Molnbaserade datamönster
Dricks
Det här innehållet är ett utdrag från eBook, Architecting Cloud Native .NET Applications for Azure, tillgängligt på .NET Docs eller som en kostnadsfri nedladdningsbar PDF som kan läsas offline.

Som vi har sett i hela den här boken ändrar en molnbaserad metod hur du utformar, distribuerar och hanterar program. Det ändrar också hur du hanterar och lagrar data.
Bild 5-1 kontrasterar skillnaderna.
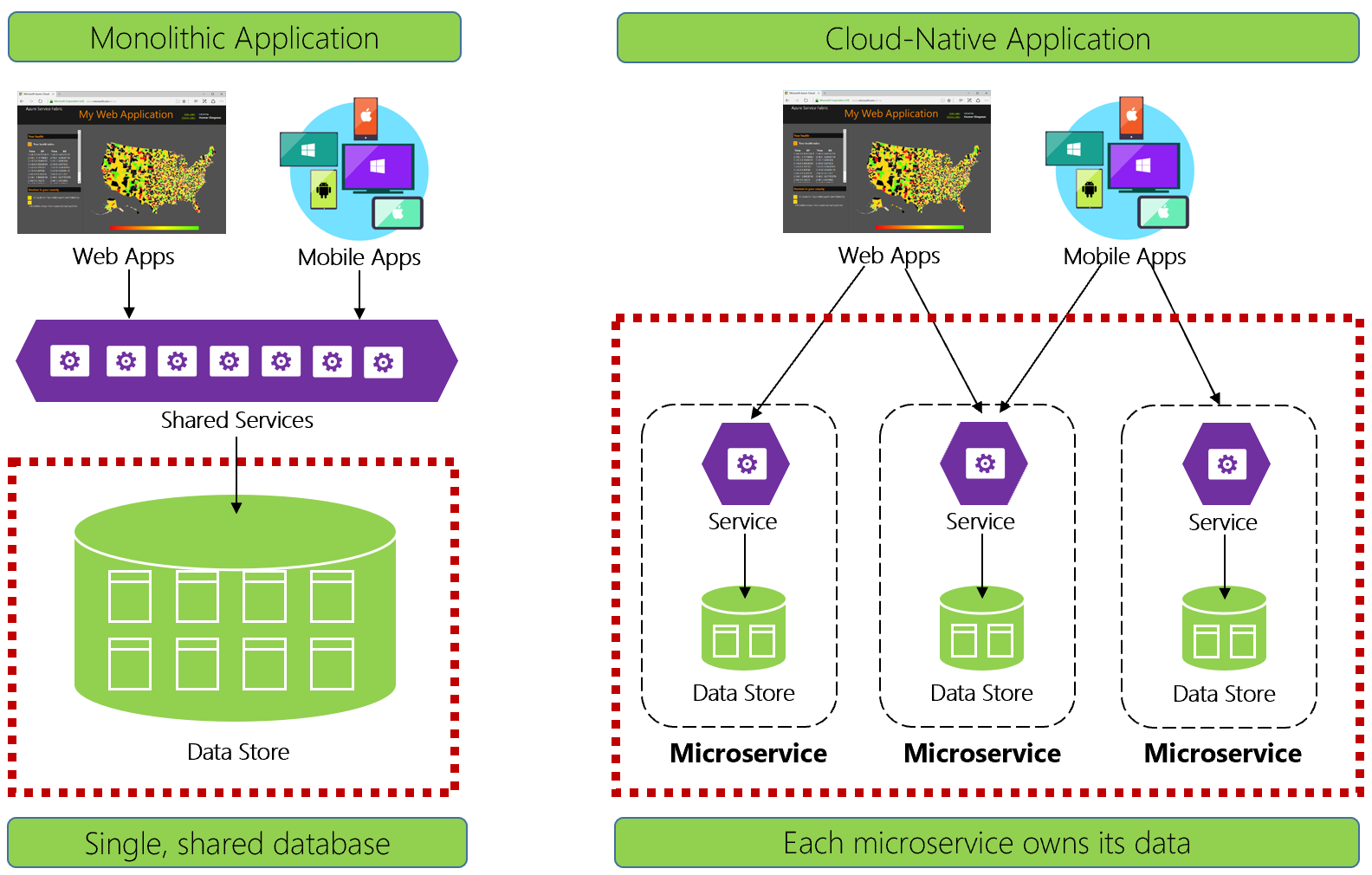
Bild 5-1. Datahantering i molnbaserade program
Erfarna utvecklare känner enkelt igen arkitekturen till vänster i bild 5-1. I det här monolitiska programmet samverkar företagstjänstkomponenterna på en delad tjänstnivå och delar data från en enda relationsdatabas.
På många sätt håller en enskild databas datahanteringen enkel. Det är enkelt att köra frågor mot data i flera tabeller. Ändringar av data uppdateras tillsammans eller så återställs alla. ACID-transaktioner garanterar stark och omedelbar konsekvens.
Vi utformar för molnbaserat och har en annan metod. På höger sida av bild 5–1 kan du se hur affärsfunktionerna skiljer sig åt i små, oberoende mikrotjänster. Varje mikrotjänst kapslar in en specifik affärskapacitet och egna data. Den monolitiska databasen delas upp i en distribuerad datamodell med många mindre databaser, var och en i linje med en mikrotjänst. När röken rensas framträder vi med en design som exponerar en databas per mikrotjänst.
Databas-per-mikrotjänst, varför?
Den här databasen per mikrotjänst ger många fördelar, särskilt för system som måste utvecklas snabbt och stöder massiv skalning. Med den här modellen...
- Domändata kapslas in i tjänsten
- Dataschemat kan utvecklas utan att påverka andra tjänster direkt
- Varje datalager kan skalas separat
- Ett datalagerfel i en tjänst påverkar inte andra tjänster direkt
Genom att separera data kan även varje mikrotjänst implementera den datalagertyp som är bäst optimerad för dess arbetsbelastning, lagringsbehov och läs-/skrivmönster. Alternativen omfattar relations-, dokument-, nyckel-värde- och till och med grafbaserade datalager.
Bild 5–2 visar principen om flerspråkig persistens i ett molnbaserat system.
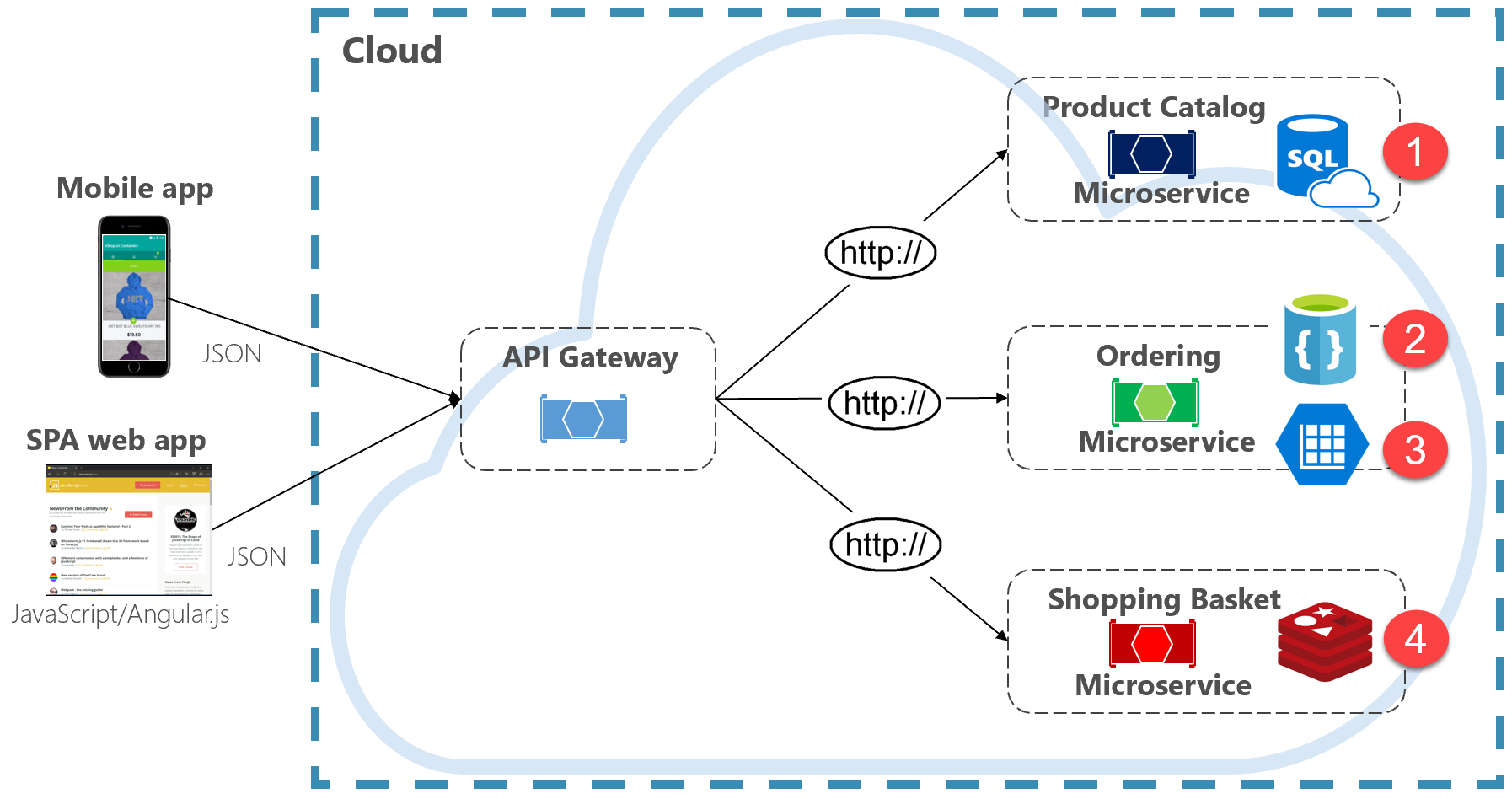
Bild 5-2. Polyglot datapersistence
Observera i föregående bild hur varje mikrotjänst stöder en annan typ av datalager.
- Produktkatalogens mikrotjänst använder en relationsdatabas för att hantera den omfattande relationsstrukturen för dess underliggande data.
- Kundvagnens mikrotjänst använder en distribuerad cache som stöder dess enkla nyckelvärdesdatalager.
- Beställningsmikrotjänsten använder både en NoSql-dokumentdatabas för skrivåtgärder tillsammans med ett mycket avnormaliserat nyckel-/värdelager för att hantera högvolymer av läsåtgärder.
Relationsdatabaser är fortfarande relevanta för mikrotjänster med komplexa data, men NoSQL-databaser har blivit mycket populära. De ger massiv skala och hög tillgänglighet. Deras schemalösa natur gör det möjligt för utvecklare att flytta från en arkitektur med typade dataklasser och ORM:er som gör ändringar dyra och tidskrävande. Vi tar upp NoSQL-databaser senare i det här kapitlet.
Att kapsla in data i separata mikrotjänster kan öka flexibiliteten, prestandan och skalbarheten, men det innebär också många utmaningar. I nästa avsnitt diskuterar vi dessa utmaningar tillsammans med mönster och metoder som hjälper dig att övervinna dem.
Frågor mellan tjänster
Mikrotjänster är oberoende och fokuserar på specifika funktionella funktioner, till exempel inventering, leverans eller beställning, men de kräver ofta integrering med andra mikrotjänster. Ofta innebär integreringen att en mikrotjänst frågar efter data. Bild 5–3 visar scenariot.

Bild 5-3. Fråga mellan mikrotjänster
I föregående bild ser vi en varukorgsmikrotjänst som lägger till ett objekt i en användares varukorg. Även om datalagret för den här mikrotjänsten innehåller korg- och linjeobjektdata, behåller det inte produkt- eller prisdata. I stället ägs dessa dataobjekt av katalogen och prissättningsmikrotjänster. Den här aspekten utgör ett problem. Hur kan varukorgens mikrotjänst lägga till en produkt i användarens varukorg när den inte har produkt- eller prisdata i sin databas?
Ett alternativ som beskrivs i kapitel 4 är ett direkt HTTP-anrop från varukorgen till katalogen och prissättningsmikrotjänster. Men i kapitel 4 sa vi att synkrona HTTP anropar par mikrotjänster tillsammans, vilket minskar deras autonomi och minskar deras arkitektoniska fördelar.
Vi kan också implementera ett mönster för begäran-svar med separata inkommande och utgående köer för varje tjänst. Det här mönstret är dock komplicerat och kräver VVS för att korrelera begärande- och svarsmeddelanden. Även om den frikopplar serverdelsmikrotjänstanropen måste den anropande tjänsten fortfarande synkront vänta tills anropet har slutförts. Nätverksbelastning, tillfälliga fel eller en överbelastad mikrotjänst och kan resultera i långvariga och till och med misslyckade åtgärder.
I stället är ett allmänt accepterat mönster för att ta bort beroenden mellan tjänster det materialiserade vymönstret, som visas i bild 5–4.
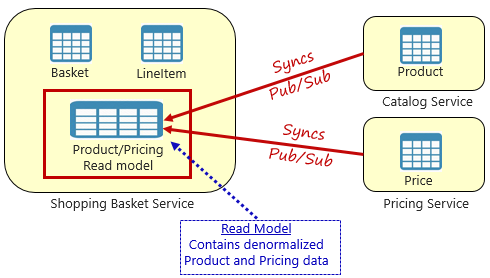
Bild 5-4. Mönster för materialiserad vy
Med det här mönstret placerar du en lokal datatabell (kallas för en läsmodell) i varukorgstjänsten. Den här tabellen innehåller en avnormaliserad kopia av de data som behövs från produkt- och prismikrotjänster. Att kopiera data direkt till varukorgens mikrotjänst eliminerar behovet av dyra korstjänstanrop. Med data som är lokala för tjänsten kan du förbättra tjänstens svarstid och tillförlitlighet. Att ha en egen kopia av data gör dessutom varukorgstjänsten mer motståndskraftig. Om katalogtjänsten skulle bli otillgänglig skulle den inte direkt påverka varukorgstjänsten. Varukorgen kan fortsätta att fungera med data från sin egen butik.
Haken med den här metoden är att du nu har duplicerade data i systemet. Att strategiskt duplicera data i molnbaserade system är dock en etablerad metod och betraktas inte som ett antimönster eller dålig praxis. Tänk på att en och endast en tjänst kan äga en datauppsättning och ha behörighet över den. Du måste synkronisera läsmodellerna när postsystemet uppdateras. Synkronisering implementeras vanligtvis via asynkrona meddelanden med ett publicerings-/prenumerationsmönster, enligt bild 5.4.
Distribuerade transaktioner
Det är svårt att köra frågor mot data mellan mikrotjänster, men det är ännu mer komplext att implementera en transaktion över flera mikrotjänster. Den inneboende utmaningen med att upprätthålla datakonsekvens mellan oberoende datakällor i olika mikrotjänster kan inte underskattas. Bristen på distribuerade transaktioner i molnbaserade program innebär att du måste hantera distribuerade transaktioner programmatiskt. Du går från en värld av omedelbar konsekvens till den slutliga konsekvensen.
Bild 5–5 visar problemet.

Bild 5-5. Implementera en transaktion mellan mikrotjänster
I föregående bild deltar fem oberoende mikrotjänster i en distribuerad transaktion som skapar en order. Varje mikrotjänst har ett eget datalager och implementerar en lokal transaktion för sitt lager. För att skapa ordern måste den lokala transaktionen för varje enskild mikrotjänst lyckas, eller så måste alla avbryta och återställa åtgärden. Inbyggt transaktionsstöd är tillgängligt inom var och en av mikrotjänsterna, men det finns inget stöd för en distribuerad transaktion som sträcker sig över alla fem tjänsterna för att hålla data konsekventa.
I stället måste du konstruera den här distribuerade transaktionen programmatiskt.
Ett populärt mönster för att lägga till distribuerat transaktionsstöd är Saga-mönstret. Det implementeras genom att gruppera lokala transaktioner programmatiskt och sekventiellt anropa var och en. Om någon av de lokala transaktionerna misslyckas avbryter Saga åtgärden och anropar en uppsättning kompenserande transaktioner. De kompenserande transaktionerna ångrar de ändringar som gjorts av de föregående lokala transaktionerna och återställer datakonsekvens. Bild 5–6 visar en misslyckad transaktion med Saga-mönstret.
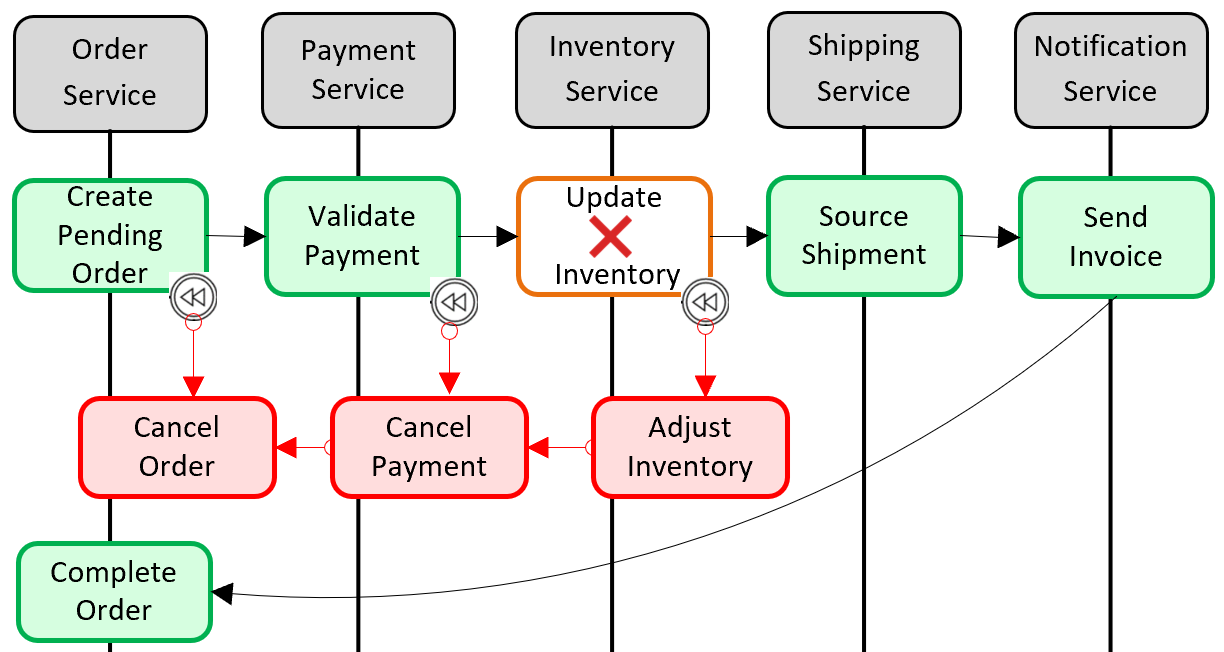
Bild 5-6. Återställa en transaktion
I föregående bild misslyckades uppdateringsinventeringsåtgärden i mikrotjänsten Inventering. Saga anropar en uppsättning kompenserande transaktioner (i rött) för att justera inventeringsantalet, avbryta betalningen och beställningen och returnera data för varje mikrotjänst tillbaka till ett konsekvent tillstånd.
Saga-mönster koreograferas vanligtvis som en serie relaterade händelser eller orkestreras som en uppsättning relaterade kommandon. I kapitel 4 diskuterade vi tjänstaggregatormönstret som skulle utgöra grunden för en orkestrerad sagaimplementering. Vi diskuterade även eventing tillsammans med Ämnena Azure Service Bus och Azure Event Grid som skulle utgöra grunden för en koreograferad sagaimplementering.
Data med hög volym
Stora molnbaserade program stöder ofta datakrav på stora volymer. I dessa scenarier kan traditionella datalagringstekniker orsaka flaskhalsar. För komplexa system som distribueras i stor skala kan både CQRS (Command and Query Responsibility Segregation) och Event Sourcing förbättra programmets prestanda.
CQRS
CQRS är ett arkitekturmönster som kan hjälpa dig att maximera prestanda, skalbarhet och säkerhet. Mönstret separerar åtgärder som läser data från de åtgärder som skriver data.
För normala scenarier används samma entitetsmodell och datalagringsplatsobjekt för både läs- och skrivåtgärder.
Ett scenario med hög volymdata kan dock dra nytta av separata modeller och datatabeller för läsningar och skrivningar. För att förbättra prestandan kan läsåtgärden köra frågor mot en mycket avnormaliserad representation av data för att undvika dyra repetitiva tabellkopplingar och tabelllås. Skrivåtgärden, som kallas ett kommando, skulle uppdateras mot en helt normaliserad representation av data som garanterar konsekvens. Sedan måste du implementera en mekanism för att hålla båda representationerna synkroniserade. När skrivtabellen ändras publicerar den vanligtvis en händelse som replikerar ändringen till lästabellen.
Bild 5–7 visar en implementering av CQRS-mönstret.
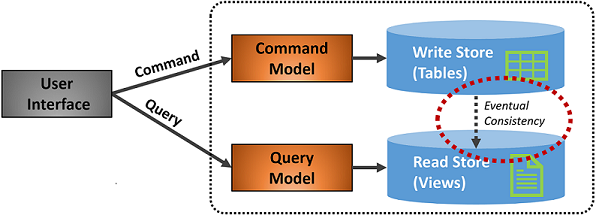
Bild 5-7. CQRS-implementering
I föregående bild implementeras separata kommando- och frågemodeller. Varje dataskrivningsåtgärd sparas i skrivarkivet och sprids sedan till läsarkivet. Var uppmärksam på hur dataspridningsprocessen fungerar enligt principen om slutlig konsekvens. Läsmodellen synkroniseras så småningom med skrivmodellen, men det kan finnas en viss fördröjning i processen. Vi diskuterar eventuell konsekvens i nästa avsnitt.
Den här separationen gör att läsningar och skrivningar kan skalas oberoende av varandra. Läsåtgärder använder ett schema som är optimerat för frågor, medan skrivningarna använder ett schema som är optimerat för uppdateringar. Läsfrågor går emot avnormaliserade data, medan komplex affärslogik kan tillämpas på skrivmodellen. Dessutom kan du införa strängare säkerhet för skrivåtgärder än de som exponerar läsningar.
Implementering av CQRS kan förbättra programprestanda för molnbaserade tjänster. Det resulterar dock i en mer komplex design. Tillämpa den här principen noggrant och strategiskt på de delar av ditt molnbaserade program som kommer att dra nytta av den. Mer information om CQRS finns i Microsoft-boken .NET Microservices: Architecture for Containerized .NET Applications (Microsoft-boken .NET Microservices: Architecture for Containerized .NET Applications).
Händelsekällor
En annan metod för att optimera scenarier med hög volymdata är händelsekällor.
Ett system lagrar vanligtvis det aktuella tillståndet för en dataentitet. Om en användare till exempel ändrar sitt telefonnummer uppdateras kundposten med det nya numret. Vi känner alltid till det aktuella tillståndet för en dataentitet, men varje uppdatering skriver över det tidigare tillståndet.
I de flesta fall fungerar den här modellen bra. I system med stora volymer kan dock omkostnader från transaktionslåsning och frekventa uppdateringsåtgärder påverka databasens prestanda, svarstider och begränsa skalbarheten.
Händelsekällor har en annan metod för att samla in data. Varje åtgärd som påverkar data sparas i ett händelselager. I stället för att uppdatera tillståndet för en datapost lägger vi till varje ändring i en sekventiell lista över tidigare händelser , ungefär som en revisors transaktionsregister. Händelsearkivet blir postsystemet för data. Den används för att sprida olika materialiserade vyer inom den avgränsade kontexten för en mikrotjänst. Bild 5.8 visar mönstret.

Bild 5-8. Händelsekällor
I föregående bild bör du notera hur varje post (i blått) för en användares kundvagn läggs till i en underliggande händelsebutik. I den angränsande materialiserade vyn projicerar systemet det aktuella tillståndet genom att spela upp alla händelser som är associerade med varje kundvagn. Den här vyn, eller läsmodellen, exponeras sedan tillbaka till användargränssnittet. Händelser kan också integreras med externa system och program eller efterfrågas för att fastställa den aktuella statusen för en entitet. Med den här metoden behåller du historiken. Du vet inte bara det aktuella tillståndet för en entitet, utan även hur du nådde det här tillståndet.
Mekaniskt sett förenklar händelsekällor skrivmodellen. Det finns inga uppdateringar eller borttagningar. Om du lägger till varje datainmatning som en oföränderlig händelse minimeras konkurrens-, låsnings- och samtidighetskonflikter som är associerade med relationsdatabaser. Genom att skapa läsmodeller med det materialiserade vymönstret kan du frikoppla vyn från skrivmodellen och välja det bästa datalagret för att optimera behoven i ditt programgränssnitt.
För det här mönstret bör du överväga ett datalager som har direkt stöd för händelsekällor. Azure Cosmos DB, MongoDB, Cassandra, CouchDB och RavenDB är bra kandidater.
Precis som med alla mönster och tekniker implementerar du strategiskt och när det behövs. Händelsekällor kan ge bättre prestanda och skalbarhet, men det sker på bekostnad av komplexitet och en inlärningskurva.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för