Designa index
SQL Server har flera indextyper som stöder olika typer av arbetsbelastningar. På hög nivå kan ett index betraktas som en på diskstruktur som är associerad med en tabell eller en vy, som gör det enklare för SQL Server att hitta raden eller raderna som är associerade med indexnyckeln (som består av en eller flera kolumner i tabellen eller vyn), jämfört med genomsökning av hela tabellen.
Klustrade index
En vanlig dba-jobbintervjufråga är att ställa skillnaden mellan ett klustrat och icke-grupperat index, eftersom index är en grundläggande datalagringsteknik i SQL Server. Ett grupperat index är den underliggande tabellen som lagras i sorterad ordning baserat på nyckelvärdet. Det kan bara finnas ett grupperat index i en viss tabell, eftersom raderna kan lagras i en ordning. En tabell utan ett grupperat index kallas för en heap och heaps används vanligtvis bara som mellanlagringstabeller. En viktig princip för prestandadesign är att hålla din klustrade indexnyckel så smal som möjligt. När du överväger nyckelkolumnerna för ditt klustrade index bör du överväga kolumner som är unika eller som innehåller många distinkta värden. En annan egenskap för en bra klustrad indexnyckel är för poster som används sekventiellt och som används ofta för att sortera data som hämtats från tabellen. Att ha det klustrade indexet i kolumnen som används för sortering kan förhindra kostnaden för sortering varje gång frågan körs, eftersom data redan lagras i önskad ordning.
Kommentar
När vi säger att tabellen är "lagrad" i en viss ordning refererar vi till den logiska ordningen, inte nödvändigtvis den fysiska beställningen på disk. Index har pekare mellan sidor och pekarna hjälper till att skapa den logiska ordningen. När du skannar ett index i ordning följer SQL Server pekarna från sida till sida. Omedelbart efter att du har skapat ett index lagras det troligen också i fysisk ordning på disken, men när du börjar göra ändringar i data och nya sidor måste läggas till i indexet, ger pekarna fortfarande rätt logisk ordning, men de nya sidorna kommer mest som inte att vara i fysisk diskordning.
Icke-grupperade index
Icke-grupperade index är en separat struktur från dataraderna. Ett icke-grupperat index innehåller de nyckelvärden som definierats för indexet och en pekare till dataraden som innehåller nyckelvärdet. Du kan lägga till en annan icke-nyckelkolumn på lövnivån för det icke-grupperade indexet för att täcka fler kolumner med hjälp av funktionen inkluderade kolumner i SQL Server. Du kan skapa flera icke-illustrerade index i en tabell.
Ett exempel på när du behöver lägga till ett index eller lägga till kolumner i ett befintligt icke-grupperat index visas nedan:

Frågeplanen anger att för varje rad som hämtas med hjälp av indexsökningen måste mer data hämtas från det klustrade indexet (själva tabellen). Det finns ett icke-grupperat index, men det innehåller bara produktkolumnen. Om du lägger till de andra kolumnerna i frågan i ett index som inte visas nedan kan du se körningsplanens ändring för att eliminera nyckelsökningen.

Indexet som skapades ovan är ett exempel på ett täckande index, där du utöver nyckelkolumnen inkluderar extra kolumner för att täcka frågan och eliminera behovet av att komma åt själva tabellen.
Både icke-klustrade och klustrade index kan definieras som unika, vilket innebär att det inte kan finnas någon duplicering av nyckelvärdena. Unika index skapas automatiskt när du skapar en PRIMÄRNYCKEL eller UNIK-begränsning i en tabell.
Fokus i det här avsnittet ligger på b-trädindex i SQL Server – dessa kallas även för radlagringsindex. Den allmänna strukturen för ett b-träd visas nedan:
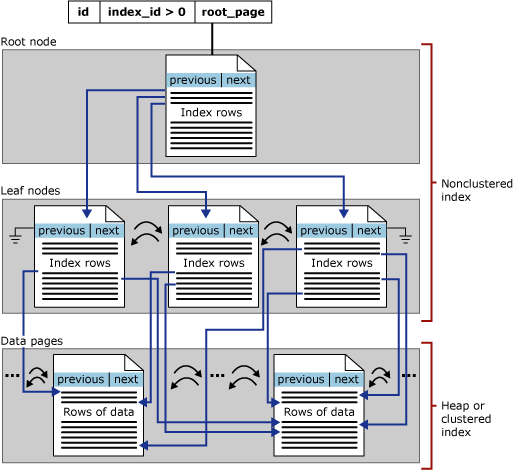
Varje sida i ett index b-träd kallas för en indexnod och den översta noden i b-träd kallas rotnoden. De nedre noderna i ett index kallas lövnoder och samlingen av lövnoder är lövnivån.
Indexdesign är en blandning av konst och vetenskap. Ett smalt index med få kolumner i nyckeln kräver mindre tid att uppdatera och har lägre underhållskostnader. men det kanske inte är användbart för så många frågor som ett bredare index som innehåller fler kolumner. Du kan behöva experimentera med flera indexeringsmetoder baserat på de kolumner som valts av programmets frågor. Frågeoptimeraren väljer vanligtvis vad den anser vara det bästa befintliga indexet för en fråga. Det betyder dock inte att det inte finns ett bättre index som kan skapas.
Korrekt indexering av en databas är en komplex uppgift. När du planerar dina index för en tabell bör du ha några grundläggande principer i åtanke:
- Förstå systemets arbetsbelastningar. En tabell som främst används för infogningsåtgärder drar mycket mindre nytta av extra index än en tabell som används för informationslageråtgärder som är 90 % läsaktivitet.
- Förstå vilka frågor som körs oftast och optimera dina index kring dessa frågor.
- Förstå datatyperna för de kolumner som används i dina frågor. Index är idealiska för heltalsdatatyper eller unika eller icke-null-kolumner.
- Skapa icke-illustrerade index på kolumner som ofta används i predikater och kopplingssatser och håll indexen så smala som möjligt för att undvika omkostnader.
- Förstå din datastorlek/volym – En tabellgenomsökning på en liten tabell blir en relativt billig åtgärd och SQL Server kan välja att göra en tabellgenomsökning bara för att det är enkelt (trivialt) att göra. En tabellgenomsökning på en stor tabell skulle bli kostsam.
Ett annat alternativ som SQL Server erbjuder är att skapa filtrerade index. Filtrerade index passar bäst för kolumner i stora tabeller där en stor procentandel av raderna har samma värde i den kolumnen. Ett praktiskt exempel skulle vara en tabell med anställda, som visas nedan, som lagrade poster för alla anställda, inklusive de som hade lämnat eller gått i pension.
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
I den här tabellen finns en kolumn med namnet CurrentFlag, som anger om en anställd för närvarande är anställd. I det här exemplet används bitdatatypen, som endast anger två värden, ett för närvarande används och noll för inte används för närvarande. Ett filtrerat index med , WHERE CurrentFlag = 1i kolumnen CurrentFlag skulle möjliggöra effektiva frågor för aktuella anställda.
Du kan också skapa index för vyer, vilket kan ge betydande prestandavinster när vyer innehåller frågeelement som sammansättningar och/eller tabellkopplingar.
Columnstore-index
Columnstore ger bättre prestanda för frågor som kör stora aggregeringsarbetsbelastningar. Den här typen av index riktades ursprungligen till informationslager, men med tiden har kolumnlagringsindex använts i många andra arbetsbelastningar för att lösa problem med frågeprestanda i stora tabeller. Från och med SQL Server 2014 finns det både icke-klustrade och klustrade kolumnlagringsindex. Precis som b-trädindex är ett grupperat kolumnlagringsindex själva tabellen lagrad på ett speciellt sätt, och icke-grupperade kolumnlagringsindex lagras oberoende av tabellen. Grupperade kolumnlagringsindex innehåller alla kolumner i en viss tabell. Till skillnad från grupperade rowstore-index sorteras dock inte klustrade kolumnlagringsindex.
Icke-grupperade kolumnlagringsindex används vanligtvis i två scenarier, den första är när en kolumn i tabellen har en datatyp som inte stöds i ett kolumnlagringsindex. De flesta datatyper stöds men XML, CLR, sql_variant, ntext, text och bild stöds inte i ett kolumnlagringsindex. Eftersom ett grupperat kolumnarkiv alltid innehåller alla kolumner i tabellen (eftersom det är tabellen) är en icke-klustrad det enda alternativet. Det andra scenariot är ett filtrerat index – det här scenariot används i en arkitektur som kallas hybridtransaktionsanalysbearbetning (HTAP), där data läses in i den underliggande tabellen och samtidigt körs rapporter i tabellen. Genom att filtrera indexet (vanligtvis i ett datumfält) ger den här designen både bra infognings- och rapporteringsprestanda.
Kolumnlagringsindex är unika i lagringsmekanismen, eftersom varje kolumn i indexet lagras oberoende av varandra. Det erbjuder en dubbel fördel. En fråga som använder ett columnstore-index behöver bara genomsöka de kolumner som behövs för att uppfylla frågan, vilket minskar den totala I/O som utförts och ger större komprimering, eftersom data i samma kolumn sannolikt kommer att likna dem.
Kolumnlagringsindex presterar bäst på analysfrågor som söker igenom stora mängder data, till exempel faktatabeller i ett informationslager. Från och med SQL Server 2016 kan du utöka ett columnstore-index med ett annat index som inte är b-träd, vilket kan vara användbart om vissa av dina frågor söker efter singleton-värden.
Columnstore-index drar också nytta av batchkörningsläget, vilket avser bearbetning av en uppsättning rader (vanligtvis cirka 900) i taget jämfört med databasmotorn som bearbetar dessa rader en i taget. I stället för att läsa in varje post separat och bearbeta dem beräknar frågemotorn beräkningen i den gruppen med 900 poster. Den här bearbetningsmodellen minskar antalet CPU-instruktioner dramatiskt.
SELECT SUM(Sales) FROM SalesAmount;
Batch-läge kan ge betydande prestandaökning jämfört med traditionell radbearbetning. SQL Server 2019 innehåller även batchläge för radlagringsdata. Även om batchläget för rowstore inte har samma läsprestanda som ett kolumnlagringsindex, kan analysfrågor se upp till en prestandaförbättring på 5 gånger.
De andra förmånskolumnlagringsindexen erbjuder datalagerarbetsbelastningar är en optimerad inläsningssökväg för massinfogningsåtgärder på 102 400 rader eller mer. Medan 102 400 är det minsta värdet som ska läsas in direkt i kolumnarkivet, kan varje samling rader, som kallas en radgrupp, vara upp till cirka 1 024 000 rader. Med färre, men fylligare, gör radgrupper dina SELECT-frågor mer effektiva, eftersom färre radgrupper måste genomsökas för att hämta de begärda posterna. Dessa inläsningar sker i minnet och läses in direkt till indexet. För mindre volymer skrivs data till en b-trädstruktur som kallas för ett deltalager och läses asynkront in i indexet.
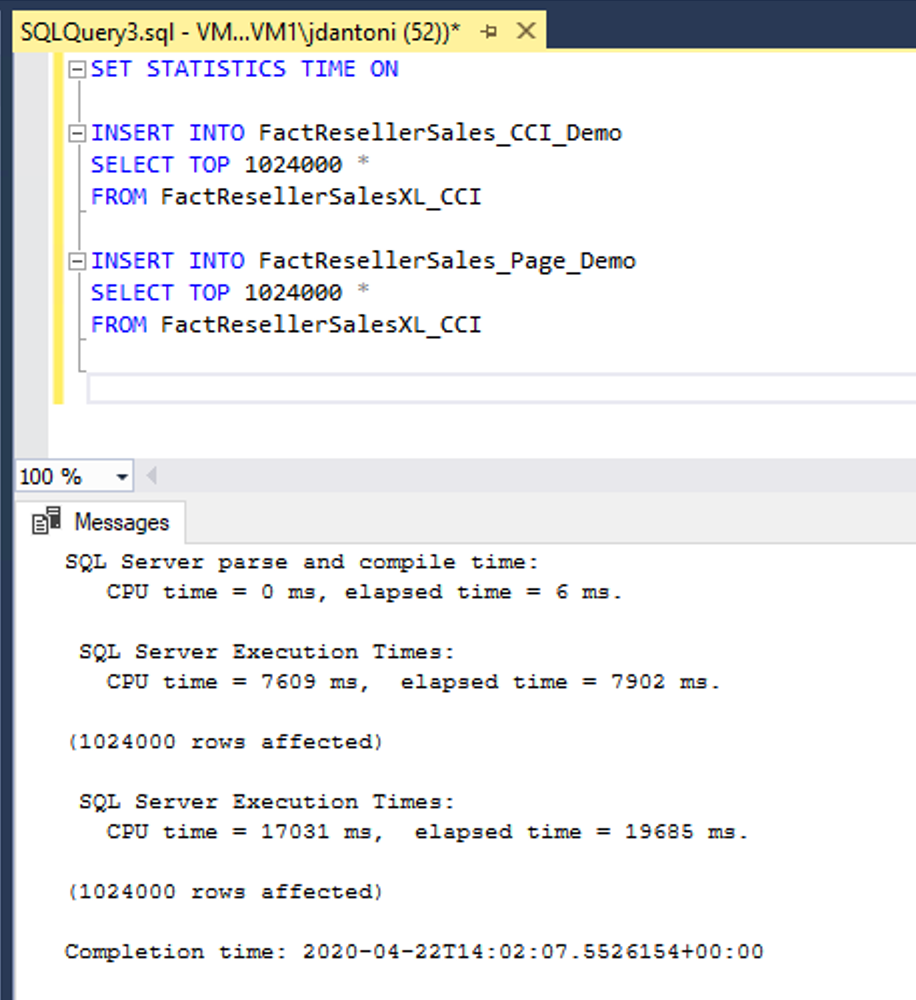
I det här exemplet läses samma data in i två tabeller, FactResellerSales_CCI_Demo och FactResellerSales_Page_Demo. FactResellerSales_CCI_Demo har ett grupperat kolumnlagringsindex och FactResellerSales_Page_Demo har ett grupperat b-trädindex med två kolumner och är sidkomprimerad. Som du ser läser varje tabell in 1 024 000 rader från den FactResellerSalesXL_CCI tabellen. När SET STATISTICS TIME är ONhåller SQL Server reda på den förflutna tiden för frågekörningen. Det tog ungefär 8 sekunder att läsa in data i kolumnlagringstabellen, där inläsningen till den sidkomprimerade tabellen tog nästan 20 sekunder. I det här exemplet läses alla rader som går in i kolumnlagringsindexet in i en enskild radgrupp.
Om du läser in mindre än 102 400 rader data till ett kolumnlagringsindex i en enda åtgärd läses den in i en b-trädstruktur som kallas för ett deltalager. Databasmotorn flyttar dessa data till kolumnlagringsindexet med hjälp av en asynkron process som kallas tuppelns mover. Att ha öppna deltalager kan påverka prestandan för dina frågor, eftersom det är mindre effektivt att läsa dessa poster än att läsa från kolumnarkivet. Du kan också ordna om indexet COMPRESS_ALL_ROW_GROUPS med alternativet för att tvinga deltaarkiven att läggas till och komprimeras till kolumnlagringsindexen.