Prestandajustering med grupperade kolumnlagringsindex
Gäller för: Azure Synapse Analytics dedikerade SQL-pooler, SQL Server 2022 (16.x) och senare
När användare kör frågor mot en columnstore-tabell i en dedikerad SQL-pool kontrollerar optimeringen de lägsta och högsta värden som lagras i varje segment. Segment som ligger utanför gränserna för frågepredikatet läse inte från disk till minne. En fråga kan slutföras snabbare om antalet segment som ska läsas och deras totala storlek är liten.
Ordnat jämfört med icke-sorterat grupperat kolumnlagringsindex
För varje tabell som skapas utan indexalternativ skapar en intern komponent (indexverktyget) som standard ett icke-ordnat grupperat kolumnlagringsindex (CCI) på den. Data i varje kolumn komprimeras till ett separat CCI-radgruppssegment. Det finns metadata för varje segments värdeintervall, så segment som ligger utanför gränserna för frågepredikatet läse inte från disken under frågekörningen. CCI erbjuder den högsta nivån av datakomprimering och minskar storleken på segment att läsa så att frågor kan köras snabbare. Men eftersom indexverktyget inte sorterar data innan de komprimeras till segment kan segment med överlappande värdeintervall inträffa, vilket gör att frågor läser fler segment från disken och tar längre tid att slutföra.
Ordnade grupperade kolumnlagringsindex genom att aktivera effektiv segmenteliminering, vilket resulterar i mycket snabbare prestanda genom att hoppa över stora mängder sorterade data som inte matchar frågepredikatet. När du skapar en ordnad CCI sorterar den dedikerade SQL-poolmotorn befintliga data i minnet efter ordernycklarna innan indexverktyget komprimerar dem till indexsegment. Med sorterade data minskas segmentöverlappningen så att frågor kan få en effektivare segmenteliminering och därmed snabbare prestanda eftersom antalet segment som ska läsas från disken är mindre. Om alla data kan sorteras i minnet samtidigt kan segment överlappande undvikas. På grund av stora tabeller i informationslager sker det här scenariot inte ofta.
Om du vill kontrollera segmentintervallen för en kolumn kör du följande kommando med tabellnamnet och kolumnnamnet:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Anteckning
I en ordnad CCI-tabell sorteras de nya data som härrör från samma batch med DML eller datainläsningsåtgärder inom den batchen, det finns ingen global sortering över alla data i tabellen. Användare kan ÅTERSKAPA den ordnade CCI:en för att sortera alla data i tabellen. I en dedikerad SQL-pool är columnstore-indexet REBUILD en offlineåtgärd. För en partitionerad tabell görs REBUILD en partition i taget. Data i partitionen som återskapas är "offline" och otillgängliga tills REBUILD har slutförts för partitionen.
Frågeprestanda
En frågas prestandavinst från en ordnad CCI beror på frågemönstren, storleken på data, hur väl data sorteras, segmentens fysiska struktur samt vilken DWU och resursklass som valts för frågekörningen. Användarna bör granska alla dessa faktorer innan de väljer ordningskolumnerna när de utformar en ordnad CCI-tabell.
Frågor med alla dessa mönster körs vanligtvis snabbare med ordnad CCI.
- Frågorna har likhets-, olikhets- eller intervallpredikat
- Predikatkolumnerna och de ordnade CCI-kolumnerna är desamma.
I det här exemplet har tabell T1 ett grupperat kolumnlagringsindex ordnat i sekvensen med Col_C, Col_B och Col_A.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
Prestanda för fråga 1 och fråga 2 kan dra mer nytta av ordnad CCI än de andra frågorna, eftersom de refererar till alla ordnade CCI-kolumner.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Datainläsningsprestanda
Prestanda för datainläsning i en ordnad CCI-tabell liknar en partitionerad tabell. Att läsa in data i en ordnad CCI-tabell kan ta längre tid än en icke-ordnad CCI-tabell på grund av datasorteringsåtgärden, men frågor kan köras snabbare efteråt med ordnad CCI.
Här är ett exempel på prestandajämförelse av inläsning av data i tabeller med olika scheman.

Här är ett exempel på en jämförelse av frågeprestanda mellan CCI och ordnad CCI.

Minska segment som överlappar
Antalet överlappande segment beror på storleken på data som ska sorteras, det tillgängliga minnet och maxgränsen för parallellitet (MAXDOP) när en ordnad CCI skapas. Följande strategier minskar segment som överlappar vid skapande av ordnad CCI.
Använd
xlargercresursklassen på en högre DWU för att tillåta mer minne för datasortering innan indexverktyget komprimerar data till segment. En gång i ett indexsegment kan inte den fysiska platsen för data ändras. Det finns ingen datasortering inom ett segment eller mellan segment.Skapa ordnad CCI med
OPTION (MAXDOP = 1). Varje tråd som används för att skapa en ordnad CCI fungerar på en delmängd data och sorterar dem lokalt. Det finns ingen global sortering mellan data sorterade efter olika trådar. Att använda parallella trådar kan minska tiden för att skapa en ordnad CCI, men genererar fler överlappande segment än att använda en enda tråd. Med en enda trådad åtgärd får du högsta komprimeringskvalitet. Exempel:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Anteckning
I dedikerade SQL-pooler i Azure Synapse Analytics stöds för närvarande maxdop-alternativet bara för att skapa en ordnad CCI-tabell med kommandot CREATE TABLE AS SELECT . Att skapa en ordnad CCI via CREATE INDEX eller CREATE TABLE kommandon stöder inte MAXDOP-alternativet. Den här begränsningen gäller inte för SQL Server 2022 och senare versioner, där du kan ange MAXDOP med CREATE INDEX kommandona eller CREATE TABLE .
- Sortera data i förväg efter sorteringsnycklarna innan du läser in dem i tabeller.
Här är ett exempel på en ordnad CCI-tabelldistribution som har noll segment som överlappar följande rekommendationer ovan. Den beställda CCI-tabellen skapas i en DWU1000c-databas via CTAS från en heaptabell på 20 GB med MAXDOP 1 och xlargerc. CCI sorteras på en BIGINT-kolumn utan dubbletter.
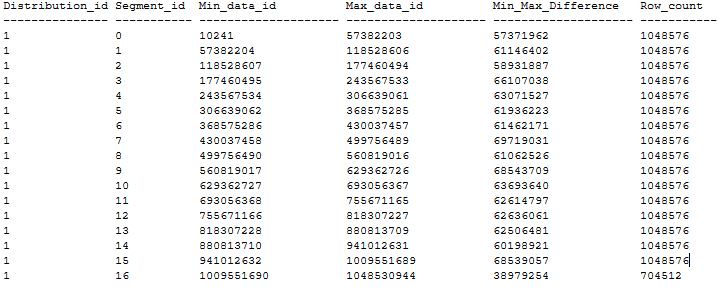
Skapa ordnad CCI på stora tabeller
Att skapa en ordnad CCI är en offlineåtgärd. För tabeller utan partitioner är data inte tillgängliga för användare förrän den ordnade CCI-skapandeprocessen har slutförts. Eftersom motorn skapar den sorterade CCI-partitionen efter partition för partitioner kan användarna fortfarande komma åt data i partitioner där ordnad CCI-skapande inte är i process. Du kan använda det här alternativet för att minimera stilleståndstiden vid ordnad CCI-skapande i stora tabeller:
- Skapa partitioner i den stora måltabellen (kallas
Table_A). - Skapa en tom ordnad CCI-tabell (kallas
Table_B) med samma tabell och partitionsschema somTable_A. - Växla en partition från
Table_AtillTable_B. - Kör
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>för att återskapa den inkopplade partitionen påTable_B. - Upprepa steg 3 och 4 för varje partition i
Table_A. - När alla partitioner har växlats från
Table_AtillTable_Boch har återskapats släpper duTable_Aoch byter namnTable_BtillTable_A.
Tips
För en dedikerad SQL-pooltabell med en ordnad CCI sorterar ALTER INDEX REBUILD om data med .tempdb Övervaka tempdb under återskapandeåtgärder. Om du behöver mer tempdb utrymme skalar du upp poolen. Skala ned igen när indexet har återskapats.
För en dedikerad SQL-pooltabell med en ordnad CCI sorterar INTE ALTER INDEX REORGANIZE om data. Om du vill använda data använder du ALTER INDEX REBUILD.
Mer information om ordnat CCI-underhåll finns i Optimera klustrade kolumnlagringsindex.
Funktionsskillnader i SQL Server 2022-funktioner
SQL Server 2022 (16.x) introducerade ordnade grupperade kolumnlagringsindex som liknar funktionen i Azure Synapse dedikerade SQL-pooler.
- För närvarande stöder endast SQL Server 2022 (16.x) och senare versioner förbättrade segmentelimineringsfunktioner för grupperade kolumnlager för sträng-, binär- och guid-datatyper och datatypen datetimeoffset för skalning större än två. Tidigare gäller den här segmentelimineringen för datatyperna numeriskt, datum och tid och datatypen datetimeoffset med en skala som är mindre än eller lika med två.
- För närvarande stöder endast SQL Server 2022 (16.x) och senare versioner klustrad kolumnlagringsradgruppseliminering för prefixet
LIKEpredikat, till exempelcolumn LIKE 'string%'. Segmenteliminering stöds inte för icke-prefixanvändning av LIKE, till exempelcolumn LIKE '%string'.
Mer information finns i Nyheter i Columnstore-index.
Exempel
A. Så här söker du efter ordnade kolumner och ordningstal:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. Om du vill ändra kolumnordning lägger du till eller tar bort kolumner från orderlistan eller ändrar från CCI till ordnad CCI:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);