Version och spåra Azure Machine Learning-datauppsättningar
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
I den här artikeln får du lära dig att version och spåra Azure Machine Learning-datauppsättningar för reproducerbarhet. Datamängden versionshantering bokmärken specifika tillstånd för dina data, så att du kan tillämpa en specifik version av datamängden för framtida experiment.
Du kanske vill versionshantera dina Azure Machine Learning-resurser i följande vanliga scenarier:
- När nya data blir tillgängliga för omträning
- När du använder olika metoder för förberedelse av data eller funktioner
Förutsättningar
Azure Machine Learning SDK för Python. Det här SDK:et innehåller paketet azureml-datasets
En Azure Machine Learning-arbetsyta. Skapa en ny arbetsyta eller hämta en befintlig arbetsyta med det här kodexemplet:
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Registrera och hämta datauppsättningsversioner
Du kan version, återanvända och dela en registrerad datamängd mellan experiment och med dina kollegor. Du kan registrera flera datauppsättningar under samma namn och hämta en specifik version efter namn och versionsnummer.
Registrera en datamängdsversion
Det här kodexemplet anger parametern create_new_version för datamängden titanic_ds till True, för att registrera en ny version av datamängden. Om arbetsytan inte har någon befintlig titanic_ds datauppsättning registrerad skapar koden en ny datauppsättning med namnet titanic_dsoch anger dess version till 1.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Hämta en datauppsättning efter namn
Som standard Dataset returnerar metoden class get_by_name() den senaste versionen av datauppsättningen som registrerats med arbetsytan.
Den här koden returnerar version 1 av datamängden titanic_ds .
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Metodtips för versionshantering
När du skapar en datamängdsversion skapar du ingen extra kopia av data med arbetsytan. Eftersom datauppsättningar är referenser till data i lagringstjänsten har du en enda sanningskälla som hanteras av lagringstjänsten.
Viktigt!
Om data som refereras till av datauppsättningen skrivs över eller tas bort återställs inte ändringen genom ett anrop till en viss version av datauppsättningen.
När du läser in data från en datauppsättning läses alltid det aktuella datainnehållet som refereras av datauppsättningen in. Om du vill se till att varje datamängdsversion är reproducerbar rekommenderar vi att du undviker ändringar av datainnehåll som refereras av datamängdsversionen. När nya data kommer in sparar du nya datafiler i en separat datamapp och skapar sedan en ny datamängdsversion för att inkludera data från den nya mappen.
Den här bilden och exempelkoden visar det rekommenderade sättet att både strukturera dina datamappar och skapa datauppsättningsversioner som refererar till dessa mappar:

from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Version av en ML-pipelineutdatauppsättning
Du kan använda en datauppsättning som indata och utdata för varje ML-pipelinesteg . När du kör pipelines igen registreras utdata från varje pipelinesteg som en ny datamängdsversion.
Machine Learning-pipelines fyller utdata för varje steg i en ny mapp varje gång pipelinen körs igen. De versionshanterade utdatauppsättningarna blir sedan reproducerbara. Mer information finns i datauppsättningar i pipelines.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Spåra data i dina experiment
Azure Machine Learning spårar dina data i hela experimentet som indata- och utdatauppsättningar. I dessa scenarier spåras dina data som en indatauppsättning:
Som ett
DatasetConsumptionConfigobjekt, antingeninputsargumentsvia eller -parametern för dittScriptRunConfigobjekt, när du skickar experimentjobbetNär skriptet anropar vissa metoder –
get_by_name()ellerget_by_id()– till exempel. Namnet som tilldelades datauppsättningen när du registrerade datamängden på arbetsytan är det namn som visas
I dessa scenarier spåras dina data som en utdatauppsättning:
Skicka ett
OutputFileDatasetConfigobjekt via antingen parameternoutputsellerargumentsnär du skickar ett experimentjobb.OutputFileDatasetConfigobjekt kan också spara data mellan pipelinesteg. Mer information finns i Flytta data mellan ML-pipelinestegRegistrera en datauppsättning i skriptet. Namnet som tilldelades till datauppsättningen när du registrerade den på arbetsytan är namnet som visas. I det här kodexemplet
training_dsvisas namnet:training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Överföring av ett underordnat jobb, med en oregistrerad datamängd, i skriptet. Den här insändningen resulterar i en anonym sparad datauppsättning
Spåra datauppsättningar i experimentjobb
För varje Machine Learning-experiment kan du spåra indatauppsättningarna för experimentobjektet Job . Det här kodexemplet använder get_details() metoden för att spåra de indatauppsättningar som används med experimentkörningen:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
Du kan också hitta input_datasets från experiment med Azure Machine Learning-studio.
Den här skärmbilden visar var du hittar indatamängden för ett experiment på Azure Machine Learning-studio. I det här exemplet startar du i fönstret Experiment och öppnar fliken Egenskaper för en specifik körning av experimentet, keras-mnist.

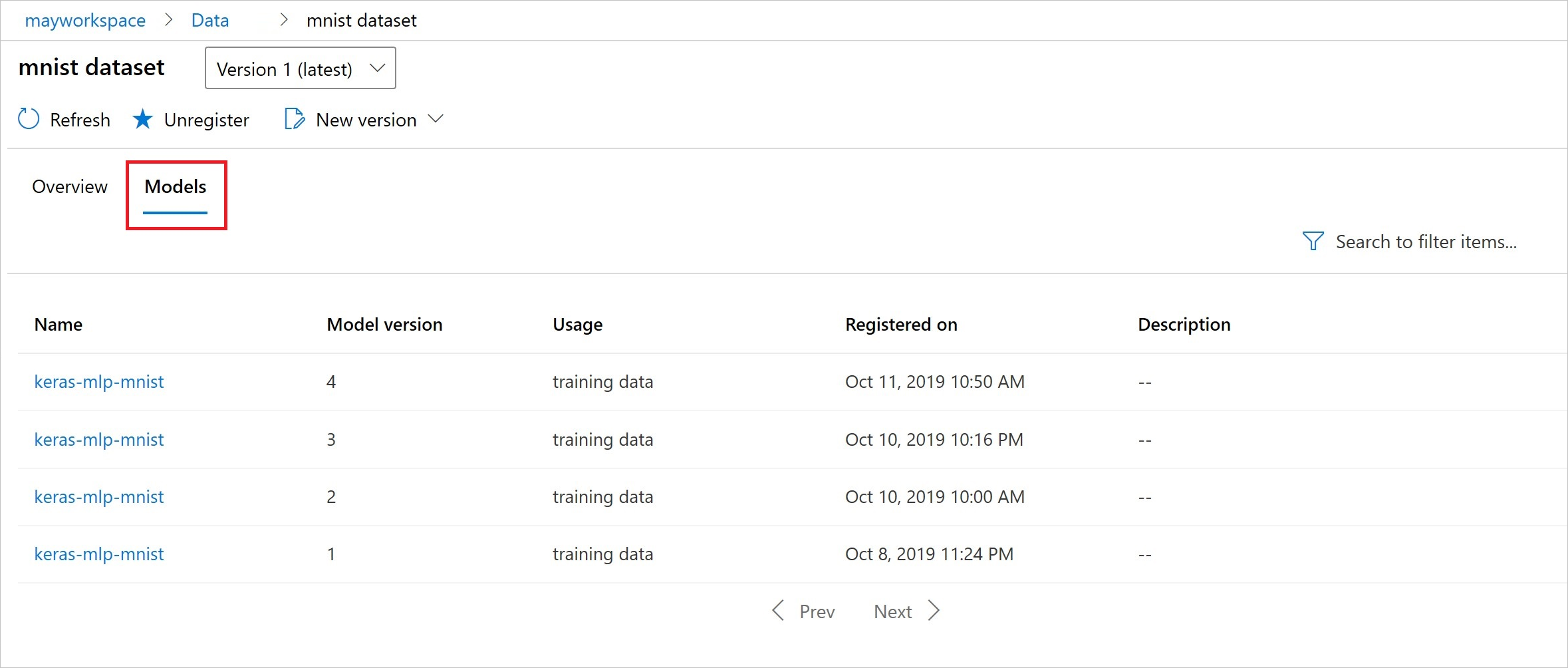
Den här koden registrerar modeller med datauppsättningar:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
Efter registreringen kan du se listan över modeller som registrerats med datamängden med antingen Python eller studio.
Thia-skärmbild är från fönstret Datauppsättningar under Tillgångar. Välj datauppsättningen och välj sedan fliken Modeller för en lista över de modeller som är registrerade med datamängden.