Apache HBase
Apache HBase är en icke-relationell databas med öppen källkod som modellerats efter Googles distribuerade lagringssystem BigTable och stöds av Apache Software Foundation. HBase är en distribuerad, skalbar versionsdatabas med höga prestanda. HBase-infrastrukturen är utformad för att lagra miljarder rader i datakolumner i löst definierade tabeller, till exempel den webbtabell som beskrevs tidigare. Följande videoklipp visar en översikt över HBase.
Precis som traditionella RDBMS är utformade för att köras ovanpå ett lokalt filsystem är HBase utformat för att fungera ovanpå Hadoop Distributed File System (HDFS). Som vi beskrivit tidigare är HDFS ett distribuerat filsystem som lagrar filer som replikerade block över flera servrar. HDFS ger HBase en skalbar och tillförlitlig filsystemserverdel.
HBase-datamodell
Tillämpningarna lagrar data som är ordnade som rader och kolumner i en tabell. Detta liknar tabeller i en RDBMS. För att illustrera ordnar vi tabellexemplet som en HBase-tabell:
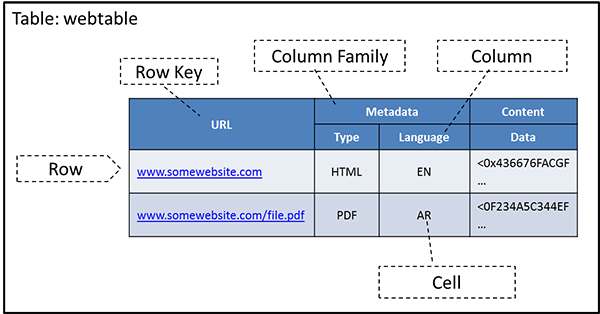
Bild 2: En tabell i HBase
En rad i HBase refereras med hjälp av en radnyckel som kan anses vara den primära nyckeln för tabellen i en RDBMS. Tabellens primära nyckel måste vara unik och därför referera till en enda rad. Till skillnad från i RDBMS (som kräver att primära nycklar ska vara av vissa typer) är radnycklar råa bytematriser, så teoretiskt sett kan allt från strängar till binära representationer av långa heltal, flyttal eller till och med hela datastrukturer som har serialiserats (konverterats till ett bytematrisformulär) fungera som en radnyckel. HBase sorterar automatiskt tabellrader efter radnyckel när de lagras. Som standard är den här sorteringen ordnad efter byte.
Kolumner i HBase har ett kolumnnamn som kan användas för att referera till en kolumn. Kolumner kan grupperas ytterligare i kolumnserier. Alla kolumngruppsmedlemmar har ett gemensamt prefix, så i exemplet med webbtabellen är kolumnerna Metadata:Type och Metadata:Language medlemmar i kolumngruppen Metadata medan Content:Data tillhör gruppen Content. Som standard avgränsar kolontecknet (:) kolumnprefixet från familjemedlemmen. Kolumngruppsprefixet måste bestå av utskrivbara tecken. Kvalificerande slut kan bestå av valfria byte.
HBase skiljer sig från en RDBMS eftersom kolumnerna inte behöver skrivas. de tolkas som råa bytesträngar. Den här tolkningen gör det möjligt för HBase att lagra alla typer av data i tabellen, men förhindrar också att den automatiskt kan verifiera datavärden när de läses in i tabellen.
Även om kolumngrupperna i en tabell måste definieras överst när du skapar tabellen kan gruppmedlemmar läggas till på begäran. HBase lagrar alla medlemmar i kolumngruppen tillsammans i det underliggande filsystemet. HBase är därför en kolumndatabas.
Tabellceller, skärningspunkten mellan rad- och kolumnkoordinater, är versionshanterade (d.v.s. HBase lagrar flera versioner [standard är 3] av de värden som lagras i tabellerna). Versionen av ett tabellcellsvärde tidsstämplas och tilldelas automatiskt av HBase vid tidpunkten för cellinfogning eller uppdatering. Därför beskriver tupeln {rad,kolumn,version} ett unikt värde som lagras i en HBase-tabell.
HBase-åtgärder
HBase har fyra primära åtgärder för datamodellen: Get, Put, Scan och Delete.
En Get-åtgärd returnerar alla celler för en angiven rad, som pekas på av en radnyckel. En Put-åtgärd kan antingen lägga till nya rader i tabellen när den används med en ny nyckel eller uppdatera en rad om nyckeln redan finns. Scan är en åtgärd som itererar över flera rader baserat på ett villkor, till exempel ett radnyckelvärde eller ett kolumnattribut. En Delete-åtgärd tar bort en rad från en tabell. Get- och Scan-åtgärder returnerar alltid data i sorterad ordning. Data sorteras först efter radnyckel, sedan efter kolumnserie, sedan efter gruppmedlemmar och slutligen efter tidsstämpel (så att de senaste värdena visas först).
Som standard utförs Get-, Scan- och Delete-åtgärder i en HBase-tabell på data som har den senaste versionen. En Put-åtgärd skapar alltid en ny version av de data som placeras i HBase. Som standard tar Delete-åtgärder bort en hel rad, men de kan även användas för att ta bort specifika dataversioner i en rad. Varje åtgärd kan också vara riktad mot ett explicit versionsnummer.
HBase-arkitektur
HBase är organiserat som ett kluster med HBase-noder. Dessa noder är av två typer: en primär nod och en eller flera sekundära noder (kallas RegionServers, se bild 3). HBase använder Apache ZooKeeper som distributionssamordningstjänst för hela HBase-klustret. Den hanterar till exempel primär markering (väljer en av noderna som primär nod), uppslag för katalogtabellen -ROOT- (förklaras snart) och nodregistrering (när nya regionservrar läggs till). Den primära nod som väljs av ZooKeeper hanterar funktioner som regionallokering, redundans och belastningsutjämning.

Bild 3: HBase-arkitektur
Precis som med de flesta databaser kan HBase spara data med hjälp av ett underliggande filsystem. HBase är utformat för att använda HDFS i serverdelen men har även stöd för olika typer av filsystem, inklusive ett lokalt filsystem och molnfilsystem som Azure Blob Storage. Vanligtvis är varje regionserver i HBase även en HDFS DataNode (en HDFS-filserver), men detta är inte obligatoriskt i HBase.
Datapartitionering
HBase är utformat för att skala tabeller till ett stort antal rader och kolumner (miljontals), med storleken på varje tabell i terabyte eller petabyte. I den här skalan är det omöjligt att ha data på en enda nod. För att kunna distribuera data som lagras i HBase över noderna i ett kluster partitionerar HBase automatiskt tabeller till regioner (horisontell partitionering). Regionerna är grupper med rader i ordningsföljd i en tabell:
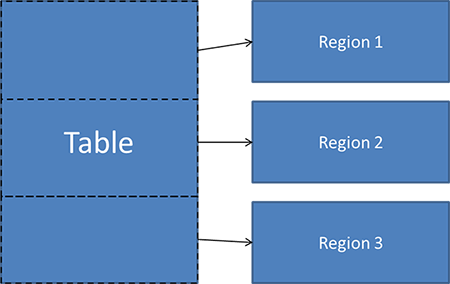
Bild 4: Dela upp en tabell i flera regioner i HBase
Varje region definieras av basraden (inklusive) och den sista raden (exklusive) samt en regionidentifierare (ett slumpmässigt genererat tal). Tabeller lagras ursprungligen i en enda region, men när tabellens storlek når ett visst tröskelvärde genererar HBase automatiskt en ny region genom att dela upp data i två nästan lika stora regioner. Den här processen fortsätter när tabellerna fortsätter att bli större.
Klientåtkomst
HBase-klienter kan ansluta till HBase för att utföra åtgärder på HBase-tabeller, enligt beskrivningen i datamodellen. Klienterna måste dock hitta rätt nod i HBase-klustret som lagrar den region i tabellen som måste nås. För att hålla reda på alla regioner och deras placering i HBase-klustret har HBase två katalogtabeller med namnen -ROOT- och .META. på HBase-språk. Tabellerna behandlas också som HBase-tabeller och kan lagras var som helst i HBase-klustret för feltolerans. Tabellen -ROOT- är alltid självständig och finns i en enda region, medan tabellen .META. kan delas upp i flera regioner. En klient ansluter först till klustret för att se platsen för tabellen -ROOT- (via ZooKeeper) och skickar sedan en fråga till tabellen -ROOT- för att få reda på platsen för tabellen .META.. Tabellen .META. returnerar sedan platsen för den faktiska rad som begärdes av klienten. När regionservern har lösts av klienten interagerar klienten direkt med den regionservern och utför nödvändiga radåtgärder.
Klienten cachelagrar även tabellerna -ROOT- och .META. efter den första åtkomsten så att efterföljande klientåtgärder inte kräver fler sökningar i dessa tabeller. Klienten fortsätter använda den cachelagrade kopian av katalogtabellerna tills den påträffar ett fel, vilket vanligtvis innebär att katalogtabellerna har uppdaterats efter att platsen för en tabellregion har flyttats. Klienten uppdaterar sin cachelagrade kopia av katalogtabellerna och fortsätter med åtgärden.
Skrivåtgärder
En regionserver hanterar skrivåtgärder på följande sätt: skrivåtgärden bifogas till en incheckningslogg på HDFS (som trippelreplikeras som standard). Därefter läggs skrivåtgärden till i ett cacheminne. När regionserverns cacheminne blir fullt rensas innehållet till filsystemet.
Eftersom incheckningsloggen lagras i HDFS är den fortfarande tillgänglig även om regionservern skulle krascha. När den primära märker att en regionserver inte längre kan nås hämtar den incheckningsloggen och delar upp ändringarna mellan regioner. Varje regionserver får en del av incheckningsloggen och spelar upp ändringarna för att ta filsystemet till sitt konsekventa tillstånd, d.v.s. innan felet uppstod.
Läsåtgärder
För läsåtgärder rådfrågar HBase alltid cacheminnet för en region. Om tillräckligt många dataversioner hittas för att uppfylla frågan, returneras data. Annars konsulteras de rensade filerna från nyaste till äldsta för att hitta nödvändiga data eller tills det inte finns några fler rensade filer att konsultera. En bakgrundsprocess komprimerar regelbundet tömningsfilerna när deras antal når ett visst tröskelvärde genom att kombinera många tömningsfiler till en. Under komprimeringen rensas alla versioner av celler utöver ett användarkonfigurerat tröskelvärde (standardvärdet är 3) för raderade rader.
ACID-egenskaper i HBase
HBase, liksom många NoSQL-databaser, är inte helt ACID-kompatibelt avsiktligt. HBase garanterar ACID-kompatibilitet för en rad, men inte för åtgärder på flera rader. ACID-egenskaper i HBase är följande:
- Atomicitet: HBase erbjuder atomicitet för åtgärder som uppdaterar enskilda rader. Put-åtgärder genomförs i sin helhet eller misslyckas. Åtgärder som uppdaterar flera rader kan antingen lyckas eller misslyckas för enskilda rader, och HBase returnerar status per rad.
- Konsekvens: HBase ger en konsekvent vy över en databas för Get-åtgärder på en enda rad. De data som returneras är data som fanns vid någon tidpunkt i tabellens historik. Dessutom visas alla ändringar som gjorts i tabellen i den ordning som de slutfördes. Scan-åtgärden i HBase är dock inte strikt konsekvent. Om en Scan-åtgärd till exempel körs samtidigt med en åtgärd som uppdaterar en eller flera rader som ingår i genomsökningen kan Scan-åtgärden returnera rader som har uppdaterats eller som inte har uppdaterats. Det är viktigt att notera att en rad alltid uppdateras i sin helhet, aldrig delvis.
- Isolering: Åtgärder på en rad utförs i ordning och är därför strikt isolerade från varandra. Men som vi förklarade i föregående punkt är genomsökningarna inte isolerade från andra åtgärder på enskilda rader.
- Hållbarhet: HBase garanterar hållbarhet för alla data som är synliga. Alla data som returneras från en läsning finns alltid på en disk i någon form.
Användningsfall för HBase
HBase erbjuder flera gränssnitt som du kan arbeta med. Java-gränssnittet för HBase kan användas i ett MapReduce-jobb. HBase har dessutom ett REST-gränssnitt som kan användas för att hämta data som lagras i HBase via HTTP-tjänstanrop.
HBase delar samma användningsfall som Googles BigTable. HBase är ett distribuerat datalager som kan lagra miljarder rader och kolumner.
HBase passar bäst för stordatalagring som kräver snabb åtkomst till flera rader i taget för aggregeringar, till exempel summering eller genomsnitt. Modellen ger också flexibel möjlighet att lägga till kolumner i databasen när som helst. Versionshanteringsegenskapen för HBase är också användbar för att lagra information som ändras över tid, men där även tidigare versioner av data är användbara. I exemplet med webbtabellen kan flera versioner av en webbsida lagras för jämförelse.
Join-åtgärden kan inte användas i HBase, där data från två eller flera tabeller kombineras i en gemensam kolumn för att skapa en ny tabell. Om programmet är beroende av kopplingar kanske inte HBase är rätt val. Dessutom lägger HBases avslappnade konsekvensmodell ytterligare bördor på programutvecklaren, till exempel för att verifiera resultatet av genomsökningar.