Välja kolumntranformering
I den här artikeln beskrivs hur du använder komponenten Välj kolumntransformering i Azure Machine Learning-designern. Syftet med komponenten Transformera kolumner är att säkerställa att en förutsägbar och konsekvent uppsättning kolumner används i nedströms maskininlärningsåtgärder.
Den här komponenten är användbar för uppgifter som bedömning, som kräver specifika kolumner. Ändringar i de tillgängliga kolumnerna kan bryta pipelinen eller ändra resultatet.
Du använder Transformera kolumner för att skapa och spara en uppsättning kolumner. Använd sedan komponenten Tillämpa transformering för att tillämpa dessa val på nya data.
Så här använder du transformering av markera kolumner
Det här scenariot förutsätter att du vill använda funktionsval för att generera en dynamisk uppsättning kolumner som ska användas för att träna en modell. För att säkerställa att kolumnvalen är desamma för bedömningsprocessen använder du komponenten Välj kolumntransformering för att avbilda kolumnvalen och tillämpa dem någon annanstans i pipelinen.
Lägg till en indatauppsättning i pipelinen i designern.
Lägg till en instans av Filterbaserad funktionsval.
Anslut komponenterna och konfigurera funktionsvalskomponenten för att automatiskt hitta ett antal bästa funktioner i indatauppsättningen.
Lägg till en instans av Träningsmodell och använd utdata från Filterbaserad funktionsval som indata för träning.
Viktigt
Eftersom funktionsvikt baseras på värdena i kolumnen kan du inte veta i förväg vilka kolumner som kan vara tillgängliga för indata till Träningsmodell.
Koppla en instans av komponenten Select Columns Transform (Transformera kolumner).
Det här steget genererar en kolumnmarkering som en transformering som kan sparas eller tillämpas på andra datauppsättningar. Det här steget säkerställer att kolumnerna som identifieras i funktionsval sparas så att andra komponenter kan återanvändas.
Lägg till komponenten Poängsätta modell .
Anslut inte indatauppsättningen. Lägg i stället till komponenten Tillämpa transformering och anslut utdata från funktionsvalstransformeringen.
Pipelinestrukturen bör se ut så här:
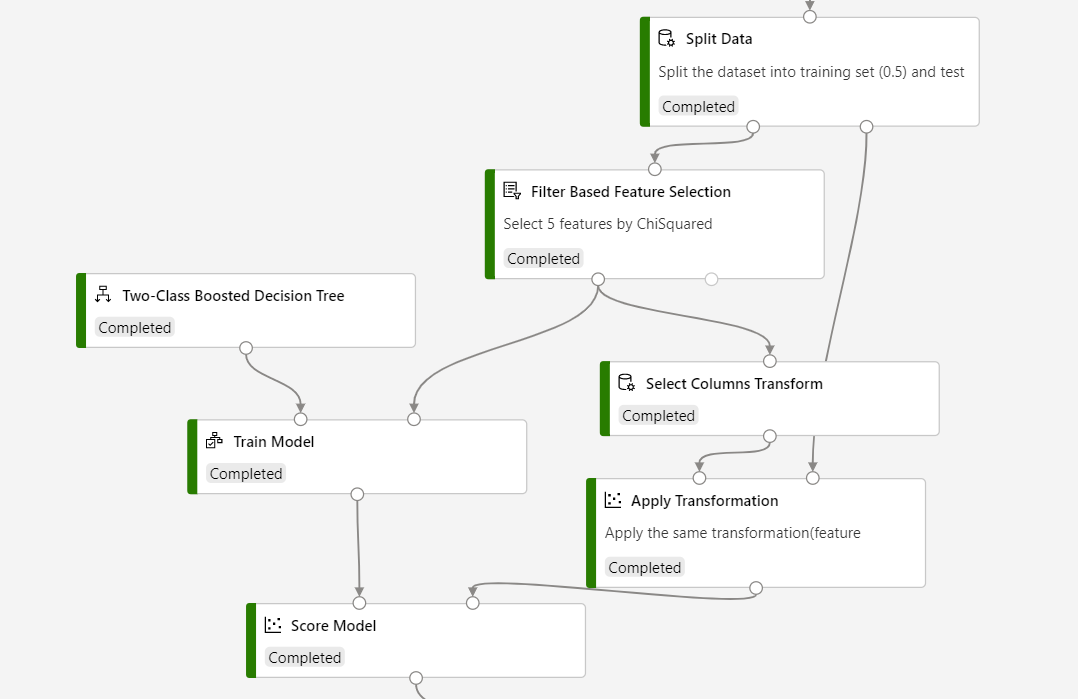
Viktigt
Du kan inte förvänta dig att tillämpa filterbaserat funktionsval på bedömningsdatauppsättningen och få samma resultat. Eftersom funktionsval baseras på värden kan den välja en annan uppsättning kolumner, vilket skulle göra att bedömningsåtgärden misslyckas.
Skicka pipelinen.
Den här processen för att spara och sedan tillämpa en kolumnmarkering säkerställer att samma dataschema är tillgängligt för träning och bedömning.
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Machine Learning.