Molnobjektlagring: OpenStack Swift och Ceph Object Gateway
OpenStack Swift är en objektlagringstjänst som ingår i molnplattformen OpenStack. Swift erbjuder klienterna ett REST-baserat HTTP-gränssnitt för interaktion med binära objekt, ungefär som Azure Blob Storage. Swift är kostnadsfritt med öppen källkod, och är tillgänglig för alla som ska installera och konfigurera på valfri dator. Tillhandahåller objektlagring i både offentliga och privata moln.
Swift-datamodell och API:er
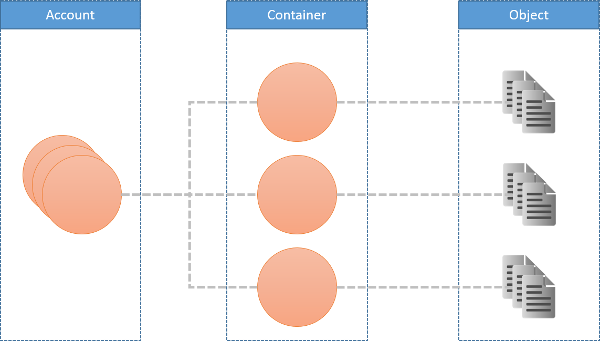
Bild 11: Swift-datamodell
I Swift har användarna tillgång till ett konto. Kontot kan användas för att definiera containrar, som kan användas för att lagra objekt. Anta till exempel att en användare med ett konto 123456 i den Swift-tjänst som körs på swift.mycloud.com lagrar objektet med namnet picture.jpg i containern images. Den fullständiga sökvägen för åtkomst till ett objekt i det här exemplet skulle vara:
https://swift.mycloud.com/v1/123456/images/picture.jpg
Eftersom Swift använder ett RESTful-gränssnitt används vanliga HTTP-åtkomstverb som GET, PUT och POST. Eftersom SWIFT-API:et är skapat med S3-API:et som modell liknar API:ets funktion och de åtgärder som stöds varandra. Kommandon är tillståndslösa och känsliga för det sammanhang där de tillämpas. Ett GET-kommando på en container visar en lista över alla objekt som lagras i containern, medan kommandot GET på ett objekt hämtar objektet. En fullständig lista över Swift-åtgärder finns i API-referensen (Swift API). Det måste noteras att S3 och SWIFT inte är 100 % API-kompatibla. S3-API-begäranden som är relaterade till fakturerings- och AWS-regioner replikeras till exempel inte i Swift.
Det måste noteras att Swift även har stöd för autentiserad åtkomst för användare som försöker få åtkomst till tjänsten (som oautentiserad, offentlig åtkomst till en Swift-tjänst). Swift integreras i OpenStacks egen autentiseringstjänst Keystone.
Swift-arkitekturen
Swift använder en arkitektur med flera nivåer för prestanda, feltolerans, tillförlitlighet och hållbarhet. Precis som andra distribuerade datalager använder Swift replikering för feltolerans. Som vi angav i diskussionen om Swifts API måste Swift ha information om konton, containrar och objekt. Därför kör Swift oberoende processer för att hålla reda på informationen om vart och ett av de här lagren i klustret.
De olika komponenterna i Swift-arkitekturen är följande:
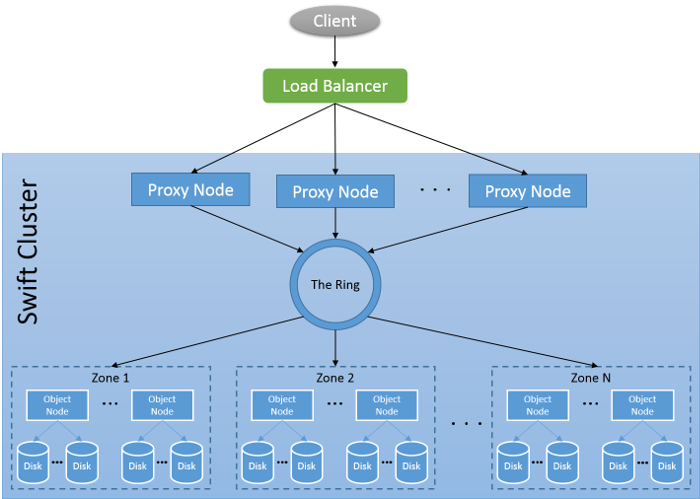
Bild 12: Swift-klusterarkitektur
Proxynoder: Det här är klientdelsservrarna som bearbetar inkommande API-begäranden. Ett Swift-kluster kan ha flera proxyservrar för att hantera större belastningar av inkommande begäranden. Proxyservern avgör vilken underordnad server som begäran ska skickas till. Proxyservrarna koordinerar även svar och hanterar problem.
Objektnoder: Det här är de faktiska objektlagringsenheterna som kan lagra eller hämta objekt.
Zoner: Swift gör att tillgänglighetszoner kan konfigureras för att isolera felgränser. Varje replik av informationen ligger i en separat zon, om möjligt. På den lägsta nivån kan en zon vara en enda objektserver eller en gruppering av några objektservrar. Zoner används för att organisera server och partitioner så att systemet klarar minst ett haveri per zon utan att data eller tjänsttillgänglighet går förlorade.
Dataplacering i Swift
Ringar: En ring representerar en mappning mellan namnen på konto/container/objekt och deras fysiska plats. Det finns separata testgrupper för konton, containrar och en objekttestgrupp per lagringsprincip (förklaras nedan). När andra komponenter behöver utföra en åtgärd på ett objekt, en container eller ett konto måste de interagera med lämplig testgrupp för att fastställa dess plats i klustret. Testgruppen bibehåller mappningen med hjälp av zoner, objektservrar, partitioneroch repliker. Varje partition i testgruppen replikeras som standard tre gånger i klustret, och platserna för en partition lagras i den mappning som hanteras av testgruppen. Testgruppen ansvarar även för att avgöra vilka enheter som används för leverans i haveriscenarier.
Partition: Swift använder konsekvent hashning för att avgöra vilka objektnoder i en zon som ska lagra vilka objekt. Varje del av testgruppen för konsekvent hashning kallas en partition.
Lagringsprincip: Lagringsprinciper är ett sätt för objektlagringsleverantörer att särskilja tjänstnivåer, funktioner och beteenden för en Swift-distribution. Varje lagringsprincip som konfigurerats i Swift exponeras för klienten via ett abstrakt namn. Varje enhet i systemet tilldelas till en eller flera lagringsprinciper. Detta åstadkoms med flera objekttestgrupper, där varje lagringsprincip har en oberoende objekttestgrupp som kan innehålla en delmängd maskinvara som implementerar en viss differentiering. Med lagringsprinciper kan en molnleverantör tillhandahålla snabb SSD-baserad åtkomst till objekt för en klient med ett högre serviceavtal, samtidigt som traditionell diskbaserad lagring tillhandahålls till en annan klient med ett annat serviceavtal.
Vi ska titta på ett exempel på hur objektåtgärder utförs i Swift. Vi antar att en klientbegäran består av en PUT-begäran för ett objekt till en viss container. Begäran tas först emot av en proxynod, som först autentiserar begäran för att säkerställa lämplig åtkomst. Proxyservern tar sedan objektnamnets hash och letar upp alla tre partitionsplatserna, enheterna, där data ska lagras med hjälp av objekttestgruppen. Processen använder sedan objekttestgruppen för att leta upp IP och annan information för de tre enheterna.
När platsen för alla tre partitionerna har fastställts skickar proxyservern objektet till var och en av lagringsnoderna, där det placeras i lämplig partition. När ett kvorum uppnås returneras minst två av de tre skrivningarna som lyckade, och därefter meddelar proxyservern klienten att uppladdningen lyckades. Swift använder alltså Quorum-skrivningar som en konsekvensfunktion. Slutligen uppdateras containerlagret asynkront för att återspegla det nya objekt som det innehåller.
Konsekvensmodell i Swift
Swift är utformat för att vara ett konsekvent system. Alla data i Swift replikeras mellan zoner, och objekten har också versioner. Swift kör särskilda användningsprocesser som kallas replikerare, som övervakar tillståndet för konton, containrar och objekt. Om de hittar en ny entitet eller en uppdaterad version av en entitet säkerställer de att data replikeras till andra servrar enligt klustrets replikeringsprincip.
Swift använder särskilda processer som kallas granskare, som söker igenom data som lagrats i ett Swift-kluster för att säkerställa att de inte är komprometterade. Granskaren beräknar om en kontrollsumma för varje objekt för att se till att de matchar. Om det finns några skillnader flyttas objektet till ett karantänutrymme och lagringsadministratören meddelas och uppmanas att undersöka detta.
Ceph Object Gateway
Vi avslutar vår diskussion om molnobjektlager med att prata om Ceph Object Gateway, även kallat RADOSGW. RADOSGW är ett ytterligare lager över Ceph Storage Cluster (RADOS) som tillhandahåller ett RESTful HTTP-gränssnitt för att interagera med objekt som lagras på RADOS. Ceph Object Gateway är unik i sin förmåga att stödja både Amazon S3- och SWIFT-API:er så att program kan migreras till respektive plattform. RADOSGW replikerar de datamodeller som används i Amazon S3 och Swift och tillhandahåller liknande funktioner som de båda tjänsterna.