Power Query anslutningsappar (förhandsversion – tillbakadragen)
Viktigt
Power Query anslutningsappsstöd introducerades som en gated offentlig förhandsversion under Kompletterande användningsvillkor för Microsoft Azure Previews, men har nu upphört. Om du har en söklösning som använder en Power Query-anslutning kan du migrera till en alternativ lösning.
Migrera senast den 28 november 2022
Förhandsversionen av Power Query-anslutningsappen tillkännagavs i maj 2021 och kommer inte att gå vidare till allmän tillgänglighet. Följande migreringsvägledning är tillgänglig för Snowflake och PostgreSQL. Om du använder en annan anslutningsapp och behöver migreringsinstruktioner kan du använda e-postkontaktinformationen i förhandsversionen för att begära hjälp eller öppna ett ärende med Azure Support.
Förutsättningar
- Ett Azure Storage-konto. Om du inte har något skapar du ett lagringskonto.
- En Azure Data Factory. Om du inte har någon skapar du en Data Factory. Se Prissättning för Data Factory Pipelines före implementeringen för att förstå de associerade kostnaderna. Kontrollera även Priser för Data Factory via exempel.
Migrera en Snowflake-datapipeline
Det här avsnittet beskriver hur du kopierar data från en Snowflake-databas till ett Azure Cognitive Search index. Det finns ingen process för direkt indexering från Snowflake till Azure Cognitive Search, så det här avsnittet innehåller en mellanlagringsfas som kopierar databasinnehåll till en Azure Storage-blobcontainer. Sedan indexeras du från den mellanlagringscontainern med hjälp av en Data Factory-pipeline.
Steg 1: Hämta snowflake-databasinformation
Gå till Snowflake och logga in på ditt Snowflake-konto. Ett Snowflake-konto ser ut som https://< account_name.snowflakecomputing.com>.
När du har loggat in samlar du in följande information från det vänstra fönstret. Du använder den här informationen i nästa steg:
- Från Data väljer du Databaser och kopierar namnet på databaskällan.
- Från Admin väljer du Användare & Roller och kopierar namnet på användaren. Kontrollera att användaren har läsbehörigheter.
- Från Admin väljer du Konton och kopierar kontots LOCATOR-värde.
- Från Snowflake-URL:en, som liknar
https://app.snowflake.com/<region_name>/xy12345/organization). kopiera regionnamnet. Ihttps://app.snowflake.com/south-central-us.azure/xy12345/organizationärsouth-central-us.azuretill exempel regionnamnet . - Från Admin väljer du Lager och kopierar namnet på det lager som är associerat med databasen som du ska använda som källa.
Steg 2: Konfigurera länkad Snowflake-tjänst
Logga in på Azure Data Factory Studio med ditt Azure-konto.
Välj din datafabrik och välj sedan Fortsätt.
Välj ikonen Hantera på den vänstra menyn.
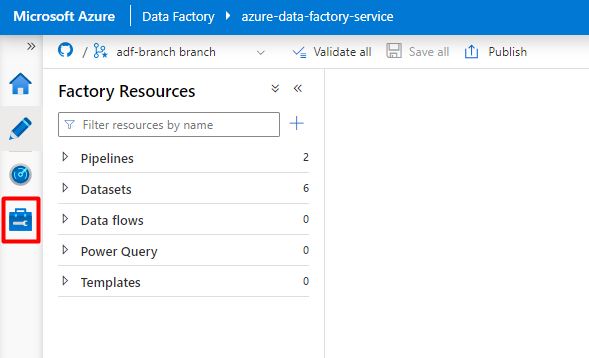
Under Länkade tjänster väljer du Ny.

I den högra rutan i datalagersökningen anger du "snowflake". Välj Snowflake-panelen och välj Fortsätt.

Fyll i formuläret Ny länkad tjänst med de data som du samlade in i föregående steg. Kontonamnet innehåller ett LOCATOR-värde och regionen (till exempel: ).
xy56789south-central-us.azure
När formuläret har slutförts väljer du Testa anslutning.
Om testet lyckas väljer du Skapa.
Steg 3: Konfigurera Snowflake Dataset
Välj ikonen Författare på den vänstra menyn.
Välj Datauppsättningar och välj sedan menyn Åtgärder för datauppsättningar (
...).
Välj Ny datauppsättning.
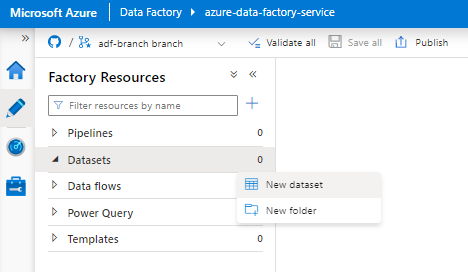
I den högra rutan i datalagersökningen anger du "snowflake". Välj Snowflake-panelen och välj Fortsätt.
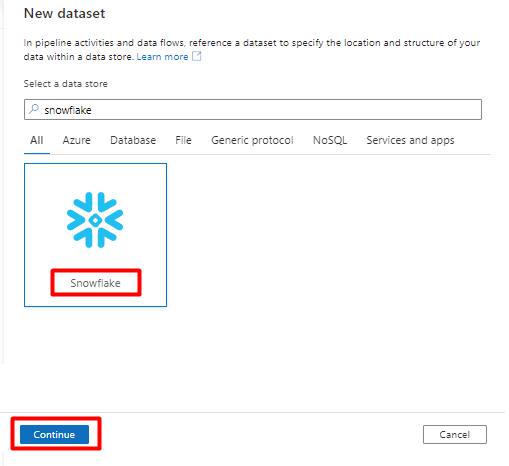
I Ange egenskaper:
- Välj den länkade tjänst som du skapade i steg 2.
- Välj den tabell som du vill importera och välj sedan OK.
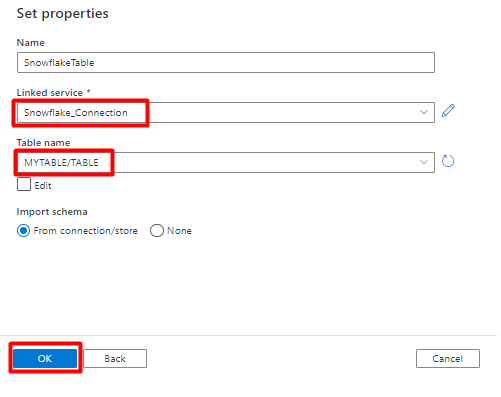
Välj Spara.
Steg 4: Skapa ett nytt index i Azure Cognitive Search
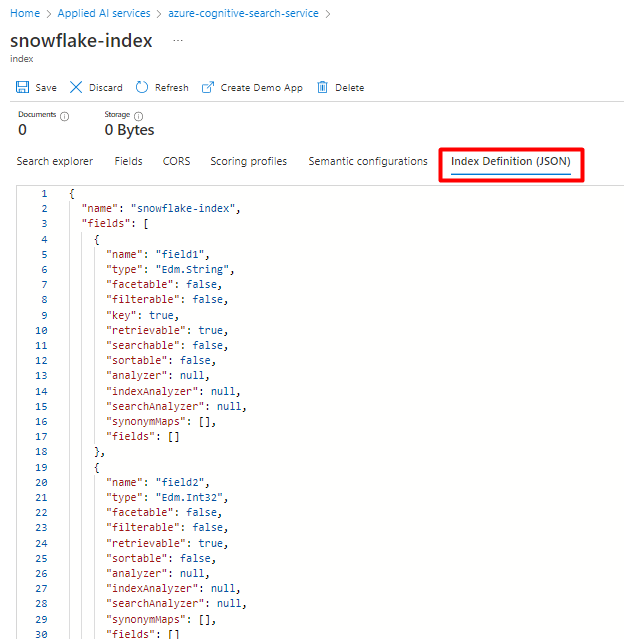
Skapa ett nytt index i din Azure Cognitive Search-tjänst med samma schema som det du för närvarande har konfigurerat för dina Snowflake-data.
Du kan återanvända det index som du använder för Snowflake Power Connector. I Azure Portal letar du upp indexet och väljer sedan Indexdefinition (JSON). Välj definitionen och kopiera den till brödtexten i din nya indexbegäran.
Steg 5: Konfigurera Azure Cognitive Search länkad tjänst
Välj Ikonen Hantera på den vänstra menyn.
Under Länkade tjänster väljer du Ny.
I den högra rutan i datalagersökningen anger du "sök". Välj Azure Search-panelen och välj Fortsätt.

Fyll i de nya länkade tjänstvärdena :
- Välj den Azure-prenumeration där din Azure Cognitive Search tjänst finns.
- Välj den Azure Cognitive Search tjänst som har indexeraren för Power Query-anslutningsappen.
- Välj Skapa.

Steg 6: Konfigurera Azure Cognitive Search datauppsättning
På den vänstra menyn väljer du Ikonen Författare .
Välj Datauppsättningar och välj sedan menyn Åtgärder för datauppsättningar (
...).
Välj Ny datauppsättning.
I den högra rutan i datalagersökningen anger du "sök". Välj Azure Search-panelen och välj Fortsätt.
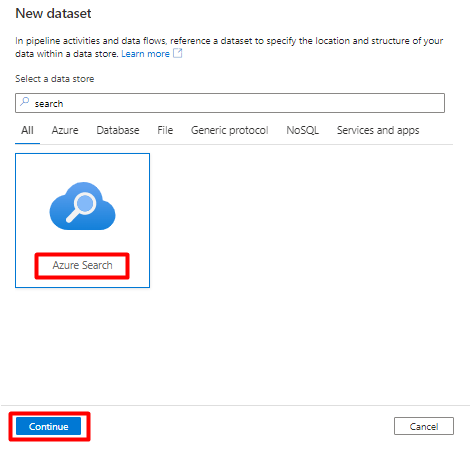
I Ange egenskaper:
Välj Spara.
Steg 7: Konfigurera Azure Blob Storage länkad tjänst
Välj Ikonen Hantera på den vänstra menyn.
Under Länkade tjänster väljer du Ny.
I den högra rutan i datalagringssökningen anger du "lagring". Välj panelen Azure Blob Storage och välj Fortsätt.
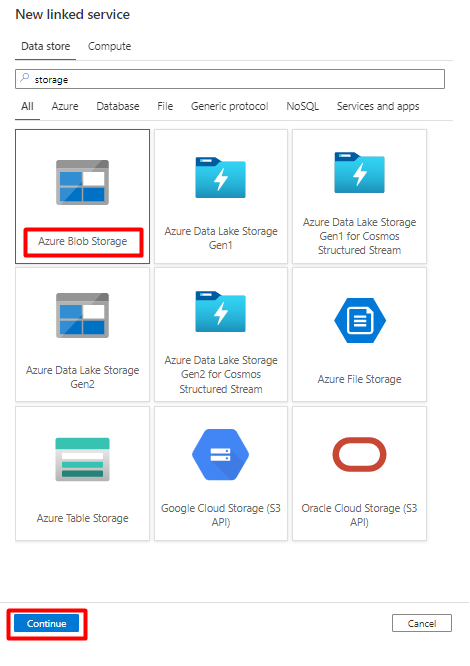
Fyll i de nya länkade tjänstvärdena :
Välj Autentiseringstyp: SAS-URI. Endast den här autentiseringstypen kan användas för att importera data från Snowflake till Azure Blob Storage.
Generera en SAS-URL för lagringskontot som du ska använda för mellanlagring. Klistra in BLOB SAS-URL:en i FÄLTET SAS-URL.
Välj Skapa.

Steg 8: Konfigurera lagringsdatauppsättning
På den vänstra menyn väljer du Ikonen Författare .
Välj Datauppsättningar och välj sedan menyn Åtgärder för datauppsättningar (
...).
Välj Ny datauppsättning.
I den högra rutan i datalagringssökningen anger du "lagring". Välj panelen Azure Blob Storage och välj Fortsätt.

Välj Format för avgränsadtext och välj Fortsätt.
I Ange egenskaper:
Under Länkad tjänst väljer du den länkade tjänst som skapades i steg 7.
Under Filsökväg väljer du den container som ska vara mottagare för mellanlagringsprocessen och väljer OK.

I Radgränsare väljer du Radmatning (\n).
Markera första raden som en rubrikruta .
Välj Spara.

Steg 9: Konfigurera pipeline
På den vänstra menyn väljer du Ikonen Författare .
Välj Pipelines och välj sedan menyn Pipelines Actions ellipses (
...).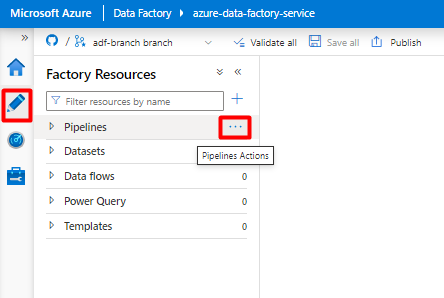
Välj Ny pipeline.
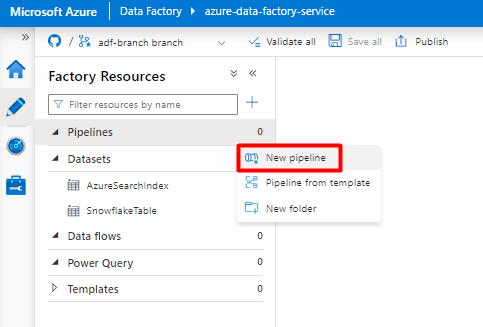
Skapa och konfigurera Data Factory-aktiviteter som kopierar från Snowflake till Azure Storage-containern:
Expandera Avsnittet Flytta & transformering och dra och släpp aktiviteten Kopiera data till den tomma pipelineredigerarens arbetsyta.
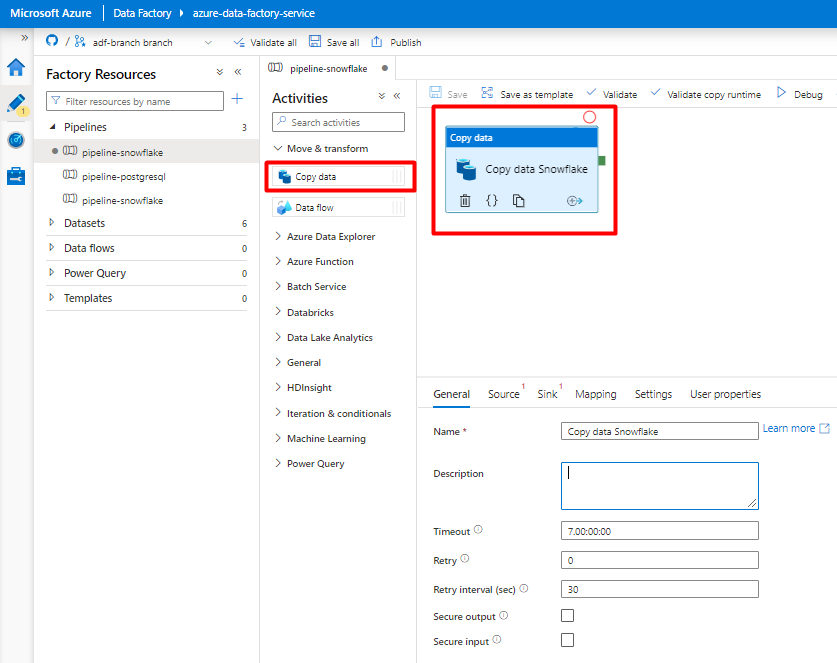
Öppna fliken Allmänt . Acceptera standardvärdena om du inte behöver anpassa körningen.
På fliken Källa väljer du tabellen Snowflake. Lämna de återstående alternativen med standardvärdena.

På fliken Mottagare :
Välj Datauppsättningen Storage DelimitedText som skapades i steg 8.
I Filnamnstillägg lägger du till .csv.
Lämna de återstående alternativen med standardvärdena.

Välj Spara.
Konfigurera de aktiviteter som kopierar från Azure Storage Blob till ett sökindex:
Expandera Avsnittet Flytta & transformering och dra och släpp aktiviteten Kopiera data till den tomma pipelineredigerarens arbetsyta.
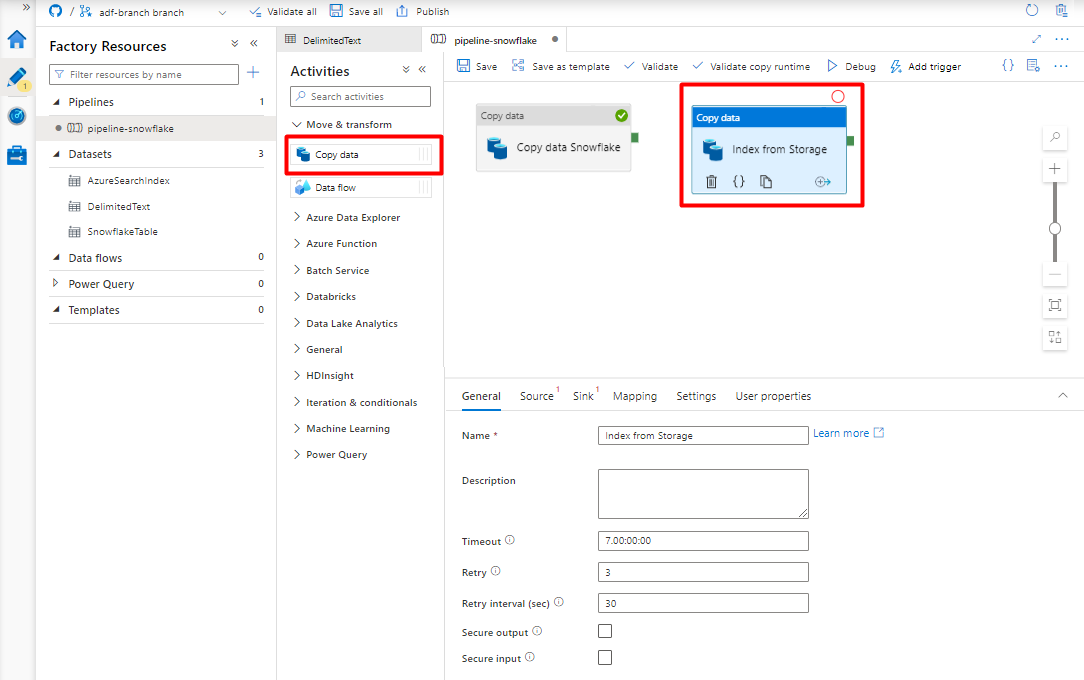
På fliken Allmänt accepterar du standardvärdena, såvida du inte behöver anpassa körningen.
På fliken Källa :
- Välj Datauppsättningen Storage DelimitedText som skapades i steg 8.
- I filsökvägstypen väljer du Sökväg till jokerteckenfil.
- Lämna alla återstående fält med standardvärden.
På fliken Mottagare väljer du ditt Azure Cognitive Search index. Lämna de återstående alternativen med standardvärdena.
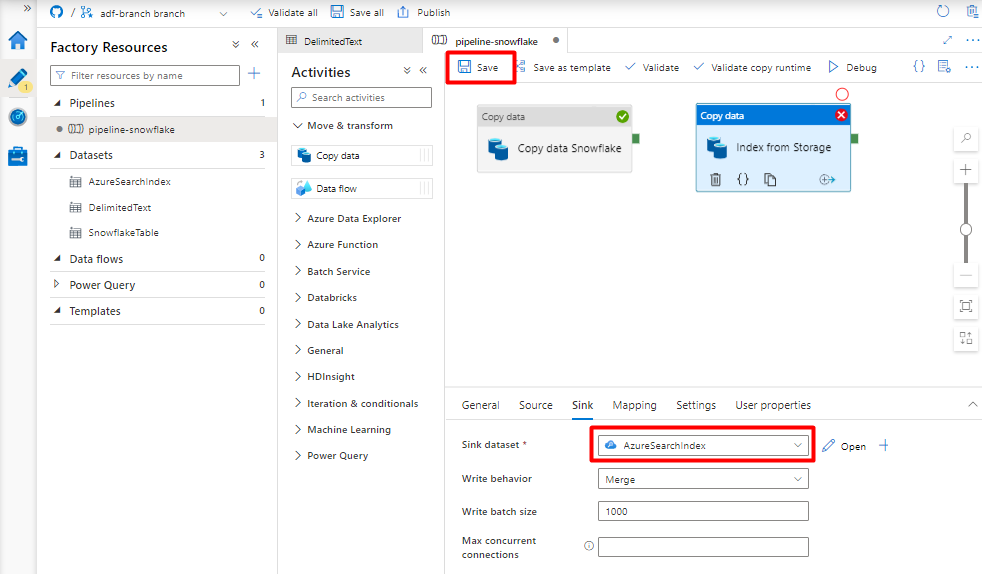
Välj Spara.
Steg 10: Konfigurera aktivitetsordning
I redigeraren pipelinearbetsyta väljer du den lilla gröna rutan i kanten av pipelineaktivitetspanelen. Dra den till aktiviteten "Index från lagringskontot för att Azure Cognitive Search" för att ange körningsordningen.
Välj Spara.

Steg 11: Lägg till en pipeline-utlösare
Välj Lägg till utlösare för att schemalägga pipelinekörningen och välj Ny/Redigera.
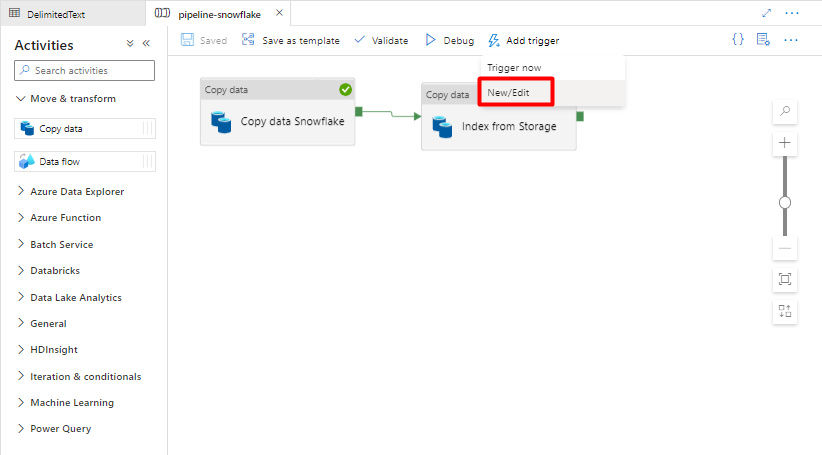
I listrutan Välj utlösare väljer du Ny.

Granska utlösaralternativen för att köra pipelinen och välj OK.
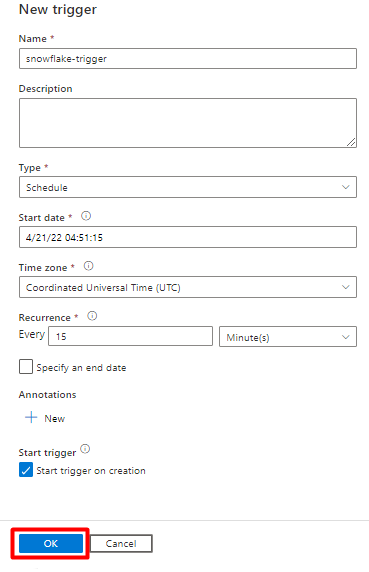
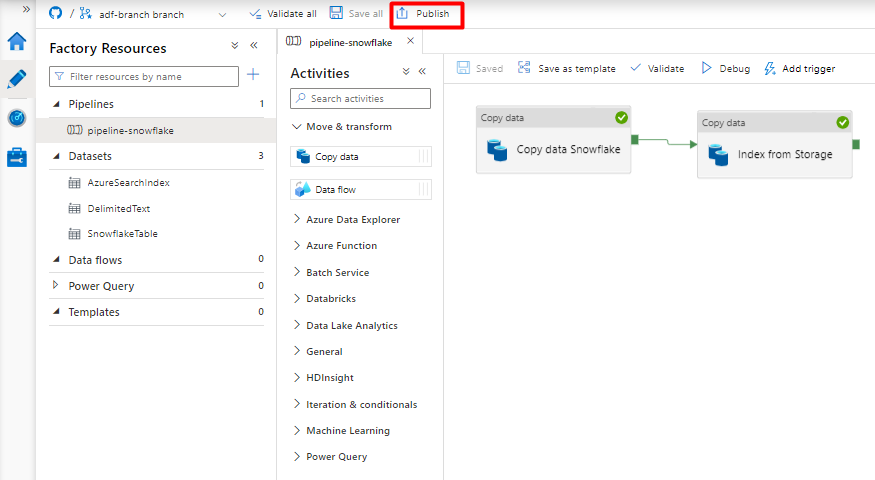
Välj Spara.
Välj Publicera.
Migrera en PostgreSQL-datapipeline
I det här avsnittet beskrivs hur du kopierar data från en PostgreSQL-databas till ett Azure Cognitive Search index. Det finns ingen process för direkt indexering från PostgreSQL till Azure Cognitive Search, så det här avsnittet innehåller en mellanlagringsfas som kopierar databasinnehåll till en Azure Storage-blobcontainer. Sedan indexeras du från den mellanlagringscontainern med hjälp av en Data Factory-pipeline.
Steg 1: Konfigurera länkad PostgreSQL-tjänst
Logga in på Azure Data Factory Studio med ditt Azure-konto.
Välj din datafabrik och välj Fortsätt.
Välj ikonen Hantera på den vänstra menyn.
Under Länkade tjänster väljer du Ny.
I den högra rutan i datalagersökningen anger du "postgresql". Välj den PostgreSQL-panel som representerar var din PostgreSQL-databas finns (Azure eller något annat) och välj Fortsätt. I det här exemplet finns PostgreSQL-databasen i Azure.

Fyll i de nya länkade tjänstvärdena :
I Metoden Kontoval väljer du Ange manuellt.
Från sidan Azure Database for PostgreSQL Översikt i Azure Portal klistrar du in följande värden i respektive fält:
- Lägg till servernamn i Fullständigt kvalificerat domännamn.
- Lägg till Admin användarnamn i Användarnamn.
- Lägg till databas i databasnamn.
- Ange lösenordet för Admin användarnamn till Användarnamn.
- Välj Skapa.

Steg 2: Konfigurera PostgreSQL-datauppsättning
I den vänstra menyn väljer du Ikonen Författare .
Välj Datauppsättningar och välj sedan ellipsmenyn Åtgärder för datauppsättningar (
...).
Välj Ny datauppsättning.
I den högra rutan i datalagersökningen anger du "postgresql". Välj Panelen Azure PostgreSQL . Välj Fortsätt.
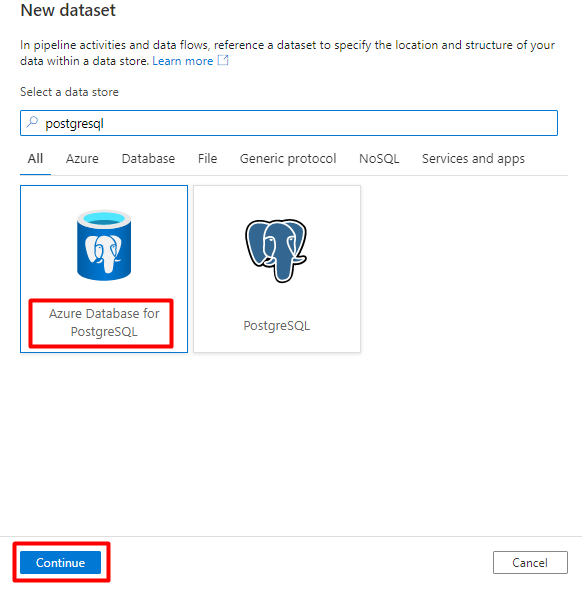
Fyll i värdena för Ange egenskaper :
Välj den länkade PostgreSQL-tjänst som skapades i steg 1.
Välj den tabell som du vill importera/indexera.
Välj OK.
Välj Spara.
Steg 3: Skapa ett nytt index i Azure Cognitive Search
Skapa ett nytt index i din Azure Cognitive Search-tjänst med samma schema som det som används för dina PostgreSQL-data.
Du kan återanvända det index som du använder för PostgreSQL Power Connector. Leta upp indexet i Azure Portal och välj sedan Indexdefinition (JSON). Välj definitionen och kopiera den till brödtexten i din nya indexbegäran.

Steg 4: Konfigurera Azure Cognitive Search länkad tjänst
På den vänstra menyn väljer du ikonen Hantera .
Under Länkade tjänster väljer du Nytt.
I den högra rutan i datalagersökningen anger du "search". Välj Azure Search-panelen och välj Fortsätt.
Fyll i värdena för Ny länkad tjänst :
- Välj den Azure-prenumeration där din Azure Cognitive Search-tjänst finns.
- Välj den Azure Cognitive Search-tjänst som har indexeraren för Power Query-anslutningsappen.
- Välj Skapa.
Steg 5: Konfigurera Azure Cognitive Search datauppsättning
I den vänstra menyn väljer du Ikonen Författare .
Välj Datauppsättningar och välj sedan ellipsmenyn Åtgärder för datauppsättningar (
...).
Välj Ny datauppsättning.
I den högra rutan i datalagersökningen anger du "search". Välj Azure Search-panelen och välj Fortsätt.
I Ange egenskaper:
Välj Spara.

Steg 6: Konfigurera Azure Blob Storage länkad tjänst
På den vänstra menyn väljer du Hantera-ikonen .
Under Länkade tjänster väljer du Nytt.
I den högra rutan i datalagersökningen anger du "lagring". Välj panelen Azure Blob Storage och välj Fortsätt.
Fyll i värdena för Ny länkad tjänst :
Välj Autentiseringstyp: SAS-URI. Endast den här metoden kan användas för att importera data från PostgreSQL till Azure Blob Storage.
Generera en SAS-URL för lagringskontot som du ska använda för mellanlagring och kopiera blob-SAS-URL:en till fältet SAS-URL.
Välj Skapa.

Steg 7: Konfigurera lagringsdatauppsättning
I den vänstra menyn väljer du Ikonen Författare .
Välj Datauppsättningar och välj sedan ellipsmenyn Åtgärder för datauppsättningar (
...).
Välj Ny datauppsättning.
I den högra rutan i datalagersökningen anger du "lagring". Välj panelen Azure Blob Storage och välj Fortsätt.
Välj AvgränsatTextformat och välj Fortsätt.
I Radgränsare väljer du Radmatning (\n).
Markera första raden som en rubrikruta .
Välj Spara.

Steg 8: Konfigurera pipeline
I den vänstra menyn väljer du Ikonen Författare .
Välj Pipelines och sedan ellipsmenyn Pipelineåtgärder (
...).
Välj Ny pipeline.
Skapa och konfigurera Data Factory-aktiviteter som kopierar från PostgreSQL till Azure Storage-containern.
Expandera avsnittet Flytta & transformering och dra och släpp aktiviteten Kopiera data till den tomma arbetsytan för pipelineredigeraren.

Öppna fliken Allmänt , acceptera standardvärdena, såvida du inte behöver anpassa körningen.
På fliken Källa väljer du postgreSQL-tabellen. Låt de återstående alternativen vara kvar med standardvärdena.

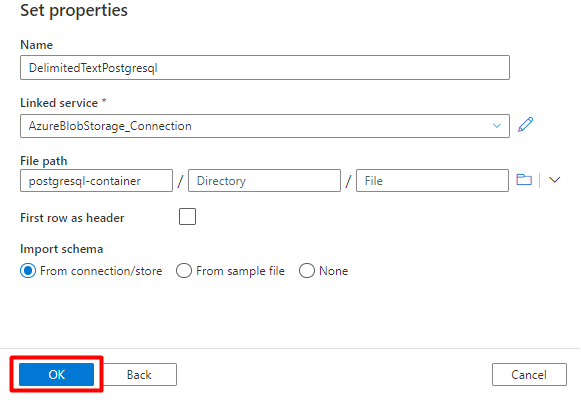
På fliken Mottagare :
Välj datauppsättningen Storage DelimitedText PostgreSQL som konfigurerades i steg 7.
I Filnamnstillägg lägger du till .csv
Låt de återstående alternativen vara kvar med standardvärdena.
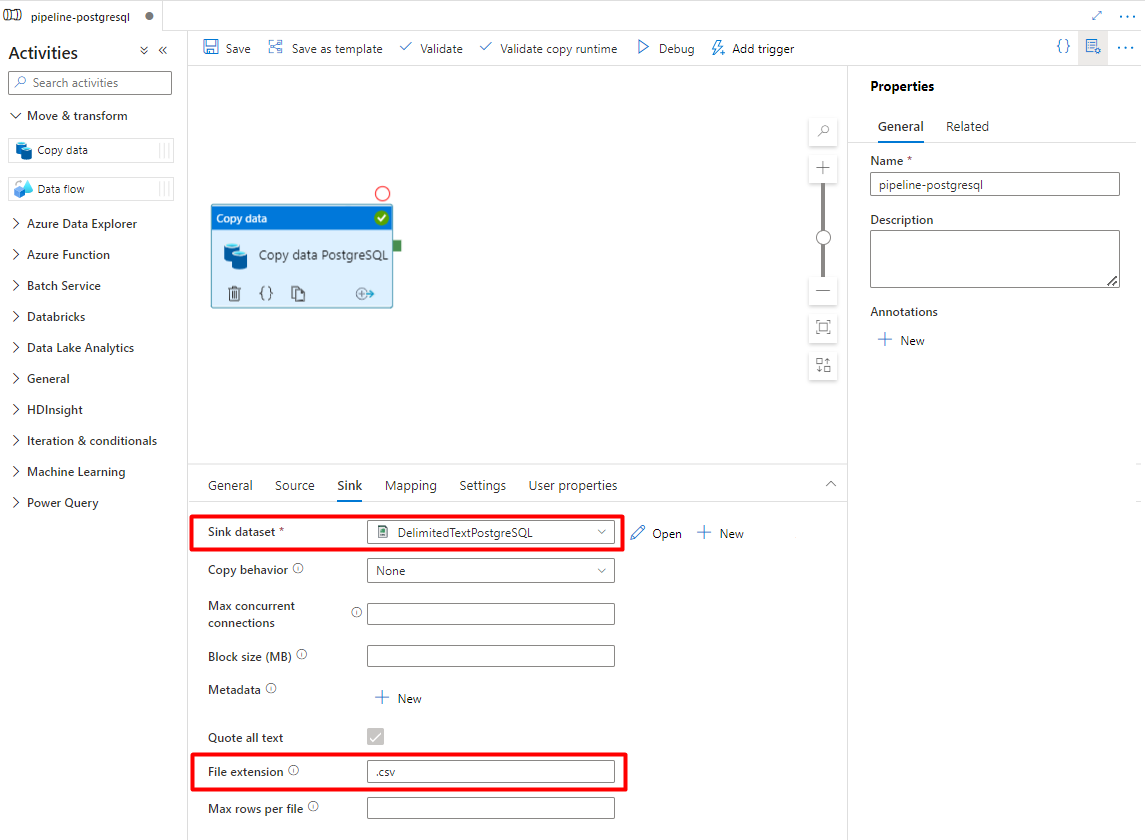
Välj Spara.
Konfigurera aktiviteterna som kopierar från Azure Storage till ett sökindex:
Expandera avsnittet Flytta & transformering och dra och släpp aktiviteten Kopiera data till den tomma arbetsytan för pipelineredigeraren.

På fliken Allmänt lämnar du standardvärdena, såvida du inte behöver anpassa körningen.
På fliken Källa :
- Välj lagringskällans datauppsättning som konfigurerades i steg 7.
- I fältet Filsökvägstyp väljer du Sökväg till jokerteckenfil.
- Lämna standardvärdena för alla återstående fält.
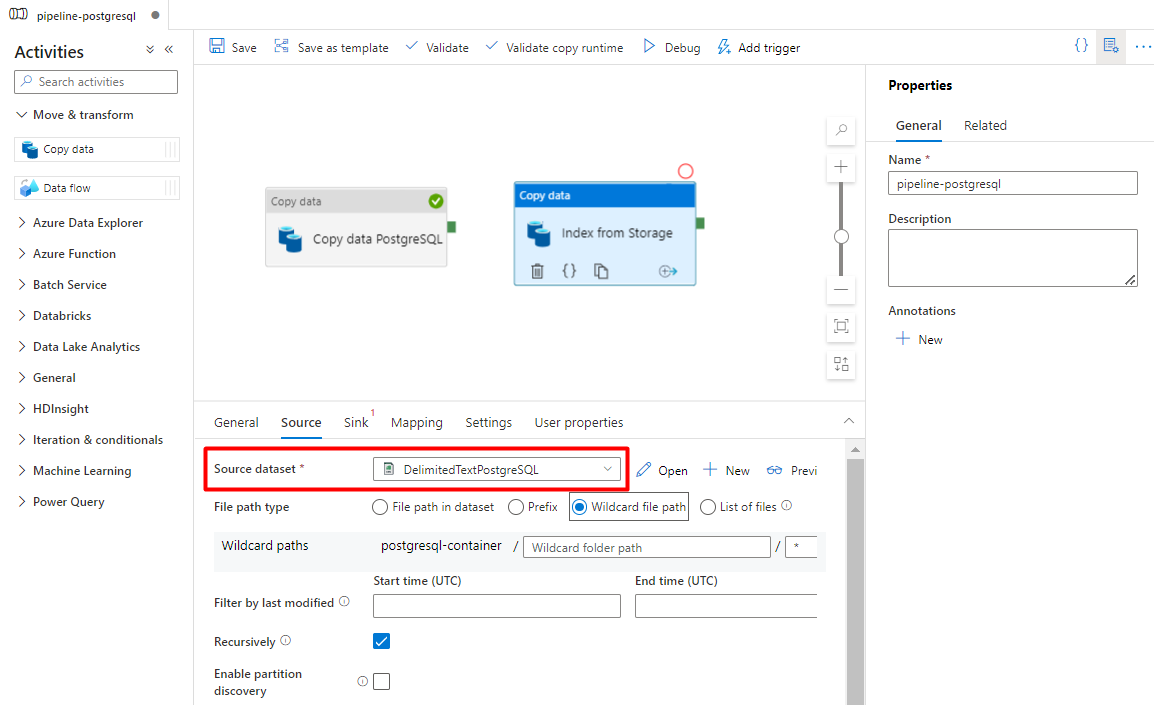
På fliken Mottagare väljer du ditt Azure Cognitive Search index. Låt de återstående alternativen vara kvar med standardvärdena.

Välj Spara.
Steg 9: Konfigurera aktivitetsordning
I redigeringsprogrammet för pipeline-arbetsytan väljer du den lilla gröna rutan vid kanten av pipelineaktiviteten. Dra den till aktiviteten "Index från lagringskonto för att Azure Cognitive Search" för att ange körningsordningen.
Välj Spara.
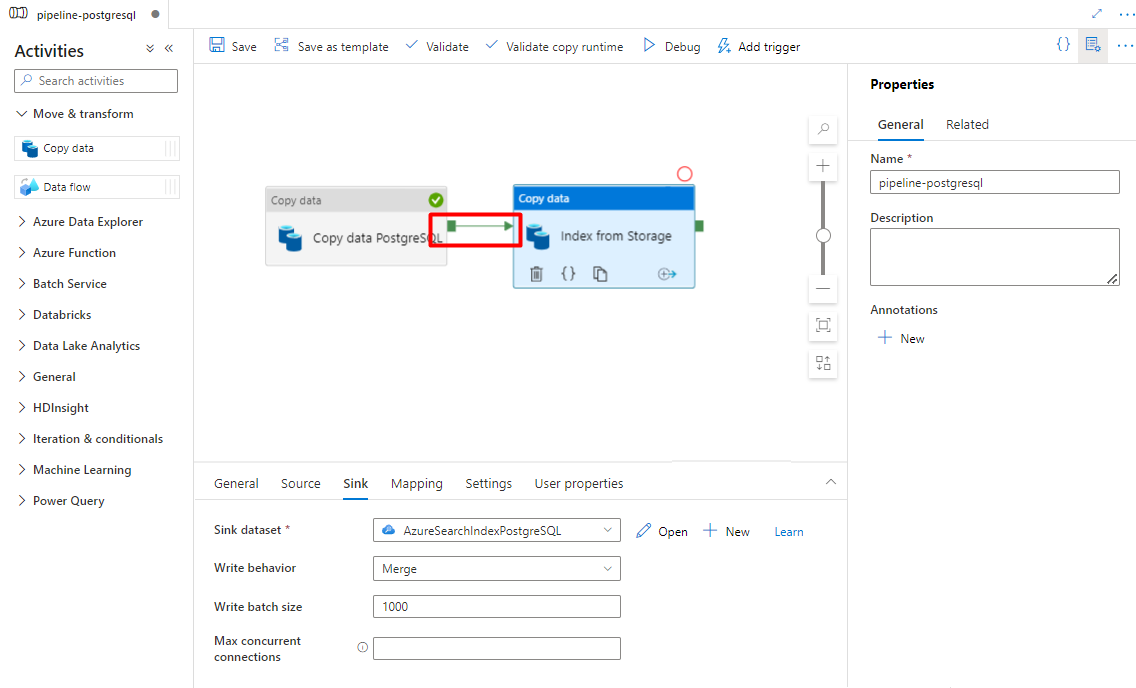
Steg 10: Lägg till en pipeline-utlösare
Välj Lägg till utlösare för att schemalägga pipelinekörningen och välj Ny/Redigera.

I listrutan Välj utlösare väljer du Nytt.
Granska utlösaralternativen för att köra pipelinen och välj OK.
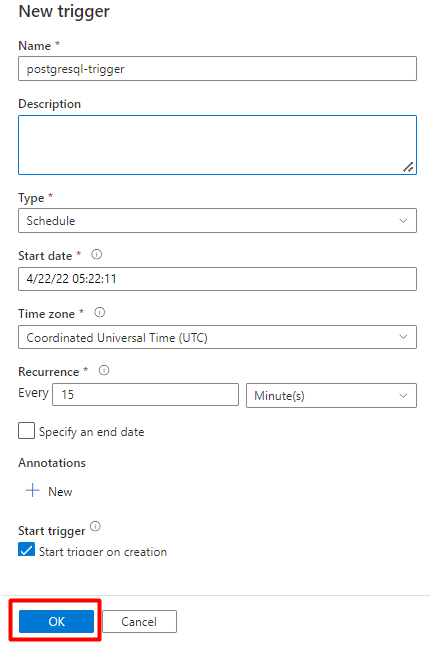
Välj Spara.
Välj Publicera.
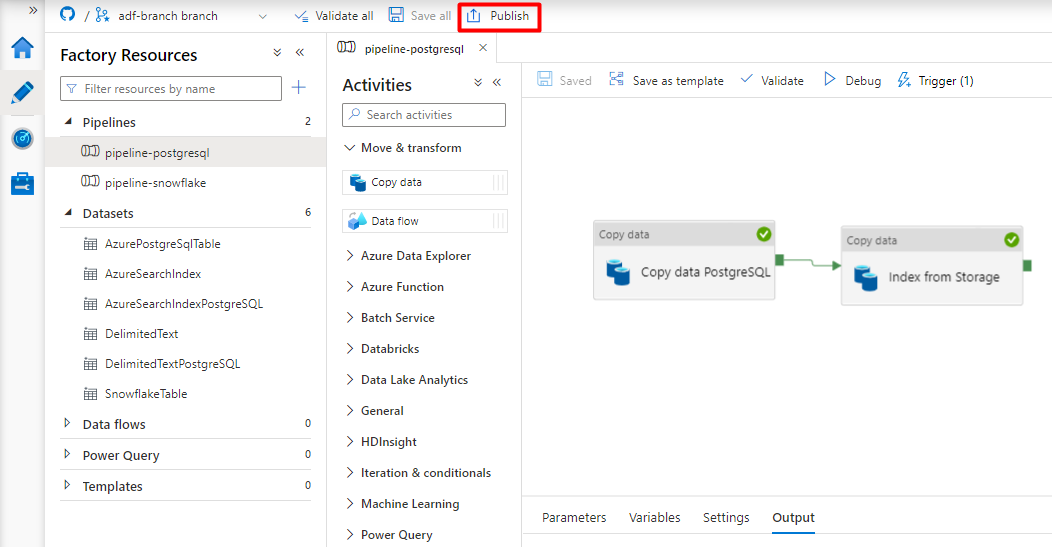
Äldre innehåll för förhandsversionen av Power Query-anslutningsappen
Ett Power Query-anslutningsprogram används med en sökindexerare för att automatisera datainmatning från olika datakällor, inklusive data från andra molnleverantörer. Den använder Power Query för att hämta data.
Datakällor som stöds i förhandsversionen är:
- Amazon Redshift
- Elasticsearch
- PostgreSQL
- Salesforce-objekt
- Salesforce-rapporter
- Smartsheet
- Snowflake
Funktioner som stöds
Power Query-anslutningsappar används i indexerare. En indexerare i Azure Cognitive Search är en crawler som extraherar sökbara data och metadata från en extern datakälla och fyller i ett index baserat på fält-till-fält-mappningar mellan indexet och datakällan. Den här metoden kallas ibland för en "pull-modell" eftersom tjänsten hämtar data utan att du behöver skriva någon kod som lägger till data i ett index. Indexerare är ett bekvämt sätt för användare att indexeras innehåll från sin datakälla utan att behöva skriva en egen crawler- eller push-modell.
Indexerare som refererar Power Query datakällor har samma stödnivå för kompetensuppsättningar, scheman, logik för ändringsidentifiering med hög vattenmärke och de flesta parametrar som andra indexerare stöder.
Förutsättningar
Även om du inte längre kan använda den här funktionen hade den följande krav i förhandsversionen:
Azure Cognitive Search i en region som stöds.
Förhandsversionsregistrering. Den här funktionen måste vara aktiverad på serverdelen.
Azure Blob Storage konto som används som mellanhand för dina data. Data flödar från din datakälla, sedan till Blob Storage och sedan till indexet. Det här kravet finns bara med den första gated preview.
Regional tillgänglighet
Förhandsversionen var endast tillgänglig för söktjänster i följande regioner:
- Central US
- East US
- USA, östra 2
- USA, norra centrala
- Europa, norra
- USA, södra centrala
- USA, västra centrala
- Europa, västra
- USA, västra
- USA, västra 2
Begränsningar för förhandsversion
I det här avsnittet beskrivs de begränsningar som är specifika för den aktuella versionen av förhandsversionen.
Det går inte att hämta binära data från datakällan.
Felsökningssession stöds inte.
Komma igång med Azure Portal
Azure Portal har stöd för Power Query-anslutningsappar. Genom att samplingsdata och läsa metadata i containern kan guiden Importera data i Azure Cognitive Search skapa ett standardindex, mappa källfält till målindexfält och läsa in indexet i en enda åtgärd. Beroende på källdatas storlek och komplexitet kan du ha ett index för fulltextsökning i drift på några minuter.
Följande video visar hur du konfigurerar en Power Query-anslutningsapp i Azure Cognitive Search.
Steg 1 – Förbereda källdata
Kontrollera att datakällan innehåller data. Guiden Importera data läser metadata och utför datasampling för att härleda ett indexschema, men läser också in data från datakällan. Om data saknas stoppas och returneras och fel returneras.
Steg 2 – Starta guiden Importera data
När du har godkänts för förhandsversionen ger Azure Cognitive Search-teamet dig en Azure Portal-länk som använder en funktionsflagga så att du kan komma åt Power Query-anslutningsappar. Öppna den här sidan och starta guiden från kommandofältet på Azure Cognitive Search-tjänstsidan genom att välja Importera data.
Steg 3 – Välj din datakälla
Det finns några datakällor som du kan hämta data från med hjälp av den här förhandsversionen. Alla datakällor som använder Power Query innehåller en "Powered By Power Query" på panelen. Välj din datakälla.
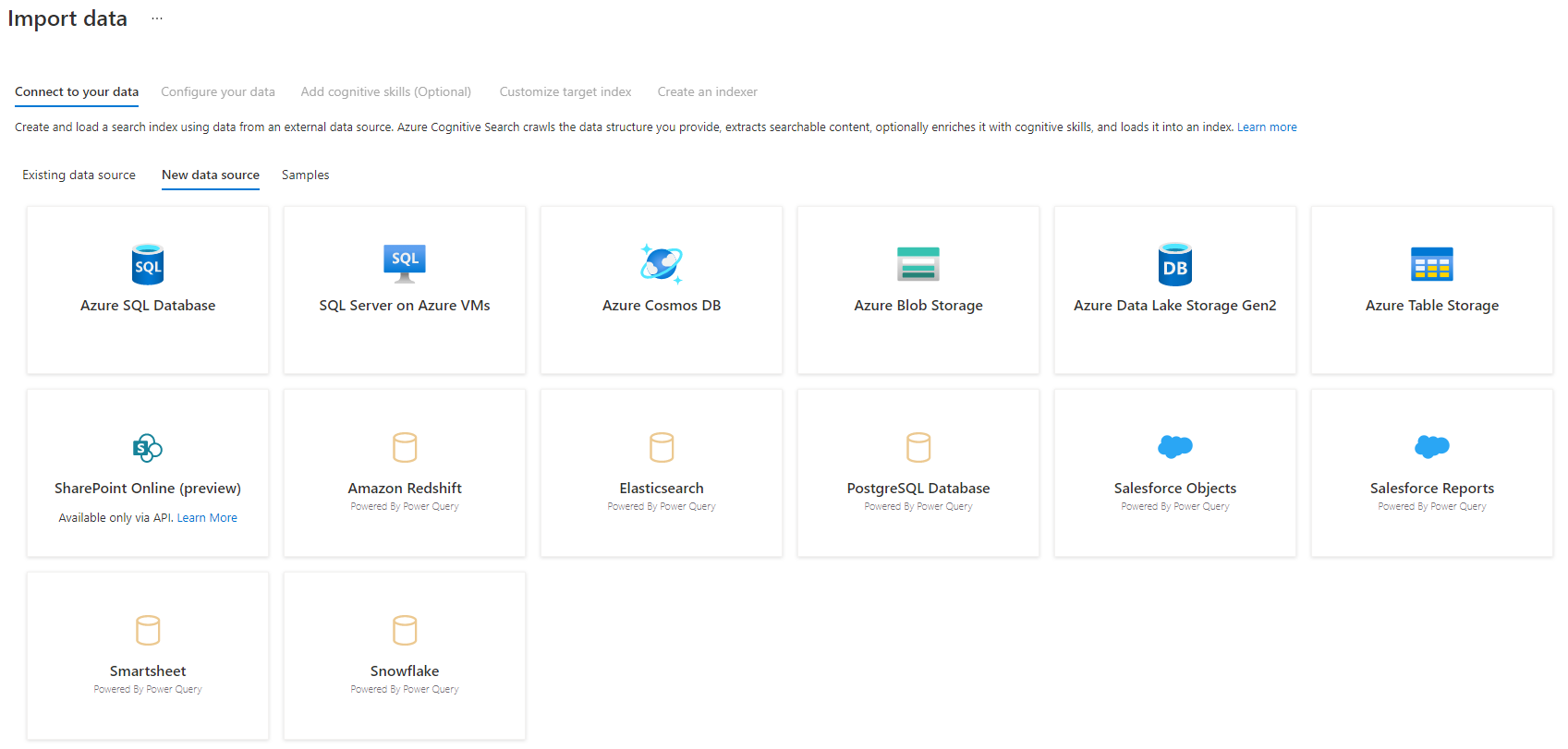
När du har valt din datakälla väljer du Nästa: Konfigurera dina data för att gå vidare till nästa avsnitt.
Steg 4 – Konfigurera dina data
I det här steget konfigurerar du anslutningen. Varje datakälla kräver olika information. För några få datakällor innehåller Power Query-dokumentationen mer information om hur du ansluter till dina data.
När du har angett dina autentiseringsuppgifter för anslutningen väljer du Nästa.
Steg 5 – Välj dina data
Importguiden förhandsgranskar olika tabeller som är tillgängliga i din datakälla. I det här steget ska du kontrollera en tabell som innehåller de data som du vill importera till ditt index.
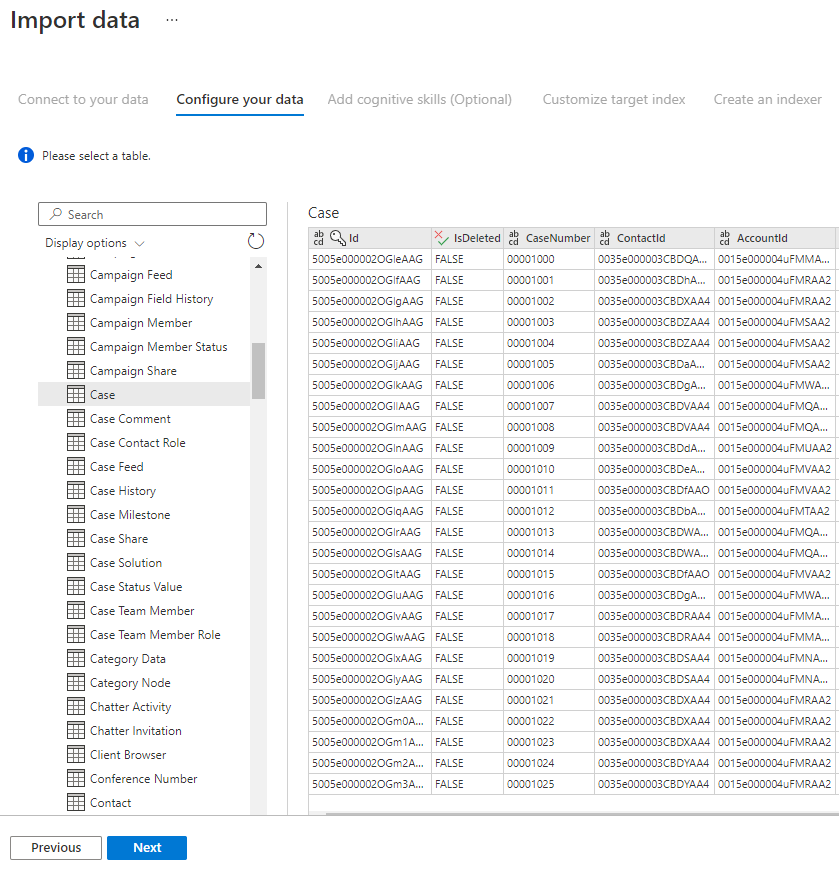
När du har valt tabellen väljer du Nästa.
Steg 6 – Transformera dina data (valfritt)
Power Query anslutningsappar ger dig en omfattande användargränssnittsupplevelse som gör att du kan manipulera dina data så att du kan skicka rätt data till ditt index. Du kan ta bort kolumner, filtrera rader och mycket mer.
Du behöver inte transformera dina data innan du importerar dem till Azure Cognitive Search.

Mer information om hur du transformerar data med Power Query finns i Använda Power Query i Power BI Desktop.
När data har transformerats väljer du Nästa.
Steg 7 – Lägga till Azure Blob Storage
Förhandsversionen av Power Query-anslutningsappen kräver för närvarande att du anger ett bloblagringskonto. Det här steget finns bara med den första grindförhandsgranskningen. Det här Blob Storage-kontot fungerar som tillfällig lagring för data som flyttas från datakällan till ett Azure Cognitive Search index.
Vi rekommenderar att du tillhandahåller ett lagringskonto med fullständig åtkomst anslutningssträng:
{ "connectionString" : "DefaultEndpointsProtocol=https;AccountName=<your storage account>;AccountKey=<your account key>;" }
Du kan hämta anslutningssträng från Azure Portal genom att gå till lagringskontobladet > Inställningsnycklar > (för klassiska lagringskonton) eller Inställningar > Åtkomstnycklar (för Azure Resource Manager lagringskonton).
När du har angett ett namn på datakällan och anslutningssträng väljer du "Nästa: Lägg till kognitiva färdigheter (valfritt)".
Steg 8 – Lägg till kognitiva färdigheter (valfritt)
AI-berikning är en förlängning av indexerare som kan användas för att göra ditt innehåll mer sökbart.
Du kan lägga till berikanden som ger fördelar i ditt scenario. När du är klar väljer du Nästa: Anpassa målindex.
Steg 9 – Anpassa målindex
På sidan Index bör du se en lista med fält med en datatyp och en serie kryssrutor för att ange indexattribut. Guiden kan generera en fältlista baserat på metadata och genom att sampling av källdata.
Du kan massval av attribut genom att markera kryssrutan överst i en attributkolumn. Välj Hämtningsbar och Sökbar för varje fält som ska returneras till en klientapp och som omfattas av bearbetning av fulltextsökning. Du kommer att märka att heltal inte är fulltext eller fuzzy-sökbara (tal utvärderas ordagrant och är ofta användbara i filter).
Mer information finns i beskrivningen av indexattribut och språkanalysverktyg.
Ta en stund att granska dina val. När du har kört guiden skapas fysiska datastrukturer och du kan inte redigera de flesta egenskaperna för dessa fält utan att släppa och återskapa alla objekt.

När du är klar väljer du Nästa: Skapa en indexerare.
Steg 10 – Skapa en indexerare
Det sista steget skapar indexeraren. Om du namnger indexeraren kan den finnas som en fristående resurs, som du kan schemalägga och hantera oberoende av index- och datakällans objekt, som skapats i samma guidesekvens.
Utdata från guiden Importera data är en indexerare som crawlar datakällan och importerar de data som du har valt till ett index på Azure Cognitive Search.
När du skapar indexeraren kan du välja att köra indexeraren enligt ett schema och lägga till ändringsidentifiering. Om du vill lägga till ändringsidentifiering anger du kolumnen "högvattenmärke".
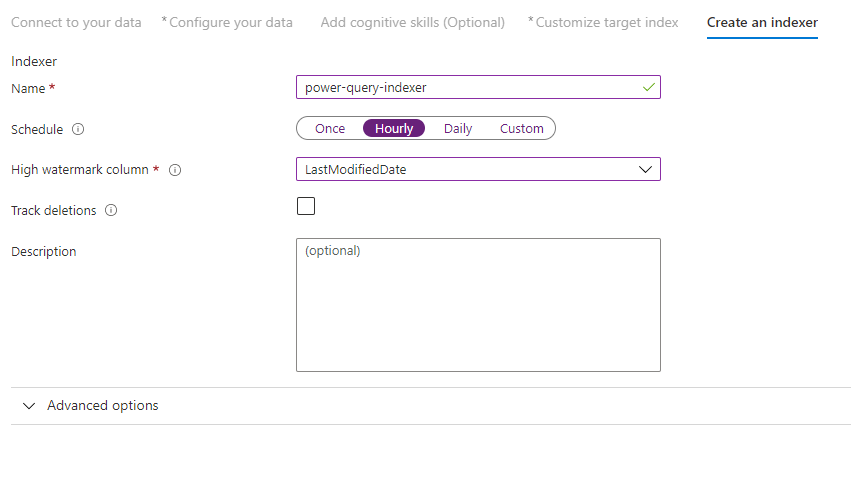
När du har fyllt i den här sidan väljer du Skicka.
Princip för ändringsidentifiering av högvattenmärke
Den här principen för ändringsidentifiering förlitar sig på en kolumn med högvattenmärke som samlar in versionen eller tiden då en rad senast uppdaterades.
Krav
- Alla infogningar anger ett värde för kolumnen.
- Alla uppdateringar av ett objekt ändrar också värdet för kolumnen.
- Värdet för den här kolumnen ökar med varje infogning eller uppdatering.
Kolumnnamn som inte stöds
Fältnamn i ett Azure Cognitive Search index måste uppfylla vissa krav. Ett av dessa krav är att vissa tecken som "/" inte tillåts. Om ett kolumnnamn i databasen inte uppfyller dessa krav kommer indexschemaidentifieringen inte att identifiera kolumnen som ett giltigt fältnamn och du ser inte kolumnen som ett föreslaget fält för indexet. Normalt skulle användning av fältmappningar lösa det här problemet, men fältmappningar stöds inte i portalen.
Om du vill indexera innehåll från en kolumn i tabellen som har ett fältnamn som inte stöds byter du namn på kolumnen under fasen "Transformera dina data" i importdataprocessen. Du kan till exempel byta namn på en kolumn med namnet "Faktureringskod/postnummer" till "postnummer". Genom att byta namn på kolumnen identifierar indexschemaidentifieringen den som ett giltigt fältnamn och lägger till den som ett förslag i indexdefinitionen.
Nästa steg
I den här artikeln beskrivs hur du hämtar data med hjälp av Power Query-anslutningsappar. Eftersom den här förhandsgranskningsfunktionen har upphört förklaras också hur du migrerar befintliga lösningar till ett scenario som stöds.
Mer information om indexerare finns i Indexerare i Azure Cognitive Search.