Skapa ett vektorlager
I Azure AI Search har ett vektorlager ett indexschema som definierar vektor- och icke-vektorfält, en vektorkonfiguration för algoritmer som skapar inbäddningsutrymmet och inställningar för vektorfältdefinitioner som används i frågebegäranden. Api: et Skapa index skapar vektorarkivet.
Följ dessa steg för att indexera vektordata:
- Definiera ett schema med en eller flera vektorkonfigurationer som anger algoritmer för indexering och sökning
- Lägga till ett eller flera vektorfält
- Läs in fördefinierade data som ett separat steg eller använd integrerad vektorisering (förhandsversion) för datasegmentering och kodning under indexering.
Den här artikeln gäller för den allmänt tillgängliga versionen av vektorsökning som inte är förhandsversion, vilket förutsätter att programkoden anropar externa resurser för segmentering och kodning.
Kommentar
Letar du efter migreringsvägledning från förhandsversionen av 2023-07-01? Se Uppgradera REST-API:er.
Förutsättningar
Azure AI Search, i valfri region och på valfri nivå. De flesta befintliga tjänster stöder vektorsökning. För tjänster som skapades före januari 2019 finns det en liten delmängd som inte stöder vektorsökning. Om ett index som innehåller vektorfält inte kan skapas eller uppdateras är detta en indikator. I det här fallet måste en ny tjänst skapas.
Befintliga vektorinbäddningar i källdokumenten. Azure AI Search genererar inte vektorer i den allmänt tillgängliga versionen av Azure SDK:er och REST-API:er. Vi rekommenderar inbäddningsmodeller i Azure OpenAI, men du kan använda valfri modell för vektorisering. Mer information finns i Generera inbäddningar.
Du bör känna till dimensionsgränsen för den modell som används för att skapa inbäddningarna och hur likheten beräknas. För textinbäddning-ada-002 i Azure OpenAI är längden på den numeriska vektorn 1536. Likheten beräknas med hjälp av
cosine. Giltiga värden är 2 till 3 072 dimensioner.Du bör vara bekant med att skapa ett index. Schemat måste innehålla ett fält för dokumentnyckeln, andra fält som du vill söka efter eller filtrera samt andra konfigurationer för beteenden som behövs under indexering och frågor.
Förbereda dokument för indexering
Innan du indexerar ska du sätta ihop en nyttolast för dokument som innehåller fält med vektor- och icke-vektordata. Dokumentstrukturen måste överensstämma med indexschemat.
Kontrollera att dina dokument:
Ange ett fält eller en metadataegenskap som unikt identifierar varje dokument. Alla sökindex kräver en dokumentnyckel. För att uppfylla kraven för dokumentnyckeln måste ett källdokument ha ett fält eller en egenskap som unikt kan identifiera det i indexet. Det här källfältet måste mappas till ett indexfält av typen
Edm.Stringochkey=truei sökindexet.Ange vektordata (en matris med flyttal med enkel precision) i källfält.
Vektorfält innehåller numeriska data som genereras av inbäddningsmodeller, en inbäddning per fält. Vi rekommenderar inbäddningsmodellerna i Azure OpenAI, till exempel textinbäddning-ada-002 för textdokument eller REST API för bildhämtning för bilder. Endast indexvektorfält på den översta nivån stöds: Vektorunderfält stöds inte för närvarande.
Ange andra fält med alfanumeriskt innehåll som kan läsas av människor för frågesvaret och för hybridfrågescenarier som innehåller fulltextsökning eller semantisk rangordning i samma begäran.
Ditt sökindex bör innehålla fält och innehåll för alla frågescenarier som du vill stödja. Anta att du vill söka eller filtrera efter produktnamn, versioner, metadata eller adresser. I det här fallet är likhetssökning inte särskilt användbart. Nyckelordssökning, geo-sökning eller filter skulle vara ett bättre val. Ett sökindex som innehåller en omfattande fältsamling med vektor- och icke-bevektordata ger maximal flexibilitet för frågekonstruktion och svarssammansättning.
Ett kort exempel på en dokumentnyttolast som innehåller vektor- och icke-bevektorfält finns i avsnittet data för belastningsvektorer i den här artikeln.
Lägga till en konfiguration för vektorsökning
En vektorkonfiguration anger algoritmen för vektorsökning och parametrar som används under indexeringen för att skapa "närmaste granne"-information bland vektornoderna:
- Hierarkisk navigerbar liten värld (HNSW)
- Fullständig KNN
Om du väljer HNSW i ett fält kan du välja fullständig KNN vid frågetillfället. Men den andra riktningen fungerar inte: om du väljer fullständig kan du inte senare begära HNSW-sökning eftersom de extra datastrukturerna som möjliggör ungefärlig sökning inte finns.
Letar du efter vägledning för migrering av förhandsversion till stabil version? Se Uppgradera REST-API:er för steg.
REST API version 2023-11-01 stöder en vektorkonfiguration med:
vectorSearchalgoritmerhnswochexhaustiveKnnnärmaste grannar, med parametrar för indexering och bedömning.vectorProfilesför flera kombinationer av algoritmkonfigurationer.
Se till att ha en strategi för att vektorisera ditt innehåll. Den stabila versionen tillhandahåller inte vektoriserare för inbyggd inbäddning.
Använd API:et Skapa eller uppdatera index för att skapa indexet.
Lägg till ett
vectorSearchavsnitt i indexet som anger de sökalgoritmer som används för att skapa inbäddningsutrymmet."vectorSearch": { "algorithms": [ { "name": "my-hnsw-config-1", "kind": "hnsw", "hnswParameters": { "m": 4, "efConstruction": 400, "efSearch": 500, "metric": "cosine" } }, { "name": "my-hnsw-config-2", "kind": "hnsw", "hnswParameters": { "m": 8, "efConstruction": 800, "efSearch": 800, "metric": "cosine" } }, { "name": "my-eknn-config", "kind": "exhaustiveKnn", "exhaustiveKnnParameters": { "metric": "cosine" } } ], "profiles": [ { "name": "my-default-vector-profile", "algorithm": "my-hnsw-config-2" } ] }Viktiga punkter:
- Namnet på konfigurationen. Namnet måste vara unikt i indexet.
profileslägg till ett abstraktionslager för att ta emot mer omfattande definitioner. En profil definieras ivectorSearchoch refereras sedan med namn på varje vektorfält."hnsw"och"exhaustiveKnn"är algoritmerna Ungefärliga närmaste grannar (ANN) som används för att organisera vektorinnehåll under indexering."m"(antal dubbelriktade länkar) är standardvärdet 4. Intervallet är 4 till 10. Lägre värden bör returnera mindre brus i resultatet."efConstruction"standardvärdet är 400. Intervallet är mellan 100 och 1 000. Det är antalet närmaste grannar som används under indexeringen."efSearch"standardvärdet är 500. Intervallet är mellan 100 och 1 000. Det är antalet närmaste grannar som används under sökningen."metric"bör vara "cosiné" om du använder Azure OpenAI, annars använder du likhetsmåttet som är associerat med den inbäddningsmodell som du använder. Värden som stöds ärcosine,dotProduct,euclidean.
Lägga till ett vektorfält i fältsamlingen
Fältsamlingen måste innehålla ett fält för dokumentnyckeln, vektorfälten och alla andra fält som du behöver för hybridsökningsscenarier.
Vektorfält är av typen Collection(Edm.Single) och flyttalsvärden med enkel precision. Ett fält av den här typen har också en dimensions egenskap och anger en vektorkonfiguration.
Använd den här versionen om du bara vill ha allmänt tillgängliga funktioner.
Använd Skapa eller uppdatera index för att skapa indexet.
Definiera ett vektorfält med följande attribut. Du kan lagra en genererad inbäddning per fält. För varje vektorfält:
typemåste varaCollection(Edm.Single).dimensionsär antalet dimensioner som genereras av inbäddningsmodellen. För text-embedding-ada-002 är det 1536.vectorSearchProfileär namnet på en profil som definierats någon annanstans i indexet.searchablemåste vara sant.retrievablekan vara sant eller falskt. True returnerar råvektorerna (1536 av dem) som oformaterad text och förbrukar lagringsutrymme. Ange sant om du skickar ett vektorresultat till en nedströmsapp.filterable,facetable,sortablemåste vara falskt.
Lägg till filterbara icke-inledande fält i samlingen, till exempel "rubrik" med
filterablevärdet true, om du vill anropa förfiltrering eller postfiltrering i vektorfrågan.Lägg till andra fält som definierar ämnet och strukturen för det textinnehåll som du indexerar. Du behöver minst en dokumentnyckel.
Du bör också lägga till fält som är användbara i frågan eller i dess svar. I följande exempel visas vektorfält för rubrik och innehåll ("titleVector", "contentVector") som motsvarar vektorer. Den innehåller också fält för motsvarande textinnehåll ("rubrik", "innehåll") som är användbart för sortering, filtrering och läsning i ett sökresultat.
I följande exempel visas fältsamlingen:
PUT https://my-search-service.search.windows.net/indexes/my-index?api-version=2023-11-01&allowIndexDowntime=true Content-Type: application/json api-key: {{admin-api-key}} { "name": "{{index-name}}", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "filterable": true }, { "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "retrievable": true }, { "name": "titleVector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-default-vector-profile" }, { "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true }, { "name": "contentVector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-default-vector-profile" } ], "vectorSearch": { "algorithms": [ { "name": "my-hnsw-config-1", "kind": "hnsw", "hnswParameters": { "m": 4, "efConstruction": 400, "efSearch": 500, "metric": "cosine" } } ], "profiles": [ { "name": "my-default-vector-profile", "algorithm": "my-hnsw-config-1" } ] } }
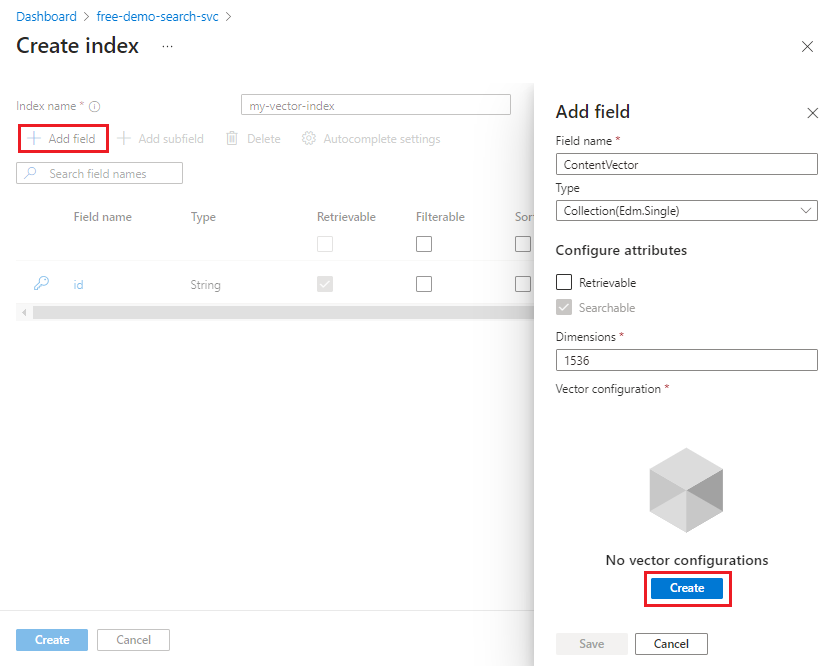
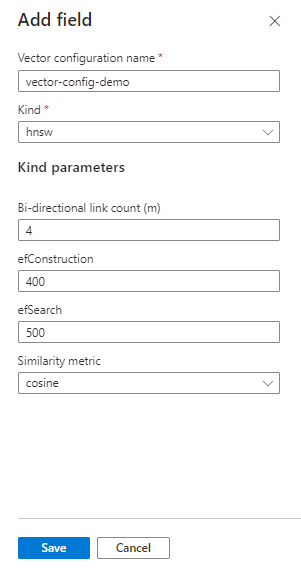
Läsa in vektordata för indexering
Innehåll som du anger för indexering måste överensstämma med indexschemat och innehålla ett unikt strängvärde för dokumentnyckeln. Fördefinierade data läses in i ett eller flera vektorfält, som kan samexistera med andra fält som innehåller alfanumeriskt innehåll.
Du kan använda push - eller pull-metoder för datainmatning.
Använd indexdokument (2023-11-01), indexdokument (2023-10-01-preview)eller lägg till, uppdatera eller ta bort dokument (2023-07-01-Preview) för att skicka dokument som innehåller vektordata.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/index?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"value": [
{
"id": "1",
"title": "Azure App Service",
"content": "Azure App Service is a fully managed platform for building, deploying, and scaling web apps. You can host web apps, mobile app backends, and RESTful APIs. It supports a variety of programming languages and frameworks, such as .NET, Java, Node.js, Python, and PHP. The service offers built-in auto-scaling and load balancing capabilities. It also provides integration with other Azure services, such as Azure DevOps, GitHub, and Bitbucket.",
"category": "Web",
"titleVector": [
-0.02250031754374504,
. . .
],
"contentVector": [
-0.024740582332015038,
. . .
],
"@search.action": "upload"
},
{
"id": "2",
"title": "Azure Functions",
"content": "Azure Functions is a serverless compute service that enables you to run code on-demand without having to manage infrastructure. It allows you to build and deploy event-driven applications that automatically scale with your workload. Functions support various languages, including C#, F#, Node.js, Python, and Java. It offers a variety of triggers and bindings to integrate with other Azure services and external services. You only pay for the compute time you consume.",
"category": "Compute",
"titleVector": [
-0.020159931853413582,
. . .
],
"contentVector": [
-0.02780858241021633,
. . .
],
"@search.action": "upload"
}
. . .
]
}
Kontrollera ditt index för vektorinnehåll
I valideringssyfte kan du fråga indexet med hjälp av Search Explorer i Azure-portalen eller ett REST API-anrop. Eftersom Azure AI Search inte kan konvertera en vektor till text som kan läsas av människor kan du försöka returnera fält från samma dokument som visar matchningen. Om vektorfrågan till exempel riktar sig mot fältet "titleVector" kan du välja "rubrik" för sökresultaten.
Fält måste tillskrivas som "hämtningsbara" för att inkluderas i resultatet.
Du kan använda Sökutforskaren för att fråga ett index. Sökutforskaren har två vyer: Frågevy (standard) och JSON-vy.
Använd JSON-vyn för vektorfrågor och klistra in en JSON-definition av den vektorfråga som du vill köra.
Använd standardvyn Fråge för en snabb bekräftelse på att indexet innehåller vektorer. Frågevyn är avsedd för fulltextsökning. Även om du inte kan använda den för vektorfrågor kan du skicka en tom sökning (
search=*) för att söka efter innehåll. Innehållet i alla fält, inklusive vektorfält, returneras som oformaterad text.
Uppdatera ett vektorlager
Om du vill uppdatera ett vektorlager ändrar du schemat och läser in dokument igen för att fylla i nya fält. API:er för schemauppdateringar inkluderar Create or Update Index (REST), CreateOrUpdateIndex i Azure SDK för .NET, create_or_update_index i Azure SDK för Python och liknande metoder i andra Azure SDK:er.
Standardvägledningen för att uppdatera ett index beskrivs i Släpp och återskapa ett index.
Viktiga punkter är:
Släpp och återskapa krävs ofta för uppdateringar av och borttagning av befintliga fält.
Du kan dock uppdatera ett befintligt schema med följande ändringar, utan att behöva återskapa det:
- Lägg till nya fält i en fältsamling.
- Lägg till nya vektorkonfigurationer, tilldelade till nya fält men inte befintliga fält som redan har vektoriserats.
- Ändra "hämtningsbar" (värden är sanna eller falska) i ett befintligt fält. Vektorfält måste vara sökbara och hämtningsbara, men om du vill inaktivera åtkomsten till ett vektorfält i situationer där det inte går att släppa och återskapa kan du ange hämtningsbar till false.
Nästa steg
Som ett nästa steg rekommenderar vi Frågevektordata i ett sökindex.
Kodexempel på lagringsplatsen azure-search-vector visar arbetsflöden från slutpunkt till slutpunkt som innehåller schemadefinition, vektorisering, indexering och frågor.
Det finns demokod för Python, C#och JavaScript.