Använda en anpassad container för att distribuera en modell till en onlineslutpunkt
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Lär dig hur du använder en anpassad container för att distribuera en modell till en onlineslutpunkt i Azure Machine Learning.
Anpassade containerdistributioner kan använda andra webbservrar än den Python Flask-standardserver som används av Azure Machine Learning. Användare av dessa distributioner kan fortfarande dra nytta av Azure Machine Learnings inbyggda övervakning, skalning, aviseringar och autentisering.
I följande tabell visas olika distributionsexempel som använder anpassade containrar, till exempel TensorFlow Serving, TorchServe, Triton Inference Server, Plumber R-paket och Azure Machine Learning Inference Minimal avbildning.
| Exempel | Skript (CLI) | beskrivning |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | Distribuera flera modeller till en enda distribution genom att utöka Azure Machine Learning Inference Minimal avbildning. |
| minimal/enkel modell | deploy-custom-container-minimal-single-model | Distribuera en enskild modell genom att utöka Azure Machine Learning Inference Minimal avbildning. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Distribuera två MLFlow-modeller med olika Python-krav till två separata distributioner bakom en enda slutpunkt med azure machine learning-slutsatsdragningen Minimal avbildning. |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Distribuera tre regressionsmodeller till en slutpunkt med hjälp av Plumber R-paketet |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Distribuera en Halv plus två-modell med hjälp av en anpassad TensorFlow-serveringscontainer med hjälp av standardmodellregistreringsprocessen. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Distribuera en Half Plus Two-modell med en anpassad TensorFlow-serveringscontainer med modellen integrerad i avbildningen. |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | Distribuera en enskild modell med hjälp av en anpassad TorchServe-container. |
| torchserve/huggingface-textgen | deploy-custom-container-torchserve-huggingface-textgen | Distribuera Hugging Face-modeller till en onlineslutpunkt och följ med i exemplet Hugging Face Transformers TorchServe. |
| triton/single-model | deploy-custom-container-triton-single-model | Distribuera en Triton-modell med en anpassad container |
Den här artikeln fokuserar på att betjäna en TensorFlow-modell med TensorFlow -servering (TF).
Varning
Microsoft kanske inte kan hjälpa till att felsöka problem som orsakas av en anpassad avbildning. Om du får problem kan du bli ombedd att använda standardbilden eller någon av de bilder som Microsoft tillhandahåller för att se om problemet är specifikt för din bild.
Förutsättningar
Innan du följer stegen i den här artikeln kontrollerar du att du har följande förutsättningar:
En Azure Machine Learning-arbetsyta. Om du inte har någon använder du stegen i artikeln Snabbstart: Skapa arbetsyteresurser för att skapa en.
Azure CLI och
mltillägget eller Azure Machine Learning Python SDK v2:Information om hur du installerar Azure CLI och tillägget finns i Installera, konfigurera och använda CLI (v2).
Viktigt!
CLI-exemplen i den här artikeln förutsätter att du använder Bash-gränssnittet (eller det kompatibla). Till exempel från ett Linux-system eller Windows-undersystem för Linux.
Om du vill installera Python SDK v2 använder du följande kommando:
pip install azure-ai-ml azure-identityOm du vill uppdatera en befintlig installation av SDK:et till den senaste versionen använder du följande kommando:
pip install --upgrade azure-ai-ml azure-identityMer information finns i Installera Python SDK v2 för Azure Machine Learning.
Du, eller tjänstens huvudnamn som du använder, måste ha deltagaråtkomst till den Azure-resursgrupp som innehåller din arbetsyta. Du har en sådan resursgrupp om du har konfigurerat din arbetsyta med hjälp av snabbstartsartikeln.
Om du vill distribuera lokalt måste Docker-motorn köras lokalt. Det här steget rekommenderas starkt. Det hjälper dig att felsöka problem.
Ladda ned källkod
Om du vill följa med i den här självstudien klonar du källkoden från GitHub.
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Initiera miljövariabler
Definiera miljövariabler:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Ladda ned en TensorFlow-modell
Ladda ned och packa upp en modell som delar indata med två och lägger till 2 i resultatet:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Kör en TF-serveringsbild lokalt för att testa att den fungerar
Använd docker för att köra avbildningen lokalt för testning:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Kontrollera att du kan skicka liveness- och bedömningsbegäranden till bilden
Kontrollera först att containern är aktiv, vilket innebär att processen i containern fortfarande körs. Du bör få ett svar på 200 (OK).
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Kontrollera sedan att du kan få förutsägelser om omärkta data:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
Stoppa avbildningen
Nu när du har testat lokalt stoppar du avbildningen:
docker stop tfserving-test
Distribuera din onlineslutpunkt till Azure
Distribuera sedan din onlineslutpunkt till Azure.
Skapa en YAML-fil för slutpunkten och distributionen
Du kan konfigurera molndistributionen med YAML. Ta en titt på YAML-exemplet för det här exemplet:
tfserving-endpoint.yml
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
tfserving-deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: {{MODEL_VERSION}}
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/{{MODEL_VERSION}}
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
Det finns några viktiga begrepp att märka i den här YAML/Python-parametern:
Beredskapsväg jämfört med liveness-vägen
En HTTP-server definierar sökvägar för både livskraft och beredskap. En liveness-väg används för att kontrollera om servern körs. En beredskapsväg används för att kontrollera om servern är redo att fungera. I maskininlärningsslutsats kan en server svara 200 OK på en liveness-begäran innan en modell läses in. Servern kunde svara 200 OK på en beredskapsbegäran först när modellen har lästs in i minnet.
Mer information om liveness- och beredskapsavsökningar finns i Kubernetes-dokumentationen.
Observera att den här distributionen använder samma sökväg för både liveness och beredskap, eftersom TF-servering endast definierar en liveness-väg.
Hitta den monterade modellen
När du distribuerar en modell som en onlineslutpunkt monterar Azure Machine Learning din modell till slutpunkten. Med modellmontering kan du distribuera nya versioner av modellen utan att behöva skapa en ny Docker-avbildning. Som standard finns en modell registrerad med namnet foo och version 1 på följande sökväg i den distribuerade containern: /var/azureml-app/azureml-models/foo/1
Om du till exempel har en katalogstruktur med /azureml-examples/cli/endpoints/online/custom-container på den lokala datorn, där modellen heter half_plus_two:
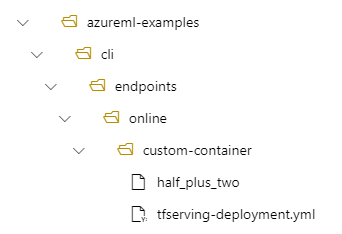
Och tfserving-deployment.yml innehåller:
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
Sedan finns din modell under /var/azureml-app/azureml-models/tfserving-deployment/1 i distributionen:
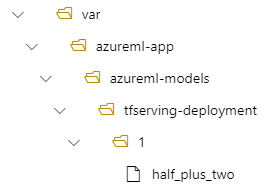
Du kan också konfigurera .model_mount_path Du kan ändra sökvägen där modellen är monterad.
Viktigt!
model_mount_path Måste vara en giltig absolut sökväg i Linux (operativsystemet för containeravbildningen).
Du kan till exempel ha model_mount_path parametern i tfserving-deployment.yml:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
.....
Sedan finns din modell på /var/tfserving-model-mount/tfserving-deployment/1 i distributionen. Observera att den inte längre finns under azureml-app/azureml-models, utan under den monteringssökväg som du angav:

Skapa slutpunkten och distributionen
Nu när du förstår hur YAML skapades skapar du slutpunkten.
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving-endpoint.yml
Det kan ta några minuter att skapa en distribution.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving-deployment.yml --all-traffic
Anropa slutpunkten
När distributionen är klar kan du se om du kan göra en bedömningsbegäran till den distribuerade slutpunkten.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Ta bort slutpunkten
Nu när du har gjort mål med slutpunkten kan du ta bort den:
az ml online-endpoint delete --name tfserving-endpoint