MongoDB
MongoDB är en dokumentorienterad databas. MongoDB undviker relationsmodellen och använder i stället en "schema lös" modell, som har utformats för att vara mer flexibel och imiterar hur data modelleras i moderna, objektorienterade programmeringsspråk. MongoDB är också utformat för att vara skalbart från grunden och kan automatiskt dela upp data mellan flera servrar och utjämna belastningen mellan servrar i ett kluster. MongoDB kan också användas för komplexa frågor, till exempel sådana som omfattar aggregeringar av MapReduce-typ och geo-spatiala frågor, vilket gör MongoDB populärt som datalager för mappningsrelaterade tillämpningar. Video 4.42 täcker MongoDB
MongoDB-datamodell
Ett dokument är den grundläggande dataenheten för MongoDB, ungefär lika med en rad i ett hanteringssystem för relationsdatabaser. Ett dokument är en ordnad uppsättning nycklar och deras associerade värden. Ett exempel på ett dokument illustreras nedan:
{
item: "ABC1",
details: {
model: "14Q3",
manufacturer: "XYZ Company"
},
stock: [ { size: "S", qty: 25 }, { size: "M", qty: 50 } ],
category: "clothing"
}
MongoDB lagrar dokument i grupper som kallas samlingar. MongoDB har ingen begränsning för de dokument som ingår i en samling. De kan innehålla valfritt antal nycklar och valfri typ av nycklar, och de behöver inte vara relaterade. Den enda begränsningen är att varje dokument i en samling har en nyckel med namnet _id, som ska ha ett unikt värde för varje dokument i en samling. MongoDB kan automatiskt generera _id-nyckeln för varje dokument som infogas i en samling.
En samling identifieras av en UTF-8-sträng som kallas samlingens namn. Många utvecklare väljer att gruppera samlingar med en namngivningskonvention, som att använda tecknet . för att ange två typer av bloggsamlingar: blog.posts och blog.authors. Detta är endast i organisationssyfte och MongoDB behandlar dem som separata, orelaterade samlingar.
Slutligen utgörs en MongoDB-databas av en grupp samlingar. Precis som samlingar identifieras en MongoDB-databas av ett UTF-8-strängnamn.
MongoDB har stöd för en omfattande uppsättning datatyper, inklusive 32/64-bitars heltal, 64-bitars flyttal, booleska värden, datum, strängar, regex, JavaScript-kod, matriser med mera. Dokument kan även kapslas, d.v.s. ett dokument kan innehålla andra dokument, vilket gör MongoDB-datamodellen fullständigt kapslad.
Internt gäller att dokument lagras i MongoDB med formatet BSON (Binary JSON). Storleken på ett enskilt dokument i MongoDB får vara högst 4 MB.
Åtgärder i MongoDB
De huvudsakliga åtgärderna i MongoDB för ändrade data är följande: infoga, ta bort och uppdatera. MongoDB tillåter batch-infogning, vilket gör att ett program kan infoga flera dokument i en och samma begäran. Den enda begränsningen i MongoDB är meddelandestorleken, som är 16 MB. MongoDB tillåter även en särskild typ av åtgärd, som kallas upsert. Den här åtgärden uppdaterar ett befintligt dokument eller infogar ett nytt dokument om inget dokument finns.
Dataförfrågningar i MongoDB görs med kommandot find. Användning av kommandot find med en uppsättning villkor kan användas för att returnera dokument som matchar en uppsättning villkor. En diskret begränsning i MongoDB är att de villkor som används i kommandot find måste vara ett konstant värde som anges i själva frågan. Det innebär att du inte kan skriva en fråga i MongoDB som hittar dokument där ett visst värde matchar ett annat värde från samlingen.
Förutom enkla frågor tillhandahåller MongoDB en uppsättning aggregeringsverktyg som kan tillämpas på uppsättningen med resultatdokument i en fråga. Aggregeringarna sträcker sig från enkla tal till MapReduce-funktioner för att ytterligare renodla och analysera data som returneras från en fråga.
Precis som med de flesta databassystem kan du i MongoDB skapa index på vissa nycklar som ska skapas för en samling. Detta kan användas för att minska den tid det tar att köra vissa typer av frågor. En viktig funktion i MongoDB är möjligheten att skapa index på geospatiala datanycklar, som latitud och longitud. MongoDB kan effektivt hantera intervallfrågor på geo-spatiala data.
Med MongoDB kan administratörer be systemet att förklara frågor, ungefär som de funktioner som erbjuds av populära RDBMS. Det gör det möjligt för administratörer att analysera och optimera frågekörningen i MongoDB.
MongoDB-arkitektur
MongoDB hanterar samlingar och dokument som filer i ett lokalt filsystem. Om ett index skapas på en viss nyckel använder MongoDB en B-Tree-struktur för att lagra indexinformationen. MongoDB arbetar i princip med de här filerna på disken på ett minnesmappat sätt, och överlåter åt operativsystemet och filsystemet att hantera minnesbufferten för de filer som innehåller informationen.
För små installationer distribueras MongoDB som ett system med en nod. För att kunna skala ut MongoDB till flera noder stöder MongoDB två skalbara lägen: replikering och horisontell partitionering. Vid replikering behålls flera kopior av samma data på flera servrar, vilket gör att MongoDB kan klara nodhaverier om en nod slutar fungera. En uppsättning MongoDB-noder som har samma data kallas replikuppsättning. En nod i en replikuppsättning kallas primär, och återstående noder kallas sekundära. Som standard svarar bara den primära noden på begäranden från klienter för både läsning och skrivning. Den primära noden skickar ut meddelanden för att uppdatera replikerna när det finns en åtgärd som skriver data. I det här läget garanterar MongoDB strikt konsekvens eftersom alla databegäranden endast bearbetas av den primära noden.
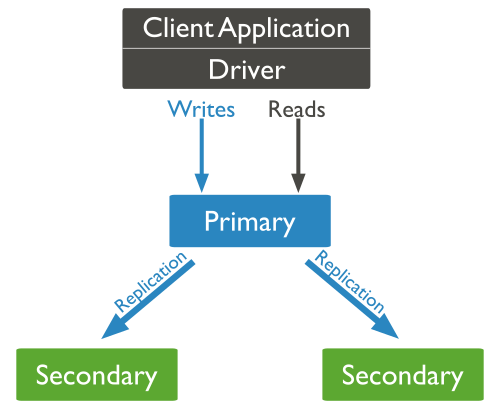
Bild 5: Replikering i MongoDB
En MongoDB replikuppsättning är utformad för automatisk redundans. Om en nod inte svarar på mer än 10 sekunder förmodas den vara inaktiv, och återstående noder röstar om vilken nod som ska bli ny primär nod.
För att kunna distribuera data tillåter MongoDB att data kan partitioneras horisontellt över flera noder. Varje horisontell partition är en oberoende databas, och tillsammans utgör dessa partitioner en enda logisk databas. Arkitekturen i ett horisontellt partitionerat MongoDB-kluster illustreras nedan:
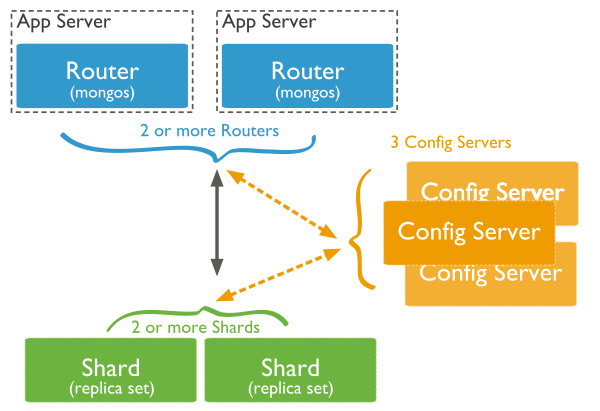
Bild 6: Horisontell partitionering i MongoDB
Data lagras i de horisontella partitionerna. För att tillhandahålla hög tillgänglighet och datakonsekvens är varje horisontell partition en replikuppsättning i ett horisontellt partitionerat kluster.
Frågerouter-gränssnitt med klientprogram och direkta åtgärder till lämplig horisontell partition (en eller flera). Frågeroutern bearbetar och målriktar åtgärder till de horisontella partitionerna och returnerar sedan resultatet till klienterna. Ett horisontellt partitionerat kluster kan innehålla fler än en frågerouter för att fördela belastningen av klientbegäranden. En klient skickar begäranden till en frågerouter. De flesta horisontellt partitionerade kluster har många frågeroutrar.
Klustrets metadata lagras på konfigurationsservrar. Dessa data innehåller en mappning av klustrets datauppsättning till de horisontella partitionerna. Frågeroutern använder dessa metadata för att rikta åtgärder mot specifika horisontella partitioner.
Data distribueras över flera noder med en specifik nyckel som kallas för horisontell partitionsnyckel. MongoDB delar upp nyckelvärdena för horisontella partitioner i segment och distribuerar segmenten jämnt över noderna i klustret. Nycklar för horisontell partition kan antingen vara hash-baserade eller intervallbaserade. I hash-baserad horisontell partitionering används hash-värdet för en nyckel för horisontell partitionering för att tilldela ett dokument till ett särskilt segment. I intervallbaserad horisontell partitionering tilldelas varje segment ett specifikt värdeintervall för nyckeln för horisontell partitionering, och dokument kan sedan tilldelas till ett specifikt segment.
Med MongoDB kan administratörer dirigera utjämningsprincipen med hjälp av taggmedveten horisontell partitionering. Administratörerna skapar och associerar taggar med intervall i nyckeln för horisontell partitionering och tilldelar sedan dessa taggar till partitionerna. Därefter migrerar balanseraren taggade data till lämpliga partitioner och säkerställer att klustret alltid tillämpar den datafördelning som taggarna beskriver.
MongoDB-användnings fall
MongoDB kan användas för att hantera specifika utmaningar för vissa typer av tillämpningar:
Stor, snabbt växande datauppsättning: MongoDB stöder stora mängder data och har en mycket flexibel schemalös design. MongoDB kan vara ett bra val för program som utvecklas snabbt och kräver ett föränderligt schema.
Platsbaserade data: MongoDB är unikt i sin förmåga att lagra och indexeras geo-spatiala data på ett effektivt sätt. Därför används MongoDB ofta för program som använder geo-spatiala data eller kartdata. (Exempel är bokningsprogram, platsbaserade tjänster osv.)
Program med hög skrivbelastning: MongoDB har inbyggt stöd för massinfogningar och har stöd för hög infogningshastighet, samtidigt som transaktionssäkerheten är avslappnad jämfört med RDBMSes.
Hög tillgänglighet i en otillförlitlig miljö: MongoDB:s arkitektur möjliggör nästan omedelbar, automatisk återställning från ett nodfel när replikeringen konfigureras. Detta är särskilt användbart i otillförlitliga miljöer.