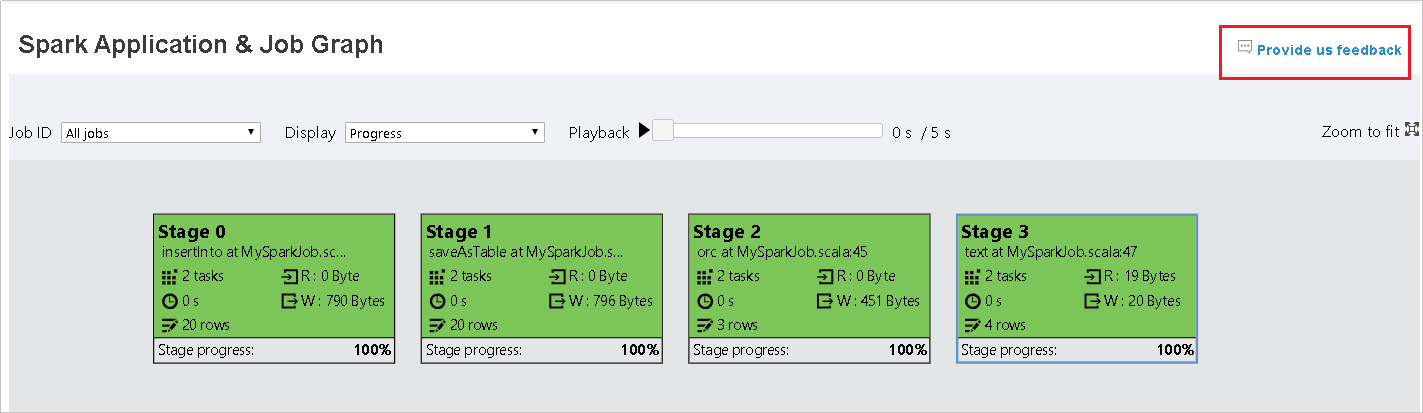
Använd fliken Graph i Spark-historikservern
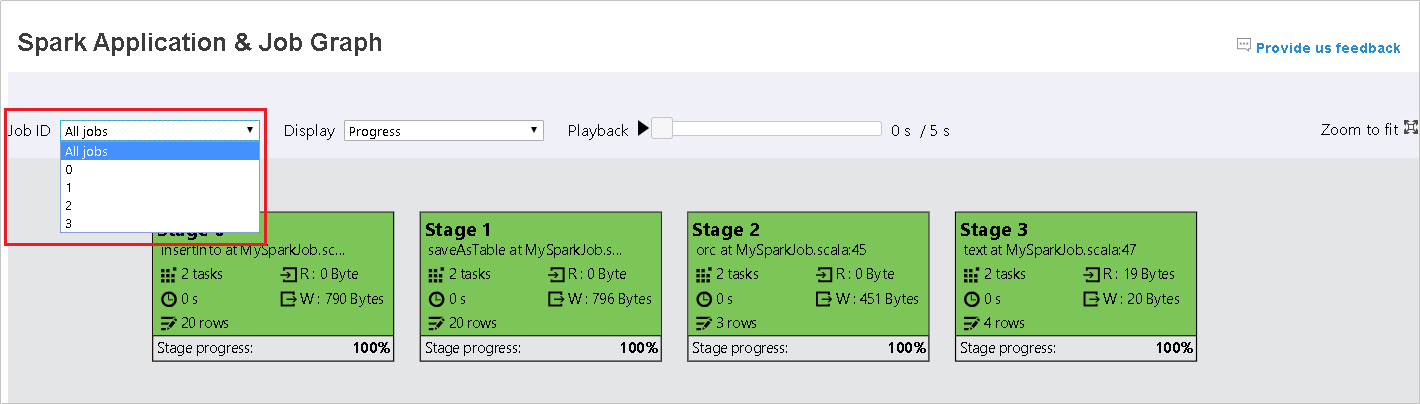
Välj jobb-ID:t och välj sedan Graph på verktygsmenyn för att se jobbdiagrammet. Som standard visar diagrammet alla jobb. Filtrera resultatet med hjälp av listrutan Jobb-ID .
Förloppet är markerat som standard. Kontrollera dataflödet genom att välja Läs eller Skriveti listrutan Visa .
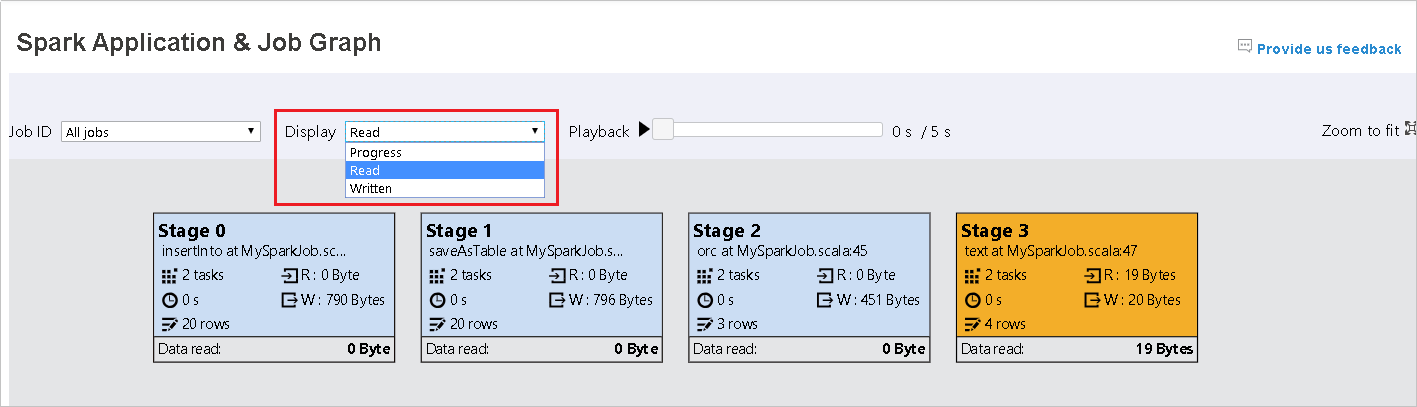
Bakgrundsfärgen för varje uppgift motsvarar en värmekarta.

Färg beskrivning Grönt Jobbet har slutförts. Orange Aktiviteten misslyckades, men det påverkar inte det slutliga resultatet av jobbet. Dessa uppgifter har duplicerade eller återförsöksinstanser som kan lyckas senare. Blått Uppgiften körs. Vitt Uppgiften väntar på att köras eller så har fasen hoppat över. Röd Uppgiften misslyckades. 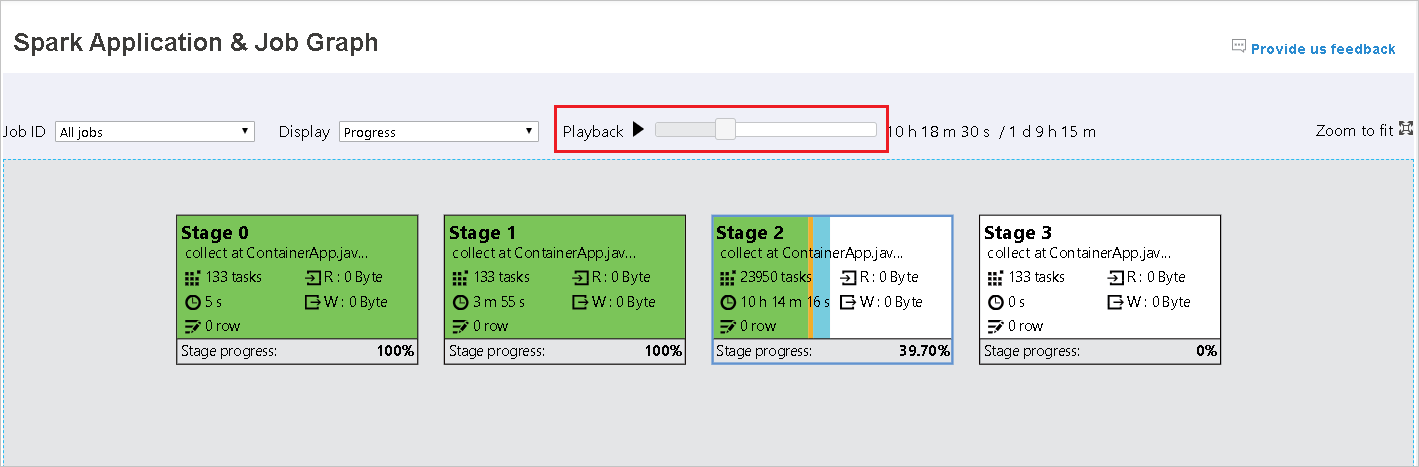
De överhoppade stegen visas i vitt.

Kommentar
Uppspelning är tillgänglig för slutförda jobb. Välj knappen Uppspelning för att spela upp jobbet igen. Stoppa jobbet när som helst genom att välja stoppknappen. När ett jobb spelas upp visas dess status efter färg. Uppspelning stöds inte för ofullständiga jobb.
Rulla om du vill zooma in eller ut på jobbdiagrammet eller välj Zooma så att det passar för skärmen.
När aktiviteter misslyckas hovra över grafnoden för att se knappbeskrivningen och välj sedan fasen för att öppna den på en ny sida.
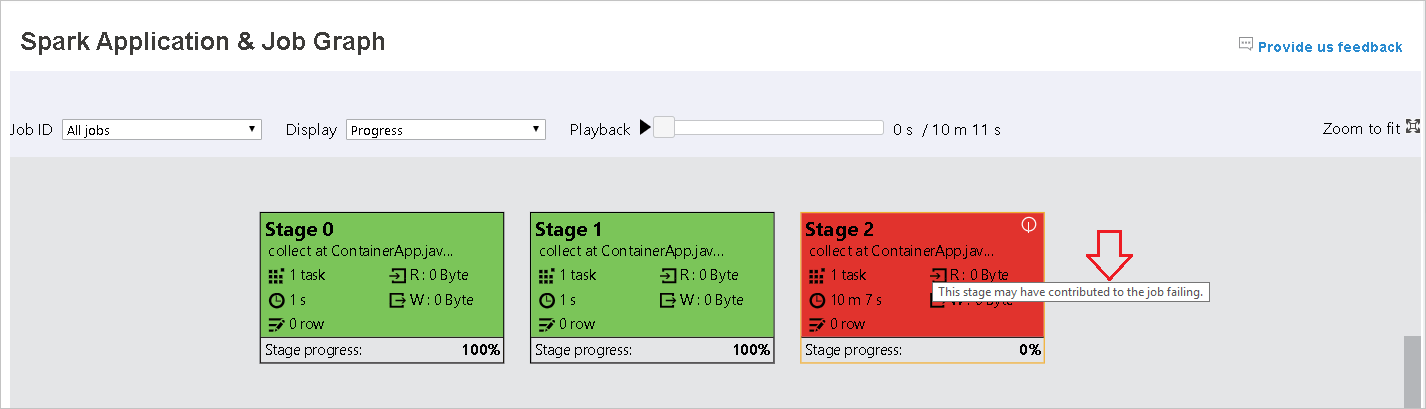
På sidan Spark-program och jobbdiagram visar stegen knappbeskrivningar och små ikoner om uppgifterna uppfyller dessa villkor:
Datasnedvridning: Dataläsningsstorlek > genomsnittlig dataläsningsstorlek för alla aktiviteter i den här fasen * 2 och dataläsningsstorlek > 10 MB.
Tidsförskjutning: Genomsnittlig körningstid > för alla aktiviteter i det här steget * 2 och körningstid > 2 minuter.
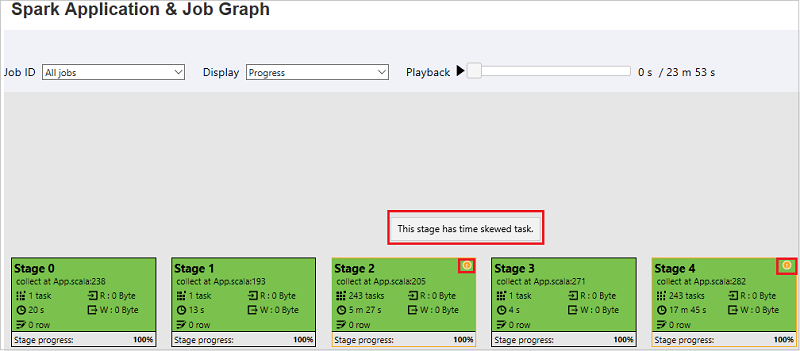
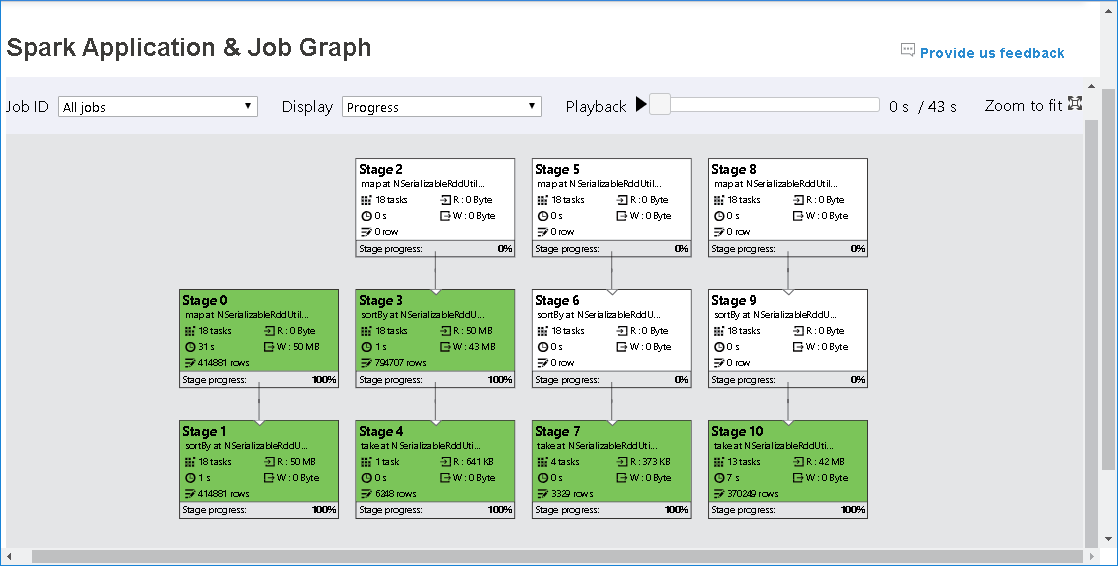
Jobbdiagramnoden visar följande information om varje steg:
ID
Namn eller beskrivning
Totalt aktivitetsnummer
Läsdata: summan av indatastorleken och shuffle-lässtorleken
Dataskrivning: summan av utdatastorleken och shuffle-skrivstorleken
Körningstid: tiden mellan starttiden för det första försöket och slutförandetiden för det senaste försöket
Radantal: summan av indataposter, utdataposter, blanda läsposter och blanda skrivposter
Förlopp
Kommentar
Som standard visar jobbdiagramnoden information från det senaste försöket i varje steg (förutom körningstid för steg). Men under uppspelningen visar jobbdiagramnoden information om varje försök.
Kommentar
För dataläsnings- och dataskrivningsstorlekar använder vi 1 MB = 1 000 KB = 1 000 * 1 000 byte.
Skicka feedback om problem genom att välja Ge oss feedback.
Använd fliken Diagnos i Spark-historikservern
Välj jobb-ID:t och välj sedan Diagnos på verktygsmenyn för att se jobbdiagnosvyn. Fliken Diagnos innehåller analys av dataförskjutning, tidsförskjutning och körningsanvändning.
Granska analys av dataförskjutning, tidsförskjutning och körningsanvändning genom att välja flikarna.
Dataskevning
Välj fliken Dataförskjutning . Motsvarande skeva uppgifter visas baserat på de angivna parametrarna.
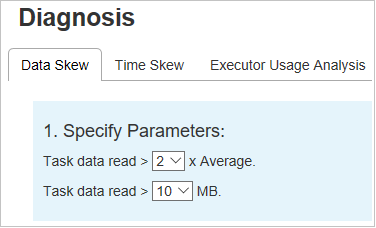
Ange parametrar
I avsnittet Ange parametrar visas parametrarna som används för att identifiera datasnedvridning. Standardregeln är: Uppgiftsdataläsningen är större än tre gånger den genomsnittliga läsningen av aktivitetsdata och läsningen av aktivitetsdata är mer än 10 MB. Om du vill definiera en egen regel för skeva uppgifter kan du välja dina parametrar. Avsnitten Förskjutet stadium och Skevt diagram uppdateras i enlighet med detta.
Skev fas
Avsnittet Skev fas visar faser som har skeva uppgifter som uppfyller de angivna kriterierna. Om det finns mer än en skev uppgift i ett stadium visar avsnittet Skev fas endast den mest skeva uppgiften (det vill:s, den största datan för datasnedställning).

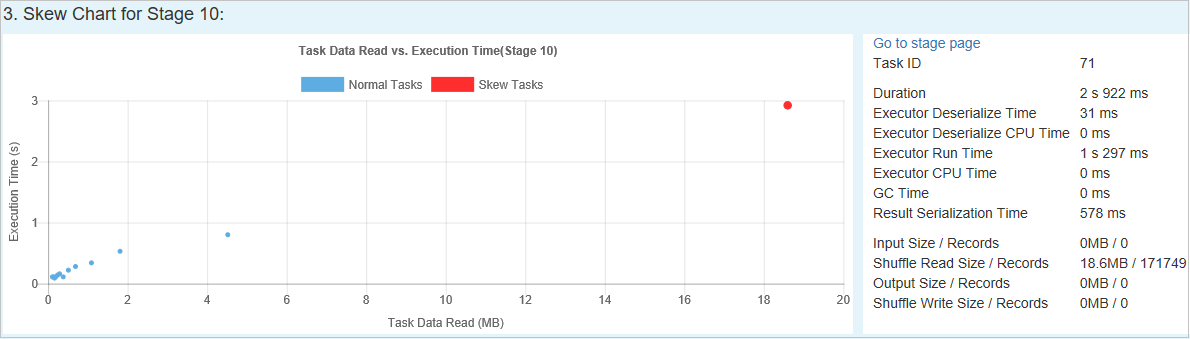
Skevt diagram
När du väljer en rad i tabellen Skev fas visar skevningsdiagrammet mer information om aktivitetsdistribution baserat på dataläsnings- och körningstid. De skeva uppgifterna är markerade i rött och de normala aktiviteterna är markerade i blått. För prestandaövervägande visar diagrammet upp till 100 exempeluppgifter. Uppgiftsinformationen visas i panelen längst ned till höger.
Tidsförskjutning
Fliken Tidsförskjutning visar skeva uppgifter baserat på körningstid för aktiviteter.
Ange parametrar
I avsnittet Ange parametrar visas parametrarna som används för att identifiera tidsförskjutning. Standardregeln är: Körningstiden för aktiviteten är större än tre gånger den genomsnittliga körningstiden och körningstiden för aktiviteter är större än 30 sekunder. Du kan ändra parametrarna baserat på dina behov. Diagrammet Skevt stadium och skevt visar motsvarande faser och uppgifter, precis som på fliken Dataförskjutning.
När du väljer Tidsförskjutning visas det filtrerade resultatet i avsnittet Skev fas enligt de parametrar som anges i avsnittet Ange parametrar . När du väljer ett objekt i avsnittet Skev fas , skapas motsvarande diagram i det tredje avsnittet och uppgiftsinformationen visas i den nedre högra panelen.
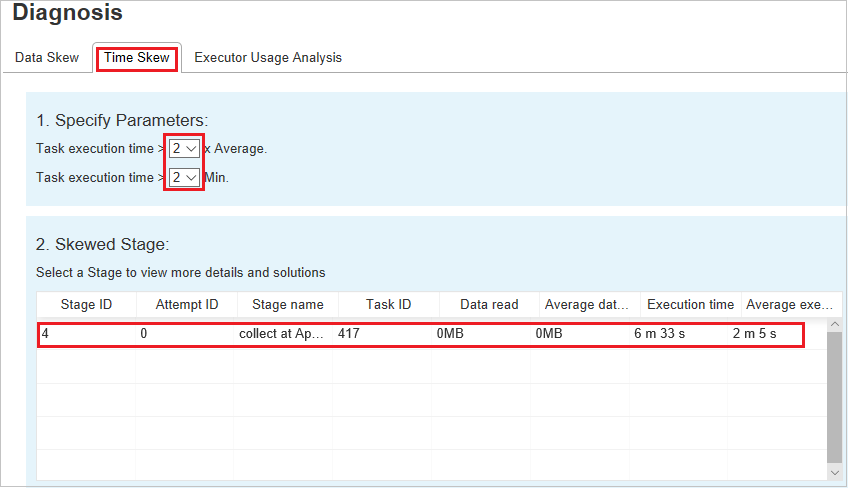
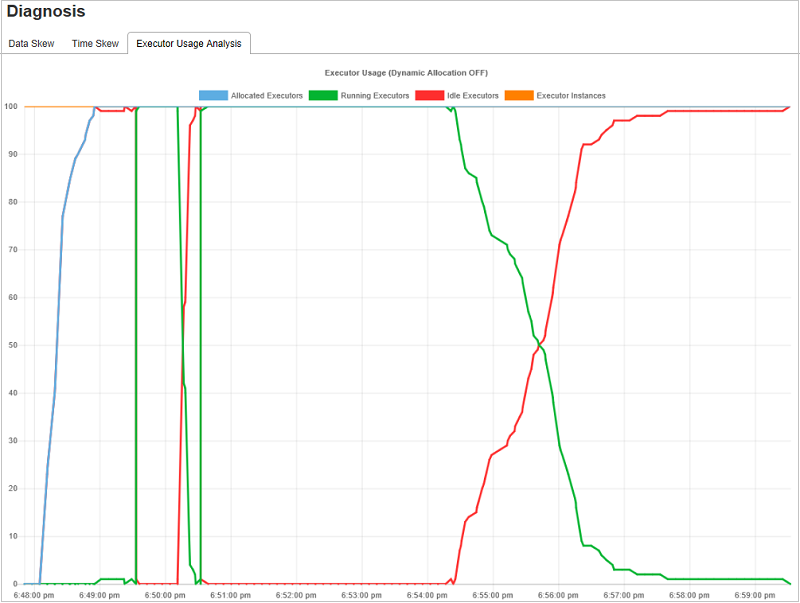
Diagram över körningsanvändningsanalys
Användningsdiagrammet för exekutor visar jobbets faktiska körallokering och körningsstatus.
När du väljer Användningsanalys för köreller skapas fyra olika kurvor för körningsanvändning: Allokerade köre, körekutorer, inaktiva utförare och Max Executor Instances. Varje köre som har lagts till eller den borttagna körhändelsen ökar eller minskar de allokerade körarna. Du kan kontrollera händelsetidslinjen på fliken Jobb för fler jämförelser.
Välj färgikonen för att välja eller avmarkera motsvarande innehåll i alla utkast.

Vanliga frågor
Hur gör jag för att återgå till communityversionen?
Utför följande steg för att återgå till communityversionen.
Öppna klustret i Ambari.
Gå till Spark2-konfigurationer>.
Välj Anpassade spark2-standardvärden.
Välj Lägg till egenskap ....
Lägg till spark.ui.enhancement.enabled=false och spara sedan det.
Egenskapen anges till false nu.
Välj Spara för att spara konfiguration.

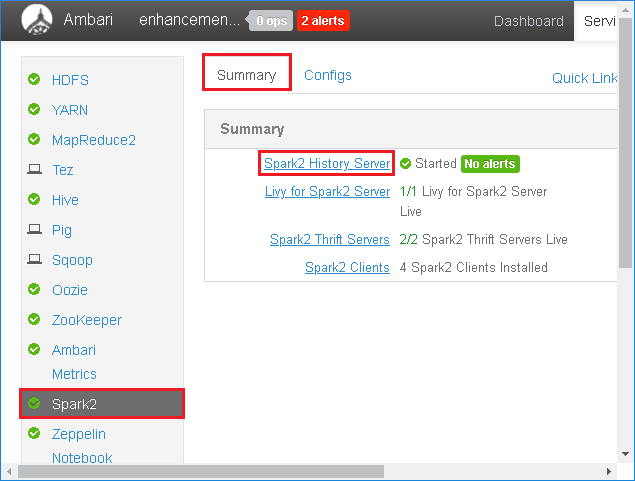
Välj Spark2 i den vänstra panelen. Välj sedan Spark2-historikserver på fliken Sammanfattning.
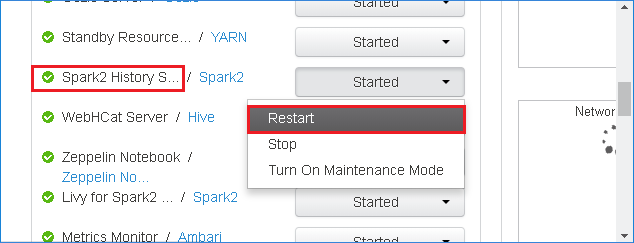
Om du vill starta om Spark-historikservern väljer du knappen Startad till höger om Spark2-historikservern och väljer sedan Starta om från den nedrullningsbara menyn.
Uppdatera webbgränssnittet för Spark-historikservern. Den återgår till communityversionen.
Hur gör jag för att ladda upp en Spark History Server-händelse för att rapportera den som ett problem?
Om du stöter på ett fel i Spark-historikservern gör du följande för att rapportera händelsen.
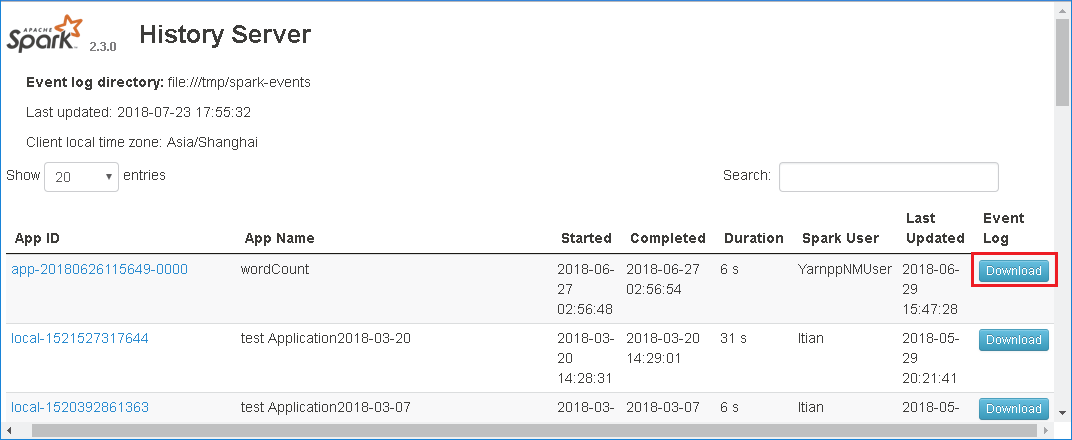
Ladda ned händelsen genom att välja Ladda ned i webbgränssnittet för Spark-historikservern.
Välj Ge oss feedback på sidan Spark-program och jobbdiagram .
Ange rubriken och en beskrivning av felet. Dra sedan filen .zip till redigeringsfältet och välj Skicka nytt problem.

Hur gör jag för att uppgradera en .jar fil i ett snabbkorrigeringsscenario?
Om du vill uppgradera med en snabbkorrigering använder du följande skript, som uppgraderar spark-enhancement.jar*.
upgrade_spark_enhancement.sh:
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
Användning
upgrade_spark_enhancement.sh https://${jar_path}
Exempel
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
Använda bash-filen från Azure-portalen
Slutför en skriptåtgärd med följande parametrar.
Property Värde Typ av skript -Anpassade Name UpgradeJar Bash-skript-URI https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.shNodtyper Head, Worker Parametrar https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar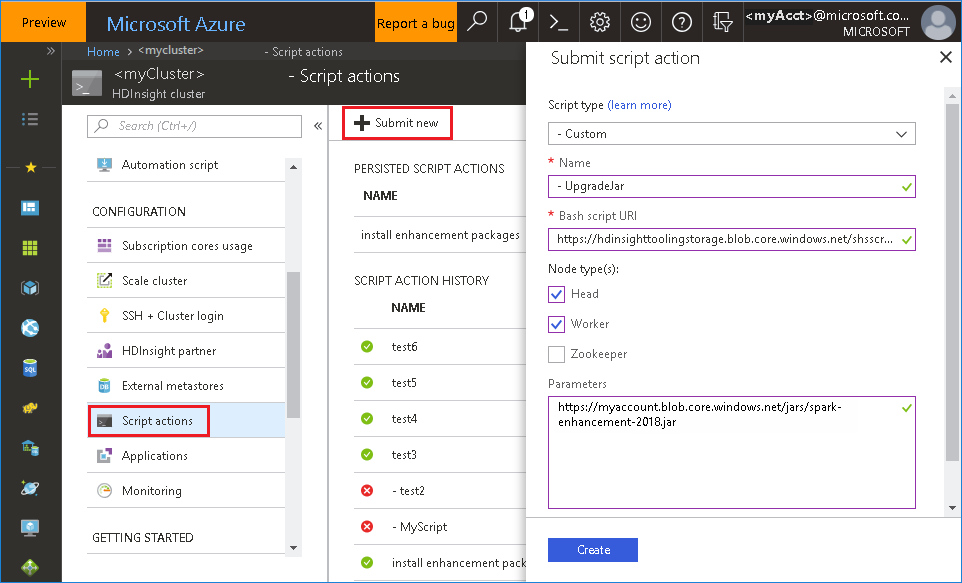
Kända problem
För närvarande fungerar Spark History Server endast för Spark 2.3 och 2.4.
Indata och utdata som använder RDD visas inte på fliken Data .
Nästa steg
Förslag
Om du har feedback eller stöter på problem när du använder det här verktyget skickar du ett e-postmeddelande till (hdivstool@microsoft.com).