Arkitekturer för stordatabearbetning
I den här modulen har vi tagit upp grundidéerna bakom distribuerad programmerings- och analysmotorer samt utmaningarna med storskalig stordatabearbetning. Vi har sett ett antal ramverk, som MapReduce, Spark och GraphLab, och dataströmbearbetningsramverk. För att fortsätta diskussionen presenterar vi nu några av de pågående försöken att definiera ett arkitekturparadigm för att hjälpa till att bygga system som kan hantera både realtidsdata och historiska data: Lambda- och Kappa-arkitekturen.
Till exempel använder digitala assistenter som Microsoft Cortana ofta komplexa maskininlärningsalgoritmer för taligenkänning och för att förstå användarnas frågor. Inkommande frågor kan anses vara en ström som måste besvaras i låg latens. Men med tiden kan historiska data från användarfrågor användas för att träna om maskininlärningssystemet för bättre taligenkänning och frågeförståelse. Det senare använder någon form av batchbearbetningssystem för att uppdatera maskininlärningsmodellerna för framtida frågor.
Lambda-arkitektur
Lambda-arkitekturen är en databehandlingsarkitektur utformad att hantera stora mängder data genom att utnyttja både batch- dataströmbearbetningsmetoder. Lambda försöker balansera latens, dataflöde och feltolerans genom att använda batchbearbetning för att tillhandahålla omfattande och exakta vyer av batchdata, och samtidigt använda dataströmbearbetning i realtid för att tillhandahålla vyer av onlinedata.
Lambda-arkitekturen beskriver ett system som består av tre lager: batchlagret, hastighetslagret (eller realtidslagret) bearbetningslagret och ett betjänande lager för att svara på frågor.
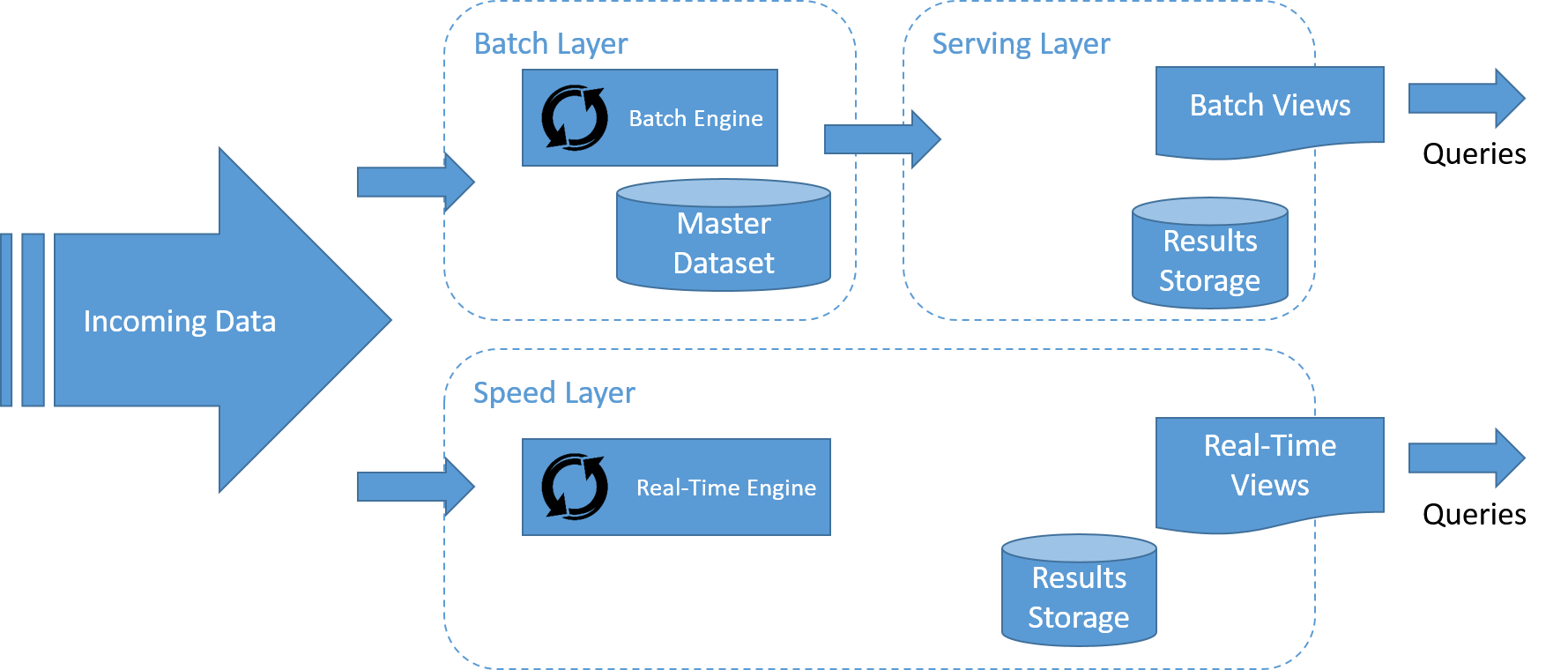
Bild 16: Ett dataströmbearbetningssystem måste bearbeta data i dataströmmen, med en separat pipeline för lagring, om det behövs, som inte ligger på den "kritiska sökvägen".
Flödet av data i Lambda-arkitekturen representeras i bilden. Stegen är följande:
- Alla data som matas in i systemet skickas till både batchlagret och hastighetslagret för bearbetning.
- Batchlagret hanterar huvuddatamängden och förberäknar batchvyerna.
- Det betjänande lagret indexerar batchvyerna så att de kan frågas med korta svarstider och ad hoc.
- Hastighetslagret bygger realtidsvyer av inkommande data på ett sätt som är mycket snabbare än batchlagret och det betjänande lagret, men kanske inte med samma precision.
- Alla inkommande frågor kan besvaras genom att slå samman resultat från batchvyer och realtidsvyer.
Batchlager
Batchlagret har viktiga funktioner i Lambda-arkitekturen:
- För det första hanterar batchlagret normalt huvuddatamängden. Huvuddatamängden är sanningskällan i Lambda-arkitekturen och kan användas för att rekonstruera data som hanteras av systemet vid fel i något av lagren i systemet. Data i batchlagret organiseras vanligtvis som en oföränderlig logg, som innehåller nya data när de kommer in i systemet.
- För det andra bygger batchlagret batchvyerna av data. Batchlagret siktar på perfekt eller nära perfekt precision genom att kunna bearbeta alla tillgängliga data vid generering av batchvyerna. Det betyder att det kan korrigera fel genom att göra omberäkningar mot hela datamängden och sedan uppdatera de befintliga batchvyerna. Utdata från batchlagret lagras i det betjänande lagret.
Apache Hadoop är det faktiska standardinställda batchbearbetningssystemet som används i de flesta arkitekturer med höga dataflöden och är det vanligaste valet för implementering av batchlagret. Bearbetningen kan göras med MapReduce eller något av batchbearbetningssystemen på högre nivå som bygger på Hadoop.
Betjänande lager
Utdata från batchlagren (batchvyerna) lagras i det betjänande lagret och görs tillgängliga för frågor av program. Det är nära knutet till batchlagret. Det betjänande lagret distribueras vanligtvis på många datorer för skalbarhet. Det betjänande lagret består normalt av någon typ av databas och är vanligtvis NoSQL. Det betjänande lagrets krav är följande:
- Skrivbar batch: Batchvyerna för ett serveringslager skapas från grunden. När en ny version av en vy blir tillgänglig måste den äldre versionen möjligen helt bytas ut mot den uppdaterade vyn. Därför behöver system med betjänande lager inte optimeras för snabba slumpmässiga skrivningar, till skillnad från traditionella databassystem.
- Skalbar: En serverlagerdatabas måste kunna hantera vyer av godtycklig storlek. Som med distribuerade filsystem och batchberäkningsramverk som diskuterats tidigare kräver detta att den distribueras på flera datorer.
- Slumpmässiga läsningar: En databas för serveringslager måste ha stöd för slumpmässiga läsningar, med index som ger direkt åtkomst till små delar av vyn. Det här kravet är nödvändigt att ha låg latens för frågor.
- Feltolerant: Eftersom en serverlagerdatabas är distribuerad måste den vara tolerant mot datorfel.
Vanliga exempel på datalager som används i det betjänande lagret är Apache Hive, HBase och Impala.
Hastighetslager
Hastighetslagret bearbetar dataströmmar i realtid med den lägsta möjliga latensen för att generera realtidsvyer av data. I stort sett är hastighetslagret ansvarigt för att fylla ”luckan” som orsakas av batchlagrets fördröjning i att tillhandahålla vyer som baseras på de senaste data.
Det här lagrets vyer kanske inte är så exakta eller kompletta som dem som slutligen skapas av batchlagret men de är tillgängliga nästan direkt efter att data tas emot och kan ersättas när batchlagrets vyer för samma data blir tillgängliga. Med hjälp av stegvisa metoder eller metoder för dataströmbearbetning som vi diskuterade tidigare i den här modulen kan bearbetningen göras på ett effektivare sätt om beräkningen kan uttryckas som en funktion för den tidigare realtidsvyn och senaste data, för att skapa de uppdaterade realtidsvyerna.
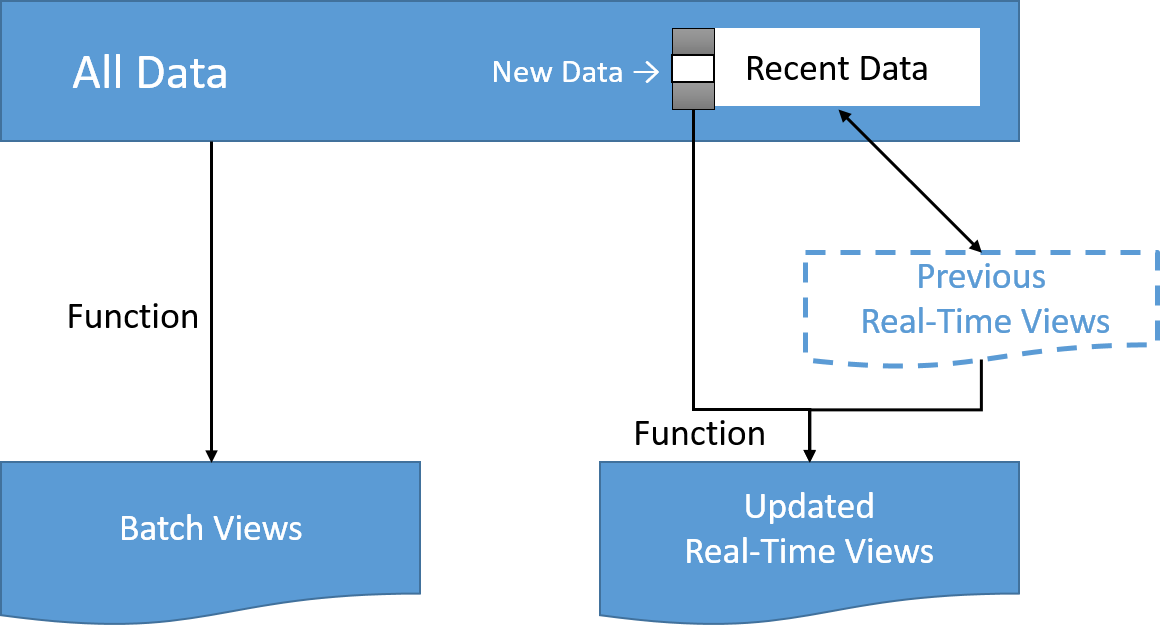
Bild 17: Ett dataströmbearbetningssystem måste bearbeta data i dataströmmen, med en separat pipeline för lagring, om det behövs, som inte ligger på den "kritiska sökvägen".
Tekniker för dataströmbearbetning som vanligtvis används i det här lagret är till exempel Apache Samza, Apache Storm, SQLstream och Apache Spark. Utdata lagras normalt i snabba NoSQL-databaser för frågor med korta svarstider.
Kappa-arkitektur
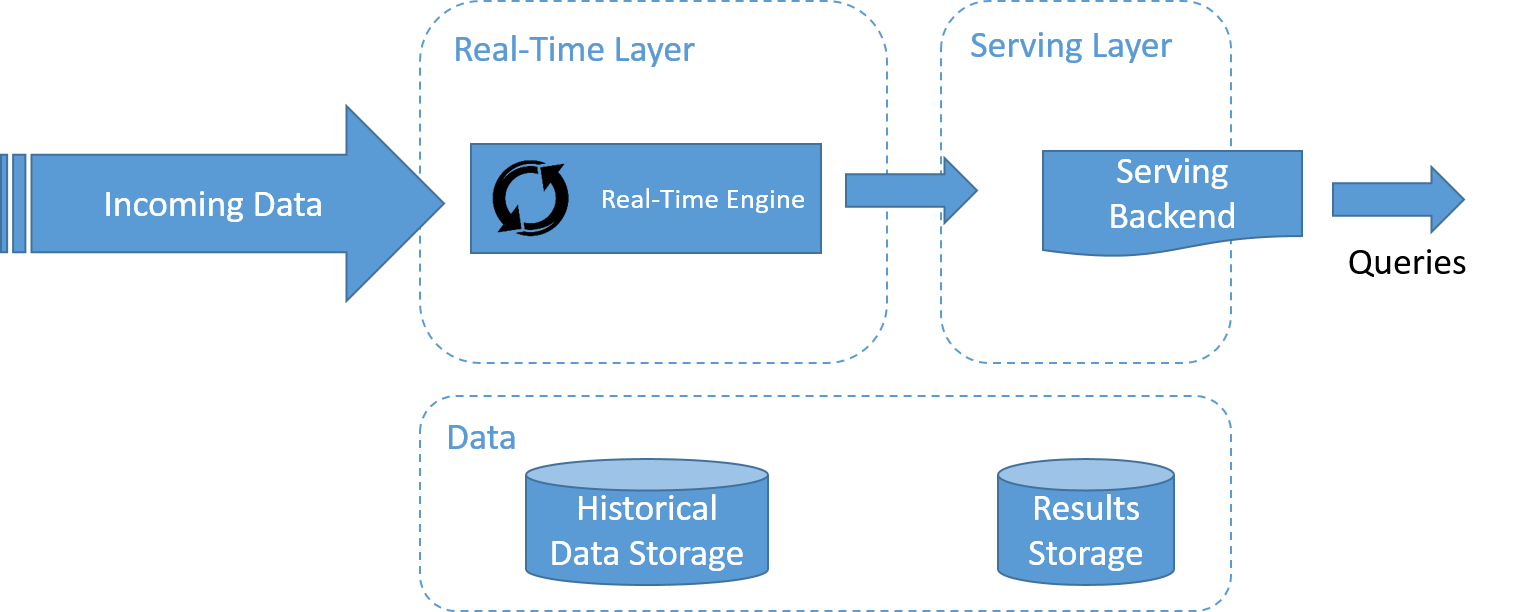
Bild 18: Ett dataströmbearbetningssystem måste bearbeta data i dataströmmen, med en separat pipeline för lagring, om det behövs, som inte ligger på den "kritiska sökvägen".
Kappa-arkitektur, som har spridits av LinkedIn, visas i bilden. En av de viktigaste motiveringarna för Kappa-arkitekturen var att undvika att ha två separata kodbaser för batch- och hastighetslager. Huvudidén är att hantera både databehandling i realtid och kontinuerlig ombearbetning av data med en enda dataströmbearbetningsmotor.
Ombearbetning av data är ett viktigt krav för att synliggöra effekterna av kodändringar för resultatet. Därför består Kappa-arkitekturen bara av två lager: dataströmbearbetning och betjäning.
Dataströmbearbetningslagret kör dataströmbearbetningsjobben. Normalt körs ett enda dataströmbearbetningsjobb för att aktivera databehandling i realtid. Ombearbetning av data görs bara när kod i dataströmbearbetningsjobbet måste ändras. Det här uppnås genom att köra ett annat ändrat dataströmbearbetningsjobb och spela upp alla tidigare data igen. Slutligen, liksom Lambda-arkitekturen används det betjänande lagret för att köra frågor på resultatet.
Lambda vs Kappa-arkitekturen är en pågående debatt i communityn för bearbetning av stordata. Valet av arkitektur beror på vissa egenskaper i programmet som ska implementeras. En enkel metod som har föreslagits av Ericsson är följande:
- Om algoritmerna som används för historiska data och realtidsdata är identiska är det allmänt sett bättre att välja Kappa-metoden. Någon form av batchberäkning kan vara nödvändig för att starta vyerna, beroende på mängden historiska data och takten för inkommande nya data.
- I vissa typer av program, till exempel maskininlärningsprogram, skiljer sig utdata för batchen och realtidssystem i precision på grund av mängden data som beräkning görs på. Det gör det mycket svårt att slå samman batch- och realtidsbearbetningsresultat i en konsekvent vy, och en Lambda-baserad arkitektur kan vara bättre för programmet.
- I vissa fall kan batchalgoritmen optimeras tack vare att den har åtkomst till hela historiska datamängden, och sedan överträffa (när det gäller dataflöde för bearbetning) realtidsalgoritmen. Att välja mellan Lambda och Kappa blir här ett val mellan att prioritera batchkörningsprestanda över enkel kodbas.