Dataströmbearbetningssystem
Ramverken som vi har tittat på hittills (MapReduce, Spark, GraphLab) har främst utformats för att utföra batchberäkningar. Deras indata är normalt stora distribuerade datamängder, som bearbetas i flera timmar för att ge stora, användbara utdata. Användningen av dessa ramverk begränsades ursprungligen till dataforskare och programmerare, som använde dem för specifika, stora frågor där den höga latensen kunde tolereras. Men när användningen av stordata växte sig större i företag skedde en övergång till ad hoc-frågekörningar på data, med förväntande svarstider på minuter, inte timmar. Verktyg som Pig, Hive, Shark och Spark SQL gjorde så att många företag kunde ställa komplexa frågor för sina data, utan att behöva förlita sig på en stor pool med högutbildade programmerare. Molnet drev detta ännu längre, med en elastisk tillgång till beräkningsresurser under körningen av en ad hoc-fråga.
Snart förväntades ännu kortare svarstider. Stordata började tas emot i realtid och var ofta bara värdefulla under en kort tid. Till exempel krävde sökmotorer att den bästa kombinationen av annonser skulle hanteras inom några millisekunder för varje frågor, och webbplatser för sociala medier identifierade populära ämnen och hashtaggar och systemövervakningsverktyg identifierade komplexa mönster i flera stora infrastrukturkomponenter. För att kunna tillhandahålla sådan låg latens började en ny klass av dataströmbearbetningsramverk ta form. Dessa hade helt andra krav och begränsningar jämfört med de tidigare systemen med batchbearbetning och interaktiv bearbetning.
Det ledde till framväxten av dataströmbearbetningssystem.
Dataströmbearbetning
Dataströmbearbetningsparadigmet tillämpar en serie åtgärder på varje element av data som genereras av en oändligt lång indatakälla. Serien av åtgärder används generellt i pipeline, vilket lägger till beroenden mellan åtgärder. I bearbetningsprogrammet läses ofta tillståndsinformation från och skrivs till en liten, snabb datakälla. Utdata från en pipeline med dataströmåtgärder är också en dataström. Detta kan användas till att utlösa andra program eller kan buffras och lagras i stabilt lagringsutrymme. Den grundläggande arkitekturen för ett sådant system visas nedan.
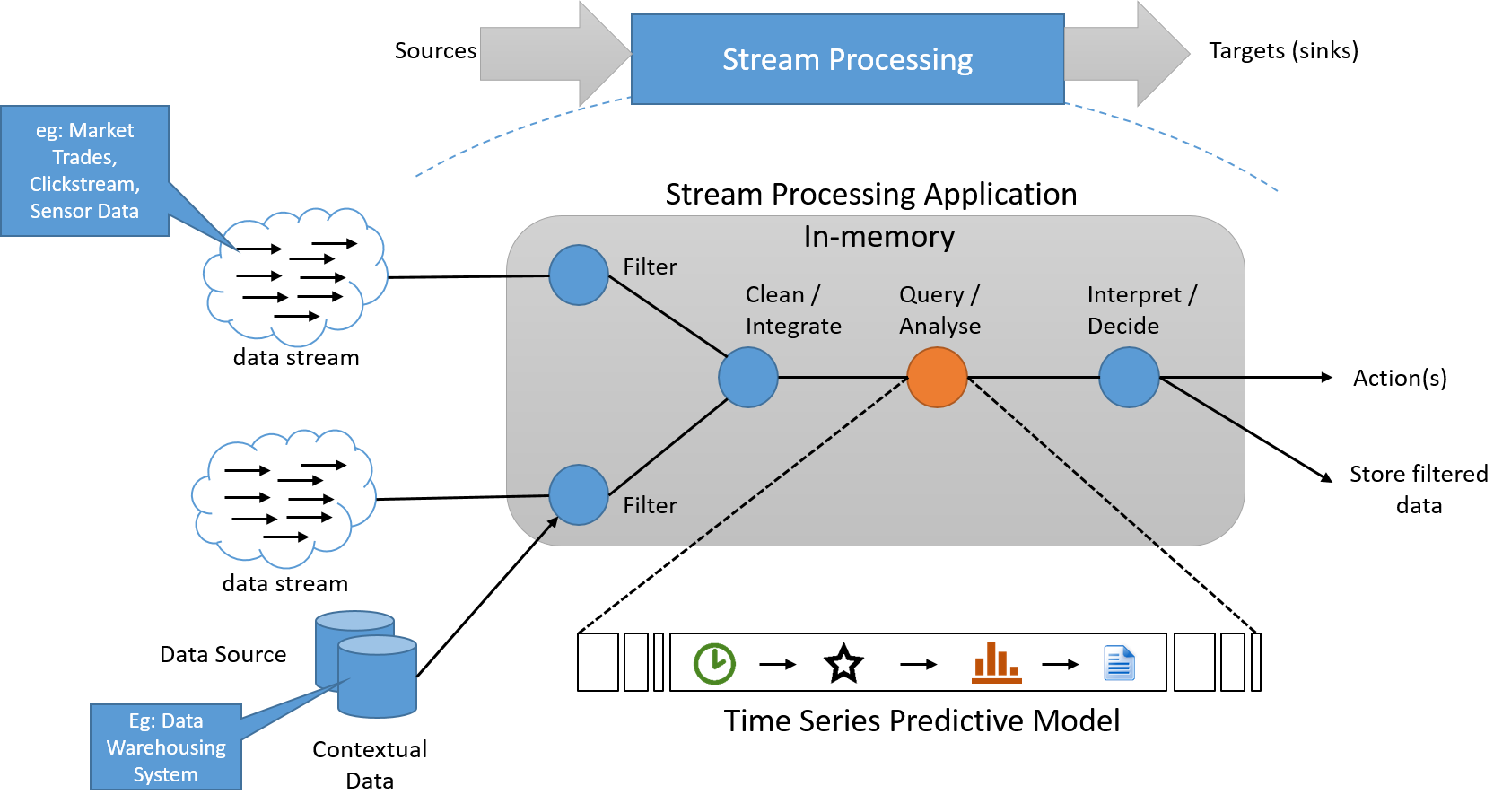
Bild 6: Ett dataströmbearbetningssystem måste bearbeta data i dataströmmen, med en separat pipeline för lagring, om det behövs, som inte ligger på den "kritiska sökvägen"
Åtta regler för dataströmbearbetning
Stonebraker et. Al. beskriver åtta grundregler för dataströmbearbetningssystem.
Regel 1: Håll data i rörelse
Ett realtidsbaserat dataströmbearbetningsramverk måste kunna bearbeta meddelanden ”i strömmen” utan att behöva lagra den på disk, vilket ger oacceptabel fördröjning på den kritiska vägen. Dessutom ska de här systemen vara aktiva (händelsedrivna) och inte passiva (där program måste avsöka resultatet för att identifiera förhållanden av intresse).
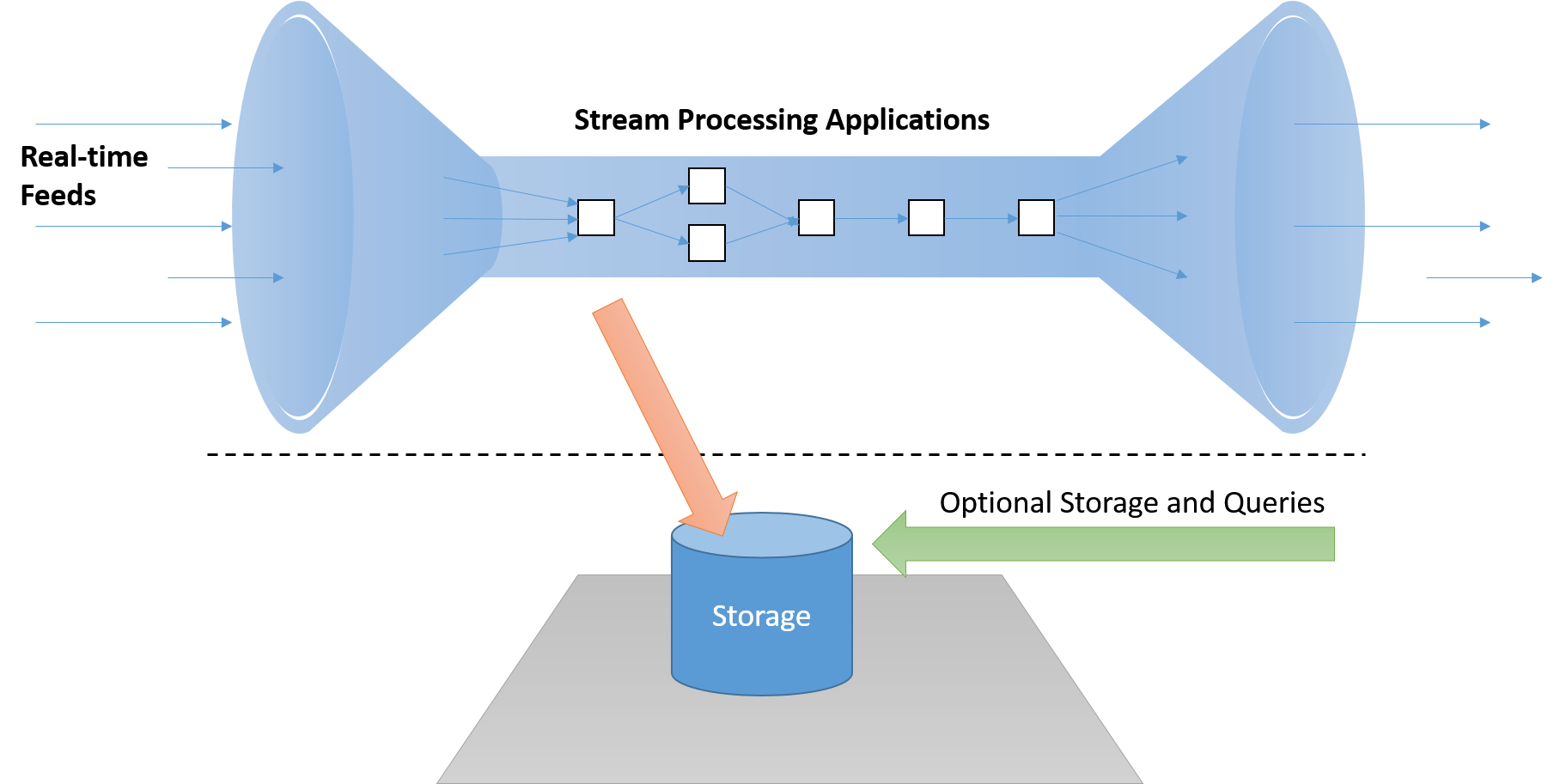
Bild 7: Ett dataströmbearbetningssystem måste bearbeta data i dataströmmen, med en separat pipeline för lagring, om det behövs, som inte ligger på den "kritiska sökvägen"
Regel 2: Flöden bör ha stöd för frågor med SQL
SQL har vuxit fram som en vida använd och välbekant standard för körningar av frågor på data. Men traditionell SQL fungerar på en fast mängd data, där frågan har slutförts när den har nått slutet av tabellen. I strömningsscenarier ökar data kontinuerligt. Stonebraker et. Al. uppfattade behovet av ett StreamSQL-språk, med tidsbaserade skjutfönster med variabel längd som definierar en frågas omfattning. Fönster kan definieras med tid, antal meddelanden eller några godtyckliga parametrar. Ytterligare operatorer kan behövas för att slå samman meddelanden från flera dataströmmar.
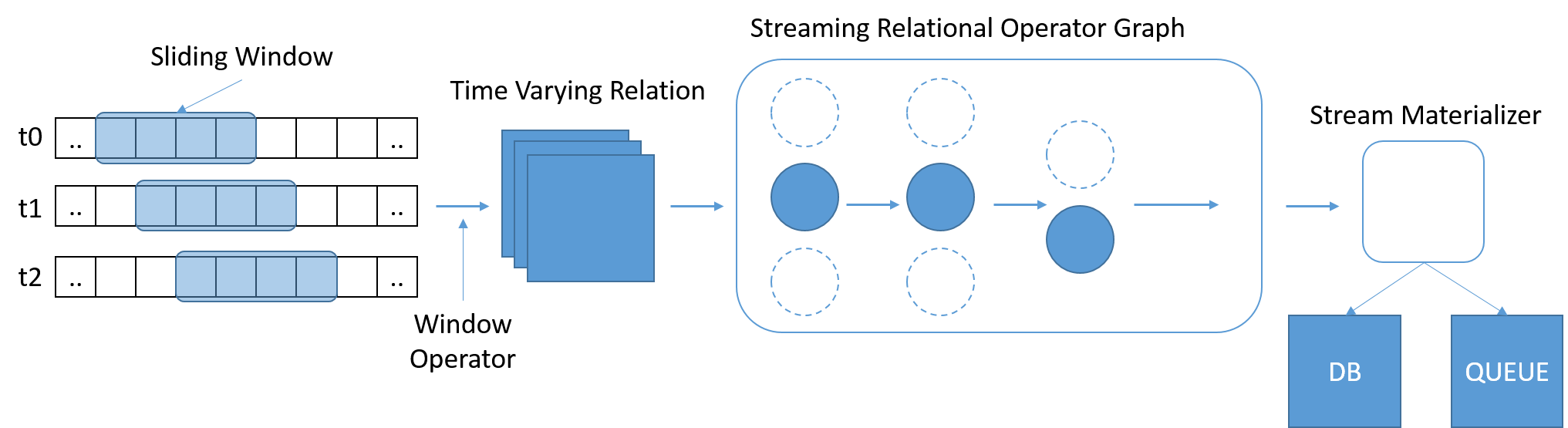
Bild 8: StreamSQL bör bearbeta delmängder av data och tillåta att relationer uttrycks mellan fönster
Regel 3: Hantera strömfel
I realtidssystem kan data förloras, försenas eller komma i fel ordning. Ett dataströmbearbetningssystem kan inte vänta oändligt på data men kanske inte heller har flexibiliteten att ignorera eller missa några data. Sådana system måste vara motståndskraftiga mot brister i dataströmmen, med mekanismer som konfigurerbara tidsgränser och ”slappa tider”, när sen ankomst kan accepteras.
Regel 4: Generera förutsägbara resultat
Resultatet av ett dataströmbearbetningssystem måste vara deterministiskt och upprepningsbart genom att spela upp dataströmmen igen. Det är särskilt svårt när systemet fungerar på flera samtidiga dataströmmar eller när meddelanden kommer i fel ordning. Meddelanden måste skapas i stigande tidsordning, oavsett ankomsttid. Den här egenskapen möjliggör även feltolerans, genom att göra det rimligt att spela upp dataströmmar igen där bearbetningen har misslyckats.
Regel 5: Integrera lagrat tillstånd
Dataströmbearbetningsprogram måste ofta kombinera nutid och dåtid. När till exempel en annons rekommenderas för en användaren måste en sökmotor kombinera den aktuella informationen om sökordet och det aktuella tillståndet för annonsmarknaden, med tidigare information om användarens klickvanor. Integrering av lagrat tillstånd och strömningsdata möjliggör även sömlös växling, varigenom en algoritm kan testas på historiska data och sedan växlas över till liveuppspelningen när den fungerar tillfredsställande. Data ska lagras i samma systemutrymme som programmet, kanske med hjälp av en inbäddad databas, för tillåta användningen av ett enhetligt språk som hanterar lagrade och strömmande data.
Regel 6: Garantera hög tillgänglighet
Dataströmbearbetningssystem fungerar i realtid och kan ofta inte tolerera omstartsåterställningar. Sådana system måste tillåta snabb växling till säkerhetskopia eller skugga, som måste synkroniseras regelbundet med det primära. Integriteten för data måste garanteras, enligt regel 4.
Regel 7: Stöd för partitionering och automatisk skalning
Distribuerad bearbetning är standardåtgärdsmodellen för alla stora system. En bra dataströmbearbetningsarkitektur ska var icke-blockerande och utnyttja moderna flertrådsarkitekturer. Dessutom ska den kunna hantera ut- eller inskalning av systemet på egen hand, genom att lägga till eller ta bort datorer, antingen baserat på ökade eller minskade datavolymer eller på bearbetningsfördröjningar eller komplexitet. Dessutom måste den automatiskt och transparent utföra belastningsutjämning på de tillgängliga datorerna. Slutanvändaren borde inte behöva hantera något av den här komplexiteten.
Regel 8: Kontrollera att den kan hålla jämna
Alla systemkomponenter ska utformas för höga prestanda, med ett minimalt antal åtgärder utanför kärnan. Systemet måste testas utifrån målarbetsbelastningen och målen för dataflöde och svarstider måste valideras.
Utvecklingen för dataströmbearbetningsmotorer
Aurora (2002) var ett av de tidigaste dataströmbearbetningssystemen, som även det utvecklades av Stonebraker med flera på MIT och Brown University. Aurora hanterade dataströmbearbetningsproblemet som en riktad acyklisk graf (DAG).
Strömindata är en sekvens obundna tupler (a1, a2, ..., an) över tid som flödar från uppströms (start) till nedströms (utdata). Ett helt program kan skapas genom att lägga till olika kombinationer av bearbetningsrutor och rita länkar mellan dem. Aurora var ett system med en enda nod, som saknade många av skalbarhetskraven på en dataströmbearbetningsmotor. En ny version av Aurora med namnet Aurora* (2003) skapades för att kombinera många Aurora-noder över ett nätverk. På så sätt uppnåddes skalbarhet genom partitionering av de olika faserna av dataströmbearbetningsjobbet på olika fysiska noder. Till sist lade Medusa-projektet (2003) till stöd för federation i Aurora, vilket gjorde det möjligt med samarbete och delning för flera användare.
Borealis (2005) var nästa tillägg i Aurora-projektet, som lade till stöd för hög tillgänglighet med hjälp av aktiv replikering. Replikerna synkroniserades noga för att ge datakonsekvens.
Apache Storm (2011) var en dataströmbearbetningsmotor som utvecklades av Twitter. Här kan bearbetningsnoderna (Bolts) prenumerera på dataströmmar från olika källor (Spouts) och därmed möjliggöra en enklare prenumerantmodell för beräkning. Storm ger garanterad meddelandebearbetning, oavsett nodfel, och möjliggör exakt en gång-semantik för att se till att data varken underberäknas eller överberäknas. Apache S4 (2011) var ett liknande prenumerationssystem som utvecklades på Yahoo!. Det är symmetriskt i den meningen att alla noder är lika och det inte finns någon centraliserad kontroll, i förhoppningen att göra det skalbart. S4 hade inte stöd för att dynamiskt lägga till eller ta bort noder till och från ett kluster som körs. Apache Samza (2013) är ett annat system för flera prenumeranter i den här formen som vi kommer att utforska i mer detalj.
Storm, Samza och S4 följer den traditionella strömningsmodellen, så kallad ”record-at-a-time”-bearbetning. I den här modellen bearbetar tillståndskänsliga operatorer med hjälp av nya data för att ändra internt tillstånd och sedan generera nya poster. Feltolerans och återställning utförs med replikering, antingen genom att göra flera kopior av bearbetningselement eller genom att buffra och lagra säkerhetskopior av meddelanden uppströms och skicka dem igen nedströms, vid fel. Ock eftersom layouten för DAG växer sig mer komplex är det svårt att garantera konsekvens mellan olika vägar. Slutligen är det inte obetydligt att kombinera dessa ramverk med batchsystem och görs ofta med hjälp av Lambda-arkitekturen (diskuteras senare).
En annan metod för att utforma dataströmbearbetningssystem tillhandahålls av Spark Streaming (2012), som tillhandahåller "mikrobatchbearbetning". Mikrobatchbearbetning konverterar dataströmberäkningar till en uppsättning extremt snabba beräkningar, med svarstider från hundratals millisekunder till några sekunder. På bekostnad av ökad latens gör det här det enklare att ge feltolerans och exakt en gång-semantik för resultatet för varje mikrobatch.
Att välja rätt ramverk att använda för en uppgift är en faktor för de förväntade garantierna för latens, feltolerans och meddelandeleverans samt kompetensuppsättningen för användarna och önskade utvecklingskostnader. I nästa enhet utforskar vi de interna egenskaperna i dessa ramverk mer detaljerat, genom att studera Apache Samza.