Förbättra prestanda för Apache Spark-arbetsbelastningar med hjälp av Azure HDInsight IO Cache
Kommentar
- IO Cache stöds till Spark 2.3 och stöds inte i Spark 2.4 (HDInsight 4.0) och Spark 3.1.2 (HDInsight 5.0)
IO Cache är en tjänst för datacachelagring för Azure HDInsight som förbättrar prestandan för Apache Spark-jobb. IO Cache fungerar också med Apache TEZ - och Apache Hive-arbetsbelastningar , som kan köras på Apache Spark-kluster . IO Cache använder en cachelagringskomponent med öppen källkod med namnet RubiX. RubiX är en lokal diskcache för användning med stordataanalysmotorer som har åtkomst till data från molnlagringssystem. RubiX är unikt bland cachelagringssystem, eftersom det använder SSD:er (Solid-State Drives) i stället för att reservera driftminne för cachelagring. IO Cache-tjänsten startar och hanterar RubiX-metadataservrar på varje arbetsnod i klustret. Den konfigurerar också alla tjänster i klustret för transparent användning av RubiX-cache.
De flesta SSD:er ger mer än 1 GByte per sekund bandbredd. Den här bandbredden, som kompletteras av operativsystemets minnesinterna filcache, ger tillräckligt med bandbredd för att läsa in motorer för bearbetning av stordatabearbetning, till exempel Apache Spark. Driftminnet är tillgängligt för Apache Spark för att bearbeta mycket minnesberoende uppgifter, till exempel shuffles. Med exklusiv användning av driftminne kan Apache Spark uppnå optimal resursanvändning.
Kommentar
IO Cache använder för närvarande RubiX som en cachelagringskomponent, men detta kan ändras i framtida versioner av tjänsten. Använd I/O Cache-gränssnitt och ta inga beroenden direkt på RubiX-implementeringen. I/O-cache stöds endast med Azure BLOB Storage just nu.
Fördelar med Azure HDInsight IO Cache
Att använda IO Cache ger en prestandaökning för jobb som läser data från Azure Blob Storage.
Du behöver inte göra några ändringar i dina Spark-jobb för att se prestandaökningar när du använder IO Cache. När I/O Cache är inaktiverat läser den här Spark-koden data via fjärranslutning från Azure Blob Storage: spark.read.load('wasbs:///myfolder/data.parquet').count(). När I/O Cache aktiveras orsakar samma kodrad en cachelagrad läsning via IO Cache. Vid följande läsningar läss data lokalt från SSD. Arbetsnoder i HDInsight-kluster är utrustade med lokalt anslutna, dedikerade SSD-enheter. HDInsight IO Cache använder dessa lokala SSD:er för cachelagring, vilket ger lägsta svarstid och maximerar bandbredden.
Komma igång
Azure HDInsight IO Cache inaktiveras som standard i förhandsversionen. IO Cache är tillgängligt i Azure HDInsight 3.6+ Spark-kluster som kör Apache Spark 2.3. Gör följande för att aktivera IO Cache på HDInsight 4.0:
Från en webbläsare går du till
https://CLUSTERNAME.azurehdinsight.net, därCLUSTERNAMEär namnet på klustret.Välj I/O Cache-tjänsten till vänster.
Välj Åtgärder (Tjänståtgärder i HDI 3.6) och Aktivera.
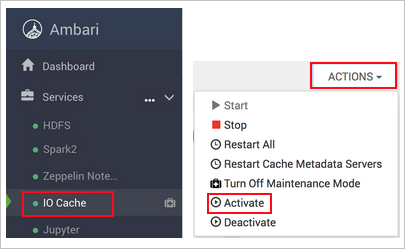
Bekräfta omstarten av alla berörda tjänster i klustret.
Kommentar
Även om förloppsindikatorn visar aktiverad aktiveras inte I/O Cache förrän du startar om de andra berörda tjänsterna.
Felsökning
Du kan få diskutrymmesfel som kör Spark-jobb när du har aktiverat I/O Cache. Dessa fel uppstår eftersom Spark också använder lokal disklagring för att lagra data under blandningsåtgärder. Spark kan få slut på SSD-utrymme när IO Cache är aktiverat och utrymmet för Spark-lagring minskar. Mängden utrymme som används av IO Cache är som standard hälften av det totala SSD-utrymmet. Diskutrymmesanvändningen för IO Cache kan konfigureras i Ambari. Om du får diskutrymmesfel minskar du mängden SSD-utrymme som används för IO Cache och startar om tjänsten. Gör följande för att ändra utrymmesuppsättningen för IO Cache:
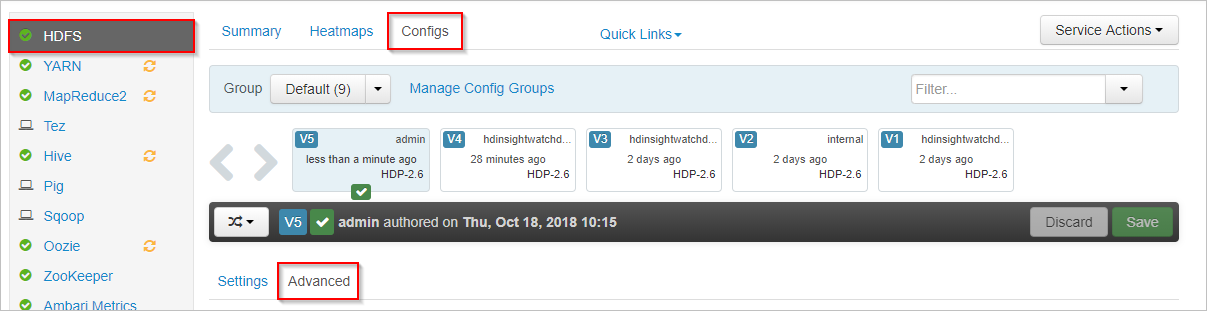
I Apache Ambari väljer du HDFS-tjänsten till vänster.
Välj flikarna Konfigurationer och Avancerat .
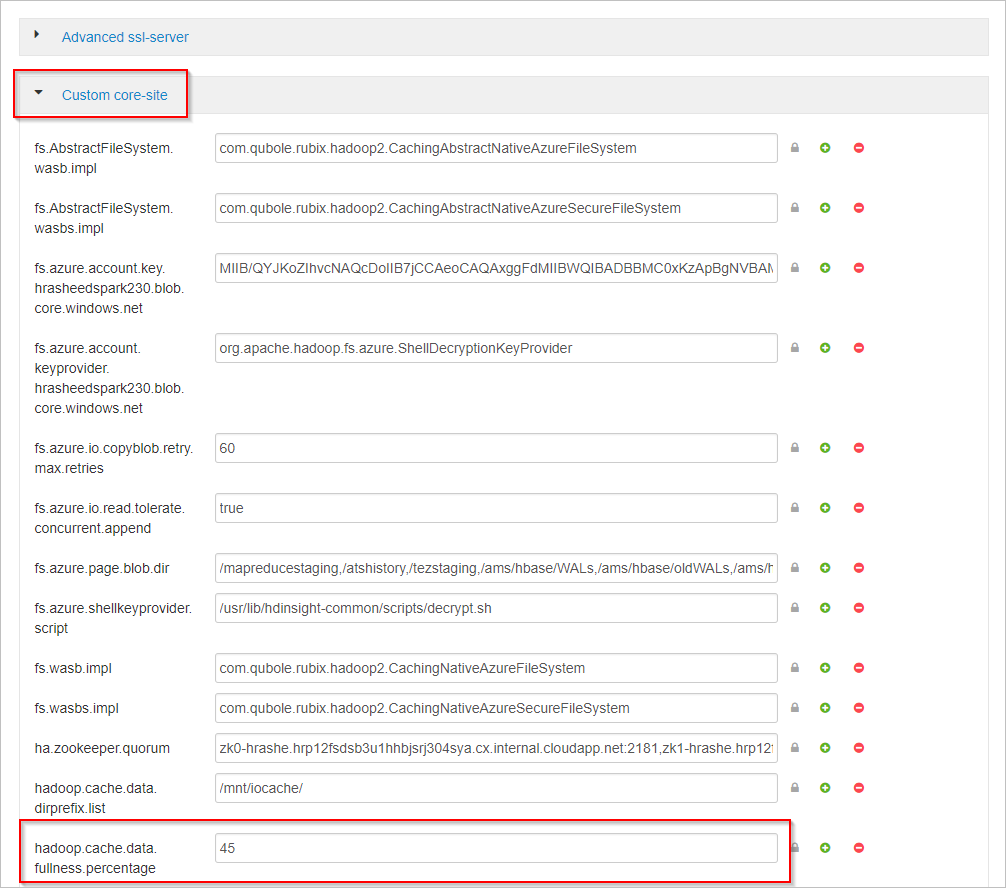
Rulla nedåt och expandera området Anpassad kärnplats .
Leta upp egenskapen hadoop.cache.data.fullness.percentage.
Ändra värdet i rutan.
Välj Spara uppe till höger.
Välj Starta om starta om>alla som påverkas.

Välj Bekräfta starta om alla.
Om det inte fungerar inaktiverar du I/O Cache.
Nästa steg
Läs mer om IO Cache, inklusive prestandamått i det här blogginlägget: Apache Spark-jobb får upp till 9 gånger snabbare med HDInsight IO Cache