Träningsmodellkomponent
Den här artikeln beskriver en komponent i Azure Machine Learning-designern.
Använd den här komponenten för att träna en klassificerings- eller regressionsmodell. Träningen sker när du har definierat en modell och angett dess parametrar och kräver taggade data. Du kan också använda Träningsmodell för att träna om en befintlig modell med nya data.
Så här fungerar träningsprocessen
I Azure Machine Learning är det vanligtvis en trestegsprocess att skapa och använda en maskininlärningsmodell.
Du konfigurerar en modell genom att välja en viss typ av algoritm och definiera dess parametrar eller hyperparametrar. Välj någon av följande modelltyper:
- Klassificeringsmodeller som baseras på neurala nätverk, beslutsträd och beslutsskogar och andra algoritmer.
- Regressionsmodeller , som kan innehålla linjär regression av standard, eller som använder andra algoritmer, inklusive neurala nätverk och Bayesian regression.
Ange en datauppsättning som är märkt och har data som är kompatibla med algoritmen. Anslut både data och modellen till Träna modell.
Vad träning producerar är ett specifikt binärt format, iLearner, som kapslar in de statistiska mönster som lärts från data. Du kan inte ändra eller läsa det här formatet direkt. Andra komponenter kan dock använda den här tränade modellen.
Du kan också visa modellens egenskaper. Mer information finns i avsnittet Resultat.
När träningen har slutförts använder du den tränade modellen med en av bedömningskomponenterna för att göra förutsägelser om nya data.
Så här använder du träningsmodell
Lägg till komponenten Träna modell i pipelinen. Du hittar den här komponenten under kategorin Machine Learning . Expandera Träna och dra sedan komponenten Train Model (Träna modell ) till din pipeline.
Anslut det otränade läget till vänster. Koppla träningsdatauppsättningen till höger indata för Träningsmodell.
Träningsdatauppsättningen måste innehålla en etikettkolumn. Alla rader utan etiketter ignoreras.
För Kolumnen Etikett klickar du på Redigera kolumn i den högra panelen i komponenten och väljer en enda kolumn som innehåller resultat som modellen kan använda för träning.
Vid klassificeringsproblem måste etikettkolumnen innehålla antingen kategoriska värden eller diskreta värden. Vissa exempel kan vara ett ja/nej-omdöme, en kod eller ett namn för sjukdomsklassificering eller en inkomstgrupp. Om du väljer en icke-kategorisk kolumn returnerar komponenten ett fel under träningen.
För regressionsproblem måste etikettkolumnen innehålla numeriska data som representerar svarsvariabeln. Helst representerar numeriska data en kontinuerlig skala.
Exempel kan vara en kreditriskpoäng, den beräknade tiden till fel för en hårddisk eller det prognostiserade antalet samtal till ett callcenter en viss dag eller tid. Om du inte väljer en numerisk kolumn kan du få ett fel.
- Om du inte anger vilken etikettkolumn som ska användas försöker Azure Machine Learning härleda vilken som är lämplig etikettkolumn med hjälp av datauppsättningens metadata. Om den väljer fel kolumn använder du kolumnväljaren för att korrigera den.
Tips
Om du har problem med att använda kolumnväljaren kan du läsa mer i artikeln Välj kolumner i datauppsättning . Den beskriver några vanliga scenarier och tips för att använda alternativen WITH RULES och BY NAME .
Skicka pipelinen. Om du har mycket data kan det ta en stund.
Viktigt
Om du har en ID-kolumn som är ID för varje rad, eller en textkolumn som innehåller för många unika värden, kan träningsmodellen stöta på ett fel som "Antal unika värden i kolumnen: {column_name}" är större än tillåtet.
Det beror på att kolumnen når tröskelvärdet för unika värden och kan orsaka slut på minne. Du kan använda Redigera metadata för att markera kolumnen som clear-funktion och den kommer inte att användas i träning, eller extrahera N-Gram-funktioner från textkomponenten för att förbearbeta textkolumnen. Mer felinformation finns i Designer felkod.
Modelltolkning
Modelltolkning ger möjlighet att förstå ML-modellen och presentera den underliggande grunden för beslutsfattande på ett sätt som är begripligt för människor.
För närvarande har komponenten Träna modell stöd för att använda tolkningspaket för att förklara ML-modeller. Följande inbyggda algoritmer stöds:
- Linjär regression
- Regression för Neural Network
- Förstärkt regression av decistionsträd
- Regression för beslutsskog
- Poisson-regression
- Logistic Regression med två klasser
- Tvåklassig dator för vektorstöd
- Two-Class ökat decistionsträd
- Beslutsskog med två klasser
- Beslutsskog för flera klasser
- Logistisk regression i flera klasser
- Neuralt nätverk med flera klasser
Om du vill generera modellförklaringar kan du välja Sant i listrutan med modellförklaring i träningsmodellkomponenten. Som standard är det inställt på Falskt i komponenten Träna modell . Observera att generering av förklaring kräver extra beräkningskostnad.
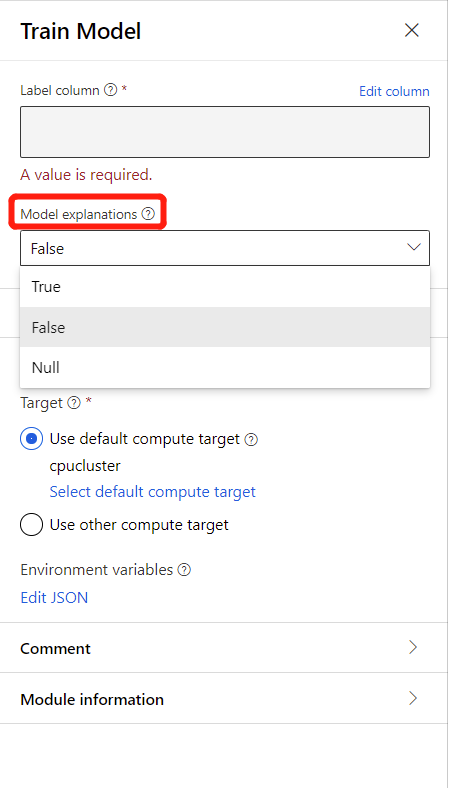
När pipelinekörningen är klar kan du gå till fliken Förklaringar i den högra rutan i komponenten Träna modell och utforska modellens prestanda, datauppsättning och funktionsvikt.
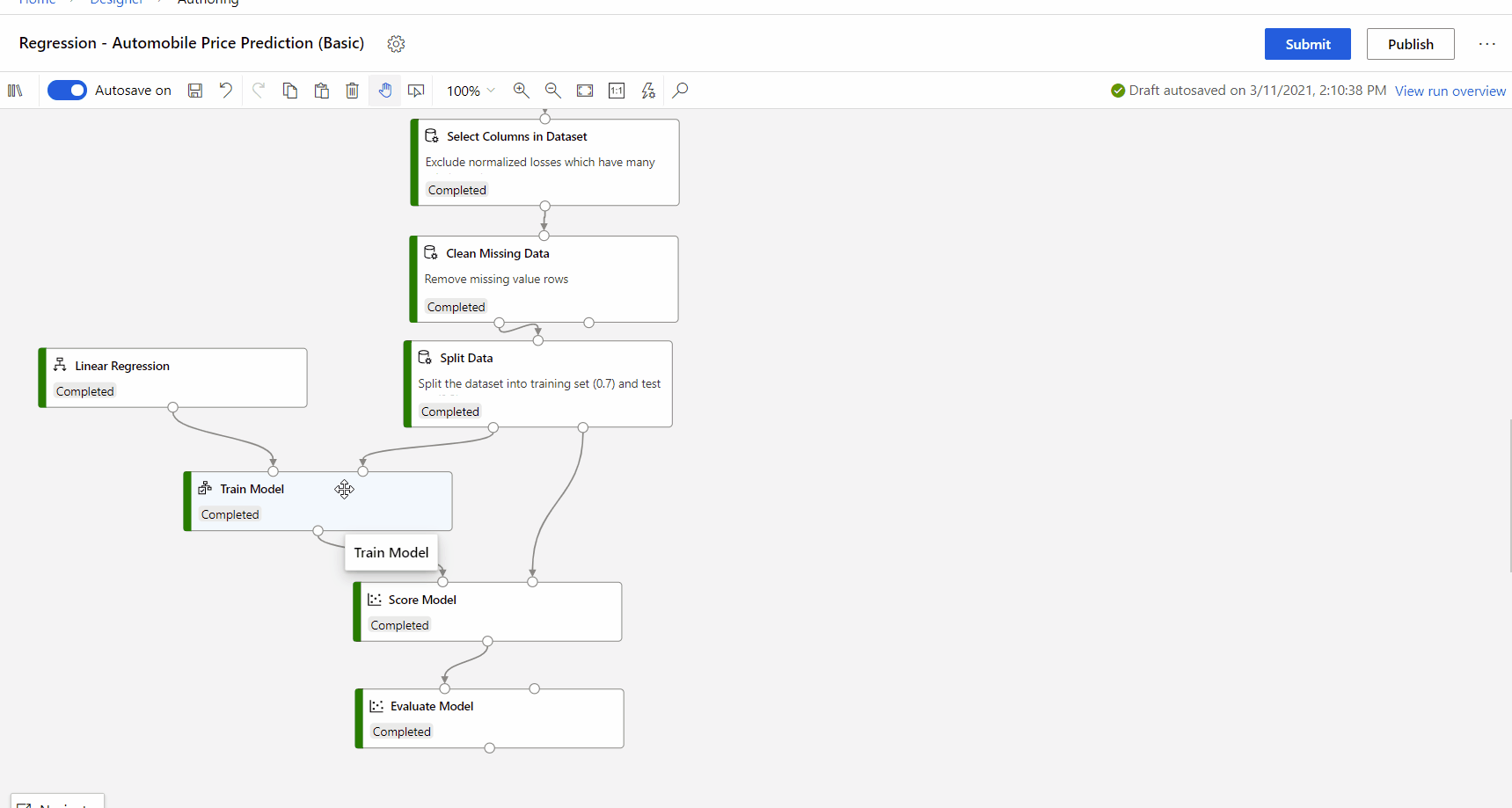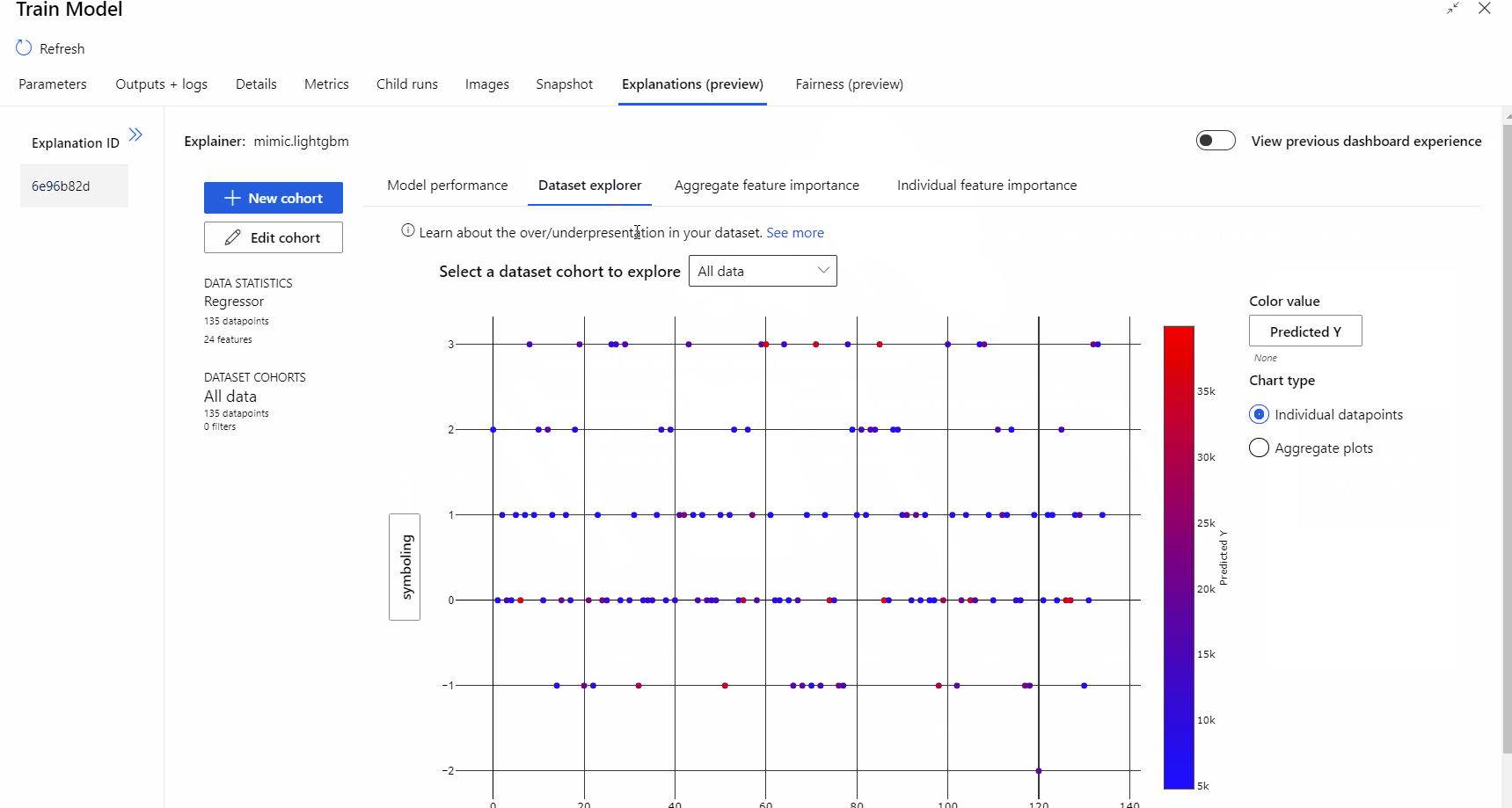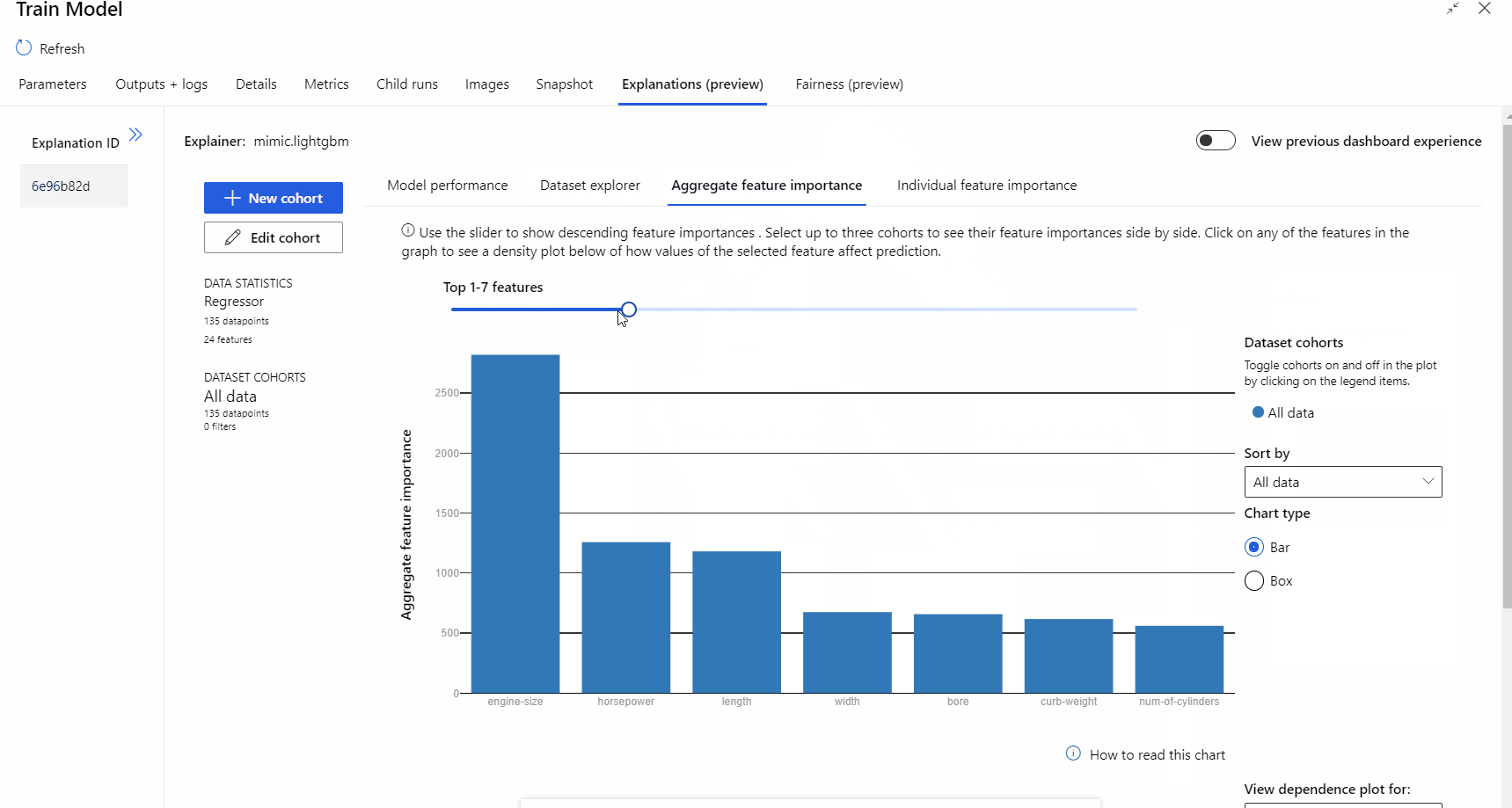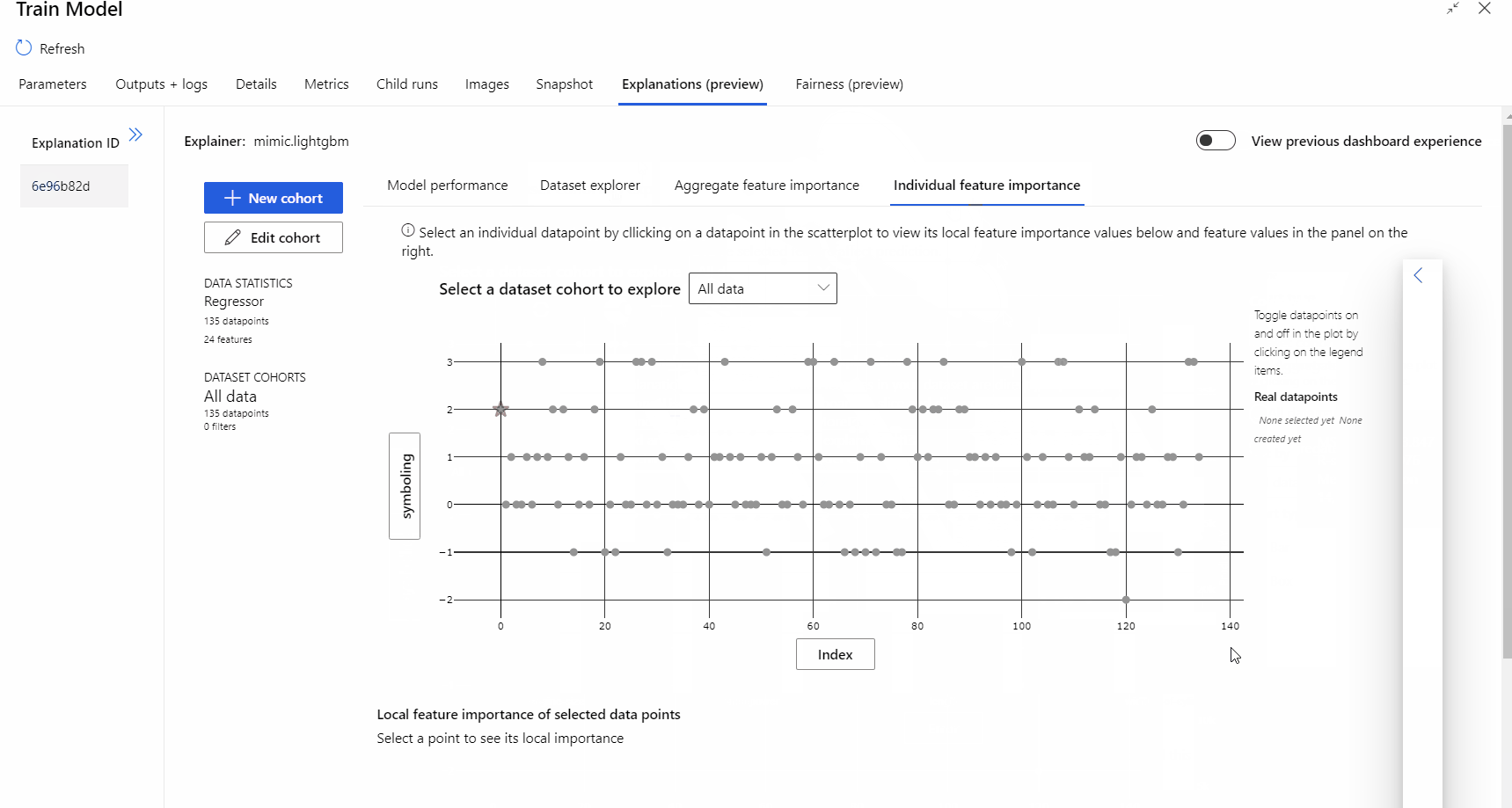
Mer information om hur du använder modellförklaringar i Azure Machine Learning finns i artikeln om att tolka ML-modeller.
Resultat
När modellen har tränats:
Om du vill använda modellen i andra pipelines väljer du komponenten och väljer ikonen Registrera datauppsättning under fliken Utdata på den högra panelen. Du kan komma åt sparade modeller i komponentpaletten under Datauppsättningar.
Om du vill använda modellen för att förutsäga nya värden ansluter du den till komponenten Score Model (Poängsätt modell ) tillsammans med nya indata.
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Machine Learning.