Importera dina träningsdata till Machine Learning Studio (klassisk) från olika datakällor
GÄLLER FÖR: Machine Learning Studio (klassisk)
Machine Learning Studio (klassisk)  Azure Machine Learning
Azure Machine Learning
Viktigt
Stödet för Machine Learning Studio (klassisk) upphör den 31 augusti 2024. Vi rekommenderar att du byter till Azure Machine Learning innan dess.
Från och med den 1 december 2021 kan du inte längre skapa nya Machine Learning Studio-resurser (klassisk). Du kan fortsätta att använda befintliga Machine Learning Studio-resurser (klassisk) till och med den 31 augusti 2024.
- Se information om hur du flyttar maskininlärningsprojekt från ML Studio (klassisk) till Azure Machine Learning.
- Läs mer om Azure Machine Learning
Dokumentationen om ML Studio (klassisk) håller på att dras tillbaka och kanske inte uppdateras i framtiden.
Om du vill använda dina egna data i Machine Learning Studio (klassisk) för att utveckla och träna en lösning för förutsägelseanalys kan du använda data från:
- Lokal fil – Läsa in lokala data i förväg från hårddisken för att skapa en datauppsättningsmodul på arbetsytan
- Onlinedatakällor – Använd modulen Importera data för att komma åt data från en av flera onlinekällor medan experimentet körs
- Machine Learning Studio-experiment (klassisk) – Använd data som har sparats som en datauppsättning i Machine Learning Studio (klassisk)
- SQL Server databas – Använd data från en SQL Server databas utan att behöva kopiera data manuellt
Anteckning
Det finns ett antal tillgängliga exempeldatauppsättningar i Machine Learning Studio (klassisk) som du kan använda för träningsdata. Mer information om dessa finns i Använda exempeldatauppsättningar i Machine Learning Studio (klassisk).
Förbereda data
Machine Learning Studio (klassisk) är utformat för att fungera med rektangulära eller tabellbaserade data, till exempel textdata som är avgränsade eller strukturerade data från en databas, men i vissa fall kan icke-rektangulära data användas.
Det är bäst om dina data är relativt rena innan du importerar dem till Studio (klassisk). Du vill till exempel ta hand om problem som icke-citatsträngar.
Det finns dock moduler i Studio (klassisk) som möjliggör viss manipulering av data i experimentet när du har importerat dina data. Beroende på vilka maskininlärningsalgoritmer du ska använda kan du behöva bestämma hur du ska hantera strukturella dataproblem, till exempel saknade värden och glesa data, och det finns moduler som kan hjälpa dig med det. Titta i avsnittet Datatransformering i modulpaletten efter moduler som utför dessa funktioner.
När som helst i experimentet kan du visa eller ladda ned data som skapas av en modul genom att klicka på utdataporten. Beroende på modulen kan det finnas olika nedladdningsalternativ tillgängliga, eller så kan du visualisera data i webbläsaren i Studio (klassisk).
Dataformat och datatyper som stöds
Du kan importera ett antal datatyper till experimentet, beroende på vilken mekanism du använder för att importera data och var de kommer från:
- Oformaterad text (.txt)
- Kommaavgränsade värden (CSV) med en rubrik (.csv) eller utan (.nh.csv)
- Tabbavgränsade värden (TSV) med en rubrik (.tsv) eller utan (.nh.tsv)
- Excel-fil
- Azure-tabell
- Hive-tabell
- SQL Database-tabell
- OData-värden
- SVMLight-data (.svmlight) (se SVMLight-definitionen för formatinformation)
- ARFF-data (Attribute Relation File Format) (.arff) (se ARFF-definitionen för formatinformation)
- Zip-fil (.zip)
- R-objekt eller arbetsytefil (. RData)
Om du importerar data i ett format som ARFF som innehåller metadata använder Studio (klassisk) dessa metadata för att definiera rubriken och datatypen för varje kolumn.
Om du importerar data, till exempel TSV- eller CSV-format som inte innehåller dessa metadata, härleder Studio (klassisk) datatypen för varje kolumn genom att sampling av data. Om data inte heller har kolumnrubriker tillhandahåller Studio (klassisk) standardnamn.
Du kan uttryckligen ange eller ändra rubriker och datatyper för kolumner med hjälp av modulen Redigera metadata .
Följande datatyper identifieras av Studio (klassisk):
- Sträng
- Integer
- Double
- Boolesk
- DateTime
- TimeSpan
Studio använder en intern datatyp som kallas datatabell för att skicka data mellan moduler. Du kan uttryckligen konvertera dina data till datatabellformat med hjälp av modulen Konvertera till datamängd .
Alla moduler som accepterar andra format än datatabeller konverterar data till datatabellen tyst innan de skickas till nästa modul.
Om det behövs kan du konvertera datatabellformatet tillbaka till CSV-, TSV-, ARFF- eller SVMLight-format med hjälp av andra konverteringsmoduler. Titta i avsnittet Konvertering av dataformat i modulpaletten efter moduler som utför dessa funktioner.
Datakapaciteter
Moduler i Machine Learning Studio (klassisk) stöder datauppsättningar på upp till 10 GB kompakta numeriska data för vanliga användningsfall. Om en modul hämtar indata från mer än ett ställe är värdet 10 GB summan av alla indata. Du kan prova större datamängder med hjälp av frågor från Hive eller Azure SQL Database, eller så kan du använda förbearbetning av Learning by Counts innan du importerar data.
Följande typer av data kan expanderas till större datauppsättningar under funktionsnormalisering och är begränsade till mindre än 10 GB:
- Utspridda
- Kategoriska
- Strängar
- Binära data
Följande moduler är begränsade till datauppsättningar som är mindre än 10 GB:
- Moduler för rekommenderare
- Modulen SMOTE (Synthetic Minority Oversampling Technique)
- Skriptmoduler: R, Python, SQL
- Moduler där den utgående datastorleken kan vara större än den inkommande datastorleken, till exempel kopplings- eller funktions-hashning
- Korsvalidering, hyperparametrar för justeringsmodeller, ordningstalsregression och ”en eller alla”-multiklasser, om antalet iterationer är mycket stort
För datauppsättningar som är större än ett par GB laddar du upp data till Azure Storage eller Azure SQL Database, eller använder Azure HDInsight i stället för att ladda upp direkt från en lokal fil.
Du hittar information om bilddata i modulreferensen Importera bilder .
Importera från en lokal fil
Du kan ladda upp en datafil från hårddisken för att använda som träningsdata i Studio (klassisk). När du importerar en datafil skapar du en datauppsättningsmodul som är redo att användas i experiment på din arbetsyta.
Om du vill importera data från en lokal hårddisk gör du följande:
- Klicka på +NYTT längst ned i Studio-fönstret (klassisk).
- Välj DATASET och FROM LOCAL FILE (FRÅN LOKAL FIL).
- I dialogrutan Ladda upp en ny datauppsättning bläddrar du till den fil som du vill ladda upp.
- Ange ett namn, identifiera datatypen och ange en beskrivning om du vill. En beskrivning rekommenderas – du kan registrera eventuella egenskaper för de data som du vill komma ihåg när du använder data i framtiden.
- Kryssrutan Det här är den nya versionen av en befintlig datauppsättning där du kan uppdatera en befintlig datauppsättning med nya data. Det gör du genom att klicka på den här kryssrutan och sedan ange namnet på en befintlig datauppsättning.
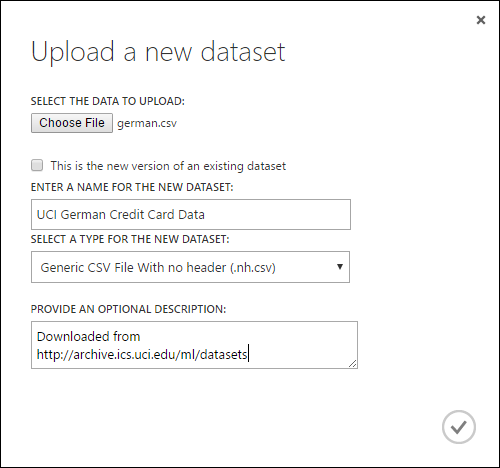
Uppladdningstiden beror på storleken på dina data och hastigheten på anslutningen till tjänsten. Om du vet att filen tar lång tid kan du göra andra saker i Studio (klassisk) medan du väntar. Men om du stänger webbläsaren innan datauppladdningen är klar misslyckas uppladdningen.
När dina data har laddats upp lagras de i en datauppsättningsmodul och är tillgänglig för alla experiment på din arbetsyta.
När du redigerar ett experiment kan du hitta de datauppsättningar som du har laddat upp i listan Mina datauppsättningar under listan Sparade datauppsättningar i modulpaletten. Du kan dra och släppa datauppsättningen på experimentarbetsytan när du vill använda datauppsättningen för ytterligare analys och maskininlärning.
Importera från onlinedatakällor
Med hjälp av modulen Importera data kan experimentet importera data från olika onlinedatakällor medan experimentet körs.
Anteckning
Den här artikeln innehåller allmän information om modulen Importera data . Mer detaljerad information om de typer av data som du kan komma åt, format, parametrar och svar på vanliga frågor finns i modulreferensavsnittet för modulen Importera data .
Med hjälp av modulen Importera data kan du komma åt data från en av flera onlinedatakällor medan experimentet körs:
- En webb-URL med HTTP
- Hadoop med HiveQL
- Azure Blob Storage
- Azure-tabell
- Azure SQL Database. SQL Managed Instance eller SQL Server
- En dataflödesprovider, OData för närvarande
- Azure Cosmos DB
Eftersom dessa träningsdata används när experimentet körs är de bara tillgängliga i experimentet. Som jämförelse är data som har lagrats i en datauppsättningsmodul tillgängliga för alla experiment på din arbetsyta.
Om du vill komma åt onlinedatakällor i ditt Studio-experiment (klassiskt) lägger du till modulen Importera data i experimentet. Välj sedan Starta guiden Importera data under Egenskaper för stegvisa guidade instruktioner för att välja och konfigurera datakällan. Du kan också välja Datakälla manuellt under Egenskaper och ange de parametrar som behövs för att komma åt data.
De onlinedatakällor som stöds är specificerade i tabellen nedan. Den här tabellen sammanfattar också de filformat som stöds och parametrar som används för att komma åt data.
Viktigt
För närvarande kan modulerna Importera data och Exportera data endast läsa och skriva data från Azure Storage som skapats med hjälp av den klassiska distributionsmodellen. Med andra ord stöds inte den nya Azure Blob Storage-kontotypen som erbjuder en frekvent lagringsnivå eller lågfrekvent lagringsåtkomstnivå.
I allmänhet bör alla Azure-lagringskonton som du kan ha skapat innan det här tjänstalternativet blev tillgängligt inte påverkas. Om du behöver skapa ett nytt konto väljer du Klassisk för distributionsmodellen eller använder Resource Manager och väljer Generell användning i stället för Blob Storage för Typ av konto.
Mer information finns i Azure Blob Storage: Frekvent och Lågfrekvent lagringsnivå.
Onlinedatakällor som stöds
Modulen Importera data i Machine Learning Studio (klassisk) stöder följande datakällor:
| Datakälla | Beskrivning | Parametrar |
|---|---|---|
| Webb-URL via HTTP | Läser data i kommaavgränsade värden (CSV), tabbavgränsade värden (TSV), attributrelationsfilformat (ARFF) och SVM-light-format (Support Vector Machines) från alla webb-URL:er som använder HTTP | URL: Anger det fullständiga namnet på filen, inklusive webbplats-URL:en och filnamnet, med valfritt tillägg. Dataformat: Anger ett av de dataformat som stöds: CSV, TSV, ARFF eller SVM-light. Om data har en rubrikrad används den för att tilldela kolumnnamn. |
| Hadoop/HDFS | Läser data från distribuerad lagring i Hadoop. Du anger de data du vill använda med HiveQL, ett SQL-liknande frågespråk. HiveQL kan också användas för att aggregera data och utföra datafiltrering innan du lägger till data i Studio (klassisk). | Hive-databasfråga: Anger den Hive-fråga som används för att generera data. HCatalog-server-URI : Angav namnet på klustret med formatet <ditt klusternamn.azurehdinsight.net>. Hadoop-användarkontonamn: Anger det Hadoop-användarkontonamn som används för att etablera klustret. Lösenord för Hadoop-användarkonto : Anger de autentiseringsuppgifter som används vid etablering av klustret. Mer information finns i Skapa Hadoop-kluster i HDInsight. Plats för utdata: Anger om data lagras i ett Hadoop-distribuerat filsystem (HDFS) eller i Azure.
Om du lagrar utdata i Azure måste du ange namnet på Azure-lagringskontot, lagringsåtkomstnyckeln och namnet på lagringscontainern. |
| SQL-databas | Läser data som lagras i Azure SQL Database, SQL Managed Instance eller i en SQL Server databas som körs på en virtuell Azure-dator. | Databasservernamn: Anger namnet på den server där databasen körs.
Om en SQL-server finns på en virtuell Azure-dator anger du tcp:<Virtual Machine DNS Name>, 1433 Databasnamn : Anger namnet på databasen på servern. Serveranvändarkontonamn: Anger ett användarnamn för ett konto som har åtkomstbehörighet för databasen. Lösenord för serveranvändarkonto: Anger lösenordet för användarkontot. Databasfråga:Ange en SQL-instruktion som beskriver de data som du vill läsa. |
| Lokal SQL-databas | Läser data som lagras i en SQL-databas. | Datagateway: Anger namnet på den Datahantering Gateway som är installerad på en dator där den kan komma åt din SQL Server databas. Information om hur du konfigurerar gatewayen finns i Utföra avancerad analys med Machine Learning Studio (klassisk) med data från en SQL-server. Databasservernamn: Anger namnet på den server där databasen körs. Databasnamn : Anger namnet på databasen på servern. Serveranvändarkontonamn: Anger ett användarnamn för ett konto som har åtkomstbehörighet för databasen. Användarnamn och lösenord: Klicka på Ange värden för att ange dina databasautentiseringsuppgifter. Du kan använda Windows-integrerad autentisering eller SQL Server-autentisering beroende på hur din SQL Server har konfigurerats. Databasfråga:Ange en SQL-instruktion som beskriver de data som du vill läsa. |
| Azure-tabell | Läser data från tabelltjänsten i Azure Storage. Om du läser stora mängder data sällan använder du Azure Table Service. Det ger en flexibel, icke-relationell (NoSQL), massivt skalbar, billig och lagringslösning med hög tillgänglighet. |
Alternativen i importdata ändras beroende på om du har åtkomst till offentlig information eller ett privat lagringskonto som kräver inloggningsuppgifter. Detta bestäms av autentiseringstypen som kan ha värdet "PublicOrSAS" eller "Konto", som var och en har en egen uppsättning parametrar. URI för signatur för offentlig eller delad åtkomst (SAS): Parametrarna är:
Anger de rader som ska söka efter egenskapsnamn: Värdena är TopN för att genomsöka det angivna antalet rader eller ScanAll för att hämta alla rader i tabellen. Om data är homogena och förutsägbara rekommenderar vi att du väljer TopN och anger ett tal för N. För stora tabeller kan detta resultera i snabbare lästider. Om data är strukturerade med uppsättningar med egenskaper som varierar beroende på tabellens djup och position väljer du alternativet ScanAll för att genomsöka alla rader. Detta säkerställer integriteten för den resulterande egenskapen och metadatakonverteringen.
Kontonyckel: Anger den lagringsnyckel som är associerad med kontot. Tabellnamn : Anger namnet på den tabell som innehåller de data som ska läsas. Rader för att söka efter egenskapsnamn: Värdena är TopN för att genomsöka det angivna antalet rader eller ScanAll för att hämta alla rader i tabellen. Om data är homogena och förutsägbara rekommenderar vi att du väljer TopN och anger ett tal för N. För stora tabeller kan detta resultera i snabbare lästider. Om data är strukturerade med uppsättningar med egenskaper som varierar beroende på tabellens djup och position väljer du alternativet ScanAll för att genomsöka alla rader. Detta säkerställer integriteten för den resulterande egenskapen och metadatakonverteringen. |
| Azure Blob Storage | Läser data som lagras i Blob-tjänsten i Azure Storage, inklusive bilder, ostrukturerad text eller binära data. Du kan använda Blob-tjänsten för att offentligt exponera data eller för att lagra programdata privat. Du kan komma åt dina data var du än befinner dig med hjälp av HTTP- eller HTTPS-anslutningar. |
Alternativen i modulen Importera data ändras beroende på om du har åtkomst till offentlig information eller ett privat lagringskonto som kräver inloggningsuppgifter. Detta bestäms av autentiseringstypen som kan ha värdet "PublicOrSAS" eller "Konto". URI för signatur för offentlig eller delad åtkomst (SAS): Parametrarna är:
Filformat: Anger formatet för data i Blob-tjänsten. De format som stöds är CSV, TSV och ARFF.
Kontonyckel: Anger den lagringsnyckel som är associerad med kontot. Sökväg till container, katalog eller blob : Anger namnet på den blob som innehåller de data som ska läsas. Blobfilformat: Anger formatet för data i blobtjänsten. De dataformat som stöds är CSV, TSV, ARFF, CSV med en angiven kodning och Excel.
Du kan använda Excel-alternativet för att läsa data från Excel-arbetsböcker. I alternativet Excel-dataformat anger du om data finns i ett Excel-kalkylbladsintervall eller i en Excel-tabell. I excel-bladet eller det inbäddade tabellalternativet anger du namnet på det blad eller den tabell som du vill läsa från. |
| Dataflödesprovider | Läser data från en feedprovider som stöds. För närvarande stöds endast OData-formatet (Open Data Protocol). | Datainnehållstyp: Anger OData-formatet. Käll-URL: Anger den fullständiga URL:en för dataflödet. Följande URL läser till exempel från Northwind-exempeldatabasen: https://services.odata.org/northwind/northwind.svc/ |
Importera från ett annat experiment
Det finns tillfällen då du vill ta ett mellanliggande resultat från ett experiment och använda det som en del av ett annat experiment. Det gör du genom att spara modulen som en datauppsättning:
- Klicka på utdata för modulen som du vill spara som en datauppsättning.
- Klicka på Spara som datauppsättning.
- När du uppmanas till det anger du ett namn och en beskrivning som gör att du enkelt kan identifiera datauppsättningen.
- Klicka på OK-bockmarkeringen .
När sparande har slutförts är datauppsättningen tillgänglig för användning i alla experiment på din arbetsyta. Du hittar den i listan Sparade datamängder i modulpaletten.