Utvärdera modellprestanda i Machine Learning Studio (klassisk)
GÄLLER FÖR: Machine Learning Studio (klassisk)
Machine Learning Studio (klassisk)  Azure Machine Learning
Azure Machine Learning
Viktigt
Stödet för Machine Learning Studio (klassisk) upphör den 31 augusti 2024. Vi rekommenderar att du byter till Azure Machine Learning innan dess.
Från och med den 1 december 2021 kan du inte längre skapa nya Machine Learning Studio-resurser (klassisk). Du kan fortsätta att använda befintliga Machine Learning Studio-resurser (klassisk) till och med den 31 augusti 2024.
- Se information om hur du flyttar maskininlärningsprojekt från ML Studio (klassisk) till Azure Machine Learning.
- Läs mer om Azure Machine Learning
Dokumentationen om ML Studio (klassisk) håller på att dras tillbaka och kanske inte uppdateras i framtiden.
I den här artikeln kan du lära dig mer om de mått som du kan använda för att övervaka modellprestanda i Machine Learning Studio (klassisk). Utvärdering av prestanda för en modell är ett av de viktigaste stegen i datavetenskapsprocessen. Den anger hur lyckad bedömning (förutsägelser) för en datamängd har varit av en tränad modell. Machine Learning Studio (klassisk) stöder modellutvärdering via två av de viktigaste maskininlärningsmodulerna:
Med de här modulerna kan du se hur din modell presterar när det gäller ett antal mått som ofta används i maskininlärning och statistik.
Utvärdering av modeller bör övervägas tillsammans med:
Tre vanliga övervakade inlärningsscenarier presenteras:
- Regression
- binär klassificering
- multiklassklassificering
Utvärdering jämfört med korsvalidering
Utvärdering och korsvalidering är standardsätt för att mäta modellens prestanda. Båda genererar utvärderingsmått som du kan granska eller jämföra med andra modellers.
Utvärdera modell förväntar sig en poängsatt datauppsättning som indata (eller två om du vill jämföra prestanda för två olika modeller). Därför måste du träna din modell med hjälp av modulen Träna modell och göra förutsägelser för vissa datamängder med hjälp av modulen Poängsätta modell innan du kan utvärdera resultaten. Utvärderingen baseras på de poängsatta etiketterna/sannolikheterna tillsammans med de sanna etiketterna, som alla matas ut av modulen Poängsätta modell .
Du kan också använda korsvalidering för att utföra ett antal träningspoängsbedömeåtgärder (10 gånger) automatiskt på olika delmängder av indata. Indata delas upp i 10 delar, där en är reserverad för testning och de andra 9 för träning. Den här processen upprepas 10 gånger och utvärderingsmåtten är i genomsnitt. Detta hjälper dig att avgöra hur väl en modell skulle generaliseras till nya datamängder. Modulen Korsvalidera modell tar in en otränad modell och vissa märkta datauppsättningar och matar ut utvärderingsresultaten för var och en av de 10 gångerna, utöver de genomsnittliga resultaten.
I följande avsnitt skapar vi enkla regressions- och klassificeringsmodeller och utvärderar deras prestanda med hjälp av modulerna Utvärdera modell och Korsvalidera modell .
Utvärdera en regressionsmodell
Anta att vi vill förutsäga en bils pris med funktioner som dimensioner, hästkrafter, motorspecifikationer och så vidare. Det här är ett typiskt regressionsproblem, där målvariabeln (priset) är ett kontinuerligt numeriskt värde. Vi kan anpassa en linjär regressionsmodell som, med tanke på funktionsvärdena för en viss bil, kan förutsäga priset på den bilen. Den här regressionsmodellen kan användas för att poängsätta samma datauppsättning som vi tränade på. När vi har de förutsagda bilpriserna kan vi utvärdera modellens prestanda genom att titta på hur mycket förutsägelserna avviker från de faktiska priserna i genomsnitt. För att illustrera detta använder vi datamängden Automobile price data (Raw) som är tillgänglig i avsnittet Sparade datamängder i Machine Learning Studio (klassisk).
Skapa experimentet
Lägg till följande moduler på din arbetsyta i Machine Learning Studio (klassisk):
- Prisdata för bilar (rådata)
- Linjär regression
- Träningsmodell
- Poängmodell
- Utvärdera modell
Anslut portarna som visas nedan i bild 1 och ange kolumnen Etikett i modulen Träna modell till pris.
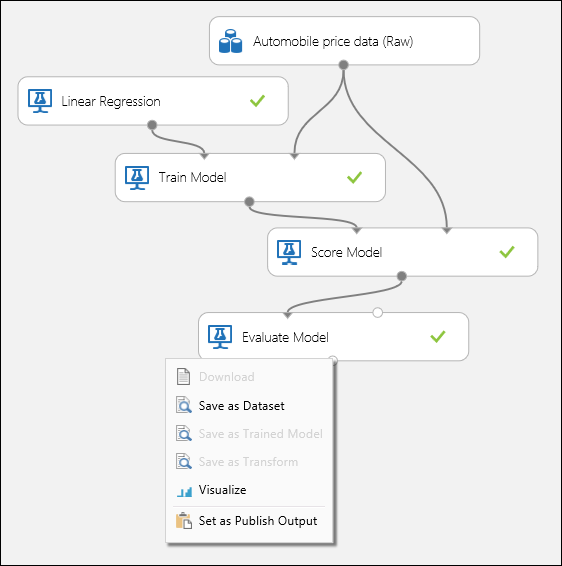
Bild 1. Utvärdera en regressionsmodell.
Granska utvärderingsresultaten
När du har kört experimentet kan du klicka på utdataporten för modulen Utvärdera modell och välja Visualisera för att se utvärderingsresultaten. Utvärderingsmåtten som är tillgängliga för regressionsmodeller är: Mean Absolute Error, Root Mean Absolute Error, Relative Absolute Error, Relative Squared Error och Coefficient of Determination.
Termen "fel" här representerar skillnaden mellan det förutsagda värdet och det sanna värdet. Det absoluta värdet eller kvadraten för den här skillnaden beräknas vanligtvis för att samla in den totala felstorleken för alla instanser, eftersom skillnaden mellan det förutsagda och sanna värdet i vissa fall kan vara negativ. Felmåtten mäter förutsägelseprestandan för en regressionsmodell när det gäller den genomsnittliga avvikelsen för förutsägelserna från de sanna värdena. Lägre felvärden innebär att modellen är mer exakt när det gäller att göra förutsägelser. Ett övergripande felmått på noll innebär att modellen passar data perfekt.
Bestämningskoefficienten, som även kallas R-kvadrat, är också ett standardsätt för att mäta hur väl modellen passar data. Det kan tolkas som den andel av variationen som förklaras av modellen. En högre andel är bättre i det här fallet, där 1 indikerar en perfekt passform.
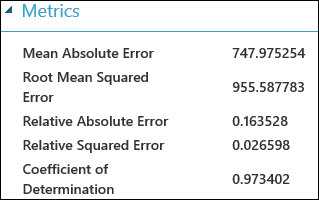
Figur 2. Mått för linjär regressionutvärdering.
Använda korsvalidering
Som tidigare nämnts kan du utföra upprepade tränings-, bedömnings- och utvärderingar automatiskt med hjälp av modulen Korsvalidera modell . Allt du behöver i det här fallet är en datauppsättning, en otränad modell och en modul för korsvalideringsmodell (se bilden nedan). Du måste ange etikettkolumnen till pris i egenskaperna för modulen Korsvalidera modell .
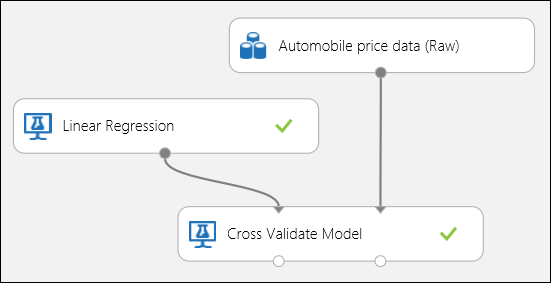
Bild 3. Korsverifiering av en regressionsmodell.
När du har kört experimentet kan du granska utvärderingsresultaten genom att klicka på den högra utdataporten för modulen Korsvalidera modell . Detta ger en detaljerad vy över måtten för varje iteration (vikning) och de genomsnittliga resultaten för vart och ett av måtten (bild 4).
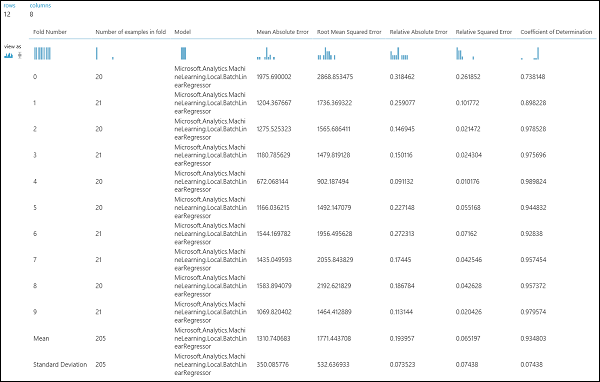
Bild 4. Korsvalideringsresultat för en regressionsmodell.
Utvärdera en binär klassificeringsmodell
I ett scenario med binär klassificering har målvariabeln bara två möjliga resultat, till exempel{ 0, 1} eller {false, true}, {negative, positive}. Anta att du får en datamängd med vuxna anställda med vissa demografiska variabler och anställningsvariabler och att du uppmanas att förutsäga inkomstnivån, en binär variabel med värdena {"<=50 K", ">50 K"}. Med andra ord representerar den negativa klassen de anställda som tjänar mindre än eller lika med 50 K per år, och den positiva klassen representerar alla andra anställda. Precis som i regressionsscenariot skulle vi träna en modell, poängsätta vissa data och utvärdera resultaten. Den största skillnaden här är valet av mått Machine Learning Studio (klassiska) beräkningar och utdata. För att illustrera scenariot med förutsägelse på inkomstnivå använder vi datauppsättningen Vuxen för att skapa ett Studio-experiment (klassiskt) och utvärdera prestandan för en logistisk regressionsmodell med två klasser, en vanlig binär klassificerare.
Skapa experimentet
Lägg till följande moduler på din arbetsyta i Machine Learning Studio (klassisk):
- Datauppsättning för binär klassificering av vuxnas folkräkningsinkomster
- Logistic Regression med två klasser
- Träningsmodell
- Poängmodell
- Utvärdera modell
Anslut portarna enligt bild 5 nedan och ange inkomst i kolumnen Etikett i modulen Träna modell.
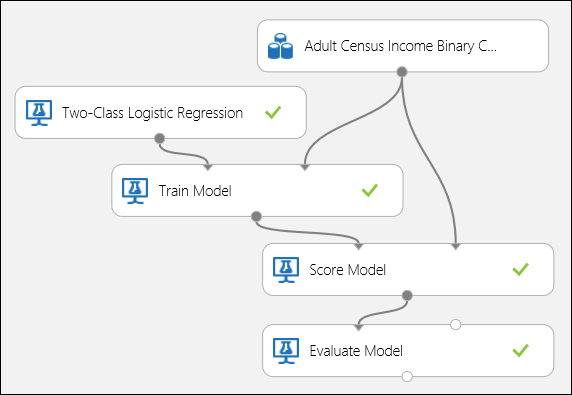
Bild 5. Utvärdera en binär klassificeringsmodell.
Granska utvärderingsresultaten
När du har kört experimentet kan du klicka på utdataporten för modulen Utvärdera modell och välja Visualisera för att se utvärderingsresultaten (bild 7). Utvärderingsmåtten som är tillgängliga för modeller för binär klassificering är: Noggrannhet, Precision, Träffsäkerhet, F1-poäng och AUC. Dessutom matar modulen ut en förvirringsmatris som visar antalet sanna positiva identifieringar, falska negativa identifieringar, falska positiva identifieringar och sanna negativa identifieringar, samt ROC-, Precisions-/träffsäkerhetskurvor och Lyft-kurvor .
Noggrannhet är helt enkelt andelen korrekt klassificerade instanser. Det är vanligtvis det första måttet du tittar på när du utvärderar en klassificerare. Men när testdata är obalanserade (där de flesta instanserna tillhör en av klasserna), eller om du är mer intresserad av prestanda för någon av klasserna, fångar noggrannheten inte riktigt effektiviteten hos en klassificerare. I scenariot med klassificering på inkomstnivå antar vi att du testar vissa data där 99 % av instanserna representerar personer som tjänar mindre än eller lika med 50 000 per år. Det går att uppnå en noggrannhet på 0,99 genom att förutsäga klassen "<=50K" för alla instanser. Klassificeraren i det här fallet verkar göra ett bra jobb totalt sett, men i verkligheten misslyckas den med att klassificera någon av de höginkomsttagare (1 %) korrekt.
Därför är det bra att beräkna ytterligare mått som samlar in mer specifika aspekter av utvärderingen. Innan du går in på information om sådana mått är det viktigt att förstå förvirringsmatrisen för en binär klassificeringsutvärdering. Klassetiketterna i träningsuppsättningen kan bara ha två möjliga värden, som vi vanligtvis kallar positiva eller negativa. De positiva och negativa instanser som en klassificerare förutsäger korrekt kallas sanna positiva (TP) respektive sanna negativa (TN). På samma sätt kallas felaktigt klassificerade instanser för falska positiva identifieringar (FP) och falska negativa (FN). Förvirringsmatrisen är helt enkelt en tabell som visar antalet instanser som faller under var och en av dessa fyra kategorier. Machine Learning Studio (klassisk) bestämmer automatiskt vilken av de två klasserna i datauppsättningen som är den positiva klassen. Om klassetiketterna är booleska eller heltal tilldelas de märkta instanserna "true" eller "1" den positiva klassen. Om etiketterna är strängar, till exempel med inkomstdatauppsättningen, sorteras etiketterna alfabetiskt och den första nivån väljs som negativ klass medan den andra nivån är den positiva klassen.

Bild 6. Förvirringsmatris för binär klassificering.
Om vi går tillbaka till problemet med inkomstklassificering vill vi ställa flera utvärderingsfrågor som hjälper oss att förstå prestandan för den klassificerare som används. En naturlig fråga är: "Av de individer som modellen förutspådde att tjäna >50 K (TP + FP), hur många klassificerades korrekt (TP)?" Den här frågan kan besvaras genom att titta på modellens precision , som är andelen positiva identifieringar som klassificeras korrekt: TP/(TP+FP). En annan vanlig fråga är "Av alla höginkomsttagare med en inkomst >på 50 000 (TP+FN), hur många klassificerare klassificerade korrekt (TP)". Det här är faktiskt återkallande, eller den sanna positiva hastigheten: TP/(TP+FN) för klassificeraren. Du kanske märker att det finns en uppenbar kompromiss mellan precision och träffsäkerhet. Till exempel skulle en klassificerare som förutsäger mestadels positiva instanser ha en hög träffsäkerhet, men en ganska låg precision eftersom många av de negativa instanserna skulle vara felklassificerade, vilket resulterar i ett stort antal falska positiva identifieringar. Om du vill se ett diagram över hur dessa två mått varierar kan du klicka på kurvan PRECISION/TRÄFFSÄKERHET på utdatasidan för utvärderingsresultatet (övre vänstra delen av bild 7).
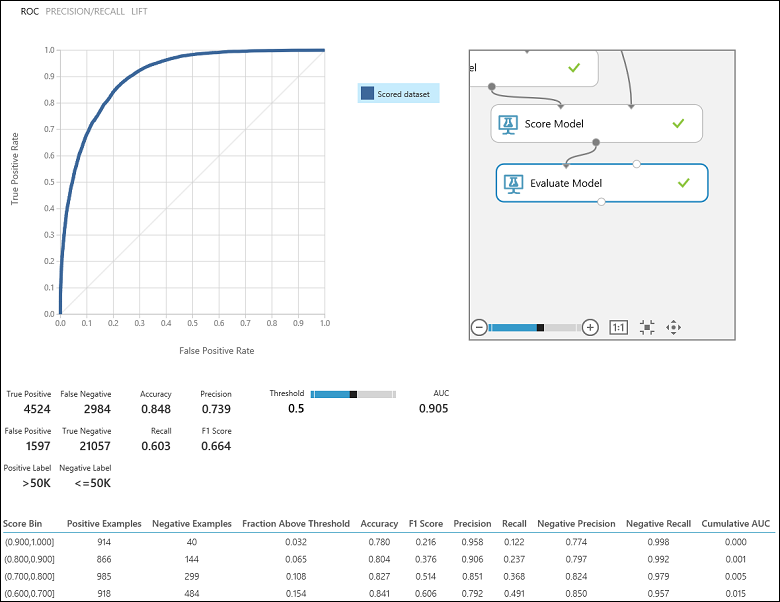
Bild 7. Utvärderingsresultat för binär klassificering.
Ett annat relaterat mått som ofta används är F1-poängen, som tar hänsyn till både precision och träffsäkerhet. Det är det harmoniska medelvärdet av dessa två mått och beräknas så här: F1 = 2 (precision x träffsäkerhet) / (precision + träffsäkerhet). F1-poängen är ett bra sätt att sammanfatta utvärderingen i ett enda tal, men det är alltid en bra idé att titta på både precision och träffsäkerhet tillsammans för att bättre förstå hur en klassificerare beter sig.
Dessutom kan man inspektera den sanna positiva frekvensen jämfört med den falska positiva frekvensen i ROC-kurvan (Receiver Operating Characteristic) och motsvarande AUC-värde (Area Under the Curve ). Ju närmare den här kurvan är det övre vänstra hörnet, desto bättre är klassificerarens prestanda (det är att maximera den sanna positiva hastigheten samtidigt som den falska positiva frekvensen minimeras). Kurvor som är nära diagonalen i diagrammet, resultat från klassificerare som tenderar att göra förutsägelser som är nära slumpmässig gissning.
Använda korsvalidering
Precis som i regressionsexemplet kan vi utföra korsvalidering för att träna, poängsätta och utvärdera olika delmängder av data automatiskt. På samma sätt kan vi använda modulen Korsvalidera modell , en otränad logistisk regressionsmodell och en datauppsättning. Etikettkolumnen måste anges till inkomst i egenskaperna för modulen Korsvalidera modell . När du har kört experimentet och klickat på den högra utdataporten för modulen Korsvalidera modell kan vi se måttvärdena för binär klassificering för varje vikning, förutom medelvärdet och standardavvikelsen för varje.
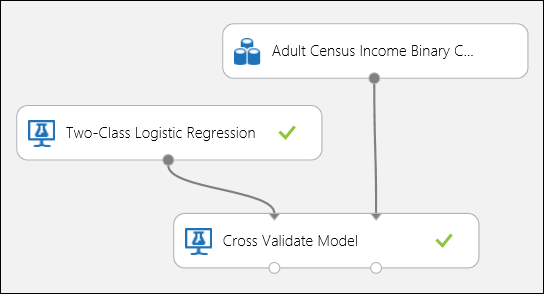
Figur 8. Korsvalificera en binär klassificeringsmodell.
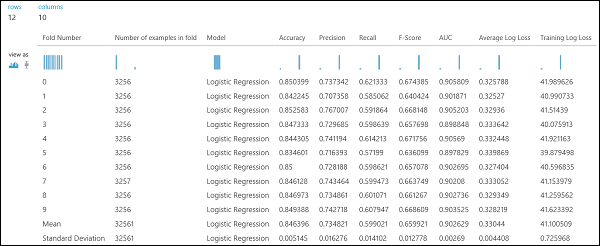
Bild 9. Korsvalideringsresultat för en binär klassificerare.
Utvärdera en klassificeringsmodell med flera klasser
I det här experimentet använder vi den populära Iris-datamängden , som innehåller instanser av tre olika typer (klasser) av irisväxten. Det finns fyra funktionsvärden (sepallängd/bredd och kronbladslängd/bredd) för varje instans. I föregående experiment tränade och testade vi modellerna med samma datauppsättningar. Här använder vi modulen Dela upp data för att skapa två delmängder av data, träna på den första och poängsätta och utvärdera den andra. Iris-datauppsättningen är offentligt tillgänglig på UCI Machine Learning-lagringsplatsen och kan laddas ned med hjälp av en importdatamodul .
Skapa experimentet
Lägg till följande moduler på din arbetsyta i Machine Learning Studio (klassisk):
Anslut portarna enligt nedan i bild 10.
Ange kolumnindexet Etikett för modulen Träna modell till 5. Datauppsättningen har ingen rubrikrad, men vi vet att klassetiketterna finns i den femte kolumnen.
Klicka på modulen Importera data och ange egenskapen Datakälla till Webb-URL via HTTP och URL:en till http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data.
Ange vilken del av instanserna som ska användas för träning i modulen Dela data (till exempel 0,7).
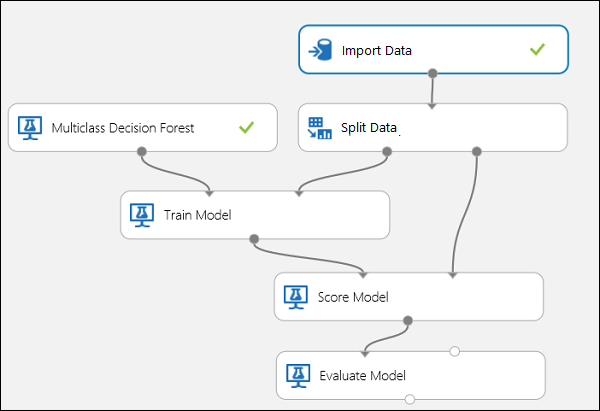
Bild 10. Utvärdera en klassificerare med flera klasser
Granska utvärderingsresultaten
Kör experimentet och klicka på utdataporten för Utvärdera modell. Utvärderingsresultaten presenteras i form av en förvirringsmatris, i det här fallet. Matrisen visar de faktiska kontra förutsagda instanserna för alla tre klasserna.
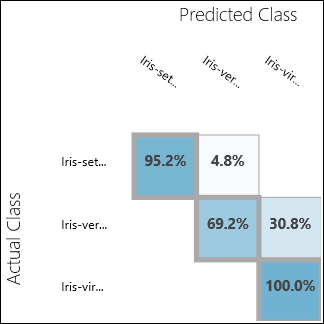
Bild 11. Utvärderingsresultat för klassificering med flera klasser.
Använda korsvalidering
Som tidigare nämnts kan du utföra upprepade tränings-, bedömnings- och utvärderingar automatiskt med hjälp av modulen Korsvalidera modell . Du behöver en datauppsättning, en otränad modell och en modul för korsvalideringsmodell (se bilden nedan). Återigen måste du ange etikettkolumnen för modulen Korsvalidera modell (kolumnindex 5 i det här fallet). När du har kört experimentet och klickat på rätt utdataport för korsvalideringsmodellen kan du granska måttvärdena för varje vikning samt medelvärdet och standardavvikelsen. De mått som visas här liknar de som beskrivs i fallet med binär klassificering. I klassificering med flera klasser beräknas dock sanna positiva/negativa och falska positiva/negativa resultat genom att räkna per klass, eftersom det inte finns någon övergripande positiv eller negativ klass. När du till exempel beräknar precisionen eller återkallandet av klassen "Iris-setosa" antas det att detta är den positiva klassen och alla andra som negativa.

Bild 12. Korsvalificera en klassificeringsmodell med flera klasser.
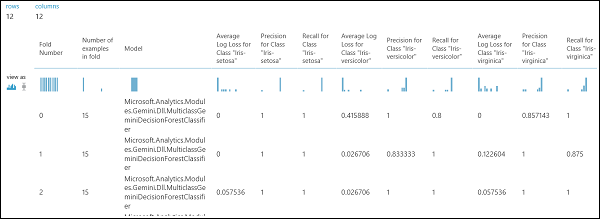
Bild 13. Korsvalideringsresultat för en klassificeringsmodell med flera klasser.