Använda Azure Machine Learning Studio i ett virtuellt Azure-nätverk
Dricks
Microsoft rekommenderar att du använder hanterade virtuella Azure Machine Learning-nätverk i stället för stegen i den här artikeln. Med ett hanterat virtuellt nätverk hanterar Azure Machine Learning jobbet med nätverksisolering för din arbetsyta och hanterade beräkningar. Du kan också lägga till privata slutpunkter för resurser som behövs av arbetsytan, till exempel Azure Storage-konto. Mer information finns i Hanterad nätverksisolering för arbetsyta.
Den här artikeln beskriver hur du använder Azure Machine Learning-studio i ett virtuellt nätverk. Studion innehåller funktioner som AutoML, designern och dataetiketter.
Vissa av studiofunktionerna är inaktiverade som standard i ett virtuellt nätverk. Om du vill återaktivera dessa funktioner måste du aktivera hanterad identitet för lagringskonton som du tänker använda i studion.
Följande åtgärder är inaktiverade som standard i ett virtuellt nätverk:
- Förhandsgranska data i studion.
- Visualisera data i designern.
- Distribuera en modell i designern.
- Skicka ett AutoML-experiment.
- Starta ett dataetiketteringsprojekt.
Studio stöder läsning av data från följande datalagertyper i ett virtuellt nätverk:
- Azure Storage-konto (blob &fil)
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure SQL Database
I den här artikeln kan du se hur du:
- Ge studioåtkomst till data som lagras i ett virtuellt nätverk.
- Få åtkomst till studion från en resurs i ett virtuellt nätverk.
- Förstå hur studion påverkar lagringssäkerheten.
Förutsättningar
Läs översikten över nätverkssäkerhet för att förstå vanliga scenarier och arkitektur för virtuella nätverk.
Ett befintligt virtuellt nätverk och undernät som ska användas.
En befintlig Azure Machine Learning-arbetsyta med en privat slutpunkt.
Ett befintligt Azure Storage-konto har lagt till ditt virtuella nätverk.
En befintlig Azure Machine Learning-arbetsyta med en privat slutpunkt.
Ett befintligt Azure Storage-konto har lagt till ditt virtuella nätverk.
- Information om hur du skapar en säker arbetsyta finns i Självstudie: Skapa en säker arbetsyta eller Självstudie: Skapa en säker arbetsyta med hjälp av en mall.
Begränsningar
Azure Storage-konto
När lagringskontot finns i det virtuella nätverket finns det extra valideringskrav för att använda studio:
- Om lagringskontot använder en tjänstslutpunkt måste slutpunkten för arbetsytans privata slutpunkt och lagringstjänst finnas i samma undernät i det virtuella nätverket.
- Om lagringskontot använder en privat slutpunkt måste den privata slutpunkten för arbetsytan och den privata lagringsslutpunkten finnas i samma virtuella nätverk. I det här fallet kan de finnas i olika undernät.
Exempelpipeline för designer
Det finns ett känt problem där användare inte kan köra en exempelpipeline på designerns startsida. Det här problemet beror på att exempeldatauppsättningen som används i exempelpipelinen är en global Azure-datauppsättning. Det går inte att komma åt den från en virtuell nätverksmiljö.
Lös problemet genom att använda en offentlig arbetsyta för att köra exempelpipelinen. Eller ersätt exempeldatauppsättningen med din egen datauppsättning på arbetsytan i ett virtuellt nätverk.
Datalager: Azure Storage-konto
Använd följande steg för att aktivera åtkomst till data som lagras i Azure Blob och File Storage:
Dricks
Det första steget krävs inte för standardlagringskontot för arbetsytan. Alla andra steg krävs för alla lagringskonton bakom det virtuella nätverket och används av arbetsytan, inklusive standardlagringskontot.
Om lagringskontot är standardlagringen för din arbetsyta hoppar du över det här steget. Om det inte är standard beviljar du arbetsytans hanterade identitet rollen Storage Blob Data Reader för Azure Storage-kontot så att den kan läsa data från bloblagring.
Mer information finns i den inbyggda rollen Blob Data Reader .
Ge din Azure-användaridentitet rollen Storage Blob Data-läsare för Azure Storage-kontot. Studion använder din identitet för att komma åt data till bloblagring, även om arbetsytans hanterade identitet har rollen Läsare.
Mer information finns i den inbyggda rollen Blob Data Reader .
Ge arbetsytans hanterade identitet rollen Läsare för privata lagringsslutpunkter. Om lagringstjänsten använder en privat slutpunkt beviljar du arbetsytans hanterade identitet Läsare åtkomst till den privata slutpunkten. Arbetsytans hanterade identitet i Microsoft Entra-ID har samma namn som din Azure Machine Learning-arbetsyta. En privat slutpunkt krävs för både blob- och fillagringstyper.
Dricks
Ditt lagringskonto kan ha flera privata slutpunkter. Ett lagringskonto kan till exempel ha en separat privat slutpunkt för blob, fil och dfs (Azure Data Lake Storage Gen2). Lägg till den hanterade identiteten i alla dessa slutpunkter.
Mer information finns i den inbyggda rollen Läsare .
Aktivera hanterad identitetsautentisering för standardlagringskonton. Varje Azure Machine Learning-arbetsyta har två standardlagringskonton, ett standardkonto för bloblagring och ett standardfilarkivkonto. Båda definieras när du skapar din arbetsyta. Du kan också ange nya standardvärden på sidan Datalagerhantering.

I följande tabell beskrivs varför hanterad identitetsautentisering används för standardlagringskonton för arbetsytan.
Lagringskonto Kommentar Standardbloblagring för arbetsyta Lagrar modelltillgångar från designern. Aktivera hanterad identitetsautentisering på det här lagringskontot för att distribuera modeller i designern. Om hanterad identitetsautentisering är inaktiverad används användarens identitet för att komma åt data som lagras i bloben.
Du kan visualisera och köra en designerpipeline om den använder ett icke-standarddatalager som har konfigurerats för att använda hanterad identitet. Men om du försöker distribuera en tränad modell utan att hanterad identitet är aktiverad i standarddatalagringen misslyckas distributionen oavsett andra datalager som används.Standardfilarkiv för arbetsyta Lagrar AutoML-experimenttillgångar. Aktivera hanterad identitetsautentisering på det här lagringskontot för att skicka AutoML-experiment. Konfigurera datalager för att använda hanterad identitetsautentisering. När du har lagt till ett Azure Storage-konto i ditt virtuella nätverk med antingen en tjänstslutpunkt eller en privat slutpunkt måste du konfigurera ditt datalager så att det använder hanterad identitetsautentisering. På så sätt kan studion komma åt data i ditt lagringskonto.
Azure Machine Learning använder datalager för att ansluta till lagringskonton. När du skapar ett nytt datalager använder du följande steg för att konfigurera ett datalager för att använda hanterad identitetsautentisering:
I studion väljer du Datalager.
Om du vill skapa ett nytt datalager väljer du + Skapa.
I inställningarna för datalager aktiverar du växeln för Använd arbetsytehanterad identitet för förhandsgranskning och profilering av data i Azure Machine Learning-studio.
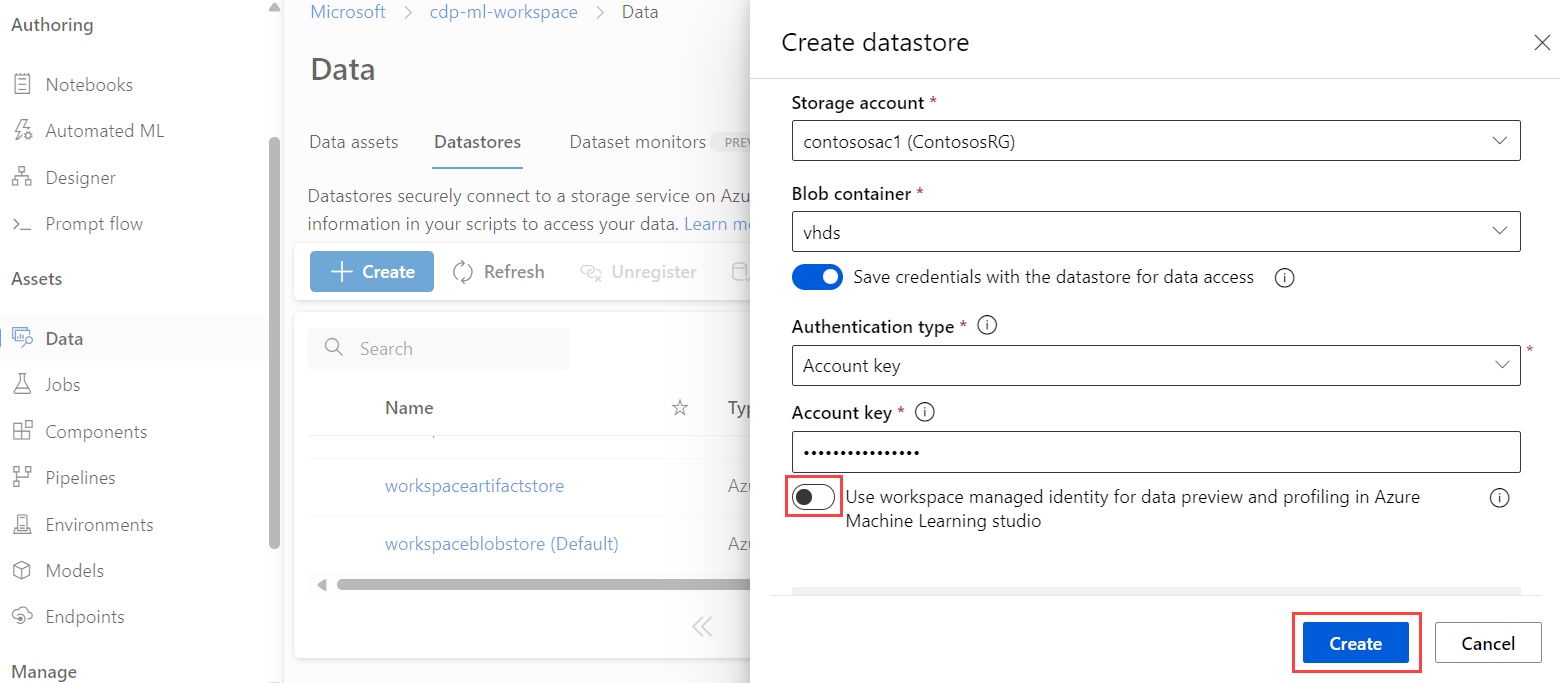
I Nätverksinställningarna för Azure Storage-kontot lägger du till
Microsoft.MachineLearningService/workspacesresurstypen och anger instansnamnet till arbetsytan.
De här stegen lägger till arbetsytans hanterade identitet som läsare i den nya lagringstjänsten med hjälp av rollbaserad åtkomstkontroll i Azure (RBAC). Med läsåtkomst kan arbetsytan visa resursen, men inte göra ändringar.


Datalager: Azure Data Lake Storage Gen1
När du använder Azure Data Lake Storage Gen1 som ett datalager kan du bara använda åtkomstkontrollistor i POSIX-format. Du kan tilldela arbetsytans hanterade identitet åtkomst till resurser precis som andra säkerhetsobjekt. Mer information finns i Åtkomstkontroll i Azure Data Lake Storage Gen1.
Datalager: Azure Data Lake Storage Gen2
När du använder Azure Data Lake Storage Gen2 som ett datalager kan du använda åtkomstkontrollistor i både Azure RBAC- och POSIX-format för att styra dataåtkomsten i ett virtuellt nätverk.
Följ stegen i avsnittet Datastore: Azure Storage-konto i den här artikeln om du vill använda Azure RBAC. Data Lake Storage Gen2 baseras på Azure Storage, så samma steg gäller när du använder Azure RBAC.
Om du vill använda ACL:er kan arbetsytans hanterade identitet tilldelas åtkomst precis som andra säkerhetsobjekt. Mer information finns i Åtkomstkontrollistor för filer och kataloger.
Datalager: Azure SQL Database
För att få åtkomst till data som lagras i en Azure SQL Database med en hanterad identitet måste du skapa en SQL-innesluten användare som mappar till den hanterade identiteten. Mer information om hur du skapar en användare från en extern provider finns i Skapa inneslutna användare som mappats till Microsoft Entra-identiteter.
När du har skapat en SQL-innesluten användare beviljar du behörigheter till den med hjälp av kommandot GRANT T-SQL.
Mellanliggande komponentutdata
När du använder azure Machine Learning-designerns mellanliggande komponentutdata kan du ange utdataplatsen för valfri komponent i designern. Använd dessa utdata för att lagra mellanliggande datauppsättningar på en separat plats i säkerhets-, loggnings- eller granskningssyfte. Använd följande steg för att ange utdata:
- Välj den komponent vars utdata du vill ange.
- I fönstret Komponentinställningar väljer du Utdatainställningar.
- Ange det datalager som du vill använda för respektive komponentutdata.
Kontrollera att du har åtkomst till mellanliggande lagringskonton i ditt virtuella nätverk. Annars misslyckas pipelinen.
Aktivera hanterad identitetsautentisering för mellanliggande lagringskonton för att visualisera utdata.
Få åtkomst till studion från en resurs i det virtuella nätverket
Om du kommer åt studion från en resurs i ett virtuellt nätverk (till exempel en beräkningsinstans eller virtuell dator) måste du tillåta utgående trafik från det virtuella nätverket till studion.
Om du till exempel använder nätverkssäkerhetsgrupper (NSG) för att begränsa utgående trafik lägger du till en regel i ett tjänsttaggmål för AzureFrontDoor.Frontend.
Brandväggsinställningar
Vissa lagringstjänster, till exempel Azure Storage-konto, har brandväggsinställningar som gäller för den offentliga slutpunkten för den specifika tjänstinstansen. Vanligtvis kan du med den här inställningen tillåta/neka åtkomst från specifika IP-adresser från det offentliga Internet. Detta stöds inte när du använder Azure Machine Learning-studio. Det stöds när du använder Azure Machine Learning SDK eller CLI.
Dricks
Azure Machine Learning-studio stöds när du använder Azure Firewall-tjänsten. Mer information finns i Konfigurera inkommande och utgående nätverkstrafik.
Relaterat innehåll
Den här artikeln är en del av en serie om att skydda ett Azure Machine Learning-arbetsflöde. Se de andra artiklarna i den här serien: