Migrering av StorSimple 1200 till Azure File Sync
StorSimple 1200-serien är en virtuell installation som körs i ett lokalt datacenter. Det går att migrera data från den här installationen till en Azure File Sync miljö. Azure File Sync är den standardmässiga och strategiska långsiktiga Azure-tjänsten som StorSimple-apparater kan migreras till. Den här artikeln innehåller de nödvändiga kunskaps- och migreringsstegen för en lyckad migrering till Azure File Sync.
Anteckning
StorSimple-tjänsten (inklusive StorSimple-Enhetshanteraren för 8000- och 1200-serien och StorSimple Data Manager) har nått slutet av supporten. Supporten för StorSimple upphörde 2019 på sidorna Microsoft LifeCycle Policy och Azure Communications . Ytterligare meddelanden skickades via e-post och publicerades på Azure Portal och i StorSimple-översikten. Kontakta Microsoft Support om du vill ha mer information.
Gäller för
| Typ av filresurs | SMB | NFS |
|---|---|---|
| Standardfilresurser (GPv2), LRS/ZRS | ||
| Standardfilresurser (GPv2), GRS/GZRS | ||
| Premiumfilresurser (FileStorage), LRS/ZRS |
Azure File Sync
Azure File Sync är en Microsoft-molntjänst som baseras på två huvudkomponenter:
- Filsynkronisering och molnnivåindelning.
- Filresurser som intern lagring i Azure som kan nås via flera protokoll som SMB och fil-REST. En Azure-filresurs är jämförbar med en filresurs på en Windows Server som du kan montera internt som en nätverksenhet. Den stöder viktiga filåtergivningsaspekter som attribut, behörigheter och tidsstämplar. Till skillnad från StorSimple krävs inget program/tjänst för att tolka de filer och mappar som lagras i molnet. Den idealiska och mest flexibla metoden för att lagra allmänna filserverdata och vissa programdata i molnet.
Den här artikeln fokuserar på migreringsstegen. Om du vill veta mer om Azure File Sync innan du migrerar rekommenderar vi följande artiklar:
Migreringsmål
Målet är att garantera integriteten hos produktionsdata och garantera tillgänglighet. Det senare kräver att driftstoppet är så litet som möjligt, så att det får plats i eller bara något överskrider de regelbundna underhållsperioderna.
Migreringsvägen storSimple 1200 till Azure File Sync
En lokal Windows Server krävs för att köra en Azure File Sync agent. Windows Server kan vara minst en 2012R2-server, men helst är en Windows Server 2019.
Det finns många alternativa migreringsvägar och det skulle skapa för lång tid av en artikel för att dokumentera dem alla och illustrera varför de har risker eller nackdelar jämfört med den väg som vi rekommenderar som bästa praxis i den här artikeln.
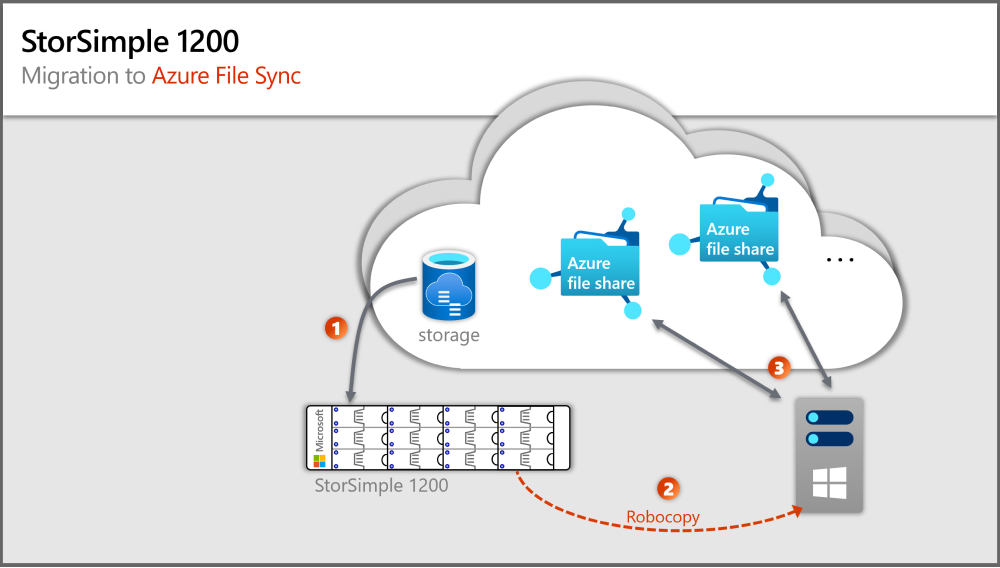
Föregående bild visar steg som motsvarar avsnitt i den här artikeln.
Steg 1: Etablera din lokala Windows Server och lagring
- Skapa en Windows Server 2019 – minst 2012R2 – som en virtuell dator eller fysisk server. Ett Redundanskluster för Windows Server stöds också.
- Etablera eller lägga till direktansluten lagring (DAS jämfört med NAS, som inte stöds). Storleken på Windows Server-lagringen måste vara lika med eller större än storleken på den tillgängliga kapaciteten för din virtuella StorSimple 1200-installation.
Steg 2: Konfigurera din Windows Server-lagring
I det här steget mappar du din StorSimple-lagringsstruktur (volymer och resurser) till din Windows Server-lagringsstruktur. Om du planerar att göra ändringar i lagringsstrukturen, vilket innebär antalet volymer, associationen av datamappar till volymer eller undermappsstrukturen ovanför eller under dina aktuella SMB/NFS-resurser, är det nu dags att ta hänsyn till dessa ändringar. Att ändra fil- och mappstrukturen efter att Azure File Sync har konfigurerats är besvärligt och bör undvikas. Den här artikeln förutsätter att du mappar 1:1, så du måste ta hänsyn till dina mappningsändringar när du följer stegen i den här artikeln.
- Ingen av dina produktionsdata ska hamna på Windows Server-systemvolymen. Molnnivåindelning stöds inte på systemvolymer. Den här funktionen krävs dock för migreringen samt kontinuerliga åtgärder som en StorSimple-ersättning.
- Etablera samma antal volymer på din Windows Server som du har på din virtuella StorSimple 1200-installation.
- Konfigurera alla Windows Server-roller, funktioner och inställningar som du behöver. Vi rekommenderar att du väljer Windows Server-uppdateringar för att hålla operativsystemet säkert och uppdaterat. På samma sätt rekommenderar vi att du väljer Microsoft Update för att hålla Microsoft-program uppdaterade, inklusive Azure File Sync-agenten.
- Konfigurera inte några mappar eller resurser innan du läser följande steg.
Steg 3: Distribuera den första Azure File Sync molnresursen
För att slutföra det här steget behöver du dina autentiseringsuppgifter för Azure-prenumerationen.
Kärnresursen som ska konfigureras för Azure File Sync kallas för en tjänst för synkronisering av lagring. Vi rekommenderar att du bara distribuerar en för alla servrar som synkroniserar samma uppsättning filer nu eller i framtiden. Skapa endast flera Synkroniseringstjänster för lagring om du har olika uppsättningar servrar som aldrig får utbyta data. Du kan till exempel ha servrar som aldrig får synkronisera samma Azure-filresurs. I annat fall är det bästa praxis att använda en enda tjänst för synkronisering av lagring.
Välj en Azure-region för lagringssynkroniseringstjänsten som är nära din plats. Alla andra molnresurser måste distribueras i samma region. För att förenkla hanteringen skapar du en ny resursgrupp i din prenumeration som innehåller synkroniserings- och lagringsresurser.
Mer information finns i avsnittet om hur du distribuerar tjänsten för synkronisering av lagring i artikeln om att distribuera Azure File Sync. Följ endast det här avsnittet i artikeln. Det finns länkar till andra avsnitt i artikeln i senare steg.
Steg 4: Matcha din lokala volym- och mappstruktur för att Azure File Sync och Azure-filresursresurser
I det här steget bestämmer du hur många Azure-filresurser du behöver. En enskild Windows Server-instans (eller ett kluster) kan synkronisera upp till 30 Azure-filresurser.
Du kan ha fler mappar på dina volymer som du för närvarande delar lokalt som SMB-resurser till dina användare och appar. Det enklaste sättet att föreställa sig det här scenariot är att föreställa sig en lokal resurs som mappar 1:1 till en Azure-filresurs. Om du har ett tillräckligt litet antal resurser, under 30 för en enda Windows Server-instans, rekommenderar vi en 1:1-mappning.
Om du har fler än 30 resurser är det ofta onödigt att mappa en lokal resurs 1:1 till en Azure-filresurs. Överväg följande alternativ.
Dela gruppering
Om personalavdelningen till exempel har 15 resurser kan du överväga att lagra alla HR-data i en enda Azure-filresurs. Att lagra flera lokala resurser i en Azure-filresurs hindrar dig inte från att skapa de vanliga 15 SMB-resurserna på din lokala Windows Server-instans. Det innebär bara att du ordnar rotmapparna för dessa 15 resurser som undermappar under en gemensam mapp. Sedan synkroniserar du den här gemensamma mappen till en Azure-filresurs. På så sätt behövs bara en enda Azure-filresurs i molnet för den här gruppen med lokala resurser.
Volymsynkronisering
Azure File Sync stöder synkronisering av roten på en volym till en Azure-filresurs. Om du synkroniserar volymroten går alla undermappar och filer till samma Azure-filresurs.
Att synkronisera volymens rot är inte alltid det bästa alternativet. Det finns fördelar med att synkronisera flera platser. Om du till exempel gör det kan du hålla antalet objekt lägre per synkroniseringsomfång. Vi testar Azure-filresurser och Azure File Sync med 100 miljoner objekt (filer och mappar) per resurs. Men bästa praxis är att försöka hålla antalet under 20 miljoner eller 30 miljoner i en enda andel. Det är inte bara bra att konfigurera Azure File Sync med ett lägre antal objekt för filsynkronisering. Ett lägre antal objekt har också fördelar med scenarier som dessa:
- Den första genomsökningen av molninnehållet kan slutföras snabbare, vilket i sin tur minskar väntan på att namnområdet ska visas på en server som är aktiverad för Azure File Sync.
- Återställning på molnsidan från en ögonblicksbild av en Azure-filresurs går snabbare.
- Haveriberedskapen för en lokal server kan påskyndas avsevärt.
- Ändringar som görs direkt i en Azure-filresurs (utanför synkroniseringen) kan identifieras och synkroniseras snabbare.
Tips
Om du inte vet hur många filer och mappar du har kan du kolla in verktyget TreeSize från JAM Software GmbH.
En strukturerad metod för en distributionskarta
Innan du distribuerar molnlagring i ett senare steg är det viktigt att skapa en karta mellan lokala mappar och Azure-filresurser. Den här mappningen informerar hur många och vilka Azure File Sync synkronisera gruppresurser som du ska etablera. En synkroniseringsgrupp kopplar ihop Azure-filresursen och mappen på servern och upprättar en synkroniseringsanslutning.
Information om hur många Azure-filresurser du behöver finns i följande begränsningar och metodtips. Om du gör det kan du optimera kartan.
En server där Azure File Sync agenten är installerad kan synkroniseras med upp till 30 Azure-filresurser.
En Azure-filresurs distribueras i ett lagringskonto. Det gör lagringskontot till ett skalningsmål för prestandanummer som IOPS och dataflöde.
Var uppmärksam på IOPS-begränsningarna för ett lagringskonto när du distribuerar Azure-filresurser. Helst bör du mappa filresurser 1:1 med lagringskonton. Detta kanske dock inte alltid är möjligt på grund av olika begränsningar, både från din organisation och från Azure. När det inte går att bara distribuera en filresurs i ett lagringskonto bör du överväga vilka resurser som kommer att vara mycket aktiva och vilka resurser som är mindre aktiva för att säkerställa att de hetaste filresurserna inte placeras i samma lagringskonto tillsammans.
Om du planerar att lyfta en app till Azure som ska använda Azure-filresursen internt kan du behöva mer prestanda från din Azure-filresurs. Om den här typen av användning är en möjlighet, även i framtiden, är det bäst att skapa en enda Standard Azure-filresurs i sitt eget lagringskonto.
Det finns en gräns på 250 lagringskonton per prenumeration per Azure-region.
Tips
Med den här informationen blir det ofta nödvändigt att gruppera flera mappar på den översta nivån på dina volymer i en ny gemensam rotkatalog. Sedan synkroniserar du den nya rotkatalogen och alla mappar som du grupperade i den till en enda Azure-filresurs. Med den här tekniken kan du hålla dig inom gränsen på 30 Azure-filresurssynkroniseringar per server.
Den här gruppering under en gemensam rot påverkar inte åtkomsten till dina data. Dina ACL:er stannar som de är. Du behöver bara justera eventuella resurssökvägar (till exempel SMB- eller NFS-resurser) som du kan ha på de lokala servermappar som du nu har ändrat till en gemensam rot. Inget annat ändras.
Viktigt
Den viktigaste skalningsvektorn för Azure File Sync är antalet objekt (filer och mappar) som behöver synkroniseras. Mer information finns i Azure File Sync skalningsmål.
Vi rekommenderar att du håller nere antalet objekt per synkroniseringsomfång. Det är en viktig faktor att tänka på när du mappar mappar till Azure-filresurser. Azure File Sync testas med 100 miljoner objekt (filer och mappar) per resurs. Men det är ofta bäst att hålla antalet objekt under 20 miljoner eller 30 miljoner i en enda aktie. Dela upp ditt namnområde i flera resurser om du börjar överskrida dessa siffror. Du kan fortsätta att gruppera flera lokala resurser i samma Azure-filresurs om du ligger ungefär under dessa siffror. Denna praxis ger dig utrymme att växa.
Det är möjligt att en uppsättning mappar i din situation logiskt kan synkroniseras till samma Azure-filresurs (med hjälp av den nya vanliga metoden för rotmappar som nämnts tidigare). Men det kan fortfarande vara bättre att gruppera om mappar så att de synkroniseras till två i stället för en Azure-filresurs. Du kan använda den här metoden för att hålla antalet filer och mappar per filresurs balanserade på servern. Du kan också dela upp dina lokala resurser och synkronisera mellan fler lokala servrar, vilket ger möjlighet att synkronisera med ytterligare 30 Azure-filresurser per extra server.
Vanliga scenarier och överväganden för filsynkronisering
| # | Synkroniseringsscenario | Stöds | Överväganden (eller begränsningar) | Lösning (eller lösning) |
|---|---|---|---|---|
| 1 | Filserver med flera diskar/volymer och flera resurser till samma Azure-målfilresurs (konsolidering) | No | En Azure-målfilresurs (molnslutpunkt) stöder endast synkronisering med en synkroniseringsgrupp. En synkroniseringsgrupp stöder bara en serverslutpunkt per registrerad server. |
1) Börja med att synkronisera en disk (dess rotvolym) med Azure-filresursen som mål. Från och med den största disken/volymen hjälper du till med lagringskraven lokalt. Konfigurera molnnivåindelning för att nivåindela alla data till molnet, vilket frigör utrymme på filserverdisken. Flytta data från andra volymer/resurser till den aktuella volymen som synkroniseras. Fortsätt stegen en i taget tills alla data är nivåindelade till molnet/migrerade. 2) Rikta en rotvolym (disk) i taget. Använd molnnivåindelning för att nivåindela alla data till azure-filresursens mål. Ta bort serverslutpunkten från synkroniseringsgruppen, återskapa slutpunkten med nästa rotvolym/disk, synkronisera och upprepa processen. Obs! Ominstallation av agenten kan krävas. 3) Rekommendera att du använder flera Azure-målfilresurser (samma eller ett annat lagringskonto baserat på prestandakrav) |
| 2 | Filserver med en enskild volym och flera resurser till samma Azure-målfilresurs (konsolidering) | Yes | Det går inte att ha flera serverslutpunkter per registrerad server som synkroniserar till samma Azure-målfilresurs (samma som ovan) | Synkronisera roten på volymen som innehåller flera resurser eller mappar på den översta nivån. Mer information finns i Dela grupperingskoncept och Volymsynkronisering . |
| 3 | Filserver med flera resurser och/eller volymer till flera Azure-filresurser under ett enda lagringskonto (mappning av 1:1-resurs) | Yes | En enskild Windows Server-instans (eller ett kluster) kan synkronisera upp till 30 Azure-filresurser. Ett lagringskonto är ett skalningsmål för prestanda. IOPS och dataflöde delas mellan filresurser. Behåll antalet objekt per synkroniseringsgrupp inom 100 miljoner objekt (filer och mappar) per resurs. Helst är det bäst att hålla sig under 20 eller 30 miljoner per aktie. |
1) Använd flera synkroniseringsgrupper (antal synkroniseringsgrupper = antalet Azure-filresurser att synkronisera med). 2) Endast 30 resurser kan synkroniseras i det här scenariot åt gången. Om du har fler än 30 resurser på filservern använder du konceptet Dela gruppering och Volymsynkronisering för att minska antalet rot- eller toppnivåmappar vid källan. 3) Använd ytterligare File Sync servrar lokalt och dela/flytta data till dessa servrar för att kringgå begränsningar på Windows-källservern. |
| 4 | Filserver med flera resurser och/eller volymer till flera Azure-filresurser under ett annat lagringskonto (1:1 resursmappning) | Yes | En enskild Windows Server-instans (eller ett kluster) kan synkronisera upp till 30 Azure-filresurser (samma eller ett annat lagringskonto). Behåll antalet objekt per synkroniseringsgrupp inom 100 miljoner objekt (filer och mappar) per resurs. Helst är det bäst att hålla sig under 20 eller 30 miljoner per aktie. |
Samma metod som ovan |
| 5 | Flera filservrar med en enda (rotvolym eller resurs) till samma Azure-målfilresurs (konsolidering) | No | En synkroniseringsgrupp kan inte använda molnslutpunkt (Azure-filresurs) som redan har konfigurerats i en annan synkroniseringsgrupp. Även om en synkroniseringsgrupp kan ha serverslutpunkter på olika filservrar kan filerna inte vara distinkta. |
Följ riktlinjerna i scenario nr 1 ovan med ytterligare överväganden om att rikta in sig på en filserver i taget. |
Skapa en mappningstabell

Använd föregående information för att avgöra hur många Azure-filresurser du behöver och vilka delar av dina befintliga data som hamnar i vilken Azure-filresurs.
Skapa en tabell som registrerar dina tankar så att du kan referera till den när du behöver det. Det är viktigt att hålla ordning eftersom det kan vara enkelt att förlora information om din mappningsplan när du etablerar många Azure-resurser samtidigt. Ladda ned följande Excel-fil som ska användas som mall för att skapa mappningen.

|
Ladda ned en mall för namnområdesmappning. |
Steg 5: Etablera Azure-filresurser
En Azure-filresurs lagras i molnet på ett Azure-lagringskonto. En annan nivå av prestandaöverväganden gäller här.
Om du har mycket aktiva resurser (resurser som används av många användare och/eller program) kan två Azure-filresurser nå prestandagränsen för ett lagringskonto.
Bästa praxis är att distribuera lagringskonton med en filresurs var. Du kan poola flera Azure-filresurser till samma lagringskonto om du har arkiveringsresurser eller om du förväntar dig låg daglig aktivitet i dem.
Dessa överväganden gäller mer för direkt molnåtkomst (via en virtuell Azure-dator) än för Azure File Sync. Om du planerar att endast använda Azure File Sync på dessa resurser fungerar det bra att gruppera flera i ett enda Azure Storage-konto.
Om du har skapat en lista över dina resurser bör du mappa varje resurs till lagringskontot som den kommer att finnas i.
I föregående fas fastställde du lämpligt antal resurser. I det här steget har du en mappning av lagringskonton till filresurser. Distribuera nu lämpligt antal Azure-lagringskonton med lämpligt antal Azure-filresurser i dem.
Kontrollera att regionen för vart och ett av dina lagringskonton är samma och matchar regionen för den Storage Sync Service-resurs som du redan har distribuerat.
Varning
Om du skapar en Azure-filresurs som har en gräns på 100 TiB kan resursen endast använda lokalt redundant lagring eller zonredundant lagringsredundans. Överväg dina lagringsredundansbehov innan du använder 100 TiB-filresurser.
Azure-filresurser skapas fortfarande med en gräns på 5 TiB som standard. Följ stegen i Skapa en Azure-filresurs för att skapa en stor filresurs.
Ett annat att tänka på när du distribuerar ett lagringskonto är redundansen för Azure Storage. Se Redundansalternativ för Azure Storage.
Namnen på dina resurser är också viktiga. Om du till exempel grupperar flera resurser för HR-avdelningen till ett Azure-lagringskonto bör du namnge lagringskontot på rätt sätt. På samma sätt bör du, när du namnger dina Azure-filresurser, använda namn som liknar de som används för deras lokala motsvarigheter.
Inställningar för lagringskonto
Det finns många konfigurationer som du kan göra på ett lagringskonto. Följande checklista bör användas för konfigurationen av lagringskontot. Du kan till exempel ändra nätverkskonfigurationen när migreringen är klar.
- Stora filresurser: Aktiverat – Stora filresurser förbättrar prestanda och gör att du kan lagra upp till 100TiB i en resurs.
- Brandvägg och virtuella nätverk: Inaktiverad – konfigurera inte några IP-begränsningar eller begränsa åtkomsten till lagringskontot till ett specifikt virtuellt nätverk. Lagringskontots offentliga slutpunkt används under migreringen. Alla IP-adresser från virtuella Azure-datorer måste tillåtas. Det är bäst att konfigurera brandväggsregler för lagringskontot efter migreringen.
- Privata slutpunkter: Stöds – Du kan aktivera privata slutpunkter, men den offentliga slutpunkten används för migreringen och måste vara tillgänglig.
Steg 6: Konfigurera Windows Server-målmappar
I föregående steg har du övervägt alla aspekter som avgör komponenterna i dina synkroniseringstopologier. Nu är det dags att förbereda servern för att ta emot filer för uppladdning.
Skapa alla mappar som synkroniserar var och en till sin egen Azure-filresurs. Det är viktigt att du följer mappstrukturen som du har dokumenterat tidigare. Om du till exempel har valt att synkronisera flera lokala SMB-resurser till en enda Azure-filresurs måste du placera dem i en gemensam rotmapp på volymen. Skapa den här målrotmappen på volymen nu.
Antalet Azure-filresurser som du har etablerat ska matcha antalet mappar som du har skapat i det här steget + antalet volymer som du ska synkronisera på rotnivå.
Steg 7: Distribuera Azure File Sync-agenten
I det här avsnittet installerar du Azure File Sync-agenten på din Windows Server-instans.
I distributionsguiden förklaras att du måste inaktivera Förbättrad säkerhetskonfiguration i Internet Explorer. Den här säkerhetsåtgärden gäller inte för Azure File Sync. Om du inaktiverar det kan du autentisera till Azure utan problem.
Öppna PowerShell. Installera nödvändiga PowerShell-moduler med hjälp av följande kommandon. Se till att installera den fullständiga modulen och NuGet-providern när du uppmanas att göra det.
Install-Module -Name Az -AllowClobber
Install-Module -Name Az.StorageSync
Om du har problem med att nå Internet från servern är det dags att lösa dem nu. Azure File Sync använder alla tillgängliga nätverksanslutningar till Internet. Det finns också stöd för att kräva att en proxyserver når Internet. Du kan antingen konfigurera en datoromfattande proxy nu eller, under agentinstallationen, ange en proxy som endast Azure File Sync ska använda.
Om konfigurationen av en proxy innebär att du måste öppna brandväggarna för servern kan den metoden vara acceptabel för dig. I slutet av serverinstallationen, när du har slutfört serverregistreringen, visar en rapport om nätverksanslutning de exakta slutpunkts-URL:er i Azure som Azure File Sync behöver kommunicera med för den region som du har valt. Rapporten visar också varför kommunikation behövs. Du kan använda rapporten för att låsa brandväggarna runt servern till specifika URL:er.
Du kan också använda en mer konservativ metod där du inte öppnar brandväggarna. Du kan i stället begränsa servern så att den kommunicerar med DNS-namnområden på högre nivå. Mer information finns i Azure File Sync proxy- och brandväggsinställningar. Följ dina egna metodtips för nätverk.
I slutet av serverinstallationsguiden öppnas en guide för serverregistrering. Registrera servern till Storage Sync-tjänstens Azure-resurs från tidigare.
De här stegen beskrivs mer detaljerat i distributionsguiden, som innehåller De PowerShell-moduler som du bör installera först: Azure File Sync agentinstallation.
Använd den senaste agenten. Du kan ladda ned den från Microsoft Download Center: Azure File Sync Agent.
Efter en lyckad installation och serverregistrering kan du bekräfta att du har slutfört det här steget. Gå till storage sync service-resursen i Azure Portal. I den vänstra menyn går du till Registrerade servrar. Servern visas där.
Steg 8: Konfigurera synkronisering
Det här steget kopplar ihop alla resurser och mappar som du har konfigurerat på din Windows Server-instans under föregående steg.
- Logga in på Azure-portalen.
- Leta upp resursen för tjänsten för synkronisering av lagring.
- Skapa en ny synkroniseringsgrupp i Storage Sync Service-resursen för varje Azure-filresurs. I Azure File Sync terminologi blir Azure-filresursen en molnslutpunkt i synkroniseringstopologin som du beskriver när du skapar en synkroniseringsgrupp. När du skapar synkroniseringsgruppen ger du den ett bekant namn så att du känner igen vilken uppsättning filer som synkroniseras där. Se till att du refererar till Azure-filresursen med ett matchande namn.
- När du har skapat synkroniseringsgruppen visas en rad för den i listan över synkroniseringsgrupper. Välj namnet (en länk) för att visa innehållet i synkroniseringsgruppen. Du ser din Azure-filresurs under Molnslutpunkter.
- Leta upp knappen Lägg till serverslutpunkt . Mappen på den lokala server som du har etablerat blir sökvägen till den här serverslutpunkten.
Varning
Se till att aktivera molnnivåindelning! Detta krävs om den lokala servern inte har tillräckligt med utrymme för att lagra den totala storleken på dina data i StorSimple-molnlagringen. Ange din nivåindelningsprincip, tillfälligt för migreringen, till 99 % ledigt utrymme på volymen.
Upprepa stegen för att skapa en synkroniseringsgrupp och lägga till den matchande servermappen som en serverslutpunkt för alla Azure-filresurser/serverplatser som måste konfigureras för synkronisering.
Steg 9: Kopiera dina filer
Den grundläggande migreringsmetoden är en RoboCopy från din virtuella StorSimple-installation till Din Windows Server och Azure File Sync till Azure-filresurser.
Kör den första lokala kopian till Windows Server-målmappen:
- Identifiera den första platsen på din virtuella StorSimple-installation.
- Identifiera den matchande mappen på Windows Server, som redan har Azure File Sync konfigurerad på den.
- Starta kopian med RoboCopy
Följande RoboCopy-kommando återkallar filer från Din StorSimple Azure-lagring till din lokala StorSimple och flyttar dem sedan över till Målmappen för Windows Server. Windows Server synkroniserar den med Azure-filresurserna. När den lokala Windows Server-volymen blir full kommer molnnivåindelningen att sätta igång och nivåindela filer som redan har synkroniserats. Molnnivåindelning genererar tillräckligt med utrymme för att fortsätta kopieringen från den virtuella StorSimple-installationen. Molnnivåindelningen kontrollerar en gång i timmen vad som har synkroniserats och frigör diskutrymme för att nå 99 % ledigt utrymme på volymen.
robocopy <SourcePath> <Dest.Path> /MT:20 /R:2 /W:1 /B /MIR /IT /COPY:DATSO /DCOPY:DAT /NP /NFL /NDL /XD "System Volume Information" /UNILOG:<FilePathAndName>
| Switch | Innebörd |
|---|---|
/MT:n |
Gör att Robocopy kan köras multitrådat. Standardvärdet för n är 8. Maxvärdet är 128 trådar. Även om ett högt antal trådar hjälper till att mätta den tillgängliga bandbredden betyder det inte att migreringen alltid kommer att gå snabbare med fler trådar. Tester med Azure Files anger mellan 8 och 20 visar balanserade prestanda för en första kopieringskörning. Efterföljande /MIR körningar påverkas progressivt av tillgänglig beräkning jämfört med tillgänglig nätverksbandbredd. Vid efterföljande körningar matchar du värdet för antal trådar närmare mot antalet processorkärnor och antalet trådar per kärna. Överväg om kärnor måste reserveras för andra uppgifter som en produktionsserver kan utföra. Tester med Azure Files har visat att upp till 64 trådar ger bra prestanda, men bara om processorerna kan hålla dem vid liv samtidigt. |
/R:n |
Maximalt antal omförsök för en fil som inte kan kopieras vid första försöket. Robocopy kommer att försöka n gånger innan filen permanent misslyckas med att kopiera i körningen. Du kan optimera körningens prestanda: Välj ett värde på två eller tre om du tror att tidsgränsproblem orsakade tidigare fel. Detta kan vara vanligare via WAN-länkar. Välj inget nytt försök eller ett värde om du tror att filen inte kunde kopieras eftersom den användes aktivt. Att försöka igen några sekunder senare kanske inte räcker för att filens användningstillstånd ska ändras. Användare eller appar som håller filen öppen kan behöva timmar mer tid. I det här fallet kan du acceptera att filen inte kopierades och fånga den i någon av dina planerade, efterföljande Robocopy-körningar, så småningom lyckas kopiera filen. Det hjälper den aktuella körningen att slutföras snabbare utan att förlängas av många återförsök som i slutändan hamnar i en majoritet av kopieringsfelen på grund av att filer fortfarande är öppna efter tidsgränsen för återförsök. |
/W:n |
Anger hur länge Robocopy ska vänta innan du försöker kopiera en fil som inte gick att kopiera under ett tidigare försök. n är antalet sekunder som ska vänta mellan återförsök. /W:n används ofta tillsammans med /R:n. |
/B |
Kör Robocopy i samma läge som ett säkerhetskopieringsprogram skulle använda. Med den här växeln kan Robocopy flytta filer som den aktuella användaren inte har behörighet för. Säkerhetskopieringsväxeln är beroende av att du kör Robocopy-kommandot i en upphöjd administratörskonsol eller Ett PowerShell-fönster. Om du använder Robocopy för Azure Files ska du montera Azure-filresursen med hjälp av lagringskontots åtkomstnyckel jämfört med en domänidentitet. Om du inte gör det kanske felmeddelandena inte intuitivt leder dig till en lösning av problemet. |
/MIR |
(Segla källan till målet.) Gör att Robocopy bara kan kopiera delta mellan källa och mål. Tomma underkataloger kopieras. Objekt (filer eller mappar) som har ändrats eller inte finns på målet kopieras. Objekt som finns på målet men inte på källan rensas (tas bort) från målet. När du använder den här växeln matchar du källans och målets mappstruktur exakt. Matchning innebär att kopiera från rätt käll- och mappnivå till den matchande mappnivån på målet. Först då kan en ”catch up”-kopiering lyckas. När källan och målet är felmatchade leder användningen /MIR till storskaliga borttagningar och omkopior. |
/IT |
Ser till att naturtrogen återgivning bevaras i vissa speglingsscenarier. Om en fil till exempel får en ACL-ändring och en attributuppdatering mellan två Robocopy-körningar markeras den som dold. Utan /ITkan ACL-ändringen missas av Robocopy och inte överföras till målplatsen. |
/COPY:[copyflags] |
Filkopieringens naturtrogna återgivning. Standard: /COPY:DAT. Kopiera flaggor: D= Data, A= Attribut, T= Tidsstämplar, S= Säkerhet = NTFS ACL:er, O= Ägarinformation, U= Auditing information. Granskningsinformation kan inte lagras i en Azure-filresurs. |
/DCOPY:[copyflags] |
Återgivning för kopian av kataloger. Standard: /DCOPY:DA. Kopiera flaggor: D= Data, A= Attribut, T= Tidsstämplar. |
/NP |
Anger att kopieringsförloppet för varje fil och mapp inte visas. Om du visar förloppet får du betydligt läge prestanda. |
/NFL |
Anger att filnamn inte ska loggas. Ger bättre kopieringsprestanda. |
/NDL |
Anger att katalognamn inte ska loggas. Ger bättre kopieringsprestanda. |
/XD |
Anger kataloger som ska undantas. När du kör Robocopy i roten på en volym bör du överväga att undanta den dolda System Volume Information mappen. Om den används som den är utformad är all information där inne specifik för den exakta volymen på det här exakta systemet och kan återskapas på begäran. Att kopiera den här informationen är inte användbart i molnet eller när data någonsin kopieras tillbaka till en annan Windows-volym. Att lämna kvar det här innehållet bör inte betraktas som dataförlust. |
/UNILOG:<file name> |
Skriver status till loggfilen som Unicode. (Skriver över den befintliga loggen.) |
/L |
Endast för en testkörning Filer ska endast visas. De kopieras inte, tas inte bort och får inga tidsstämplar. Används ofta med /TEE för konsolutdata. Flaggor från exempelskriptet, som /NP, /NFLoch /NDL, kan behöva tas bort för att uppnå korrekt dokumenterade testresultat. |
/LFSM |
Endast för mål med nivåindelad lagring. Stöds inte när målet är en fjärransluten SMB-resurs. Anger att Robocopy fungerar i läget "låg ledigt utrymme". Den här växeln är endast användbar för mål med nivåindelad lagring som kan få slut på lokal kapacitet innan Robocopy slutförs. Den har lagts till specifikt för användning med mål som är aktiverade för molnnivåindelning i Azure File Sync. Den kan användas oberoende av Azure File Sync. I det här läget pausar Robocopy när en filkopiering skulle få målvolymens lediga utrymme att hamna under ett lägsta värde. Det här värdet kan anges med /LFSM:n flaggans form. Parametern n anges i bas 2: nKB, nMBeller nGB. Om /LFSM anges utan explicit golvvärde anges golvet till 10 procent av målvolymens storlek. Läget för lågt ledigt utrymme är inte kompatibelt med /MT, /EFSRAWeller /ZB. Stöd för /B har lagts till i Windows Server 2022. Mer information om en relaterad bugg och lösning finns i avsnittet Windows Server 2022 och RoboCopy LFSM nedan. |
/Z |
Använd försiktigt Kopierar filer i omstartsläge. Du bör bara använda den här växeln i en instabil nätverksmiljö. Den ber betydligt sämre kopieringsprestanda på grund av den extra loggningen. |
/ZB |
Använd försiktigt Använder omstartsläge. Om åtkomst nekas använder det här alternativet omstartsläge. Det här alternativet ger betydligt sämre kopieringsprestanda på grund av kontrollpunkterna. |
Viktigt
Vi rekommenderar att du använder en Windows Server 2022. När du använder en Windows Server 2019 ska du se till att den senaste korrigeringsnivån eller minst OS-uppdateringen KB5005103 är installerad. Den innehåller viktiga korrigeringar för vissa Robocopy-scenarier.
När du kör RoboCopy-kommandot för första gången kommer dina användare och program fortfarande åt StorSimple-filer och -mappar och kan eventuellt ändra det. Det är möjligt att RoboCopy har bearbetat en katalog, går vidare till nästa och sedan en användare på källplatsen (StorSimple) lägger till, ändrar eller tar bort en fil som nu inte kommer att bearbetas i den aktuella RoboCopy-körningen. Det är okej.
Den första körningen handlar om att flytta tillbaka huvuddelen av data till en lokal plats, över till din Windows Server och säkerhetskopiera till molnet via Azure File Sync. Detta kan ta lång tid, beroende på:
- din nedladdningsbandbredd
- återkallandehastigheten för StorSimple-molntjänsten
- uppladdningsbandbredden
- antalet objekt (filer och mappar) som behöver bearbetas av någon av tjänsterna
När den första körningen är klar kör du kommandot igen.
Den andra gången slutförs den snabbare, eftersom den bara behöver transportera ändringar som har inträffat sedan den senaste körningen. Dessa ändringar är sannolikt redan lokala för StorSimple, eftersom de är nya. Det minskar ytterligare tiden eftersom behovet av återkallande från molnet minskar. Under den andra körningen kan fortfarande nya ändringar ackumuleras.
Upprepa den här processen tills du är nöjd med att den tid det tar att slutföra är en acceptabel stilleståndstid.
När du anser att stilleståndstiden är acceptabel och du är beredd att ta StorSimple-platsen offline gör du det nu: Ta till exempel bort SMB-resursen så att ingen användare kan komma åt mappen eller vidta andra lämpliga steg som förhindrar att innehåll ändras i den här mappen på StorSimple.
Kör en sista RoboCopy-runda. Detta hämtar eventuella ändringar som kan ha missats. Hur lång tid det här sista steget tar beror på roboCopy-genomsökningens hastighet. Du kan beräkna tiden (som är lika med stilleståndstiden) genom att mäta hur lång tid den föregående körningen tog.
Skapa en resurs i Windows Server-mappen och eventuellt justera DFS-N-distributionen så att den pekar på den. Se till att ange samma behörigheter på resursnivå som på StorSimple SMB-resursen.
Du har migrerat en resurs/grupp med resurser till en gemensam rot eller volym. (Beroende på vad du mappade och bestämde att du behövde gå till samma Azure-filresurs.)
Du kan försöka köra några av dessa kopior parallellt. Vi rekommenderar att du bearbetar omfånget för en Azure-filresurs i taget.
Varning
När du har flyttat alla data från StorSimple till Windows Server och migreringen är klar: Gå tillbaka till alla synkroniseringsgrupper i Azure Portal och justera värdet för ledigt utrymme för molnnivåindelning till något som passar bättre för cacheanvändning, till exempel 20 %.
Principen för ledigt utrymme på molnnivånivå fungerar på volymnivå med potentiellt flera serverslutpunkter som synkroniseras från den. Om du glömmer att justera det lediga utrymmet på en serverslutpunkt fortsätter synkroniseringen att tillämpa den mest restriktiva regeln och försöker behålla 99 % ledigt diskutrymme, vilket gör att den lokala cachen inte fungerar som förväntat. Såvida det inte är ditt mål att bara ha namnområdet för en volym som bara innehåller sällan använda arkiveringsdata.
Felsöka
Det mest sannolika problemet du kan stöta på är att RoboCopy-kommandot misslyckas med "Full volym" på Windows Server-sidan. Om så är fallet är nedladdningshastigheten förmodligen bättre än din uppladdningshastighet. Molnnivåindelning fungerar en gång i timmen för att evakuera innehåll från den lokala Windows Server-disken som har synkroniserats.
Låt synkroniseringsframsteg och molnnivåindelning frigöra diskutrymme. Du kan se att i Utforskaren på Din Windows Server.
Om Windows Server har tillräckligt med tillgänglig kapacitet kan du lösa problemet genom att köra kommandot igen. Inget går sönder när du kommer in i den här situationen och du kan gå vidare med självförtroende. Besväret med att köra kommandot igen är den enda konsekvensen.
Du kan också stöta på andra Azure File Sync problem. Om det händer kan du läsa felsökningsguiden för Azure File Sync.
Hastigheten och framgångsgraden för en viss RoboCopy-körning beror på flera faktorer:
- IOPS på käll- och mållagringen
- tillgänglig nätverksbandbredd mellan källa och mål
- möjlighet att snabbt bearbeta filer och mappar i ett namnområde
- antalet ändringar mellan RoboCopy-körningar
- storleken och antalet filer som du behöver kopiera
Överväganden för IOPS och bandbredd
I den här kategorin måste du överväga kapaciteten hos källlagringen, mållagringen och nätverket som ansluter dem. Det maximala möjliga dataflödet bestäms av den långsammaste av dessa tre komponenter. Kontrollera att nätverksinfrastrukturen är konfigurerad för att stödja optimal överföringshastighet efter bästa förmåga.
Varning
Även om det ofta är mest önskvärt att kopiera så snabbt som möjligt bör du överväga att använda ditt lokala nätverk och NAS-installationer för andra, ofta affärskritiska uppgifter.
Kopiering så snabbt som möjligt kanske inte är önskvärt när det finns en risk att migreringen kan monopolisera tillgängliga resurser.
- Tänk på när det är bäst i din miljö att köra migreringar: under dagen, utanför arbetstid eller under helger.
- Överväg också att använda QoS för nätverk på en Windows Server för att begränsa RoboCopy-hastigheten.
- Undvik onödigt arbete för migreringsverktygen.
RoboCopy kan infoga fördröjningar mellan paket genom att ange växeln /IPG:n där n mäts i millisekunder mellan RoboCopy-paket. Med den här växeln kan du undvika monopolisering av resurser på både I/O-begränsade enheter och trånga nätverkslänkar.
/IPG:n kan inte användas för exakt nätverksbegränsning till en viss Mbit/s. Använd Windows Server Network QoS i stället. RoboCopy är helt beroende av SMB-protokollet för alla nätverksbehov. Att använda SMB är anledningen till att RoboCopy inte kan påverka själva nätverkets dataflöde, men det kan göra användningen långsammare.
En liknande tanke gäller för den IOPS som observerats på NAS. Klusterstorleken på NAS-volymen, paketstorlekarna och en matris med andra faktorer påverkar den observerade IOPS. Att införa fördröjning mellan paket är ofta det enklaste sättet att kontrollera belastningen på NAS:n. Testa flera värden, till exempel från cirka 20 millisekunder (n=20) till multiplar av det talet. När du har introducerat en fördröjning kan du utvärdera om dina andra appar nu kan fungera som förväntat. Med den här optimeringsstrategin kan du hitta den optimala RoboCopy-hastigheten i din miljö.
Bearbetningshastighet
RoboCopy bläddrar igenom det namnområde som det pekar på och utvärderar varje fil och mapp för kopiering. Varje fil utvärderas under en första kopia och under upphämtningskopior. Till exempel upprepade körningar av RoboCopy /MIR mot samma käll- och mållagringsplatser. Dessa upprepade körningar är användbara för att minimera stilleståndstiden för användare och appar och för att förbättra den övergripande framgångsgraden för migrerade filer.
Vi betraktar ofta bandbredd som den mest begränsande faktorn i en migrering , och det kan vara sant. Men möjligheten att räkna upp ett namnområde kan påverka den totala tiden att kopiera ännu mer för större namnområden med mindre filer. Tänk på att kopiering av 1 TiB av små filer tar betydligt längre tid än att kopiera 1 TiB med färre men större filer, förutsatt att alla andra variabler förblir desamma. Därför kan du uppleva långsam överföring om du migrerar ett stort antal små filer. Det här beteendet är förväntat.
Orsaken till den här skillnaden är den bearbetningskraft som krävs för att gå igenom ett namnområde. RoboCopy stöder flertrådade kopior via parametern /MT:n där n står för antalet trådar som ska användas. När du etablerar en dator specifikt för RoboCopy bör du överväga antalet processorkärnor och deras relation till antalet trådar som de tillhandahåller. De vanligaste är två trådar per kärna. Kärn- och trådantalet för en dator är en viktig datapunkt för att bestämma vilka flertrådsvärden /MT:n du ska ange. Tänk också på hur många RoboCopy-jobb du planerar att köra parallellt på en viss dator.
Fler trådar kopierar vårt 1-TiB-exempel på små filer betydligt snabbare än färre trådar. Samtidigt kanske den extra resursinvesteringen på våra 1 TiB av större filer inte ger proportionella fördelar. Ett högt antal trådar försöker kopiera fler av de stora filerna över nätverket samtidigt. Den här extra nätverksaktiviteten ökar sannolikheten för att begränsas av dataflöde eller lagrings-IOPS.
Under en första RoboCopy till ett tomt mål eller en differentiell körning med många ändrade filer begränsas du troligen av nätverkets dataflöde. Börja med ett stort antal trådar i den första körningen. Ett högt antal trådar, även utöver dina tillgängliga trådar på datorn, hjälper till att mätta den tillgängliga nätverksbandbredden. Efterföljande /MIR-körningar påverkas progressivt av bearbetning av objekt. Färre ändringar i en differentiell körning innebär mindre dataöverföring över nätverket. Din hastighet är nu mer beroende av din möjlighet att bearbeta namnområdesobjekt än att flytta dem via nätverkslänken. För efterföljande körningar matchar du värdet för antal trådar med antalet processorkärnor och antalet trådar per kärna. Överväg om kärnor måste reserveras för andra uppgifter som en produktionsserver kan ha.
Tips
Tumregel: Den första RoboCopy-körningen, som flyttar mycket data i ett nätverk med högre svarstid, drar nytta av överetablering av antalet trådar (/MT:n). Efterföljande körningar kopierar färre skillnader och du är mer benägna att flytta från nätverkets dataflöde begränsat till beräkningsbegränsat. Under dessa omständigheter är det ofta bättre att matcha Antalet RoboCopy-trådar med de faktiskt tillgängliga trådarna på datorn. Överetablering i det scenariot kan leda till fler kontextförskjutningar i processorn, vilket kan göra din kopia långsammare.
Undvik onödigt arbete
Undvik storskaliga ändringar i namnområdet. Till exempel att flytta filer mellan kataloger, ändra egenskaper i stor skala eller ändra behörigheter (NTFS-ACL:er). Särskilt ACL-ändringar kan ha stor inverkan eftersom de ofta har en sammanhängande ändringseffekt på filer längre ned i mapphierarkin. Konsekvenserna kan vara:
- utökad Körningstid för RoboCopy-jobb eftersom varje fil och mapp som påverkas av en ACL-ändring behöver uppdateras
- återanvändning av data som flyttats tidigare kan behöva kopieras på nytt. Till exempel måste mer data kopieras när mappstrukturer ändras efter att filer redan har kopierats tidigare. Ett RoboCopy-jobb kan inte "spela upp" en namnområdesändring. Nästa jobb måste rensa filerna som tidigare transporterats till den gamla mappstrukturen och ladda upp filerna i den nya mappstrukturen igen.
En annan viktig aspekt är att använda RoboCopy-verktyget på ett effektivt sätt. Med det rekommenderade RoboCopy-skriptet skapar och sparar du en loggfil för fel. Kopieringsfel kan inträffa – det är normalt. Dessa fel gör det ofta nödvändigt att köra flera rundor av ett kopieringsverktyg som RoboCopy. En första körning, till exempel från en NAS till DataBox eller en server till en Azure-filresurs. Och en eller flera extra körningar med /MIR-växeln för att fånga och försöka igen filer som inte kopieras.
Du bör vara beredd på att köra flera rundor av RoboCopy mot ett angivet namnområdesomfång. Efterföljande körningar slutförs snabbare eftersom de har mindre att kopiera, men begränsas i allt högre grad av bearbetningshastigheten för namnområdet. När du kör flera rundor kan du påskynda varje runda genom att inte låta RoboCopy försöka orimligt hårt för att kopiera allt i en viss körning. Dessa RoboCopy-växlar kan göra stor skillnad:
/R:nn = hur ofta du försöker kopiera en misslyckad fil och/W:nn = hur många sekunder som ska vänta mellan återförsök
/R:5 /W:5 är en rimlig inställning som du kan anpassa dig efter dina önskemål. I det här exemplet görs ett nytt försök med en misslyckad fil, med fem sekunders väntetid mellan återförsök. Om filen fortfarande inte kan kopieras försöker nästa RoboCopy-jobb igen. Filer som misslyckades på grund av att de används eller på grund av timeout-problem kan så småningom kopieras på det här sättet.
Windows Server 2022 och RoboCopy LFSM
RoboCopy-växeln /LFSM kan användas för att undvika att ett RoboCopy-jobb misslyckas med ett fullständigt volymfel . RoboCopy pausar när en filkopia gör att målvolymens lediga utrymme hamnar under värdet "floor".
Använd RoboCopy med Windows Server 2022. Endast den här versionen av RoboCopy innehåller viktiga felkorrigeringar och funktioner som gör växeln kompatibel med ytterligare flaggor som behövs i de flesta migreringar. Till exempel kompatibilitet med /B flaggan.
/B kör RoboCopy i samma läge som ett säkerhetskopieringsprogram skulle använda. Med den här växeln kan RoboCopy flytta filer som den aktuella användaren inte har behörighet för.
Normalt kan RoboCopy köras på källan, målet eller en tredje dator.
Viktigt
Om du tänker använda /LFSMmåste RoboCopy köras på målservern för Windows Server 2022 Azure File Sync.
Observera också att med /LFSM måste du också använda en lokal sökväg för målet, inte en UNC-sökväg. Som målsökväg bör du till exempel använda E:\Foldername i stället för en UNC-sökväg som \\ServerName\FolderName.
Varning
Den tillgängliga versionen av RoboCopy på Windows Server 2022 har en bugg som gör att pauserna räknas mot antalet fel per fil. Använd följande lösning.
De rekommenderade /R:2 /W:1 flaggorna ökar sannolikheten för att en fil misslyckas på grund av en /LFSM inducerad paus. I det här exemplet kommer en fil som inte kopierats efter tre pauser på grund av /LFSM att pausen orsakades att RoboCopy felaktigt misslyckas med filen. Lösningen för detta är att använda högre värden för /R:n och /W:n. Ett bra exempel är /R:10 /W:1800 (10 återförsök på 30 minuter vardera). Detta bör ge Azure File Sync nivåindelningsalgoritmen tid att skapa utrymme på målvolymen.
Den här buggen har åtgärdats men korrigeringen är ännu inte offentligt tillgänglig. I det här stycket finns uppdateringar om korrigeringens tillgänglighet och hur du distribuerar den.
Anteckning
Har du fortfarande frågor eller har du stött på problem?
Vi är här för att hjälpa till: 
Relevanta länkar
Migreringsinnehåll:
Azure File Sync innehåll: