Apache Cassandra
Apache Cassandra är ett fullständigt distribuerat, strukturerat nyckelvärdeslagringssystem. Cassandra gifter sig med de bästa aspekterna av både HBase och Amazons uppsättning lagringstekniker, som kallas Dynamo.3 Cassandra använder datamodellen för HBase och implementeringsarkitekturen för Dynamo. Följande video behandlar Cassandra.
Cassandra-datamodell
Cassandra implementerar datamodellen i HBase, enligt beskrivningen i föregående enhet), med lite annorlunda terminologi.
En tabell i Cassandra kallas kolumngrupp (ska inte förväxlas med en kolumngrupp i Apache HBase, som är en grupp associerade kolumner i en tabell, se bild 7a). En post (eller rad) behandlas som ett nyckel/värde-par, där nyckeln är en identifierande egenskap för posten. Värdet anses också vara en uppsättning nyckel/värde-par, där varje nyckel är namnet på varje kolumn och varje värde är värdet i kolumnen (bild 7b).

Bild 7: Cassandra-datamodellen. (a) Logisk vy för webbtabellen i Cassandra. (b) En rad i tabellen som visas som en kapslad sekvens med nyckel/värde-par.
Liksom HBase tillåter Cassandra även kapslade kolumner, som kallas överordnade kolumner. Överordnade kolumner i Cassandra implementeras som kapslade nyckel/värde-par, där den överordnade kolumnens namn är nyckeln och värdet är en sekvens med nyckel/värde-par som motsvarar varje kolumnnamn och värde.
I Cassandra kan data lagras i nyckel- eller värdedelarna i varje nyckel/värde-par. Värdena kan lagras i namn på kolumner och överordnade kolumner om det behövs. Vanliga åtgärder i Cassandra är att lagra och hämta enskilda rader med hjälp av nyckeln och uppdateringar av delar av en rad. Datamodellen i Cassandra liknar HBase och är relativt flexibel när det gäller att tillåta lagring av olika typer av data. Den stora skillnaden mellan datamodellerna i HBase och Cassandra är att Cassandra inte har inbyggt stöd för versionshantering, som HBase har.
Cassandras stöd för dataåtgärder liknar det i HBase, med några få undantag. Vanliga åtgärder i Cassandra är Get, Insert och Delete. Åtgärder kan utföras på en enskild rad eller en uppsättning rader (som kallas intervall). Dessutom kan åtgärder utföras på en uppsättning kolumner i en databas (kallas för ett segment):
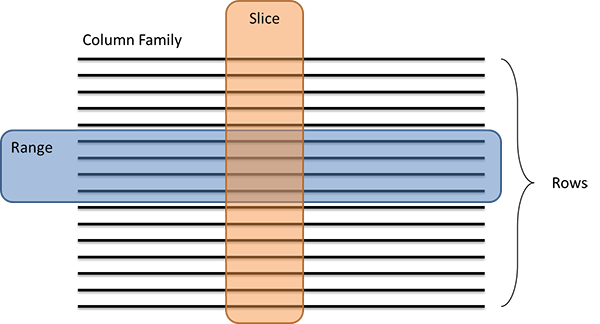
Bild 8: Intervall och sektorer i Cassandra
Cassandra-arkitektur
Cassandra är ett distribuerat datalager som utformats för körning på ett nodkluster, ungefär som HBase. Till skillnad från HBase följer Cassandra dock en decentraliserad arkitektur (det vill säga att det inte finns någon primär-sekundär arkitektur och varje nod i Cassandra har samma roll), vilket innebär att Cassandra är utformat utan en enda felpunkt (SPOF). Även om HBase är utformat för att vara motståndskraftigt mot fel är det beroende av Hadoop Distributed File System (HDFS) för beständig lagring, där NameNode är en SPOF. För Cassandra krävs inget underliggande DFS (Distributed File System). Noderna i ett Cassandra-kluster använder helt enkelt den lokala lagringen på varje nod. Samordning mellan klusternoder i Cassandra hanteras med en peer-to-peer-metod.
Datadistribution i Cassandra
Klientbegäranden om att läsa eller skriva data i Cassandra kan hanteras av vilken nod som helst i klustret. När rader infogas i en kolumngrupp i Cassandra distribuerar Cassandra automatiskt raderna bland de olika noderna i ett kluster. Den teknik som används för att distribuera raderna skiljer sig dock mycket från hur de distribueras i HBase. I Cassandra distribueras data mellan noderna baserat på hash-värdet för nyckeln för en rad med hjälp av en strategi som kallas konsekvent hashning.
Konsekvent hashning
Cassandra distribuerar automatiskt rader mellan de olika noderna i klustret med hjälp av hash-värdet för nyckeln för varje rad. I standardfallet använder Cassandra en MD5-hashningsalgoritm (Message Digest 5) i nyckeln för varje rad och genererar 128 bitar långa hash-värden. Hash-värdet för en nyckel avgör var raden lagras i klustret. För att kunna distribuera rader jämnt över noderna i ett Cassandra-kluster tilldelas varje nod i klustret ett unikt token. Ett token är ett intervall med hash-värden som tilldelas varje nod. Som standard är nod-token ett värdeintervall från 0 till 2127, som är jämnt dividerat med antalet noder i klustret. Samlingen av alla noder i klustret kallas gemensamt för en token-ring, med noderna ordnade i ordningsföljd. Varje nod i token-ringen är medveten om de andra noderna i token-ringen och det intervall med hash-värden som de är ansvariga för. Följande bild visar ett exempel.
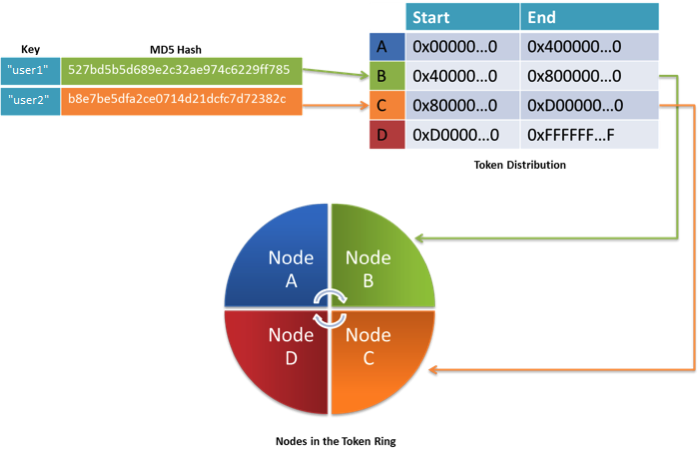
Bild 9: Noder ordnade som en cirkelring med hashvärden i konsekvent hash-hashning
I exemplet har nyckeln user1 ett MD5-hash-värde som börjar med hexvärdet 5. Den nod som passar det här intervallet i token-ringen är B (den accepterar hash-värden från 0x4 till 0x8). Raden med nyckeln user1 lagras därför på nod B. På samma sätt lagras user2 på nod C eftersom dess hash-värde börjar med B, och noden C är ansvarig för alla värden från 0x8 till 0xD.
Det är viktigt att notera att Cassandra-administratören kan partitionera token-utrymmet manuellt mellan noderna, och tilldela olika intervall av hash-utrymmet till en nod. Med konsekvent hashning får Cassandra-klustren därmed en naturlig belastningsutjämningsfunktion. Nu utforskar vi hur det konsekventa hashningsschemat ger replikering och feltolerans till ett Cassandra-kluster.
Replikering
Även om datadistributionsprincipen i Cassandra fördelar data jämnt mellan noderna i klustret gäller att om fel uppstår på en av noderna kan de rader som lagras på noden förloras. För att tillhandahålla redundans vid nodfel replikerar Cassandra rader över flera noder, enligt definitionen i replikeringsfaktorn (som är 1 som standard). Cassandra erbjuder både en rackmedveten och en rackomedveten strategi för replikplacering. Den första repliken placeras alltid utifrån den metod för konsekvent hashning som beskrivs ovan.
Anta att den angivna replikeringsfaktorn är $N$. Den första repliken placeras alltid utifrån den metod för konsekvent hashning som beskrivs ovan. I den rackmedvetna strategin placeras den andra repliken alltid i ett annat datacenter (om Cassandra-klustret sträcker sig över flera datacenter) eller i ett annat rack än den första repliken. Återstående repliker placeras på noder som finns i samma rack som den första, i nodernas ordningsföljd i token-ringen. I den rackokänsliga strategin placeras repliker helt enkelt i ordning längs nästa $N - 1$ noder i tokenringen.
Noder kan läggas till i ett Cassandra-kluster när som helst. Detta hanteras på två sätt. Antingen tilldelar administratören manuellt token för den nya inkommande noden, eller så hittar Cassandra automatiskt den nod som har flest data och delar upp dess token i två halvor. Ena halvan av hash-utrymmet ges sedan till den nya inkommande noden. Den nya noden accepterar inte begäranden omedelbart eftersom den först måste lära sig topologin för ringen och acceptera data som den också kan vara ansvarig för. När den har gjort det kan den ansluta ringen som en fullständig medlem och börja acceptera begäranden. Cassandra fördelar därefter data på nytt mellan noderna i klustret.
Processen för att hålla replikerna uppdaterade i Cassandra kallas antientropi. Antientropi i Cassandra uppnås med Merkle-träd. Ett Merkle-träd1 (bild 10) är ett hash-träd där bladen är hash-värden för värdena i enskilda nycklar. Överordnade noder högre upp i trädet är hash-värden för deras respektive underordnade. Den huvudsakliga fördelen med Merkle-träd är att grenarna i trädet kan kontrolleras oberoende av varandra, utan genomsökning av hela grenen. Cassandra beräknar regelbundet Merkle-träden för varje kolumngrupp och byter dem bland replikmedlemmarna för att snabbt kunna beräkna skillnader i tabellerna så att de kan synkroniseras. Till skillnad mot andra metoder i Cassandra är antientropi en dyr åtgärd som inte utförs ofta. Cassandra har även metoder för att utföra omedelbar reparation av repliker under läsning (kallas läsreparation). Detta beskrivs längre fram.
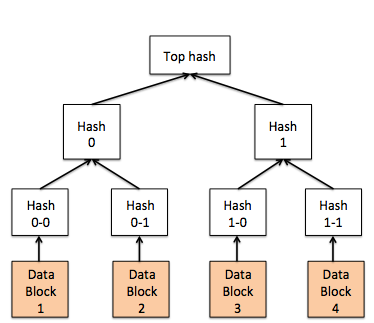
Bild 10: Merkleträd
Dataåtgärder i Cassandra
Skrivåtgärder
När en skrivåtgärd skickas till en Cassandra-nod skrivs den först till incheckningsloggen (i det lokala filsystemet) för den noden. Incheckningsloggen är en typ av journal som garanterar att skrivåtgärden kan återställas i händelse av krasch. Skrivningen vidarebefordras därefter till memtabellen, som är en minnesresident datastruktur (en typ av cache). Memtabellen gör att data kan vara minnesresidenta, vilket gör att framtida åtgärder kan läsa värdena direkt från minnet för att ge bättre prestanda. När memtabellens storleken når ett visst tröskelvärde rensar Cassandra den till disken i en fil med namnet SSTable, och skapar sedan en ny memtabell. Rensningsåtgärden är inte blockerande, och andra åtgärder på den Cassandra-noden behöver därför inte vänta på att rensningen ska slutföras innan den fortsätter köras.
Borttagningsåtgärder
Borttagningsåtgärder behandlas som uppdateringsåtgärder som placerar en gravsten (en borttagningsmarkör) på det värde som ska tas bort, vilket innebär att data inte rensas från Cassandra omedelbart utan markeras för borttagning (detta kallas även mjuk borttagning). Värdena tas inte bort förrän ett värde för respittid för skräpinsamling har nåtts. Som standard är detta värde 864 000 sekunder (cirka 10 dagar). När tröskelvärdet för skräpinsamlingen har överskridits markeras gravstensvärdena som utgångna.
Komprimeringsåtgärder
När Cassandra-instansen körs kan den ha samlat in flera SSTables (via många rensningar). En åtgärd som kallas komprimering utförs med jämna mellanrum för att slå samman data från flera SSTables. Under komprimeringsåtgärden sammanfogas nycklarna, kolumnerna slås samman, utgångna gravstenar tas bort och ett nytt index skapas.
Läsåtgärder
För att läsa data från ett Cassandra-kluster ansluter en klient till en nod i klustret. Baserat på den konsekvensnivå som anges av klienten vidarebefordras läsbegäran till ett antal noder i klienten. Denna läsåtgärd blockeras tills den nödvändiga konsekvensnivån är uppfylld. Om några noder svarar med ett inaktuellt värde returneras det senaste värdet till klienten. Cassandra utför sedan en läsreparationsåtgärd. Den här åtgärden utförs utöver den periodiska antientropi-åtgärd som beskrivits tidigare. Läsreparationsåtgärden uppdaterar replikerna. Läsreparationen utförs enligt den konsekvensnivå som angetts under läsningen, vilket förklaras härnäst.
Justerbar konsekvens
Till skillnad från andra NoSQL-databassystem har Cassandra en justerbar konsekvensmodell. Program som gör förfrågningar till Cassandra för läs- och skrivåtgärder kan ange en konsekvensnivå som krävs från Cassandra för åtgärden. Programmet kan därför ange vilken konsekvensnivå som krävs för varje åtgärd. Cassandra har stöd för upp till fem konsekvensnivåer, enligt beskrivningen i följande tabell.
| Konsekvensnivå | Implikation för läsningar | Implikation för skrivningar |
|---|---|---|
| ZERO | Stöds inte för läsningar. | Skrivåtgärden returneras omedelbart utan bekräftelse. |
| ANY | Stöds inte för läsningar. Använd ONE i stället. | Minst en nod genomför skrivåtgärden, vilket tillåter tips att räknas som en skrivning (förklaras senare). |
| ONE | Returnerar omedelbart posten som innehas av den första noden som svarar på frågan. När läsbegäran har utförts utförs en läsreparation, om replikerna är inkonsekventa. | Se till att värdet skrivs till incheckningsloggen och memtabellen för minst en nod innan du återgår till klienten. |
| QUORUM | Fråga alla noder. Efter att en majoritet av replikerna $(\frac{replication\factor}{2} + 1)$ har svarat, återgå till klienten med den senaste tidsstämpeln. Utför sedan vid behov en läsreparation i bakgrunden på alla återstående repliker. Svaret skickas först efter att läsreparationen har avslutats. | Se till att skrivningen har tagits emot av minst en majoritet av replikerna $(\frac{replication\factor}{2} + 1)$. |
| ALL | Fråga alla noder. Vänta tills alla noder har svarat och gå tillbaka till klienten med den senaste tidsstämpeln. Utför sedan vid behov en läsreparation i bakgrunden. Svaret skickas först efter att läsreparationen har avslutats. Om några noder inte svarar kan läsåtgärden misslyckas. | Se till att antalet noder som anges av replikeringslänken tog emot skrivningen innan du återgår till klienten. Om så lite som en replik inte svarar på skrivåtgärden misslyckas åtgärden. |
Problemidentifiering i Cassandra
Aggregerad problemidentifiering
Med ingen centraliserad primär för att hålla reda på noderna i klustret använder Cassandra ett särskilt skvallerprotokoll för att kommunicera i alla noder i tokenringen. I Cassandra uttrycks felen som en sannolikhet med hjälp av en AFD-algoritm (aggregerad problemidentifiering)2, som kan sammanfattas på följande sätt.
Varje sekund kontaktar varje nod i Cassandra-token-ringen en annan slumpmässig medlem i ringen för att fråga om dess status. Denna kommunikation sker med hjälp av ett handskakningsprotokoll som liknar en TCP-handskakning. Om det inte går att kontakta noden uppstår ett misstänkt haveri. Därför ger systemet för felövervakning en kontinuerlig misstanke om hur säker det är att en nod har misslyckats, vilket är önskvärt eftersom det kan ta hänsyn till variationer i nätverksmiljön. Även om en anslutning fångas upp innebär det inte nödvändigtvis att hela noden är död. En misstanke ger därför en mer flytande och proaktiv indikation på svag eller stark risk för haveri som baseras på tolkning i stället för en enkel binär utvärdering, till exempel död eller levande i pulsslagsmetoder.
Hinted handoff
När data måste skrivas till en plats som inte längre kan kontaktas (på grund av haveri) implementerar Cassandra en strategi som kallas hinted handoff. Den nod som ursprungligen tog emot skrivbegäran identifierar att målnoden (där skrivningen ska utföras) är inaktiv. Noden skapar sedan en ledtråd (hint), som är en påminnelse om denna skrivåtgärd. Ledtråden är som när en person tar emot ett meddelande till någon annan som inte är närvarande. Tipset skulle vara att "Jag har den här skrivinformationen som är avsedd för nod X. Jag kommer att hålla fast vid den här skrivningen, och när jag märker att noden X har kommit tillbaka online skickar jag skrivbegäran till noden X." Med den här strategin kan Cassandra vara tillgängligt för skrivningar. Med skrivkonsekvensmodellen ANY räknas en hinted handoff som en lyckad skrivning.
ACID-egenskaper i Cassandra
Till skillnad från andra databassystem är Cassandras ACID-egenskaper helt konfigurerbara per åtgärd. Cassandras ACID-egenskaper är följande:
Atomicitet: Cassandra garanterar atomicitet i en kolumnfamilj för alla kolumner i en rad, om skrivning har sparats i minst en incheckningslogg.
Konsekvens: Genom att använda konsekvensmodellen ALLA eller KVORUM för läsningar och skrivningar anses Cassandra vara starkt konsekvent, men på bekostnad av tillgängligheten (eftersom läsningar och skrivningar kan misslyckas). Med de svagare konsekvensmodellerna (som ZERO, ANY, ONE och så vidare) kan prestanda bli högre (genom att svarstiden kortas för klienterna), men på bekostnad av konsekvensen.
Mer formellt kan konsekvensen i Cassandra uttryckas i följande formel:
- $W$ är antalet skrivrepliker.
- $W$ är antalet skrivskyddade repliker.
- $N$ är replikeringsfaktorn.
- Om $W + R > N$, är systemet starkt konsekvent.
Den här formeln innebär att en kombination av läs- och skrivåtgärder måste komma åt alla repliker för en viss rad för att åtgärden ska vara starkt konsekvent. Du bör till exempel ta hänsyn till tillstånd när $W = 1$ (för konsekvensnivån ONE) och $R = N$ (för konsekvensnivån ALL). I det här scenariot anses systemet vara starkt konsekvent. På liknande sätt gäller att om $W = N$ och $R = 1$ är systemet starkt konsekvent. Om vi tänker på ett QUORUM-tillstånd med Q definierat som $\frac{N}{2} + 1$, och om $W = R = Q$ (d.v.s. både läsningar och skrivningar görs i QUORUM-läge), anses systemet vara konsekvent.
Isolering: Eftersom version 1.1 kan Cassandra endast garantera isolering av en skrivåtgärd för en viss rad.
Hållbarhet: Under modellerna ALL, ONE och QUORUM är skrivningar garanterat hållbara (de skrivs till incheckningsloggen). Med modellerna ZERO och ANY är det inte säkert att skrivningarna blir varaktiga eftersom det inte finns någon garanti för att skrivningarna skrevs till incheckningsloggen för någon nod.
Cassandra-användnings fall
Cassandra är ett unikt datalagringssystem med användbara funktioner, till exempel justerbar konsekvens, hög tillgänglighet och skalbarhet. Cassandra distribueras bäst på ett stort antal servrar, vilket gör att användarna kan utnyttja funktionerna fullt ut.
Cassandra är också bland de mest kraftfulla för sin skrivningsprestanda, som delvis beror på arkitekturen och den justerbara konsekvensmodellen. Cassandra utvecklades främst för tillämpningar i sociala nätverk, där skrivningar är frekventa och läsåtgärder är mindre förutsägbara.
En annan användbar funktion i Cassandra är att det har direkt stöd för replikering över flera datacenter. Metoden för feltolerans är mer dynamisk jämfört med HBase eller Hadoop och tolkar inte långa svarstider som fel. Den schemafria datamodellen är också lämplig för tillämpningar som utvecklas, där ändringar ofta kan behövas.
Referenser
- Merkle, R. (1988). A digital signature based on a conventional encryption function Proceedings of CRYPTO (pp. 369–378). Springer-Verlag
- Hayashibara, Naohiro, m.fl. (2004). Den φ periodiseringsfeldetektorn Reliable Distributed Systems, Proceedings of the 23rd IEEE International Symposium on Reliable Distributed Systems
- DeCandia, Giuseppe, m.fl. (2007). Dynamo: Amazons nyckelvärdesbutik ACM SIGOPS Operating Systems Review med hög tillgänglighet. Vol. 41. Nr 6 ACM