Beskriva inmatning och bearbetning av data
Dataanalys handlar om att hitta meningsfull information och slutsatsdragning från data. Detta kan gälla allt från att välja det optimala produktutbudet för en återförsäljare eller välja rätt vaccinkandidater för ett bioteknikföretag.
På ett företag kan dataanalys till exempel handla om att använda de data som organisationen producerar till att få en bild av organisationens resultat samt vad du kan göra för att påverka resultatet. Med hjälp av dataanalys kan du identifiera styrkor och svagheter i organisationen, och fatta välgrundade affärsbeslut.
De data ett företag använder kan komma från många olika källor. Det kan finnas mängder av historiska data att gå igenom samtidigt som nya data anländer kontinuerligt. Dessa data kan komma från kundköp, banktransaktioner, förändrade aktiekurser, realtidsdata om vädret, övervakningsenheter eller till och med kameror. I en lösning för dataanalys kombinerar du dessa data och skapar ett informationslager där du kan ställa frågor (och få svar) om verksamheten. När du ska skapa ett informationslager måste du samla in de data du behöver och omvandla dem till ett lämpligt format. Sedan kan du använda analysverktyg och visualiseringar till att granska informationen och identifiera trender och deras orsaker.
Kommentar
Omvandling är en process där du transformerar och mappar rådata till ett format som passar bättre för analys. Du kan skriva kod för att fånga in, filtrera, rensa, kombinera och aggregera data från många olika källor.
I den här lektionen får du lära dig mer om två viktiga steg i dataanalysen: datainmatning och databehandling. I diagrammet nedan ser du hur de här stegen passar ihop.
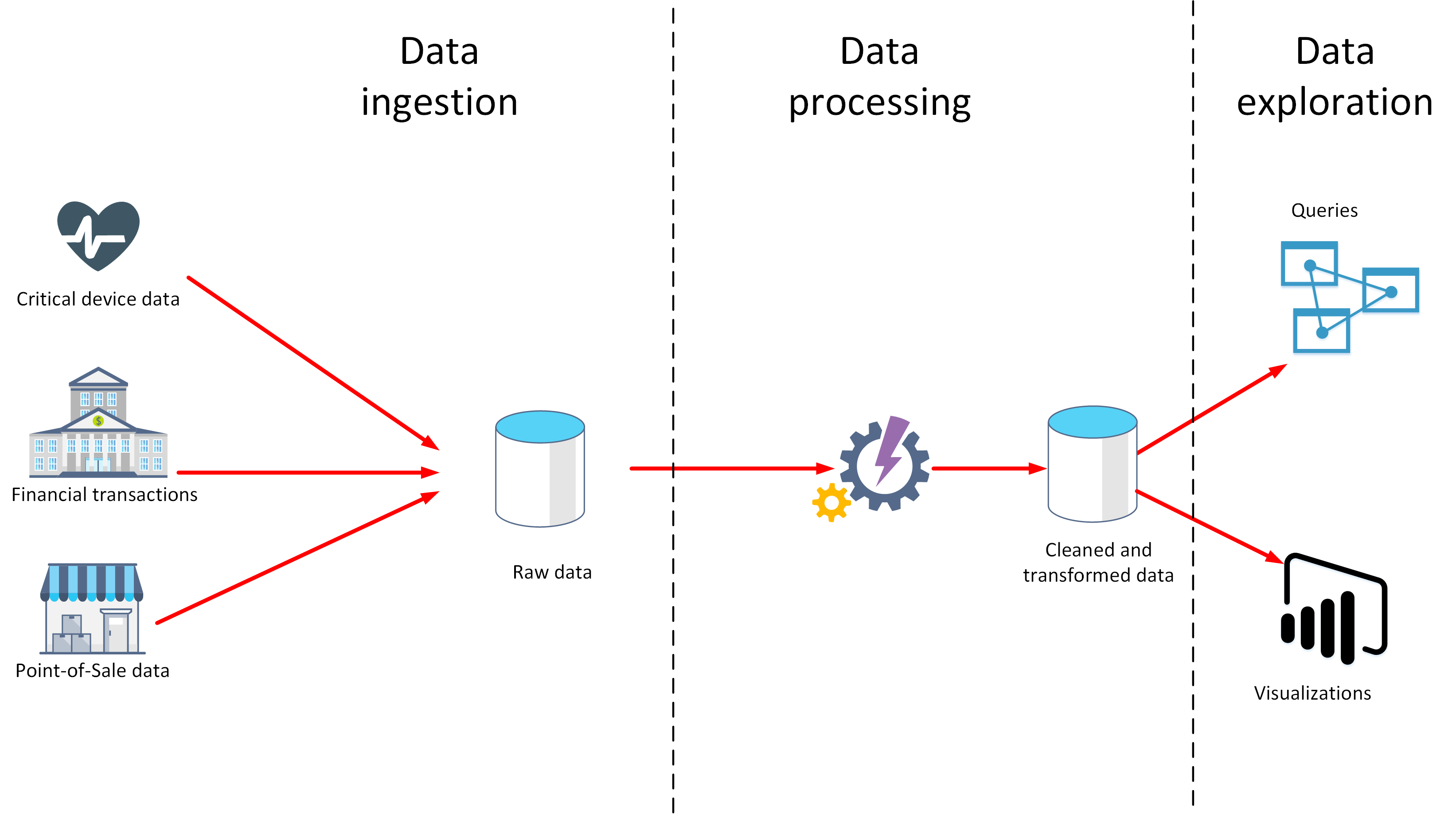
Vad är datainmatning?
Datainmatning är processen att samla in och importera data för användning eller lagring i en databas. Data kan anlända som en kontinuerlig ström eller i batchar beroende på källan. Syftet med inmatningsprocessen är att samla in och lagra dessa data. Rådata kan förvaras i en lagringsplats som ett databashanteringssystem, en uppsättning filer eller någon annan typ av snabb och lättillgänglig lagring.
Data kan även filtreras under inmatningsprocessen. Inmatningen kan till exempel avvisa misstänkta, skadade eller duplicerade data. Misstänkta data kan vara data som kommer från en oväntad källa. Skadade eller duplicerade data kan bero på ett enhetsfel, överföringsfel eller manipulering.
Du kan även utföra vissa transformeringar i det här skedet och konvertera data som ska bearbetas senare till ett standardformat. Du kan till exempel formatera om alla datum- och tidsdata så att de representeras i samma format och konvertera alla måttdata till samma enheter. De här transformeringarna måste dock gå snabbt att utföra. Försök inte köra några komplexa beräkningar eller aggregeringar i det här skedet.
Vad är databehandling?
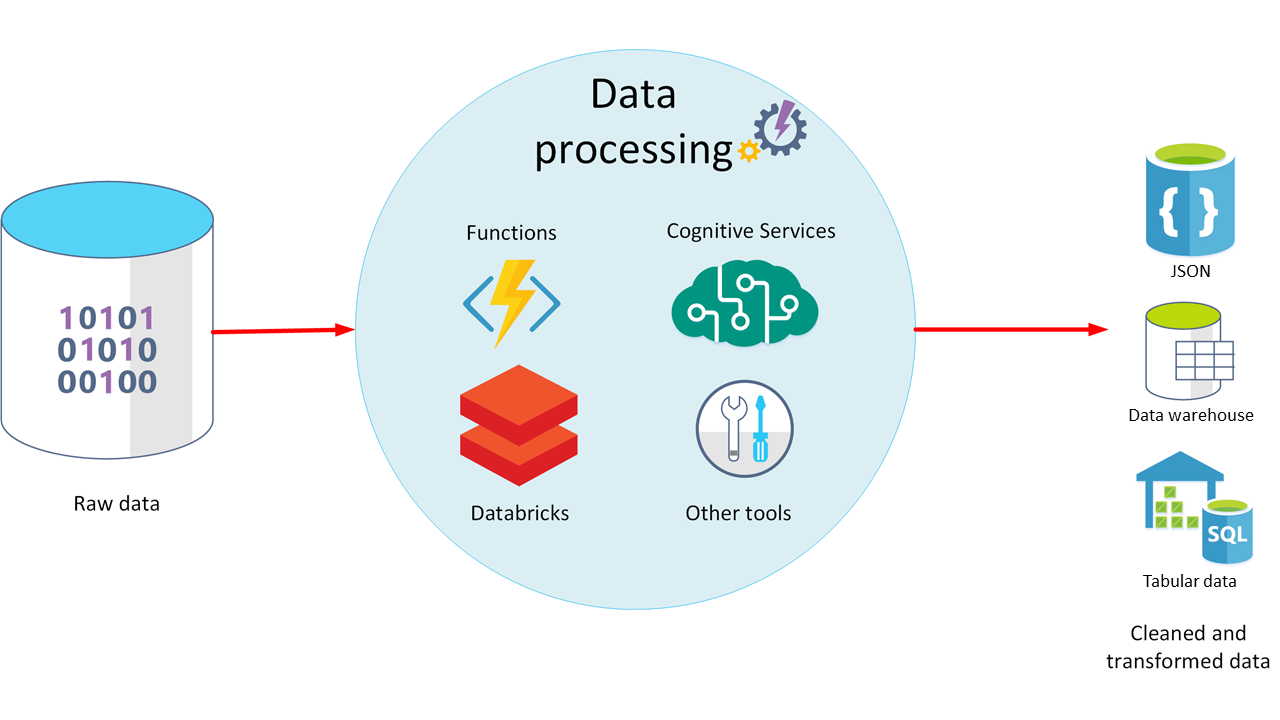
Databehandlingsfasen inträffar när data har matats in och samlats in. I den här processen tar du rådata, rensar dem och omvandlar dem till ett mer meningsfullt format (som tabeller, grafer och dokument). Resultatet är en databas med data du kan använda till att köra frågor och generera visualiseringar, så att de får en form och kontext som datorer och medarbetarna i organisationen kan tolka.
Kommentar
Datarensning är en generaliserad term som omfattar ett antal åtgärder, till exempel att ta bort extremvärden och tillämpa filter och transformeringar som skulle ta för lång tid att köra under inmatningsfasen.
Syftet med databehandlingen är att omvandla rådata till en eller flera affärsmodeller. En affärsmodell beskriver data i termer av meningsfulla affärsentiteter. Modellen kan dessutom aggregera och sammanfatta information. Databehandlingsfasen kan också generera prediktiva eller andra analytiska modeller från dina data. Det kan vara komplicerat med databehandling. Processen kan bestå av automatiserade skript där verktyg som Azure Databricks, Azure Functions och Azure Cognitive Services används till att undersöka data, formatera om dem och generera modeller. En dataanalytiker kan använda maskininlärning till att fastställa framtida trender baserat på de här modellerna.
Vad är ELT och ETL?
I databehandlingen kan du använda två metoder för att hämta inmatade data, bearbeta data, generera modeller och sedan spara dina transformerade data och modeller. De här metoderna kallas för ETL och ELT.
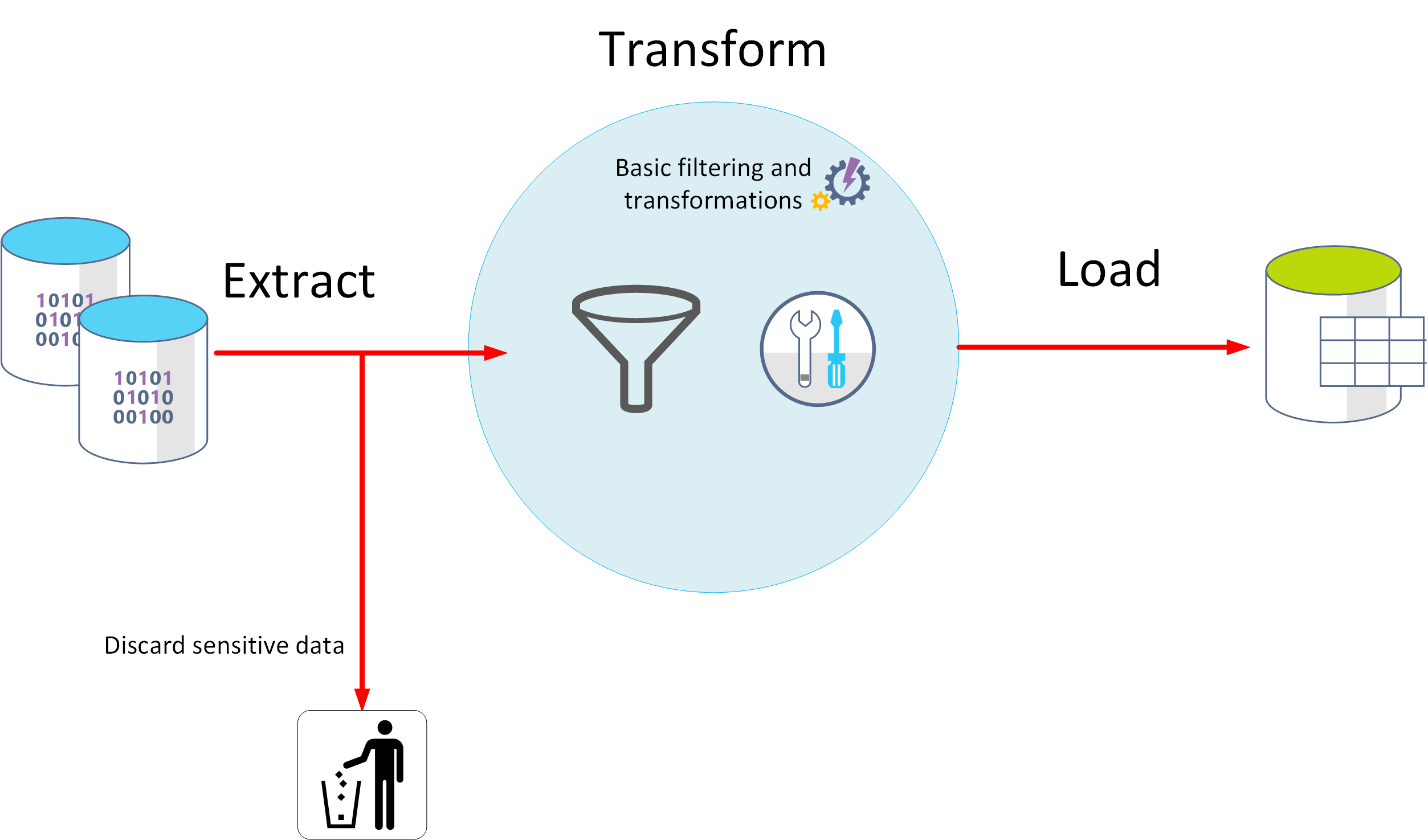
ETL står för extrahering, transformering och laddning. Rådata hämtas och transformeras innan de sparas. Stegen för extrahering, transformering och laddning kan utföras som en kontinuerlig pipeline med åtgärder. Den här metoden passar för system som bara behöver enkla modeller och där beroendet mellan objekten är litet. Den här typen av process används till exempel ofta för enklare datarensningsuppgifter, borttagning av dubbletter och formatering av innehållet i enskilda fält.
En annan metod är ELT. ELT står för extrahering, laddning och transformering. Processen skiljer sig från ETL på så sätt att data lagras innan de transformeras. Databehandlingsmotorn kan iterativt hämta och bearbeta data från lagringen innan dina transformerade data och modeller skrivs tillbaka till lagringen. ELT passar bättre för komplexa modeller som är beroende av flera objekt i databasen. Här sker ofta bearbetningen i regelbundna batcher.
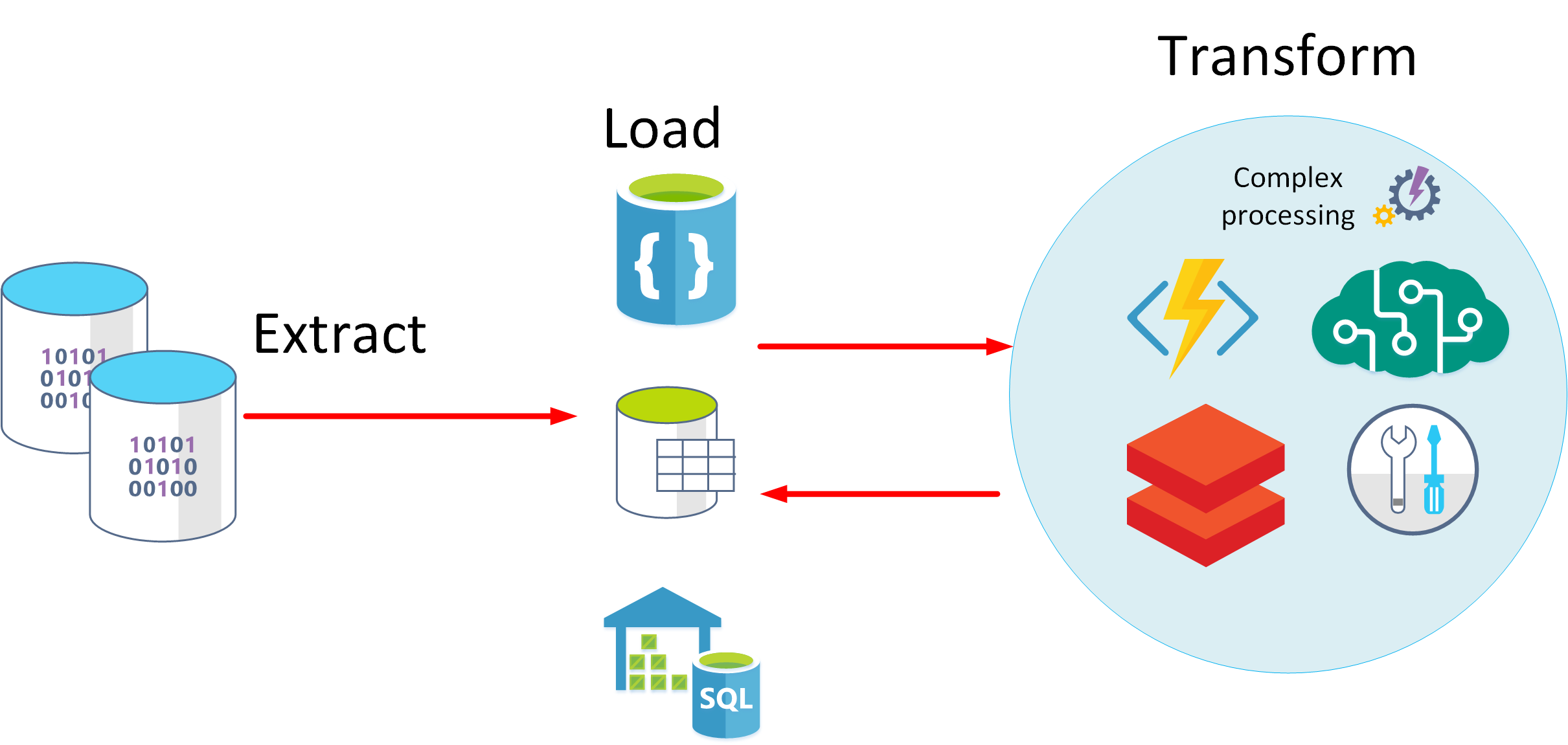
ELT är en skalbar metod som passar bra för molnet eftersom den har nytta av den enorma beräkningskraften. I den mer strömorienterade ETL-metoden ligger fokus på dataflödet. ETL kan dock filtrera data innan de lagras. På så sätt kan ETL bidra till datasekretess och regelefterlevnad, eftersom känsliga data kan tas bort innan de tas emot i dina analysmodeller.
Azure har flera alternativ för att implementera metoderna ELT och ETL. Om du till exempel lagrar data i Azure SQL Database kan du använda SQL Server Integration Services. Integration Services kan extrahera och transformera data från en mängd olika källor, som XML-datafiler, flata filer och relationsdatakällor, och sedan läsa in data till ett eller flera mål.
Det här är en enkel tabell som visar fördelarna med ETL och ELT i de flesta fall.

En annan mer allmän metod är att använda Azure Data Factory. Azure Data Factory är en molnbaserad dataintegreringstjänst som gör att du kan skapa datadrivna arbetsflöden för orkestrering av flytt och transformering av data i stor skala. Med Azure Data Factory kan du skapa och schemalägga datadrivna arbetsflöden (så kallade ”pipelines”) som kan mata in data från olika datalager. Du kan skapa komplexa ETL-processer som transformerar data visuellt via dataflöden, eller med hjälp av beräkningstjänster som Azure HDInsight Hadoop, Azure Databricks och Azure SQL Database.