Azure Data Lake Storage frågeacceleration
Med frågeacceleration kan program och analysramverk dramatiskt optimera databearbetningen genom att bara hämta de data som krävs för att utföra en viss åtgärd. Detta minskar den tid och bearbetningskraft som krävs för att få viktiga insikter om lagrade data.
Översikt
Frågeacceleration accepterar filtreringspredikat och kolumnprojektioner, vilket gör det möjligt för program att filtrera rader och kolumner när data läse från disk. Endast de data som uppfyller villkoren för ett predikat överförs via nätverket till programmet. Detta minskar nätverksfördröjningen och beräkningskostnaden.
Du kan använda SQL för att ange radfilterpredikat och kolumnprojektioner i en begäran om frågeacceleration. En begäran bearbetar endast en fil. Därför stöds inte avancerade relationsfunktioner i SQL, till exempel kopplingar och gruppera efter aggregeringar. Frågeacceleration stöder CSV- och JSON-formaterade data som indata till varje begäran.
Funktionen för frågeacceleration är inte begränsad till Data Lake Storage (lagringskonton som har det hierarkiska namnområdet aktiverat på dem). Frågeacceleration är kompatibelt med blobarna i lagringskonton som inte har ett hierarkiskt namnområde aktiverat på dem. Det innebär att du kan uppnå samma minskning av nätverksfördröjningen och beräkningskostnaderna när du bearbetar data som du redan har lagrat som blobar på lagringskonton.
Ett exempel på hur du använder frågeacceleration i ett klientprogram finns i Filtrera data med hjälp av Azure Data Lake Storage frågeacceleration.
Dataflöde
Följande diagram illustrerar hur ett typiskt program använder frågeacceleration för att bearbeta data.
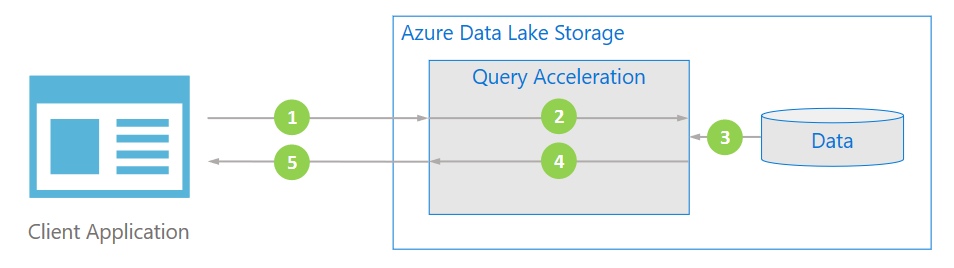
Klientprogrammet begär fildata genom att ange predikat och kolumnprojektioner.
Frågeacceleration parsar den angivna SQL-frågan och distribuerar arbete för att parsa och filtrera data.
Processorer läser data från disken, parsar data med lämpligt format och filtrerar sedan data genom att tillämpa de angivna predikaten och kolumnprojektionerna.
Frågeacceleration kombinerar svarsshards för att strömma tillbaka till klientprogrammet.
Klientprogrammet tar emot och parsar det strömmade svaret. Programmet behöver inte filtrera andra data och kan tillämpa den önskade beräkningen eller omvandlingen direkt.
Bättre prestanda till en lägre kostnad
Frågeacceleration optimerar prestanda genom att minska mängden data som överförs och bearbetas av ditt program.
För att beräkna ett aggregerat värde hämtar program ofta alla data från en fil och bearbetar och filtrerar sedan data lokalt. En analys av in- och utdatamönstren för analysarbetsbelastningar visar att program vanligtvis bara kräver 20 % av de data som de läser för att utföra en viss beräkning. Den här statistiken gäller även efter att du har tillämpat tekniker som partitionsrensning. Det innebär att 80 % av dessa data överförs i onödan över nätverket, parsas och filtreras av program. Det här mönstret, som är utformat för att ta bort onödiga data, medför en betydande beräkningskostnad.
Även om Azure har ett branschledande nätverk, både när det gäller dataflöde och svarstid, är det fortfarande dyrt att överföra data i nätverket i onödan för programprestanda. Genom att filtrera bort oönskade data under lagringsbegäran eliminerar frågeacceleration den här kostnaden.
Dessutom kräver cpu-belastningen som krävs för att parsa och filtrera onödiga data att programmet etablerar ett större antal och större virtuella datorer för att kunna utföra sitt arbete. Genom att överföra den här beräkningsbelastningen till frågeaccelerationen kan program göra betydande kostnadsbesparingar.
Program som kan dra nytta av frågeacceleration
Frågeacceleration är utformat för distribuerade analysramverk och databearbetningsprogram.
Distribuerade analysramverk som Apache Spark och Apache Hive innehåller ett lagringsabstraktionslager inom ramverket. De här motorerna innehåller även frågeoptimerare som kan ta med kunskap om den underliggande I/O-tjänstens funktioner när du fastställer en optimal frågeplan för användarfrågor. Dessa ramverk börjar integrera frågeacceleration. Därför ser användare av dessa ramverk förbättrad frågesvarstid och en lägre total ägandekostnad utan att behöva göra några ändringar i frågorna.
Frågeacceleration är också utformad för databearbetningsprogram. Dessa typer av program utför vanligtvis storskaliga datatransformeringar som kanske inte direkt leder till analysinsikter så att de inte alltid använder etablerade distribuerade analysramverk. Dessa program har ofta en mer direkt relation till den underliggande lagringstjänsten så att de kan dra direkt nytta av funktioner som frågeacceleration.
Ett exempel på hur ett program kan integrera frågeacceleration finns i Filtrera data med hjälp av Azure Data Lake Storage frågeacceleration.
Prissättning
På grund av den ökade beräkningsbelastningen i Azure Data Lake Storage-tjänsten skiljer sig prismodellen för att använda frågeacceleration från den normala Azure Data Lake Storage transaktionsmodellen. Frågeacceleration debiterar en kostnad för mängden data som genomsöks samt en kostnad för mängden data som returneras till anroparen. Mer information finns i Azure Data Lake Storage Gen2 prissättning.
Trots ändringen av faktureringsmodellen är frågeaccelerationens prismodell utformad för att sänka den totala ägandekostnaden för en arbetsbelastning, med tanke på minskningen av de mycket dyrare VM-kostnaderna.