Definiera användningsfall och samverkan mellan datadeduplicering
Dina datadedupliceringsbesparingar varierar beroende på datatyp, blandning av data, storleken på volymerna och filerna som dessa volymer innehåller. Du kan välja att utvärdera besparingarna efter volym innan du aktiverar deduplicering.
Användningsfall för datadeduplicering
Följande lista innehåller typiska scenarier för deduplicering och deras respektive volymutrymmesbesparingar:
| Användningsfall | Innehåll | Utrymmesbesparingar |
|---|---|---|
| Användardokument | Gruppera innehållspublikation eller delning, användarens hemmappar och profilomdirigering för åtkomst till offlinefiler | 30 till 50 procent |
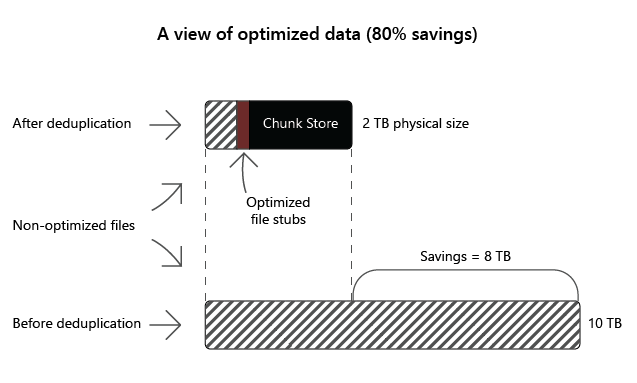
| Programvarudistributionsresurser | Binärfiler för programvara, cab-filer, symbolfiler, bilder och uppdateringar | 70 till 80 procent |
| Virtualiseringsbibliotek | lagring av virtuella hårddiskfiler (t.ex. .vhd- och .vhdx-filer) för etablering till hypervisor-enheter | 80 till 95 procent |
| Allmänna filresurser | en blandning av alla tidigare identifierade datatyper | 50 till 60 procent |
Rekommenderade användningsfall för datadeduplicering
Baserat på potentiella besparingar och typisk resursanvändning i Windows Server rangordnas distributionskandidater för deduplicering som idealiska, bör utvärderas eller inte vara idealiska kandidater.
- Idealiska kandidater för deduplicering:
- Omdirigeringsservrar för mappar.
- Virtualiseringsdepå eller etableringsbibliotek.
- Programvarudistributionsresurser.
- Säkerhetskopieringsvolymer för Microsoft SQL Server och Microsoft Exchange Server.
- Filer på skalbara filservrar (SOFS) klusterdelade volymer (CSV:er).
- Virtualiserade virtuella säkerhetskopierings-VHD:ar (till exempel Microsoft System Center Data Protection Manager).
- VIRTUELLA VDI-hårddiskar för virtualiserad skrivbordsinfrastruktur (endast personliga VDI:er).
Viktigt!
I de flesta VDI-distributioner krävs särskild planering för att överväga startstormar. Den här termen refererar till den situation där många användare försöker logga in på sin VDI samtidigt, vanligtvis i början av en arbetsdag. En startstorm medför en tung belastning på VDI-lagringssystemet och kan leda till långa fördröjningar för VDI-användare under den första inloggningen. Du kan minimera effekten av startstormar genom att aktivera deduplicering. På så sätt cachelagras segment som läse från diskdedupliceringsarkivet vid start av virtuella datorer i minnet. Därför kräver efterföljande läsningar inte frekvent åtkomst till segmenten på disken eftersom de är tillgängliga i cacheminnet.
Bör utvärderas baserat på innehåll:
- Verksamhetsspecifika servrar (LOB).
- Leverantörer av statiskt innehåll.
- Webbservrar.
- Databehandling med höga prestanda (HPC).
Inte idealiska kandidater för deduplicering:
- Microsoft Hyper-V-värdar.
- Windows Server Update Service (WSUS).
- SQL Server- och Exchange Server-databasvolymer.
Utvärdera besparingar med verktyget för dedupliceringsutvärdering
Du kan använda Verktyget för dedupliceringsutvärdering, DDPEval.exe, för att fastställa de förväntade besparingarna från deduplicering på en viss volym. DDPEval.exe stöder utvärdering av lokala enheter och mappade eller ommappade fjärrresurser.
Dricks
När du installerar dedupliceringsfunktionen installeras DDPEval.exe automatiskt i katalogen \Windows\System32\.
Samverkan i Datadeduplicering
I Windows Server bör du överväga följande relaterade tekniker och potentiella problem när du distribuerar datadeduplicering:
Windows BranchCache
Du kan optimera åtkomsten till data via WAN (Wide Area Network) genom att aktivera BranchCache på Windows Server- och Windows-klientoperativsystem. När du kombinerar de två teknikerna är alla deduplicerade filer redan indexerade och hashade, vilket påskyndar bearbetningen av begäranden om data från ett avdelningskontor. Det här är som att förindexera eller förinstallera en BranchCache-aktiverad server.
Kommentar
BranchCache är en funktion som kan minska WAN-användningen och förbättra svarstiden för nätverksprogram när användare kommer åt innehåll på ett centralt kontor från avdelningskontor. När du aktiverar BranchCache cachelagras en kopia av innehållet som hämtas från webbservern eller filservern i avdelningskontoret. Om en annan klient i grenen begär samma innehåll kan klienten ladda ned det direkt från det lokala grennätverket i stället för att återigen behöva använda WAN för att hämta innehållet från det centrala kontoret.
Redundanskluster
Redundanskluster har fullt stöd för datadeduplicering, vilket innebär att deduplicerade volymer redundansväxlar korrekt mellan noder i klustret. Detta kräver dock att du installerar funktionen Datadeduplicering på varje nod i klustret som deltar i en redundansväxling.
FSRM-kvoter
Även om du inte bör skapa en hård kvot för en volymrotmapp som är aktiverad för deduplicering kan du använda Filserverresurshanteraren (FSRM) för att skapa en mjuk kvot i ett sådant scenario. När FSRM påträffar en deduplicerad fil identifieras filens logiska storlek för kvotberäkningar. Därför ändras inte kvotanvändningen (inklusive eventuella kvottrösklar) när deduplicering bearbetar en fil. Alla andra FSRM-kvotfunktioner, inklusive mjuka volymrotskvoter och kvoter för undermappar, fungerar som förväntat när du använder deduplicering.
Kommentar
FSRM är en uppsättning verktyg som hjälper dig att identifiera, kontrollera och hantera typen och mängden data som lagras på dina servrar. Med FSRM kan du konfigurera hårda eller mjuka kvoter för mappar och volymer. En hård kvot hindrar användare från att spara filer när kvotgränsen har nåtts. Medan en mjuk kvot inte tillämpar kvotgränsen genereras ett meddelande när data på volymen når ett tröskelvärde.
DFS Replication
Datadeduplicering är kompatibel med DFS-replikering (Distributed File System). Om du optimerar eller avoptimerar en fil utlöses ingen replikering eftersom filen inte ändras. DFS Replication använder fjärrdifferenskomprimering (RDC) (inte segmenten i segmentlagret) för övertrådsbesparingar.