Självstudie: Designer – träna en regressionsmodell utan kod
Träna en linjär regressionsmodell som förutsäger bilpriser med hjälp av Azure Machine Learning-designern. Den här självstudien är del ett i en serie med två delar.
I den här självstudien används Azure Machine Learning-designern. Mer information finns i Vad är Azure Machine Learning Designer?
Kommentar
Designer stöder två typer av komponenter, klassiska fördefinierade komponenter (v1) och anpassade komponenter (v2). Dessa två typer av komponenter är INTE kompatibla.
Klassiska fördefinierade komponenter ger fördefinierade komponenter huvudsakligen för databearbetning och traditionella maskininlärningsuppgifter som regression och klassificering. Den här typen av komponent stöds fortfarande, men inga nya komponenter läggs till.
Med anpassade komponenter kan du omsluta din egen kod som en komponent. Den stöder delning av komponenter mellan arbetsytor och sömlös redigering i Studio-, CLI v2- och SDK v2-gränssnitt.
För nya projekt rekommenderar vi starkt att du använder anpassad komponent, som är kompatibel med AzureML V2 och fortsätter att ta emot nya uppdateringar.
Den här artikeln gäller för klassiska fördefinierade komponenter och är inte kompatibel med CLI v2 och SDK v2.
I del ett av självstudien lär du dig att:
- Skapa en ny pipeline.
- Import data.
- Förbereda data.
- Träna en maskininlärningsmodell.
- Utvärdera en maskininlärningsmodell.
I del två av självstudien distribuerar du din modell som en slutpunkt för slutsatsdragning i realtid för att förutsäga priset på en bil baserat på tekniska specifikationer som du skickar den till.
Kommentar
En färdig version av den här självstudien är tillgänglig som en exempelpipeline.
Du hittar den genom att gå till designern på din arbetsyta. I avsnittet Ny pipeline väljer du Exempel 1 – Regression: Automobile Price Prediction(Basic).
Viktigt!
Om du inte ser grafiska element som nämns i det här dokumentet, till exempel knappar i studio eller designer, kanske du inte har rätt behörighetsnivå för arbetsytan. Kontakta azure-prenumerationsadministratören för att kontrollera att du har beviljats rätt åtkomstnivå. Mer information finns i Hantera användare och roller.
Skapa en ny pipeline
Azure Machine Learning-pipelines organiserar flera steg för maskininlärning och databearbetning i en enda resurs. Med pipelines kan du organisera, hantera och återanvända komplexa arbetsflöden för maskininlärning mellan projekt och användare.
För att skapa en Azure Machine Learning-pipeline behöver du en Azure Machine Learning-arbetsyta. I det här avsnittet får du lära dig hur du skapar båda dessa resurser.
Skapa en ny arbetsyta
Du behöver en Azure Machine Learning-arbetsyta för att använda designern. Arbetsytan är den översta resursen för Azure Machine Learning. Den är en central plats där du kan arbeta med alla artefakter som du skapar i Azure Machine Learning. Anvisningar om hur du skapar en arbetsyta finns i Skapa arbetsyteresurser.
Kommentar
Om din arbetsyta använder ett virtuellt nätverk finns det ytterligare konfigurationssteg som du måste använda för att använda designern. Mer information finns i Använda Azure Machine Learning-studio i ett virtuellt Azure-nätverk
Skapa pipelinen
Kommentar
Designer stöder två typer av komponenter, klassiska fördefinierade komponenter och anpassade komponenter. Dessa två typer av komponenter är inte kompatibla.
Klassiska fördefinierade komponenter tillhandahåller fördefinierade komponenter som främst används för databearbetning och traditionella maskininlärningsuppgifter som regression och klassificering. Den här typen av komponent stöds fortfarande, men inga nya komponenter läggs till.
Med anpassade komponenter kan du ange din egen kod som en komponent. Det finns stöd för delning mellan arbetsytor och sömlös redigering i Studio-, CLI- och SDK-gränssnitt.
Den här artikeln gäller för klassiska fördefinierade komponenter.
Logga in på ml.azure.com och välj den arbetsyta som du vill arbeta med.
Välj Designer –> klassisk fördefinierad
Välj Skapa en ny pipeline med klassiska fördefinierade komponenter.
Klicka på pennikonen bredvid det automatiskt genererade pipelineutkastnamnet och byt namn på den till Förutsägelse av bilpris. Namnet behöver inte vara unikt.

Importera data
Det finns flera exempeldatauppsättningar som ingår i designern som du kan experimentera med. I den här självstudien använder du automobile price data (Raw).
Till vänster om pipelinearbetsytan finns en palett med datauppsättningar och komponenter. Välj Komponent –>Exempeldata.
Välj datamängden Automobile price data (Raw) och dra dem till arbetsytan.

Visualisera datan
Du kan visualisera data för att förstå den datauppsättning som du ska använda.
Högerklicka på prisdata för bilar (rådata) och välj Förhandsgranska data.
Välj de olika kolumnerna i datafönstret för att visa information om var och en.
Varje rad representerar en bil och variablerna som är associerade med varje bil visas som kolumner. Det finns 205 rader och 26 kolumner i den här datamängden.
Förbereda data
Datauppsättningar kräver vanligtvis viss förbearbetning före analys. Du kanske har lagt märke till några saknade värden när du inspekterade datamängden. Dessa saknade värden måste rensas så att modellen kan analysera data korrekt.
Ta bort en kolumn
När du tränar en modell måste du göra något åt de data som saknas. I den här datamängden saknar kolumnen normalized-losses många värden, så du utesluter kolumnen från modellen helt och hållet.
I datauppsättningarna och komponentpaletten till vänster om arbetsytan klickar du på Komponent och söker efter komponenten Välj kolumner i datauppsättning .
Dra komponenten Välj kolumner i datauppsättning till arbetsytan. Släpp komponenten under datamängdskomponenten.
AnslutDatamängd för bilprisdata (Raw) till komponenten Välj kolumner i datauppsättning. Dra från datauppsättningens utdataport, som är den lilla cirkeln längst ned i datauppsättningen på arbetsytan, till indataporten för Välj kolumner i datauppsättning, som är den lilla cirkeln överst i komponenten.
Dricks
Du skapar ett dataflöde via pipelinen när du ansluter utdataporten för en komponent till en indataport för en annan.
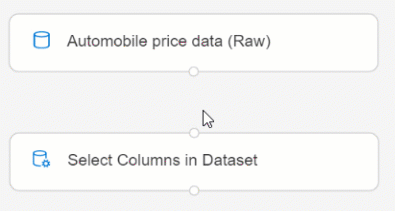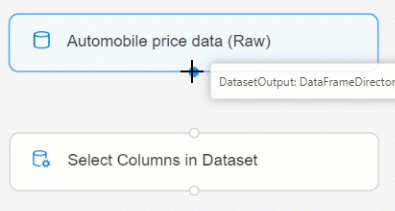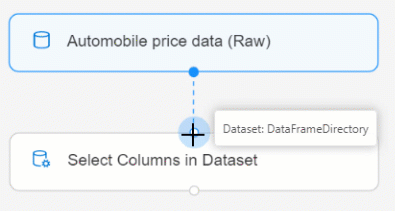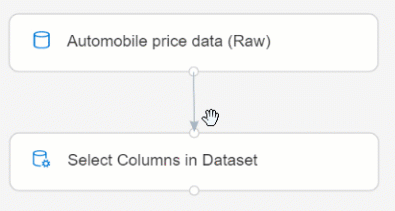
Välj komponenten Välj kolumner i datauppsättning .
Klicka på pilikonen under Inställningar till höger om arbetsytan för att öppna komponentinformationsfönstret. Du kan också dubbelklicka på komponenten Välj kolumner i datauppsättning för att öppna informationsfönstret.
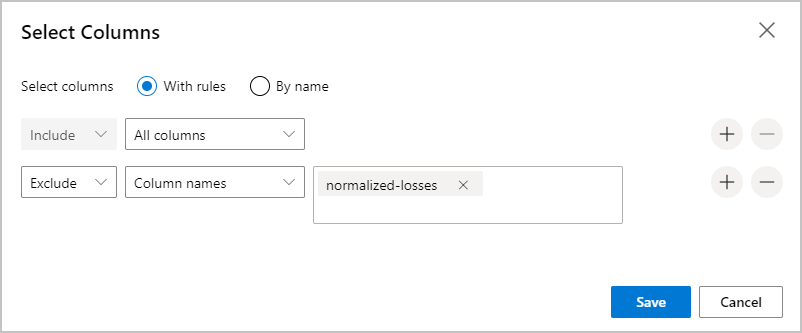
Välj Redigera kolumn till höger om fönstret.
Expandera listrutan Kolumnnamn bredvid Inkludera och välj Alla kolumner.
Välj för + att lägga till en ny regel.
I de nedrullningsbara menyerna väljer du Exkludera och Kolumnnamn.
Ange normalized-losses i textrutan.
I det nedre högra hörnet väljer du Spara för att stänga kolumnväljaren.
I fönstret Select Columns in Dataset component details (Välj kolumner i datauppsättningskomponentens information) expanderar du Nodinformation.
Välj textrutan Kommentar och ange Exkludera normaliserade förluster.
Kommentarer visas i diagrammet som hjälper dig att organisera din pipeline.
Rensa saknade data
Datamängden saknar fortfarande värden när du har tagit bort kolumnen normalized-losses . Du kan ta bort återstående saknade data med hjälp av komponenten Rensa saknade data .
Dricks
Att rensa saknade värden från indata är en förutsättning för att använda de flesta komponenterna i designern.
I datauppsättningarna och komponentpaletten till vänster om arbetsytan klickar du på Komponent och söker efter komponenten Rensa saknade data .
Dra komponenten Rensa saknade data till pipelinearbetsytan. Anslut den till Välj Kolumner i datauppsättningskomponenten.
Välj komponenten Rensa saknade data .
Klicka på pilikonen under Inställningar till höger om arbetsytan för att öppna komponentinformationsfönstret. Du kan också dubbelklicka på komponenten Rensa saknade data för att öppna informationsfönstret.
Välj Redigera kolumn till höger om fönstret.
I fönstret Kolumner som ska rensas som visas expanderar du den nedrullningsbara menyn bredvid Inkludera. Markera, Alla kolumner
Välj Spara
I fönstret Information om komponenten Rensa saknade data går du till Rensningsläge och väljer Ta bort hela raden.
I fönstret Information om komponenten Rensa saknade data expanderar du Nodinformation.
Markera textrutan Kommentar och ange Ta bort saknade värderader.
Din pipeline bör nu se ut ungefär så här:
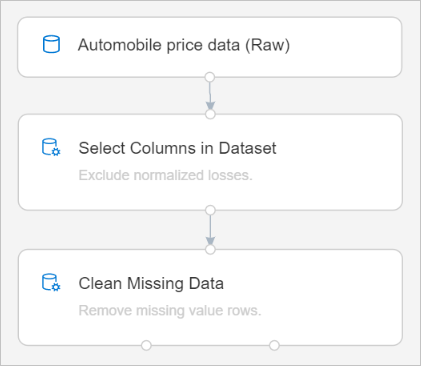
Träna en maskininlärningsmodell
Nu när du har komponenterna på plats för att bearbeta data kan du konfigurera träningskomponenterna.
Eftersom du vill förutsäga priset, vilket är ett tal, kan du använda en regressionsalgoritm. I det här exemplet använder du en linjär regressionsmodell.
Dela upp data
Att dela upp data är en vanlig uppgift inom maskininlärning. Du delar upp dina data i två separata datauppsättningar. En datauppsättning tränar modellen och den andra testar hur bra modellen presterade.
I datauppsättningarna och komponentpaletten till vänster om arbetsytan klickar du på Komponent och söker efter komponenten Dela data .
Dra komponenten Dela data till pipelinearbetsytan.
Anslut den vänstra porten i Rensa komponenten Saknade data till komponenten Dela data.
Viktigt!
Kontrollera att den vänstra utdataporten för Rensa saknade data ansluter till Delade data. Den vänstra porten innehåller rensade data. Rätt port innehåller borttagna data.
Välj komponenten Dela data .
Klicka på pilikonen under Inställningar till höger om arbetsytan för att öppna komponentinformationsfönstret. Du kan också dubbelklicka på komponenten Dela data för att öppna informationsfönstret.
I fönstret Dela datainformation anger du Bråk av rader i den första utdatauppsättningen till 0,7.
Det här alternativet delar upp 70 procent av data för att träna modellen och 30 procent för att testa den. Datamängden på 70 procent kommer att vara tillgänglig via den vänstra utdataporten. Återstående data är tillgängliga via rätt utdataport.
I fönstret Dela datainformation expanderar du Nodinformation.
Välj textrutan Kommentar och ange Dela upp datamängden i träningsuppsättningen (0.7) och testuppsättningen (0.3)..
Träna modellen
Träna modellen genom att ge den en datamängd som inkluderar priset. Algoritmen konstruerar en modell som förklarar relationen mellan funktionerna och priset enligt träningsdata.
I datauppsättningarna och komponentpaletten till vänster om arbetsytan klickar du på Komponent och söker efter komponenten Linjär regression .
Dra komponenten Linjär regression till pipelinearbetsytan.
I datauppsättningarna och komponentpaletten till vänster om arbetsytan klickar du på Komponent och söker efter komponenten Träna modell .
Dra komponenten Träna modell till pipelinearbetsytan.
Anslut utdata från Linjär regressionskomponent till vänster indata för train model-komponenten.
Anslut träningsdatautdata (vänster port) för Dela upp datakomponenten till rätt indata för train model-komponenten.
Viktigt!
Kontrollera att den vänstra utdataporten för Delade data ansluter till träningsmodellen. Den vänstra porten innehåller träningsuppsättningen. Rätt port innehåller testuppsättningen.
Välj komponenten Träna modell .
Klicka på pilikonen under Inställningar till höger om arbetsytan för att öppna komponentinformationsfönstret. Du kan också dubbelklicka på komponenten Träna modell för att öppna informationsfönstret.
Välj Redigera kolumn till höger om fönstret.
I kolumnfönstret Etikett som visas expanderar du den nedrullningsbara menyn och väljer Kolumnnamn.
I textrutan anger du pris för att ange det värde som din modell ska förutsäga.
Viktigt!
Kontrollera att du anger kolumnnamnet exakt. Använd inte kapitalisera pris.
Din pipeline bör se ut så här:
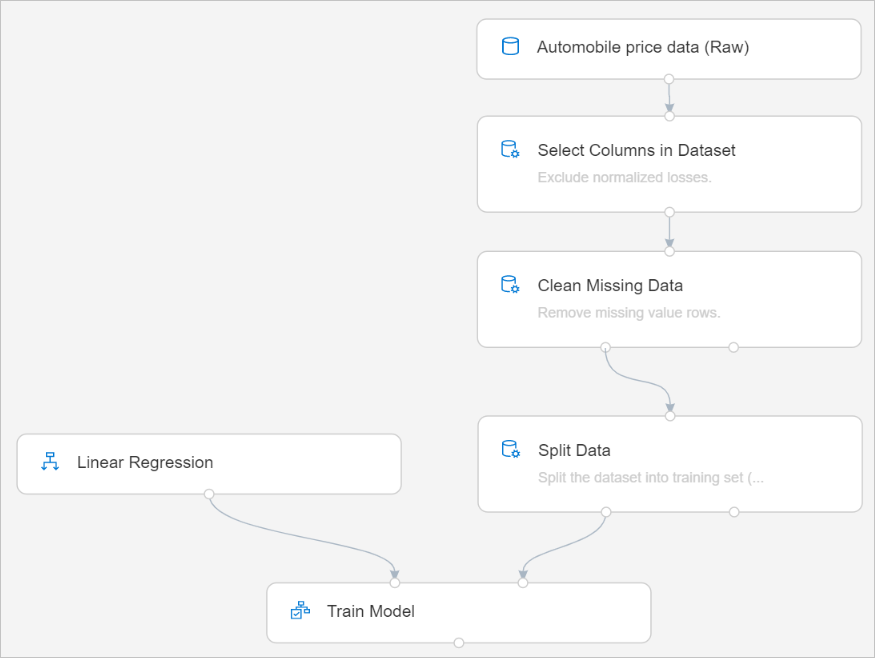
Lägg till komponenten Poängsätta modell
När du har tränat din modell med 70 procent av data kan du använda den för att poängsätta de övriga 30 procenten för att se hur bra modellen fungerar.
I datauppsättningarna och komponentpaletten till vänster om arbetsytan klickar du på Komponent och söker efter komponenten Poängsätta modell .
Dra komponenten Poängsätta modell till pipelinearbetsytan.
Anslut utdata från Träna modellkomponenten till den vänstra indataporten för Poängsätta modell. Anslut testdatautdata (höger port) för Dela upp datakomponenten till rätt indataport för poängmodell.
Lägg till komponenten Utvärdera modell
Använd komponenten Utvärdera modell för att utvärdera hur bra din modell har gjort testdatamängden.
I datauppsättningarna och komponentpaletten till vänster om arbetsytan klickar du på Komponent och söker efter komponenten Utvärdera modell .
Dra komponenten Utvärdera modell till pipelinearbetsytan.
Anslut utdata från Poängsätta modellkomponenten till vänster indata för Utvärdera modell.
Den slutliga pipelinen bör se ut ungefär så här:
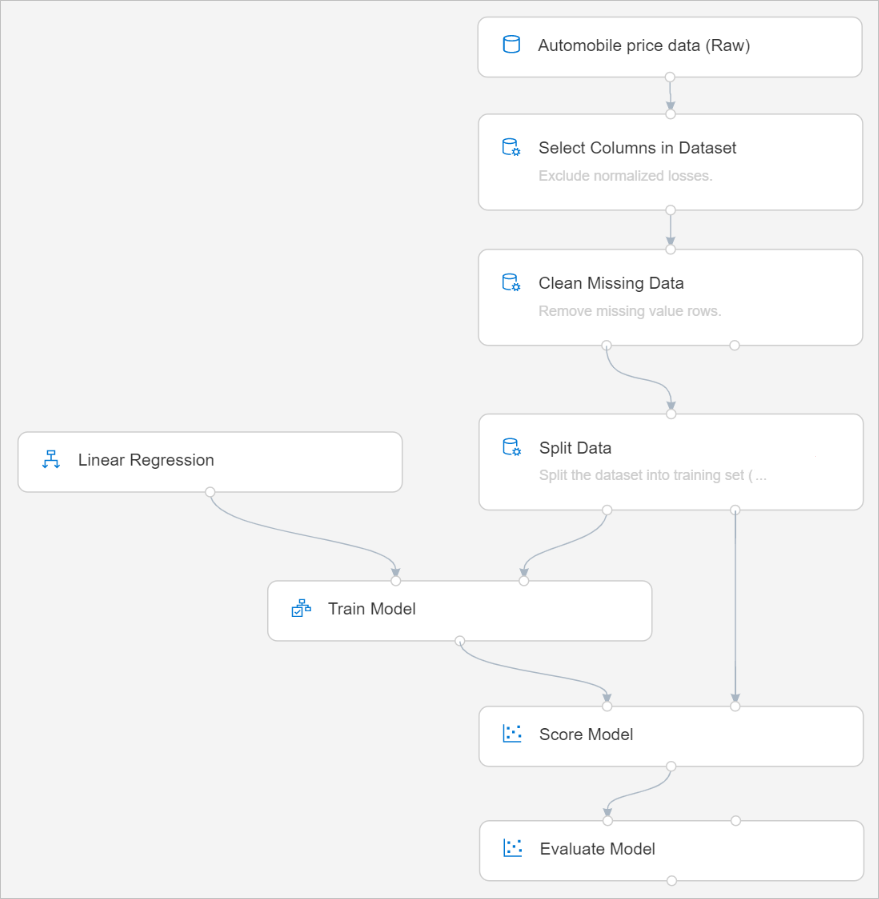
Skicka pipeline
Välj Konfigurera och skicka i det högra övre hörnet för att skicka pipelinen.

Sedan visas en steg-för-steg-guide, följ guiden för att skicka pipelinejobbet.


I steget Grundläggande kan du konfigurera experimentet, jobbets visningsnamn, jobbbeskrivning osv.
I steget Indata och utdata kan du tilldela värdet till de indata/utdata som höjs upp till pipelinenivå. I det här exemplet är det tomt eftersom vi inte har befordrat några indata/utdata till pipelinenivå.
I Körningsinställningar kan du konfigurera standarddatalager och standardberäkning till pipelinen. Det är standarddatalager/beräkning för alla komponenter i pipelinen. Men om du anger en annan beräkning eller ett annat datalager för en komponent uttryckligen respekterar systemet inställningen för komponentnivå. Annars används standardinställningen.
Steget Granska + skicka är det sista steget för att granska alla inställningar innan du skickar. Guiden kommer ihåg den senaste konfigurationen om du skickar pipelinen.
När du har skickat pipelinejobbet visas ett meddelande längst upp med en länk till jobbinformationen. Du kan välja den här länken för att granska jobbinformationen.

Visa poängsatta etiketter
På sidan med jobbinformation kan du kontrollera status, resultat och loggar för pipelinejobbet.
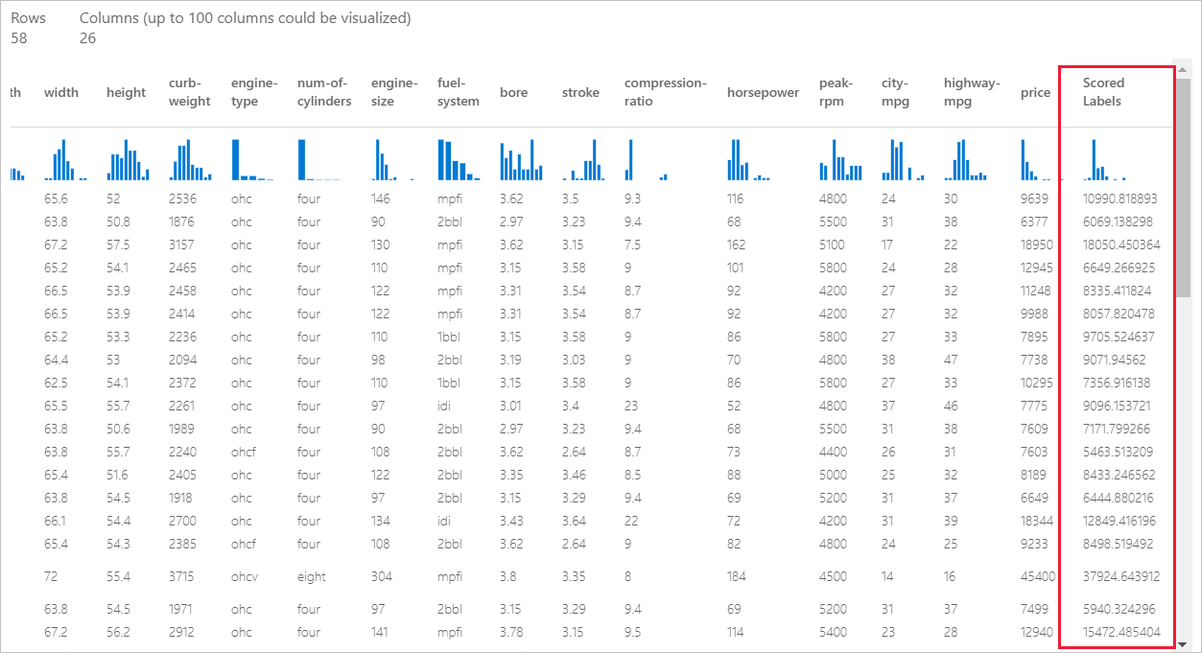
När jobbet har slutförts kan du visa resultatet av pipelinejobbet. Titta först på förutsägelserna som genereras av regressionsmodellen.
Högerklicka på komponenten Poängsätta modell och välj Förhandsgranska data>Poängsatt datamängd för att visa dess utdata.
Här kan du se de förväntade priserna och de faktiska priserna från testdata.
Utvärdera modeller
Använd Utvärdera modell för att se hur väl den tränade modellen har utförts på testdatauppsättningen.
- Högerklicka på komponenten Utvärdera modell och välj Förhandsgranska dataUtvärderingsresultat> för att visa dess utdata.
Följande statistik visas för din modell:
- Genomsnittligt absolut fel (MAE): Medelvärdet av absoluta fel. Ett fel är skillnaden mellan det förutsagda värdet och det faktiska värdet.
- Medelkvadratfel (RMSE): Kvadratroten av genomsnittet av kvadratfel i förutsägelser som görs mot testdatauppsättningen.
- Relativa absoluta fel: Medelvärdet av absoluta fel i förhållande till den absoluta skillnaden mellan faktiska värden och medelvärdet av alla faktiska värden.
- Relativa kvadratfel: Medelvärdet av kvadratfel i förhållande till kvadratskillnaden mellan faktiska värden och medelvärdet av alla faktiska värden.
- Bestämningskoefficient: Det här statistiska måttet kallas även för R-kvadratvärdet och anger hur väl en modell passar data.
För all felstatistik gäller att mindre är bättre. Ett mindre värde anger att förutsägelserna ligger närmare de faktiska värdena. För bestämningskoefficienten är det närmare dess värde en (1.0), desto bättre förutsägelser.
Rensa resurser
Hoppa över det här avsnittet om du vill fortsätta med del 2 i självstudien och distribuera modeller.
Viktigt!
Du kan använda de resurser som du skapade som förutsättningar för andra Azure Machine Learning-självstudier och instruktionsartiklar.
Ta bort allt
Om du inte planerar att använda något som du har skapat tar du bort hela resursgruppen så att du inte debiteras några avgifter.
I Azure-portalen väljer du Resursgrupper till vänster i fönstret.

I listan väljer du den resursgrupp som du skapade.
Välj Ta bort resursgrupp.
Om du tar bort resursgruppen tas även alla resurser som du skapade i designern bort.
Ta bort enskilda tillgångar
I designern där du skapade experimentet tar du bort enskilda tillgångar genom att välja dem och sedan välja knappen Ta bort .
Beräkningsmålet som du skapade här skalar automatiskt till noll noder när det inte används. Den här åtgärden vidtas för att minimera avgifterna. Om du vill ta bort beräkningsmålet gör du följande:

Du kan avregistrera datauppsättningar från din arbetsyta genom att välja varje datauppsättning och välja Avregistrera.

Om du vill ta bort en datauppsättning går du till lagringskontot med hjälp av Azure-portalen eller Azure Storage Explorer och tar bort dessa tillgångar manuellt.
Nästa steg
I del två får du lära dig hur du distribuerar din modell som en realtidsslutpunkt.