Integrera datalager med IoT-pipelines
Nu när du har implementerat Cosmos DB måste du bestämma hur du kan integrera den med Azure IoT-tjänster. Du planerar att utforska dess användning av alternativ för både varm och kall sökväg. Den här utforskningen gör det enklare att ta hänsyn till inventering av smarta installationer och scenarier för enhetstelemetri som ingår i din molnbaserade programdesign. Du vill också identifiera andra datalager som du kanske kan använda i din design.
Vad är Azure Cosmos DB-specifika designöverväganden?
När du utformar Azure Cosmos DB-databas- och containerhierarkin är rätt val av partitionsnyckel viktigt för att säkerställa optimal prestanda och effektivitet. Det här valet är relevant i IoT-scenarier som vanligtvis omfattar stora mängder strömmande data.
När du väljer den lämpligaste partitionsnyckeln bör du överväga användningsmönstren och gränsen på 20 GB för storleken på en enskild logisk partition. I allmänhet är bästa praxis att skapa en partitionsnyckel med hundratals eller tusentals distinkta värden. Den här metoden leder till en balanserad användning av lagrings- och beräkningsresurser mellan de objekt som är associerade med dessa partitionsnyckelvärden. Samtidigt får den kombinerade storleken på objekt som delar samma partitionsnyckelvärde inte överstiga 20 GB.
När du till exempel samlar in IoT-data kan du välja att använda egenskapen /date för telemetriströmning och /deviceId för enhetsinventering, om dessa egenskaper representerar målen för de vanligaste datafrågorna. Du kan också skapa en syntetisk partitionsnyckel, till exempel en sammanlänkning av värdena för /deviceId och /date. En annan metod är att lägga till ett slumpmässigt tal inom ett angivet intervall i slutet av partitionsnyckelvärdet. Den här metoden hjälper till att säkerställa en balanserad fördelning av arbetsbelastningen över flera partitioner. På så sätt kan du utföra parallella skrivningar över flera partitioner när du läser in objekten i målsamlingen.
Vad är datapipelines i IoT-scenarier?
En vanlig förekomst i IoT-scenarier är implementeringen av flera samtidiga datasökvägar, antingen genom att partitionera den inmatade dataströmmen eller genom att vidarebefordra dataposter till flera pipelines. Motsvarande arkitekturmönster kallas Lambda-arkitektur och består av två olika typer av pipelines.
En snabb (frekvent) bearbetningspipeline:
- Utför bearbetning i realtid.
- Analyserar data.
- Visar datainnehåll.
- Genererar kortsiktig, tidskänslig information.
- Utlöser motsvarande åtgärder, till exempel aviseringar.
- Lagrar data i ett arkiv.
En långsam (kall) bearbetningspipeline:
- Utför mer komplex analys, vilket potentiellt kombinerar data från flera källor och under en längre tidsperiod.
- Genererar artefakter som rapporter eller maskininlärningsmodeller.
Vilken roll har Azure-tjänster för att implementera IoT-pipelines?
IoT-system matar in telemetri som genereras av en mängd olika enheter, bearbetar och analyserar strömmande data för att härleda insikter i nära realtid och arkivera data till kall lagring för batchanalys. Datasökvägen börjar med telemetri som genereras av IoT-enheter som skickas för inledande bearbetning till Azure IoT Hub eller Azure IoT Central. Både Azure IoT Hub och Azure IoT Central lagrar insamlade data under en konfigurerbar tidsperiod.
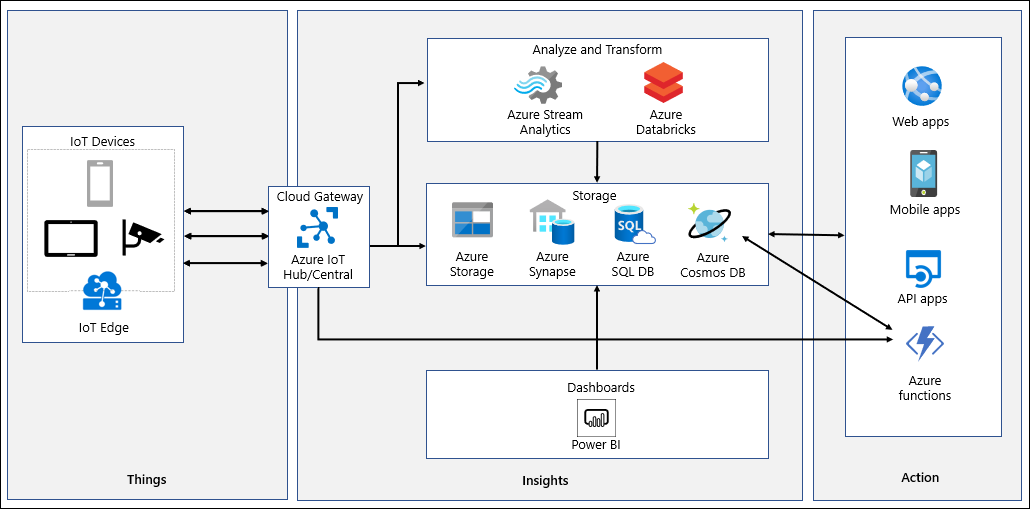
Azure IoT Hub stöder partitionering och meddelanderoutning, vilket gör att du kan ange specifika meddelanden för bearbetning, aviseringar och reparationsuppgifter av Azure Logic Apps och Azure Functions. Motsvarande funktioner är tillgängliga i Azure IoT Central och baseras på dess anpassade konfigurerade regler som utlöser åtgärder via webhooks. Webhooks kan peka på Azure Functions, Azure Logic Apps, Microsoft Flow eller dina egna anpassade appar. Med Azure IoT Hub-vägar kan du också vidarebefordra telemetri till en Azure-funktion för inledande bearbetning och sedan vidarebefordra den till Azure Cosmos DB. Exempel på sådan bearbetning är formatkonvertering eller konstruktion av en syntetisk partitionsnyckel. En annan potentiell användning av Azure IoT Hub-vägar är att kopiera inkommande data till Azure Blob Storage eller Azure Data Lake. Den här metoden tillhandahåller ett alternativ för arkivering till låg kostnad, med bekväm åtkomst för batchbearbetning, inklusive Data science-uppgifter i Azure Machine Learning.
Azure IoT Central erbjuder kontinuerlig dataexport till Azure Event Hubs, Azure Service Bus och anpassade webhooks. Det går också att konfigurera intervallbaserad dataexport till Azure Blob Storage. Azure Functions stöder bindningar för Azure Event Hubs och Azure Service Bus, som du kan använda för att integrera dem med Azure Cosmos DB.
Med Azure IoT Central kan du ge insikter i nästan realtid med dess inbyggda analysfunktioner. För mer avancerade analysbehov eller när du använder Azure IoT Hub kan du kanalisera data till Azure Stream Analytics. Azure Stream Analytics stöder Azure Cosmos DB SQL API som utdata och skriver dataströmbearbetningsresultat som JSON-formaterade objekt i Azure Cosmos DB-containrar. Detta implementerar dataarkivering och möjliggör ad hoc-frågor med låg svarstid på ostrukturerade JSON-data. Funktionen för ändringsflöde identifierar automatiskt nya data och ändringar i befintliga data. Du kan bearbeta dessa data genom att ansluta Azure Cosmos DB till Azure Synapse Analytics. När bearbetningen är klar kan du läsa in den igen till Azure Cosmos DB för mer djupgående rapportering. Du kan också använda Azure Databricks med Apache Spark-strömning för att:
- Läs in data från Azure IoT Hub.
- Bearbeta den för att leverera realtidsanalyser.
- Arkivera den för långsiktig kvarhållning och mer rapportering till Azure-tjänster som Azure Cosmos DB, Azure Blob Storage eller Azure Data Lake.