Azure Synapse Data Explorer översikt över datainmatning (förhandsversion)
Datainmatning är den process som används för att läsa in dataposter från en eller flera källor för att importera data till en tabell i Azure Synapse Data Explorer pool. När data har matats in blir de tillgängliga för frågor.
Den Azure Synapse Data Explorer datahanteringstjänsten, som ansvarar för datainmatning, implementerar följande process:
- Hämtar data i batchar eller direktuppspelning från en extern källa och läser begäranden från en väntande Azure-kö.
- Batchdata som flödar till samma databas och tabell är optimerade för dataflöde för inmatning.
- Inledande data verifieras och formatet konverteras vid behov.
- Ytterligare datamanipulering, inklusive matchande schema, organisering, indexering, kodning och komprimering av data.
- Data sparas i lagring enligt den angivna kvarhållningsprincipen.
- Inmatade data checkas in i motorn, där det är tillgängligt för frågor.
Dataformat, egenskaper och behörigheter som stöds
Inmatningsegenskaper: De egenskaper som påverkar hur data matas in (till exempel taggning, mappning, skapandetid).
Behörigheter: För att mata in data kräver processen behörigheter på databasnivå. Andra åtgärder, till exempel fråga, kan kräva behörigheter som databasadministratör, databasanvändare eller tabelladministratör.
Batchbearbetning jämfört med strömmande inmatningar
Batchinmatning utför databatchbearbetning och är optimerad för dataflöde med hög inmatning. Den här metoden är den bästa och mest högpresterande typen av inmatning. Data batchas enligt inmatningsegenskaper. Små batchar med data sammanfogas och optimeras för snabba frågeresultat. Inmatningsbatchprincipen kan anges för databaser eller tabeller. Som standard är det maximala batchvärdet 5 minuter, 1 000 objekt eller en total storlek på 1 GB. Datastorleksgränsen för ett kommando för batchinmatning är 4 GB.
Direktuppspelningsinmatning är pågående datainmatning från en strömmande källa. Direktuppspelningsinmatning möjliggör svarstid i nära realtid för små datauppsättningar per tabell. Data matas ursprungligen in i radarkivet och flyttas sedan till kolumnlagringsutbredningar.
Inmatningsmetoder och verktyg
Azure Synapse Data Explorer stöder flera inmatningsmetoder, var och en med sina egna målscenarier. Dessa metoder omfattar inmatningsverktyg, anslutningsappar och plugin-program till olika tjänster, hanterade pipelines, programmatisk inmatning med hjälp av SDK:er och direkt åtkomst till inmatning.
Inmatning med hanterade pipelines
För organisationer som vill ha hantering (begränsning, återförsök, övervakare, aviseringar med mera) som utförs av en extern tjänst är det troligtvis den lämpligaste lösningen att använda en anslutningsapp. Köad inmatning är lämplig för stora datavolymer. Azure Synapse Data Explorer stöder följande Azure Pipelines:
- Händelsehubb: En pipeline som överför händelser från tjänster till Azure Synapse Data Explorer. Mer information finns i Mata in data från Event Hub till Azure Synapse Data Explorer.
- Synapse-pipelines: En fullständigt hanterad dataintegreringstjänst för analysarbetsbelastningar i Synapse-pipelines ansluter till över 90 källor som stöds för att tillhandahålla effektiv och elastisk dataöverföring. Synapse-pipelines förbereder, transformerar och berikar data för att ge insikter som kan övervakas på olika sätt. Den här tjänsten kan användas som en engångslösning, på en periodisk tidslinje eller utlösas av specifika händelser.
Programmatisk inmatning med SDK:er
Azure Synapse Data Explorer tillhandahåller SDK:er som kan användas för fråge- och datainmatning. Programmatisk inmatning är optimerad för att minska inmatningskostnaderna genom att minimera lagringstransaktioner under och efter inmatningsprocessen.
Innan du börjar använder du följande steg för att hämta Data Explorer-poolslutpunkter för att konfigurera programmatisk inmatning.
I Synapse Studio väljer du Hantera>Data Explorer pooler i fönstret till vänster.
Välj den Data Explorer pool som du vill använda för att visa dess information.
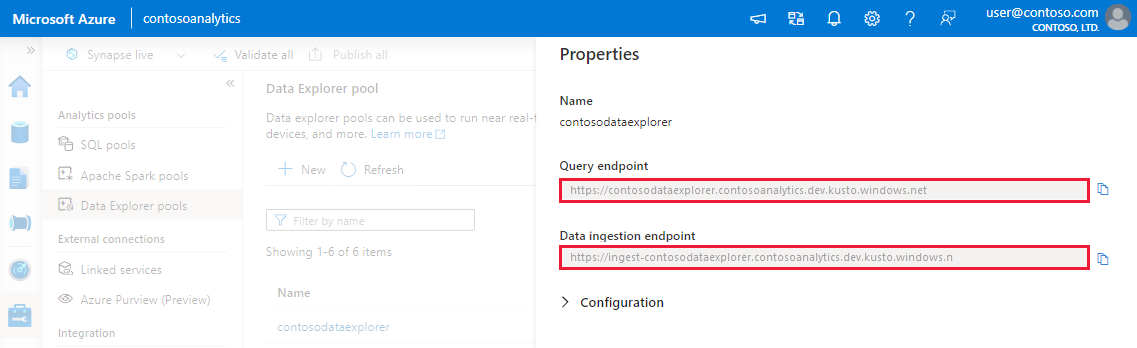
Anteckna fråge- och datainmatningsslutpunkterna. Använd frågeslutpunkten som kluster när du konfigurerar anslutningar till din Data Explorer pool. När du konfigurerar SDK:er för datainmatning använder du slutpunkten för datainmatning.
Tillgängliga SDK:er och projekt med öppen källkod
Verktyg
- Inmatning med ett klick: Gör att du snabbt kan mata in data genom att skapa och justera tabeller från en mängd olika källtyper. Inmatning med ett klick föreslår automatiskt tabeller och mappningsstrukturer baserat på datakällan i Azure Synapse Data Explorer. Inmatning med ett klick kan användas för engångsinmatning eller för att definiera kontinuerlig inmatning via Event Grid i containern som data matades in till.
Kusto-frågespråk mata in kontrollkommandon
Det finns ett antal metoder som gör att data kan matas in direkt till motorn med Kusto-frågespråk -kommandon (KQL). Eftersom den här metoden kringgår Datahantering tjänster är den bara lämplig för utforskning och prototyper. Använd inte den här metoden i produktions- eller högvolymscenarier.
Infogad inmatning: Ett kontrollkommando .ingest infogas skickas till motorn, där de data som ska matas in är en del av själva kommandotexten. Den här metoden är avsedd för improviserad testning.
Mata in från fråga: Ett kontrollkommando .set, .append, .set-or-append eller .set-or-replace skickas till motorn, med de data som anges indirekt som resultat av en fråga eller ett kommando.
Mata in från lagring (pull): Ett kontrollkommando .ingest i skickas till motorn, med data lagrade i viss extern lagring (till exempel Azure Blob Storage) som är tillgängliga för motorn och pekas ut av kommandot.
Ett exempel på hur du använder inmatningskontrollkommandon finns i Analysera med Data Explorer.
Inmatningsprocess
När du har valt den lämpligaste inmatningsmetoden för dina behov gör du följande:
Ange kvarhållningsprincip
Data som matas in i en tabell i Azure Synapse Data Explorer omfattas av tabellens effektiva kvarhållningsprincip. Den gällande kvarhållningsprincipen härleds från databasens kvarhållningsprincip såvida den inte anges explicit för en tabell. Frekvent kvarhållning är en funktion av klusterstorlek och kvarhållningsprincipen. Om du matar in mer data än du har tillgängligt utrymme framtvingas den första i data till kall kvarhållning.
Kontrollera att databasens kvarhållningsprincip är lämplig för dina behov. Annars ska du åsidosätta den explicit på tabellnivå. Mer information finns i Kvarhållningsprincip.
Skapa en tabell
För att kunna mata in data måste en tabell skapas i förväg. Välj ett av följande alternativ:
Skapa en tabell med ett kommando. Ett exempel på hur du använder kommandot skapa en tabell finns i Analysera med Data Explorer.
Skapa en tabell med inmatning med ett klick.
Anteckning
Om en post är ofullständig eller om ett fält inte kan parsas som den datatyp som krävs fylls motsvarande tabellkolumner i med null-värden.
Skapa schemamappning
Schemamappning hjälper till att binda källdatafält till måltabellkolumner. Med mappning kan du ta data från olika källor till samma tabell, baserat på de definierade attributen. Olika typer av mappningar stöds, både radorienterade (CSV, JSON och AVRO) och kolumnorienterade (Parquet). I de flesta metoder kan mappningar också skapas i förväg i tabellen och refereras från inmatningskommandoparametern.
Ange uppdateringsprincip (valfritt)
Vissa av dataformatmappningarna (Parquet, JSON och Avro) stöder enkla och användbara inmatningstidstransformeringar. Om scenariot kräver mer komplex bearbetning vid inmatningstillfället använder du uppdateringsprincipen, vilket möjliggör enkel bearbetning med Kusto-frågespråk kommandon. Uppdateringsprincipen kör automatiskt extraheringar och transformeringar på inmatade data i den ursprungliga tabellen och matar in resulterande data i en eller flera måltabeller. Ange din uppdateringsprincip.