Guide till Net#-språk för neuralt nätverk för Machine Learning Studio (klassisk)
GÄLLER FÖR: Machine Learning Studio (klassisk)
Machine Learning Studio (klassisk)  Azure Machine Learning
Azure Machine Learning
Viktigt
Stödet för Machine Learning Studio (klassisk) upphör den 31 augusti 2024. Vi rekommenderar att du byter till Azure Machine Learning innan dess.
Från och med den 1 december 2021 kan du inte längre skapa nya Machine Learning Studio-resurser (klassisk). Du kan fortsätta att använda befintliga Machine Learning Studio-resurser (klassisk) till och med den 31 augusti 2024.
- Se information om hur du flyttar maskininlärningsprojekt från ML Studio (klassisk) till Azure Machine Learning.
- Läs mer om Azure Machine Learning
Dokumentationen om ML Studio (klassisk) håller på att dras tillbaka och kanske inte uppdateras i framtiden.
Net# är ett språk som utvecklats av Microsoft och som används för att definiera komplexa arkitekturer för neurala nätverk, till exempel djupa neurala nätverk eller sammansättningar av godtyckliga dimensioner. Du kan använda komplexa strukturer för att förbättra inlärningen av data, till exempel bild, video eller ljud.
Du kan använda en Net#-arkitekturspecifikation i alla neurala nätverksmoduler i Machine Learning Studio (klassisk):
I den här artikeln beskrivs de grundläggande begrepp och syntax som behövs för att utveckla ett anpassat neuralt nätverk med Net#:
- Krav för neuralt nätverk och hur du definierar de primära komponenterna
- Syntaxen och nyckelorden för Net#-specifikationsspråket
- Exempel på anpassade neurala nätverk som skapats med Net #
Grunderna i neuralt nätverk
En neural nätverksstruktur består av noder som är ordnade i lager och viktade anslutningar (eller kanter) mellan noderna. Anslutningarna är riktningsbaserade och varje anslutning har en källnod och en målnod.
Varje träningsbart lager (ett dolt eller ett utdatalager) har ett eller flera anslutningspaket. Ett anslutningspaket består av ett källlager och en specifikation av anslutningarna från det källlagret. Alla anslutningar i ett visst paket delar käll- och mållager. I Net# anses ett anslutningspaket tillhöra paketets målskikt.
Net# stöder olika typer av anslutningspaket, vilket gör att du kan anpassa hur indata mappas till dolda lager och mappas till utdata.
Standardpaketet eller standardpaketet är ett fullständigt paket där varje nod i källlagret är ansluten till varje nod i målskiktet.
Dessutom stöder Net# följande fyra typer av avancerade anslutningspaket:
Filtrerade paket. Du kan definiera ett predikat med hjälp av platserna för källlagernoden och mållagernoden. Noder ansluts när predikatet är Sant.
Faltningspaket. Du kan definiera små områden med noder i källlagret. Varje nod i målskiktet är ansluten till ett område med noder i källlagret.
Poolpaket och svarsnormaliseringspaket. Dessa liknar faltningspaket på så sätt att användaren definierar små områden med noder i källlagret. Skillnaden är att kanternas vikter i dessa paket inte kan tränas. I stället tillämpas en fördefinierad funktion på källnodvärdena för att fastställa målnodvärdet.
Anpassningar som stöds
Arkitekturen för neurala nätverksmodeller som du skapar i Machine Learning Studio (klassisk) kan anpassas i stor utsträckning med hjälp av Net#. Du kan:
- Skapa dolda lager och kontrollera antalet noder i varje lager.
- Ange hur lager ska anslutas till varandra.
- Definiera särskilda anslutningsstrukturer, till exempel faltningar och viktdelningspaket.
- Ange olika aktiveringsfunktioner.
Mer information om syntaxen för specifikationsspråk finns i Strukturspecifikation.
Exempel på hur du definierar neurala nätverk för vissa vanliga maskininlärningsuppgifter, från simplex till komplext, finns i Exempel.
Allmänna krav
- Det måste finnas exakt ett utdatalager, minst ett indatalager och noll eller flera dolda lager.
- Varje lager har ett fast antal noder, konceptuellt ordnade i en rektangulär matris med godtyckliga dimensioner.
- Indatalager har inga associerade tränade parametrar och representerar den punkt där instansdata kommer in i nätverket.
- Träningsbara lager (de dolda lagren och utdataskikten) har associerade tränade parametrar, så kallade vikter och biaser.
- Käll- och målnoderna måste finnas i separata lager.
- Anslutningarna måste vara acykliska. Med andra ord kan det inte finnas en kedja av anslutningar som leder tillbaka till den första källnoden.
- Utdataskiktet kan inte vara ett källskikt i ett anslutningspaket.
Strukturspecifikationer
En strukturspecifikation för neurala nätverk består av tre delar: konstantdeklarationen, lagerdeklarationen, anslutningsdeklarationen. Det finns också ett valfritt resursdeklarationsavsnitt . Avsnitten kan anges i valfri ordning.
Konstant deklaration
En konstant deklaration är valfri. Det ger ett sätt att definiera värden som används någon annanstans i definitionen för neurala nätverk. Deklarationssatsen består av en identifierare följt av ett likhetstecken och ett värdeuttryck.
Följande instruktion definierar till exempel en konstant x:
Const X = 28;
Om du vill definiera två eller flera konstanter samtidigt omger du identifierarnamnen och värdena i klammerparenteser och separerar dem med semikolon. Ett exempel:
Const { X = 28; Y = 4; }
Den högra sidan av varje tilldelningsuttryck kan vara ett heltal, ett verkligt tal, ett booleskt värde (sant eller falskt) eller ett matematiskt uttryck. Ett exempel:
Const { X = 17 * 2; Y = true; }
Lagerdeklaration
Lagerdeklarationen krävs. Den definierar lagrets storlek och källa, inklusive dess anslutningspaket och attribut. Deklarationssatsen börjar med namnet på lagret (indata, dolda eller utdata), följt av lagrets dimensioner (en tupplar med positiva heltal). Ett exempel:
input Data auto;
hidden Hidden[5,20] from Data all;
output Result[2] from Hidden all;
- Produkten av dimensionerna är antalet noder i lagret. I det här exemplet finns det två dimensioner [5,20], vilket innebär att det finns 100 noder i lagret.
- Lagren kan deklareras i valfri ordning, med ett undantag: Om fler än ett indatalager har definierats måste den ordning i vilken de deklareras matcha ordningen på funktionerna i indata.
Om du vill ange att antalet noder i ett lager ska fastställas automatiskt använder du nyckelordet auto . Nyckelordet auto har olika effekter, beroende på skiktet:
- I en deklaration av indataskiktet är antalet noder antalet funktioner i indata.
- I en dold lagerdeklaration är antalet noder det tal som anges av parametervärdet för Antal dolda noder.
- I en utdatalagerdeklaration är antalet noder 2 för klassificering med två klasser, 1 för regression och lika med antalet utdatanoder för klassificering med flera klasser.
Följande nätverksdefinition gör att storleken på alla lager kan fastställas automatiskt:
input Data auto;
hidden Hidden auto from Data all;
output Result auto from Hidden all;
En lagerdeklaration för ett träningsbart lager (de dolda lagren eller utdataskikten) kan eventuellt innehålla utdatafunktionen (kallas även aktiveringsfunktion), som som standard är sigmoid för klassificeringsmodeller och linjär för regressionsmodeller. Även om du använder standardinställningen kan du uttryckligen ange aktiveringsfunktionen, om så önskas för tydlighetens skull.
Följande utdatafunktioner stöds:
- Sigmoid
- Linjär
- softmax
- rlinear
- Square
- Rot
- srlinear
- Abs
- Tanh
- brlinear
Följande deklaration använder till exempel funktionen softmax :
output Result [100] softmax from Hidden all;
Anslutningsdeklaration
Omedelbart efter att du har definierat det träningsbara lagret måste du deklarera anslutningar mellan de lager som du har definierat. Deklarationen för anslutningspaketet börjar med nyckelordet from, följt av namnet på paketets källlager och den typ av anslutningspaket som ska skapas.
För närvarande stöds fem typer av anslutningspaket:
- Fullständiga paket, som anges med nyckelordet
all - Filtrerade paket, som anges med nyckelordet
where, följt av ett predikatuttryck - Convolutional-paket , som anges av nyckelordet
convolve, följt av convolution-attributen - Poolpaket , som anges av nyckelordens maxpool eller medelvärdespool
- Svarsnormaliseringspaket , vilket anges av nyckelordssvarsnormen
Fullständiga paket
Ett fullständigt anslutningspaket innehåller en anslutning från varje nod i källlagret till varje nod i mållagret. Det här är standardtypen för nätverksanslutning.
Filtrerade paket
En filtrerad specifikation för anslutningspaket innehåller ett predikat, uttryckt syntaktiskt, ungefär som ett C#-lambda-uttryck. I följande exempel definieras två filtrerade paket:
input Pixels [10, 20];
hidden ByRow[10, 12] from Pixels where (s,d) => s[0] == d[0];
hidden ByCol[5, 20] from Pixels where (s,d) => abs(s[1] - d[1]) <= 1;
I predikatet för
ByRowsär en parameter som representerar ett index i den rektangulära matrisen med noder i indataskiktet ,Pixelsochdär en parameter som representerar ett index i matrisen med noder i det dolda lagret,ByRow. Typen av bådasochdär en tupplar av heltal av längd två. Konceptuelltssträcker sig intervall över alla par med heltal med0 <= s[0] < 10och0 <= s[1] < 20, ochdintervall över alla par med heltal, med0 <= d[0] < 10och0 <= d[1] < 12.Till höger om predikatuttrycket finns ett villkor. I det här exemplet finns det en gräns från källlagernoden till målnivånoden för varje värde
si ochdså att villkoret är Sant. Det här filteruttrycket anger därför att paketet innehåller en anslutning från noden som definierats avstill noden som definierats avdi alla fall där s[0] är lika med d[0].
Du kan också ange en uppsättning vikter för ett filtrerat paket. Värdet för attributet Vikter måste vara en tupplar med flyttalsvärden med en längd som matchar antalet anslutningar som definieras av paketet. Som standard genereras vikter slumpmässigt.
Viktvärden grupperas efter målnodindexet. Om den första målnoden är ansluten till K-källnoder är de första K elementen i tuppeln Vikter vikterna för den första målnoden i källindexordning. Detsamma gäller för de återstående målnoderna.
Det går att ange vikter direkt som konstanta värden. Om du till exempel har lärt dig vikterna tidigare kan du ange dem som konstanter med den här syntaxen:
const Weights_1 = [0.0188045055, 0.130500451, ...]
Convolutional-paket
När träningsdata har en homogen struktur används ofta konvolutional-anslutningar för att lära sig högnivåfunktioner i data. I bild-, ljud- eller videodata kan till exempel rumslig eller temporal dimension vara ganska enhetlig.
Convolutional-paket använder rektangulära kernels som skjuts genom dimensionerna. I grund och botten definierar varje kernel en uppsättning vikter som tillämpas i lokala stadsdelar, som kallas kernelprogram. Varje kernelprogram motsvarar en nod i källlagret, som kallas den centrala noden. Vikten på en kernel delas mellan många anslutningar. I ett convolutional-paket är varje kernel rektangulär och alla kernelprogram har samma storlek.
Convolutional-paket stöder följande attribut:
InputShape definierar dimensionaliteten i källlagret för det här konvolutional-paketet. Värdet måste vara en tupplar med positiva heltal. Heltalsprodukten måste vara lika med antalet noder i källlagret, men annars behöver den inte matcha den dimensionalitet som deklareras för källlagret. Längden på den här tuppeln blir aritetsvärdet för det convolutional-paketet. Vanligtvis refererar aritet till antalet argument eller operander som en funktion kan ta.
Om du vill definiera kernelernas form och platser använder du attributen KernelShape, Stride, Utfyllnad, LowerPad och UpperPad:
KernelShape: (krävs) Definierar dimensionaliteten för varje kernel för det konvolutionala paketet. Värdet måste vara en tuppeln av positiva heltal med en längd som motsvarar ariteten i paketet. Varje komponent i den här tuppeln får inte vara större än motsvarande komponent i InputShape.
Steg: (valfritt) Definierar de glidande stegstorlekarna för decentraliseringen (en stegstorlek för varje dimension), som är avståndet mellan de centrala noderna. Värdet måste vara en tuppeln med positiva heltal med en längd som är ariteten i paketet. Varje komponent i den här tuppeln får inte vara större än motsvarande komponent i KernelShape. Standardvärdet är en tuppeln med alla komponenter lika med en.
Delning: (valfritt) Definierar viktdelningen för varje dimension av invecklingen. Värdet kan vara ett enda booleskt värde eller en tuppel med booleska värden med en längd som är ariteten i paketet. Ett enda booleskt värde utökas till att vara en tuppel med rätt längd med alla komponenter lika med det angivna värdet. Standardvärdet är en tuppeln som består av alla True-värden.
MapCount: (valfritt) Definierar antalet funktionskartor för det convolutional-paketet. Värdet kan vara ett enda positivt heltal eller en tuppel med positiva heltal med en längd som är ariteten i paketet. Ett enda heltalsvärde utökas till att vara en tuppel med rätt längd med de första komponenterna lika med det angivna värdet och alla återstående komponenter lika med en. Standardvärdet är ett. Det totala antalet funktionskartor är produkten av komponenterna i tuppeln. Faktoreringen av det här totala antalet mellan komponenterna avgör hur funktionsmappningsvärdena grupperas i målnoderna.
Vikter: (valfritt) Definierar de initiala vikterna för paketet. Värdet måste vara en tupplar med flyttalsvärden med en längd som är antalet kernels gånger antalet vikter per kernel, enligt definitionen senare i den här artikeln. Standardvikterna genereras slumpmässigt.
Det finns två uppsättningar egenskaper som styr utfyllnad, och egenskaperna är ömsesidigt uteslutande:
Utfyllnad: (valfritt) Avgör om indata ska fyllas med hjälp av ett standardutfyllnadsschema. Värdet kan vara ett enda booleskt värde, eller så kan det vara en tuppel med booleska värden med en längd som är ariteten i paketet.
Ett enda booleskt värde utökas till att vara en tuppel med rätt längd med alla komponenter lika med det angivna värdet.
Om värdet för en dimension är Sant, är källan logiskt vadderad i den dimensionen med nollvärdesceller för att stödja ytterligare kernelprogram, så att de centrala noderna för de första och sista kärnorna i den dimensionen är de första och sista noderna i den dimensionen i källlagret. Därför bestäms antalet "dummy"-noder i varje dimension automatiskt för att passa exakt
(InputShape[d] - 1) / Stride[d] + 1kernels i det vadderade källskiktet.Om värdet för en dimension är Falskt definieras kernels så att antalet noder på varje sida som utelämnas är detsamma (upp till en skillnad på 1). Standardvärdet för det här attributet är en tuppeln med alla komponenter som är lika med False.
UpperPad och LowerPad: (valfritt) Ge större kontroll över mängden utfyllnad som ska användas. Viktigt: Dessa attribut kan definieras om och endast om egenskapen Utfyllnad ovan inte har definierats. Värdena ska vara heltalsvärdestupplar med längder som är ariteten i paketet. När dessa attribut anges läggs "dummy"-noder till i de nedre och övre ändarna av varje dimension i indataskiktet. Antalet noder som läggs till i de nedre och övre ändarna i varje dimension bestäms av LowerPad[i] respektive UpperPad[i] .
För att säkerställa att kernels endast motsvarar "riktiga" noder och inte "dummy"-noder måste följande villkor uppfyllas:
Varje komponent i LowerPad måste vara strikt mindre än
KernelShape[d]/2.Varje komponent i UpperPad får inte vara större än
KernelShape[d]/2.Standardvärdet för dessa attribut är en tupplar med alla komponenter lika med 0.
Inställningen Utfyllnad = sant tillåter så mycket utfyllnad som behövs för att behålla kärnans "mitt" inuti "riktiga" indata. Detta ändrar matematiken lite för att beräkna utdatastorleken. I allmänhet beräknas utdatastorleken D som
D = (I - K) / S + 1, därIär indatastorleken,Kär kernelstorleken,Sär steget och/är heltalsdivision (runda mot noll). Om du anger UpperPad = [1, 1] är indatastorlekenIi praktiken 29 och därmedD = (29 - 5) / 2 + 1 = 13. Men när utfyllnad = sant, i huvudsakIstöts upp avK - 1; däravD = ((28 + 4) - 5) / 2 + 1 = 27 / 2 + 1 = 13 + 1 = 14. Genom att ange värden för UpperPad och LowerPad får du mycket mer kontroll över utfyllnaden än om du bara anger Utfyllnad = sant.
Mer information om convolutional-nätverk och deras program finns i följande artiklar:
- http://d2l.ai/chapter_convolutional-neural-networks/lenet.html
- https://research.microsoft.com/pubs/68920/icdar03.pdf
Poolpaket
Ett poolpaket tillämpar geometri som liknar konvolutional anslutning, men använder fördefinierade funktioner till källnodvärden för att härleda målnodvärdet. Därför har poolningspaket inget träningsbart tillstånd (vikter eller fördomar). Poolpaket stöder alla convolutional-attribut förutom Delning, MapCount och Vikter.
Vanligtvis överlappar inte de kärnor som sammanfattas av angränsande poolenheter. Om Stride[d] är lika med KernelShape[d] i varje dimension är det lager som erhålls det traditionella lokala poollagret, som ofta används i convolutional neurala nätverk. Varje målnod beräknar det maximala eller medelvärdet av aktiviteterna för dess kernel i källlagret.
I följande exempel visas ett poolpaket:
hidden P1 [5, 12, 12]
from C1 max pool {
InputShape = [ 5, 24, 24];
KernelShape = [ 1, 2, 2];
Stride = [ 1, 2, 2];
}
- Ariteten i paketet är 3: det vill: längden på tupplar
InputShape,KernelShapeochStride. - Antalet noder i källlagret är
5 * 24 * 24 = 2880. - Det här är ett traditionellt lokalt poollager eftersom KernelShape och Stride är lika.
- Antalet noder i målskiktet är
5 * 12 * 12 = 1440.
Mer information om poollager finns i följande artiklar:
- https://www.cs.toronto.edu/~hinton/absps/imagenet.pdf (Avsnitt 3.4)
- https://cs.nyu.edu/~koray/publis/lecun-iscas-10.pdf
- https://cs.nyu.edu/~koray/publis/jarrett-iccv-09.pdf
Svarsnormaliseringspaket
Svarsnormalisering är ett lokalnormaliseringsschema som först introducerades av Geoffrey Hinton, et al, i artikeln ImageNet Classification with Deep Convolutional Neural Networks.In the paper ImageNet Classification with Deep Convolutional Neural Networks.
Svarsnormalisering används för att underlätta generalisering i neurala nät. När en neuron utlöses på en mycket hög aktiveringsnivå undertrycker ett lokalt svarsnormaliseringslager aktiveringsnivån för de omgivande neuronerna. Detta görs med hjälp av tre parametrar (α, βoch k) och en konvolutional struktur (eller grannskapsform). Varje neuron i målskiktet y motsvarar ett neuron x i källskiktet. Aktiveringsnivån för y anges av följande formel, där f är aktiveringsnivån för ett neuron och Nx är kerneln (eller uppsättningen som innehåller neuronerna i närheten av x), enligt definitionen i följande konvolutional struktur:
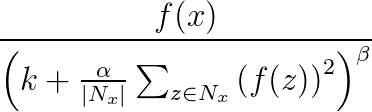
Svarsnormaliseringspaket stöder alla convolutional-attribut förutom Delning, MapCount och Vikter.
Om kerneln innehåller neuroner på samma karta som x kallas normaliseringsschemat för samma kartnormalisering. Om du vill definiera samma kartnormalisering måste den första koordinaten i InputShape ha värdet 1.
Om kerneln innehåller neuroner i samma rumsliga position som x, men neuronerna finns i andra kartor, anropas normaliseringsschemat över kartnormalisering. Denna typ av svarsnormalisering implementerar en form av lateral hämning inspirerad av den typ som finns i verkliga neuroner, vilket skapar konkurrens om stora aktiveringsnivåer bland neuronutdata som beräknas på olika kartor. Om du vill definiera normalisering mellan kartor måste den första koordinaten vara ett heltal större än ett och inte större än antalet kartor, och resten av koordinaterna måste ha värdet 1.
Eftersom svarsnormaliseringspaket använder en fördefinierad funktion på källnodvärden för att fastställa målnodvärdet, har de inget träningsbart tillstånd (vikter eller biaser).
Anteckning
Noderna i målskiktet motsvarar neuroner som är kärnornas centrala noder. Om KernelShape[d] till exempel är udda KernelShape[d]/2 motsvarar den centrala kernelnoden. Om KernelShape[d] är jämn är den centrala noden på KernelShape[d]/2 - 1. Padding[d] Om är False har därför den första och sista KernelShape[d]/2 noderna inte motsvarande noder i målskiktet. Undvik den här situationen genom att definiera Utfyllnad som [true, true, ..., true].
Förutom de fyra attribut som beskrevs tidigare stöder svarsnormaliseringspaket även följande attribut:
- Alfa: (obligatoriskt) Anger ett flyttalsvärde som motsvarar
αi föregående formel. - Beta: (obligatoriskt) Anger ett flyttalsvärde som motsvarar
βi föregående formel. - Offset: (valfritt) Anger ett flyttalsvärde som motsvarar
ki föregående formel. Standardvärdet är 1.
I följande exempel definieras ett svarsnormaliseringspaket med hjälp av följande attribut:
hidden RN1 [5, 10, 10]
from P1 response norm {
InputShape = [ 5, 12, 12];
KernelShape = [ 1, 3, 3];
Alpha = 0.001;
Beta = 0.75;
}
- Källlagret innehåller fem kartor, var och en med en dimension på 12 x 12, totalt i 1 440 noder.
- Värdet för KernelShape anger att detta är samma kartnormaliseringslager, där grannskapet är en 3x3-rektangel.
- Standardvärdet för Utfyllnad är Falskt, vilket innebär att målskiktet bara har 10 noder i varje dimension. Om du vill inkludera en nod i målskiktet som motsvarar varje nod i källlagret lägger du till Utfyllnad = [sant, sant, sant]; och ändra storleken på RN1 till [5, 12, 12].
Delningsdeklaration
Net# kan också ha stöd för att definiera flera paket med delade vikter. Vikterna för två paket kan delas om deras strukturer är desamma. Följande syntax definierar paket med delade vikter:
share-declaration:
share { layer-list }
share { bundle-list }
share { bias-list }
layer-list:
layer-name , layer-name
layer-list , layer-name
bundle-list:
bundle-spec , bundle-spec
bundle-list , bundle-spec
bundle-spec:
layer-name => layer-name
bias-list:
bias-spec , bias-spec
bias-list , bias-spec
bias-spec:
1 => layer-name
layer-name:
identifier
Följande resursdeklaration anger till exempel lagernamnen, vilket indikerar att både vikter och fördomar ska delas:
Const {
InputSize = 37;
HiddenSize = 50;
}
input {
Data1 [InputSize];
Data2 [InputSize];
}
hidden {
H1 [HiddenSize] from Data1 all;
H2 [HiddenSize] from Data2 all;
}
output Result [2] {
from H1 all;
from H2 all;
}
share { H1, H2 } // share both weights and biases
- Indatafunktionerna är partitionerade i två lika stora indatalager.
- De dolda lagren beräknar sedan funktioner på högre nivå på de två indataskikten.
- Resursdeklarationen anger att H1 och H2 måste beräknas på samma sätt från deras respektive indata.
Du kan också ange detta med två separata aktiedeklarationer på följande sätt:
share { Data1 => H1, Data2 => H2 } // share weights
<!-- -->
share { 1 => H1, 1 => H2 } // share biases
Du kan bara använda det korta formuläret när lagren innehåller ett enda paket. I allmänhet är delning endast möjligt när den relevanta strukturen är identisk, vilket innebär att de har samma storlek, samma faltningsgeometri och så vidare.
Exempel på Net#-användning
Det här avsnittet innehåller några exempel på hur du kan använda Net# för att lägga till dolda lager, definiera hur dolda lager interagerar med andra lager och skapa konvolutional nätverk.
Definiera ett enkelt anpassat neuralt nätverk: "Hello World"-exempel
Det här enkla exemplet visar hur du skapar en modell för neuralt nätverk som har ett enda dolt lager.
input Data auto;
hidden H [200] from Data all;
output Out [10] sigmoid from H all;
Exemplet illustrerar några grundläggande kommandon på följande sätt:
- Den första raden definierar indataskiktet (med namnet
Data). När du använder nyckelordetautoinnehåller det neurala nätverket automatiskt alla funktionskolumner i indataexemplen. - Den andra raden skapar det dolda lagret. Namnet
Htilldelas till det dolda lagret, som har 200 noder. Det här lagret är helt anslutet till indataskiktet. - Den tredje raden definierar utdataskiktet (med namnet
Out), som innehåller 10 utdatanoder. Om det neurala nätverket används för klassificering finns det en utdatanod per klass. Nyckelordet sigmoid anger att utdatafunktionen tillämpas på utdataskiktet.
Definiera flera dolda lager: exempel på visuellt innehåll
I följande exempel visas hur du definierar ett något mer komplext neuralt nätverk med flera anpassade dolda lager.
// Define the input layers
input Pixels [10, 20];
input MetaData [7];
// Define the first two hidden layers, using data only from the Pixels input
hidden ByRow [10, 12] from Pixels where (s,d) => s[0] == d[0];
hidden ByCol [5, 20] from Pixels where (s,d) => abs(s[1] - d[1]) <= 1;
// Define the third hidden layer, which uses as source the hidden layers ByRow and ByCol
hidden Gather [100]
{
from ByRow all;
from ByCol all;
}
// Define the output layer and its sources
output Result [10]
{
from Gather all;
from MetaData all;
}
Det här exemplet illustrerar flera funktioner i specifikationsspråket för neurala nätverk:
- Strukturen har två indataskikt,
PixelsochMetaData. - Lagret
Pixelsär ett källlager för två anslutningspaket, med målskikt ochByRowByCol. - Lagren
GatherochResultär målskikt i flera anslutningspaket. - Utdataskiktet,
Result, är ett målskikt i två anslutningspaket, ett med det andra dolda lagretGathersom målskikt och det andra med indataskiktetMetaDatasom målskikt. - De dolda lagren
ByRowochByCol, anger filtrerad anslutning med hjälp av predikatuttryck. Mer exakt är noden iByRowvid [x, y] ansluten till noderna iPixelssom har den första indexkoordinaten lika med nodens första koordinat, x. På samma sätt är noden iByColvid [x, y] ansluten till noderna iPixelssom har den andra indexkoordinaten inom en av nodens andra koordinat, y.
Definiera ett convolutional-nätverk för klassificering med flera klasser: exempel på sifferigenkänning
Definitionen av följande nätverk är utformad för att identifiera tal, och den illustrerar några avancerade tekniker för att anpassa ett neuralt nätverk.
input Image [29, 29];
hidden Conv1 [5, 13, 13] from Image convolve
{
InputShape = [29, 29];
KernelShape = [ 5, 5];
Stride = [ 2, 2];
MapCount = 5;
}
hidden Conv2 [50, 5, 5]
from Conv1 convolve
{
InputShape = [ 5, 13, 13];
KernelShape = [ 1, 5, 5];
Stride = [ 1, 2, 2];
Sharing = [false, true, true];
MapCount = 10;
}
hidden Hid3 [100] from Conv2 all;
output Digit [10] from Hid3 all;
Strukturen har ett enda indataskikt,
Image.Nyckelordet
convolveanger att lagren med namnetConv1ochConv2är faltningslager. Var och en av dessa lagerdeklarationer följs av en lista över convolution-attributen.Nätet har ett tredje dolt lager,
Hid3, som är helt anslutet till det andra dolda lagret,Conv2.Utdataskiktet,
Digit, är endast anslutet till det tredje dolda lagret,Hid3. Nyckelordetallanger att utdataskiktet är helt anslutet tillHid3.Ariteten för faltningen är tre: längden på tupplar
InputShape,KernelShape,StrideochSharing.Antalet vikter per kernel är
1 + KernelShape\[0] * KernelShape\[1] * KernelShape\[2] = 1 + 1 * 5 * 5 = 26. Eller26 * 50 = 1300.Du kan beräkna noderna i varje dolt lager på följande sätt:
NodeCount\[0] = (5 - 1) / 1 + 1 = 5NodeCount\[1] = (13 - 5) / 2 + 1 = 5NodeCount\[2] = (13 - 5) / 2 + 1 = 5Det totala antalet noder kan beräknas med hjälp av den deklarerade dimensionaliteten i lagret , [50, 5, 5], enligt följande:
MapCount * NodeCount\[0] * NodeCount\[1] * NodeCount\[2] = 10 * 5 * 5 * 5Eftersom
Sharing[d]är False endast förd == 0ärMapCount * NodeCount\[0] = 10 * 5 = 50antalet kernels .
Tack till
Net#-språket för anpassning av arkitekturen i neurala nätverk utvecklades på Microsoft av Shon Katzenberger (Architect, Machine Learning) och Alexey Kamenev (Software Engineer, Microsoft Research). Den används internt för maskininlärningsprojekt och program som sträcker sig från bildidentifiering till textanalys. Mer information finns i Neurala nät i Machine Learning Studio – Introduktion till Net#