Gruppera data i bins-komponenten
Den här artikeln beskriver hur du använder komponenten Gruppdata i bins i Azure Machine Learning-designern för att gruppera nummer eller ändra fördelningen av kontinuerliga data.
Komponenten Gruppera data i lagerplatser har stöd för flera alternativ för att binera data. Du kan anpassa hur intervallkanterna anges och hur värden fördelas i intervallen. Du kan till exempel:
- Skriv manuellt en serie värden som ska fungera som intervallgränser.
- Tilldela värden till intervall med hjälp av quantiles eller percentilrankningar.
- Framtvinga en jämn fördelning av värden i intervallen.
Mer om bining och gruppering
Att gruppera eller gruppera data (kallas ibland kvantisering) är ett viktigt verktyg för att förbereda numeriska data för maskininlärning. Det är användbart i scenarier som dessa:
En kolumn med kontinuerliga tal har för många unika värden för att modellera effektivt. Så du tilldelar automatiskt eller manuellt värdena till grupper för att skapa en mindre uppsättning diskreta intervall.
Du vill ersätta en kolumn med tal med kategorivärden som representerar specifika intervall.
Du kanske till exempel vill gruppera värden i en ålderskolumn genom att ange anpassade intervall, till exempel 1–15, 16–22, 23–30 och så vidare för användardemografi.
En datauppsättning har några extrema värden, alla långt utanför det förväntade intervallet, och dessa värden har en outsized påverkan på den tränade modellen. För att minimera biasen i modellen kan du omvandla data till en enhetlig distribution med hjälp av quantiles-metoden.
Med den här metoden avgör komponenten Gruppera data i lagerplatser de idealiska intervallplatserna och intervallbredderna för att säkerställa att ungefär samma antal exempel hamnar i varje lagerplats. Beroende på vilken normaliseringsmetod du väljer omvandlas värdena i intervallen antingen till percentiler eller mappas till ett lagerplatsnummer.
Exempel på binning
Följande diagram visar fördelningen av numeriska värden före och efter bining med quantiles-metoden . Observera att jämfört med rådata till vänster har data binerats och omvandlats till en enhetsnormal skala.
Eftersom det finns så många sätt att gruppera data, alla anpassningsbara, rekommenderar vi att du experimenterar med olika metoder och värden.
Så här konfigurerar du gruppdata i intervall
Lägg till komponenten Gruppera data i lagerplatser i pipelinen i designern. Du hittar den här komponenten i kategorin Datatransformering.
Anslut den datauppsättning som har numeriska data till lagerplatsen. Kvantisering kan endast tillämpas på kolumner som innehåller numeriska data.
Om datauppsättningen innehåller icke-numeriska kolumner använder du komponenten Välj kolumner i datauppsättning för att välja en delmängd av kolumner att arbeta med.
Ange binningsläget. Binningsläget avgör andra parametrar, så se till att välja alternativet Binning-läge först. Följande typer av binning stöds:
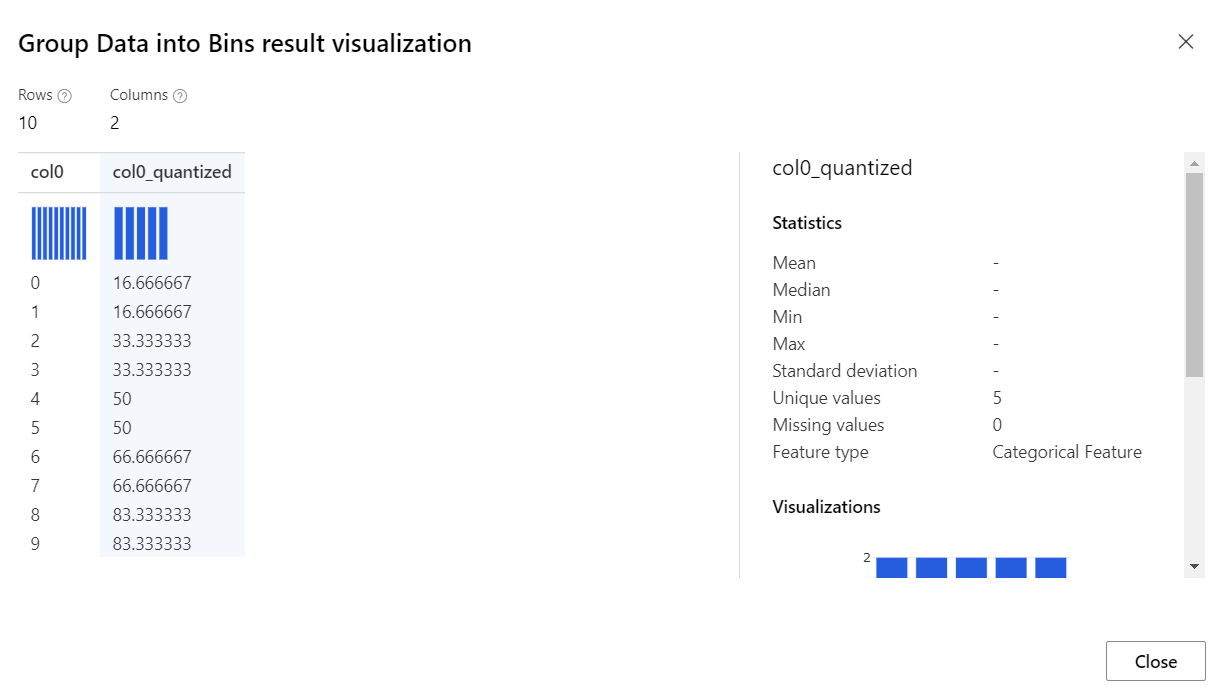
Quantiles: Kvantilmetoden tilldelar värden till lagerplatser baserat på percentilrankningar. Den här metoden kallas även för lika hög binning.
Lika med bredd: Med det här alternativet måste du ange det totala antalet lagerplatser. Värdena från datakolumnen placeras i intervallen så att varje lagerplats har samma intervall mellan start- och slutvärden. Därför kan vissa lagerplatser ha fler värden om data klumpas ihop runt en viss punkt.
Anpassade kanter: Du kan ange de värden som börjar varje lagerplats. Gränsvärdet är alltid den nedre gränsen för intervallet.
Anta till exempel att du vill gruppera värden i två lagerplatser. En har värden som är större än 0 och en har värden som är mindre än eller lika med 0. För lagerplatskanter anger du i det här fallet 0 i kommaavgränsad lista över lagerplatskanter. Utdata för komponenten blir 1 och 2, vilket anger bin-indexet för varje radvärde. Observera att listan med kommaavgränsade värden måste vara i stigande ordning, till exempel 1, 3, 5, 7.
Anteckning
Entropy MDL-läge definieras i Studio (klassisk) och det finns inget motsvarande öppen källkod paket som kan användas för att stödja i Designer ännu.
Om du använder bineringslägena Quantiles och Equal Width använder du alternativet Antal lagerplatser för att ange hur många lagerplatser eller quantiler du vill skapa.
Använd kolumnväljaren för att välja de kolumner som har de värden som du vill intervallera för kolumner. Kolumner måste vara en numerisk datatyp.
Samma binningsregel tillämpas på alla tillämpliga kolumner som du väljer. Om du behöver gruppera vissa kolumner med en annan metod använder du en separat instans av komponenten Gruppdata i lagerplatser för varje uppsättning kolumner.
Varning
Om du väljer en kolumn som inte är en tillåten typ genereras ett körningsfel. Komponenten returnerar ett fel så snart den hittar en kolumn av otillåten typ. Om du får ett fel granskar du alla markerade kolumner. Felet visar inte alla ogiltiga kolumner.
För Utdataläge anger du hur du vill mata ut de kvantiserade värdena:
Tillägg: Skapar en ny kolumn med de intervallerade värdena och lägger till den i indatatabellen.
Inplace: Ersätter de ursprungliga värdena med de nya värdena i datauppsättningen.
ResultOnly: Returnerar bara resultatkolumnerna.
Om du väljer binningsläget Quantiles använder du alternativet Quantile-normalisering för att fastställa hur värden normaliseras innan du sorterar i quantiles. Observera att normaliseringsvärden transformerar värdena men inte påverkar det slutliga antalet lagerplatser.
Följande normaliseringstyper stöds:
Procent: Värden normaliseras inom intervallet [0 100].
PQuantile: Värden normaliseras inom intervallet [0,1].
QuantileIndex: Värden normaliseras inom intervallet [1,antal lagerplatser].
Om du väljer alternativet Anpassade kanter anger du en kommaavgränsad lista med tal som ska användas som intervallkanter i den kommaavgränsade listan över textrutor för intervallkanter .
Värdena markerar den punkt som delar upp lagerplatser. Om du till exempel anger ett bin edge-värde genereras två lagerplatser. Om du anger två bin edge-värden genereras tre intervall.
Värdena måste sorteras i den ordning som intervallen skapas, från lägsta till högsta.
Välj alternativet Tagga kolumner som kategoriska för att ange att de kvantiserade kolumnerna ska hanteras som kategoriska variabler.
Skicka pipelinen.
Resultat
Komponenten Gruppera data i lagerplatser returnerar en datauppsättning där varje element har raderats i enlighet med det angivna läget.
Den returnerar också en binningstransformering. Den funktionen kan skickas till komponenten Tillämpa transformering för att ta bort nya dataexempel med hjälp av samma lagringsläge och parametrar.
Tips
Om du använder binning på dina träningsdata måste du använda samma binningsmetod för data som du använder för testning och förutsägelse. Du måste också använda samma lagerplatser och intervallbredder.
För att säkerställa att data alltid transformeras med samma binningsmetod rekommenderar vi att du sparar användbara datatransformeringar. Tillämpa dem sedan på andra datauppsättningar med hjälp av komponenten Tillämpa transformering .
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Machine Learning.