Incidentspårning
Incidenter har en livscykel. För att svara mest effektivt måste du kunna spåra utvecklingen av själva incidenten och utvecklingen av ditt svar på den från början av den livscykeln.
Utvärdera det du vet
Ett bra sätt att utvärdera din incidentspårningsprocedur med hjälp av en specifik incident är att ställa dig själv en rad frågor:
- När fick du först veta om problemet? Om ditt mål är att förkorta tiden det tar att återhämta sig från incidenter så måste du börja samla in information från den tidpunkt då du blir medveten om problemen.
- Hur fick du reda på problemet? Varnade ditt övervakningssystem dig om incidenten? Fick du först veta om det när kunder klagade, antingen direkt till dig eller på sociala medier?
- Om du bara får reda på problemet, är du den första att veta? Vem behöver du i så fall informera? Om inte – vem mer vet om problemet?
- Om andra vet om problemet – vad (om något) görs åt det? Antar alla att någon annan undersöker det eller har någon börjat vidta åtgärder för att hantera det?
- Hur illa är det? Vi kanske inte har någon uppfattning om allvarlighetsgrad eller påverkan, och det finns ingen plats för oss att ta reda på hur illa problemet verkligen är och vem som påverkas.
De här frågorna kan vara svåra att besvara om inget spåras.
Skapa en standard för var incidentinformation ska spåras
Det finns många möjliga platser där du kan lagra och dela din lista över incidenter (aktiva eller inte) och all aktuell information om dessa incidenter. Dessa kan vara lika enkla som ett delat filområde med Word-dokument och så komplext som högspecialiserad programvara och tjänster för incidentspårning. Mellan dessa två ytterligheter finns system för biljett- och arbetsspårning som du kan använda för den här uppgiften. Vilket system du väljer är faktiskt mindre viktigt än hur du använder det. Oavsett vilket system du använder måste alla som kan ha någon koppling alls till incidenter (tekniker, kundsupport, hantering, PR, juridik och så vidare) veta vart de ska gå för att hitta systemet, hur man skapar en incident och hur man kommer åt data när det är lämpligt. Ett säkert sätt för att misslyckas med incidentspårning är att personerna som systemet ska hjälpa inte vet hur de kommer till det ("vilken webbadress har vårt system nu igen?") när de behöver det.
I den här modulen använder vi funktionerna för arbetsobjekt i Azure DevOps för vårt exempelspårningssystem.
Skapa en konversationsbrygga
För att besvara några av frågorna i föregående avsnitt Utvärdera vad du känner till och för att påbörja incidenthanteringsprocessen måste du ha ett sätt att kommunicera med andra om incidenten. Helst kommer detta att vara någon form av "teamsamarbete" elektroniskt medium för konversation, även om telefonbroar också fungerar. Konferenssamtal/telefonbryggor är mindre föredragna, eftersom det är svårare att retroaktivt granska incidentkommunikationen (därav rollen "Scribe" som nämndes tidigare).
Oavsett vilket medium du väljer bör du se till att skapa en unik kanal som är strikt begränsad till diskussion om den här incidenten och inget annat. Det är viktigt att hålla irrelevanta diskussioner utanför den här kanalen, eftersom du måste kunna ta data härifrån och analysera dem senare i din granskning efter incidenten.
I den här modulen använder vi Microsoft Teams som vår metod för incidentkommunikation.
Automatisera incidentspårningens start
Vi går igenom de delar vi har satt samman hittills. Vi har:
- Lista över de jourpersoner (och en rotation som definierats för dem).
- Roll som vi kan tilldela till personer som arbetar med en incident.
- Specifik plats där vi ska deklarera incidenten och spåra den.
- Unik kanal för personer som arbetar med incidenten för att kommunicera om den.
Du kan och bör automatisera skapandet och hanteringen av alla dessa saker i största möjliga utsträckning. När ett brådskande problem uppstår vill du inte behöva komma ihåg alla steg som krävs för att utlösa en incident, ta med rätt personer och spåra den. Allt du vill göra är att kunna trycka på "start-knappen" så att det direkt går att börja arbeta för att hantera problemet.
Använd Logic Apps för kodlös automatisering
Ett sätt att automatisera ditt första svar är att använda Logic Apps, vilket kan förenkla jobbet med schemaläggning, automatisering och orkestrering av uppgifter, affärsprocesser och arbetsflöden.
Logic Apps är en Azure-molntjänst för att skapa integreringslösningar. Den använder anslutningsprogram för att skapa automatiserade arbetsflöden. Utlösare startar logikappen när en specifik händelse inträffar eller när data uppfyller angivna villkor. Åtgärder är det som sedan utförs i Logic Apps-arbetsflödet.
I vårt exempel använder vi följande logik Anslutningsverktyg för incidentspårning:
- Azure Boards (en del av Azure DevOps), som du kan använda för att skapa och spåra problem/incidenter.
- Azure Storage, där du kan lagra och hämta information om vem som är jour så att du kan tilldela rätt personer att svara på incidenten. I vårt exempel använder vi Azure Table Storage eftersom det erbjuder en mycket enkel "nyckel/värde"-butik som gör det enkelt att lagra en lista över tekniker och deras jourstatus.
- Microsoft Teams, som du kan använda för att skapa en ny, unik incidentkanal för att spåra dina teknikteams konversationer i realtid när de kommunicerar om specifika incidenter. På så sätt kan du bevara interaktionerna i förhållande till tidslinjen för händelser senare när du utför en granskning efter incidenten.
Nu ska vi knyta samman detta med Logic Apps. Ta först en titt på den fullständiga appen som visas i Logic Apps Designer, sedan går vi igenom den steg för steg.
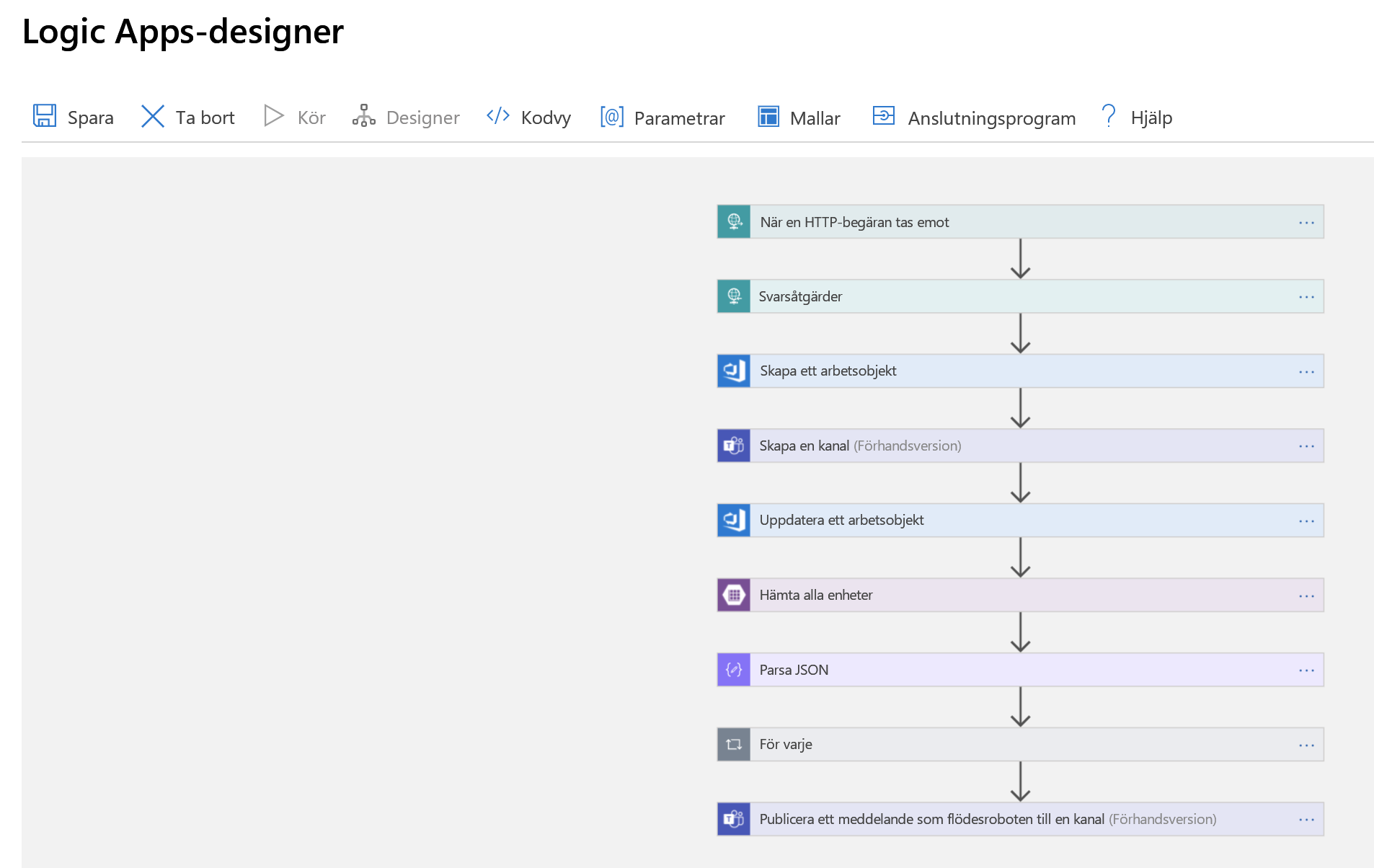
Det första steget är att hantera en utlösare, den HTTP-begäran som vi nämnde. En HTTP POST-begäran görs till vår logikapp som innehåller en JSON-nyttolast med information om incidenten som vi vill deklarera. Vi parsar nyttolasten och skickar tillbaka en bekräftelse om att vi har tagit emot den:
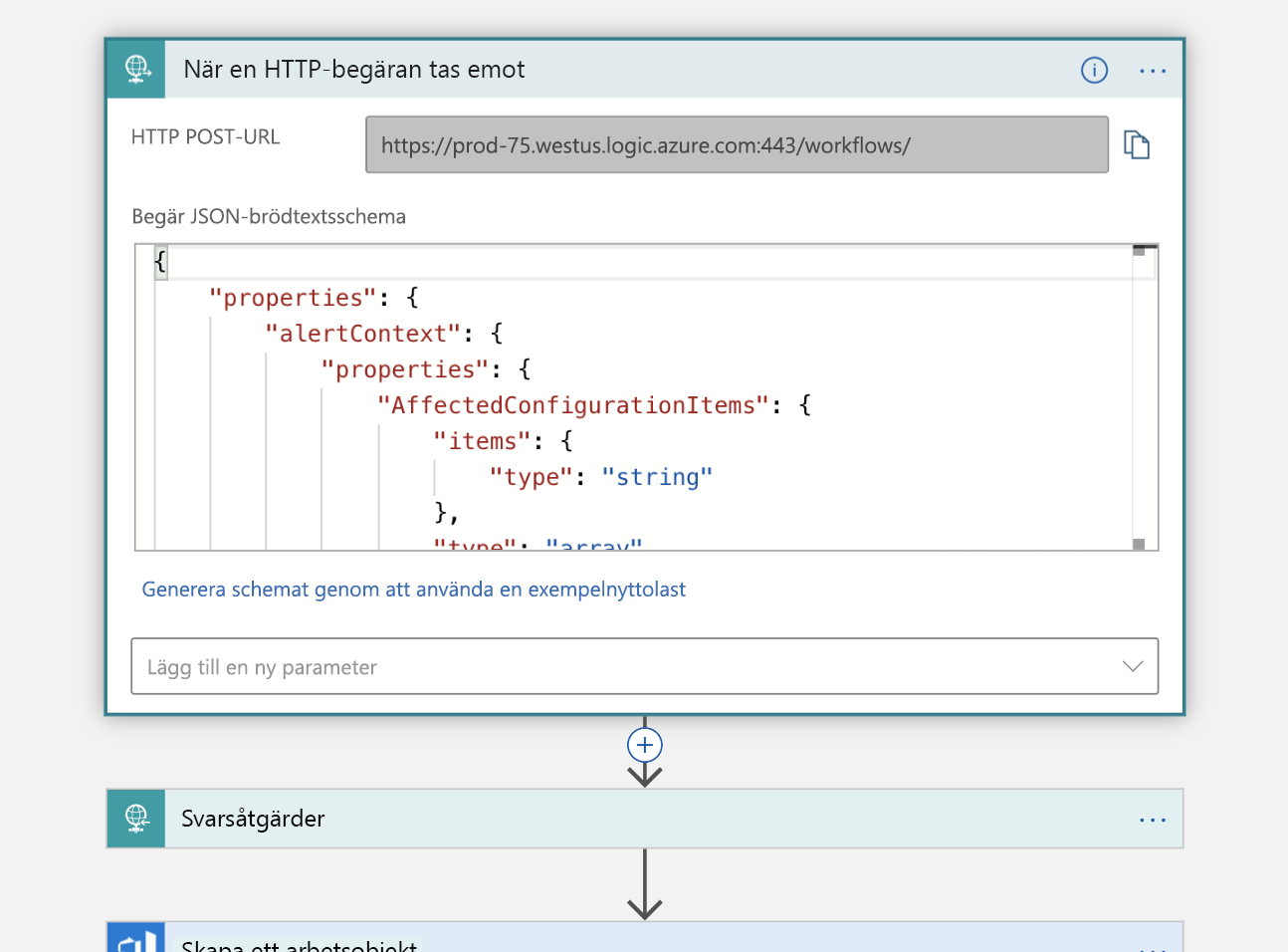
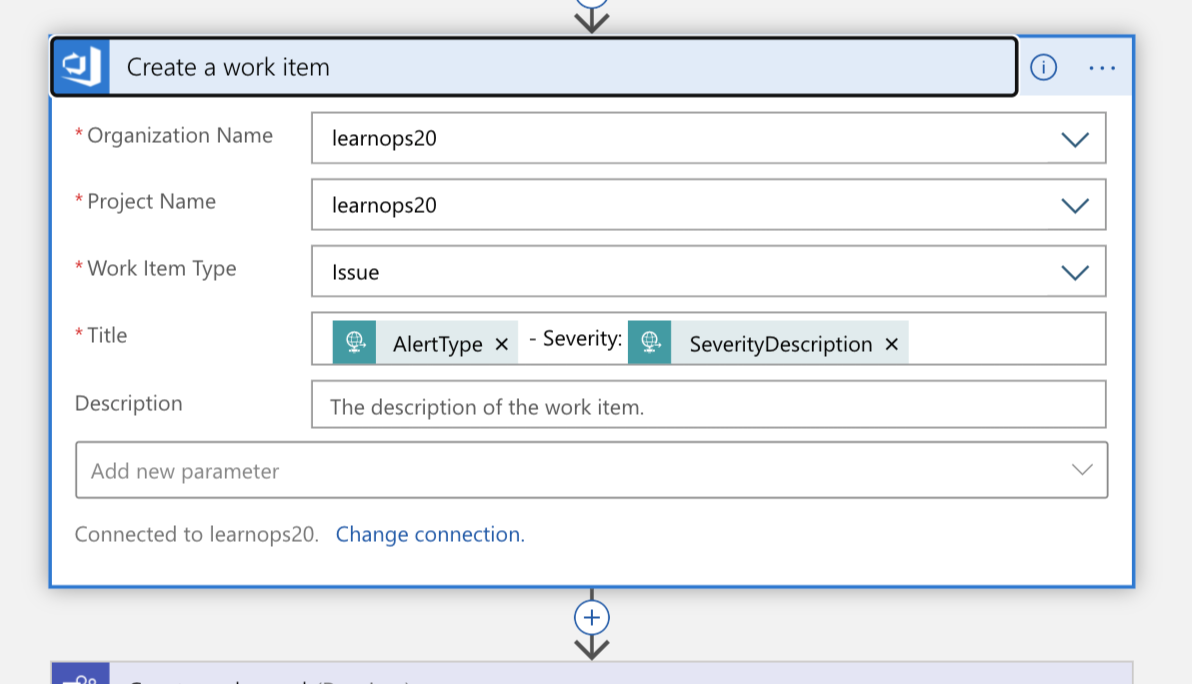
Med den här informationen skapar vi ett nytt arbetsobjekt i vår Azure DevOps-organisation som representerar den här incidenten.
Den skapar sedan en ny Teams-kanal för incidenten:
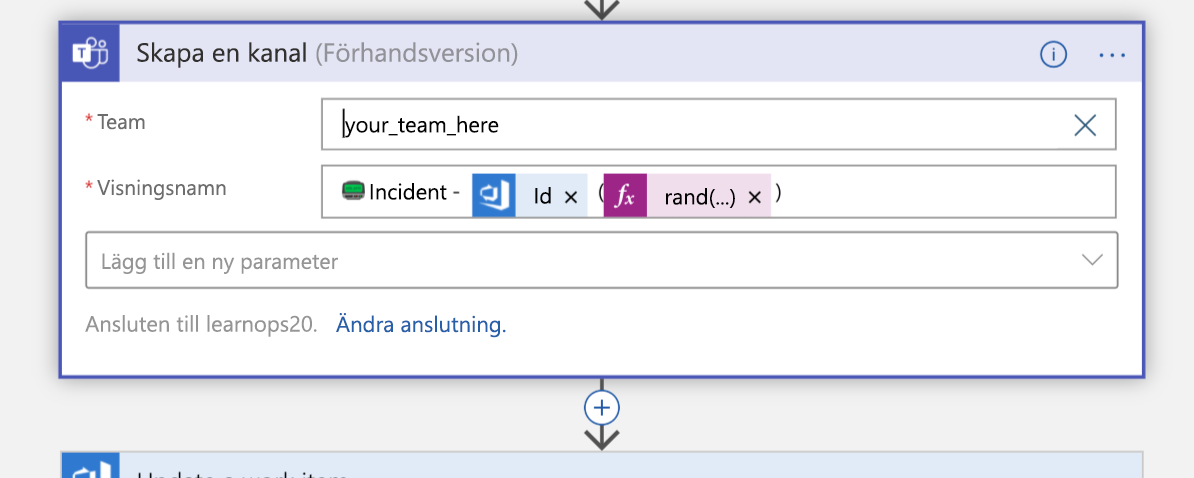
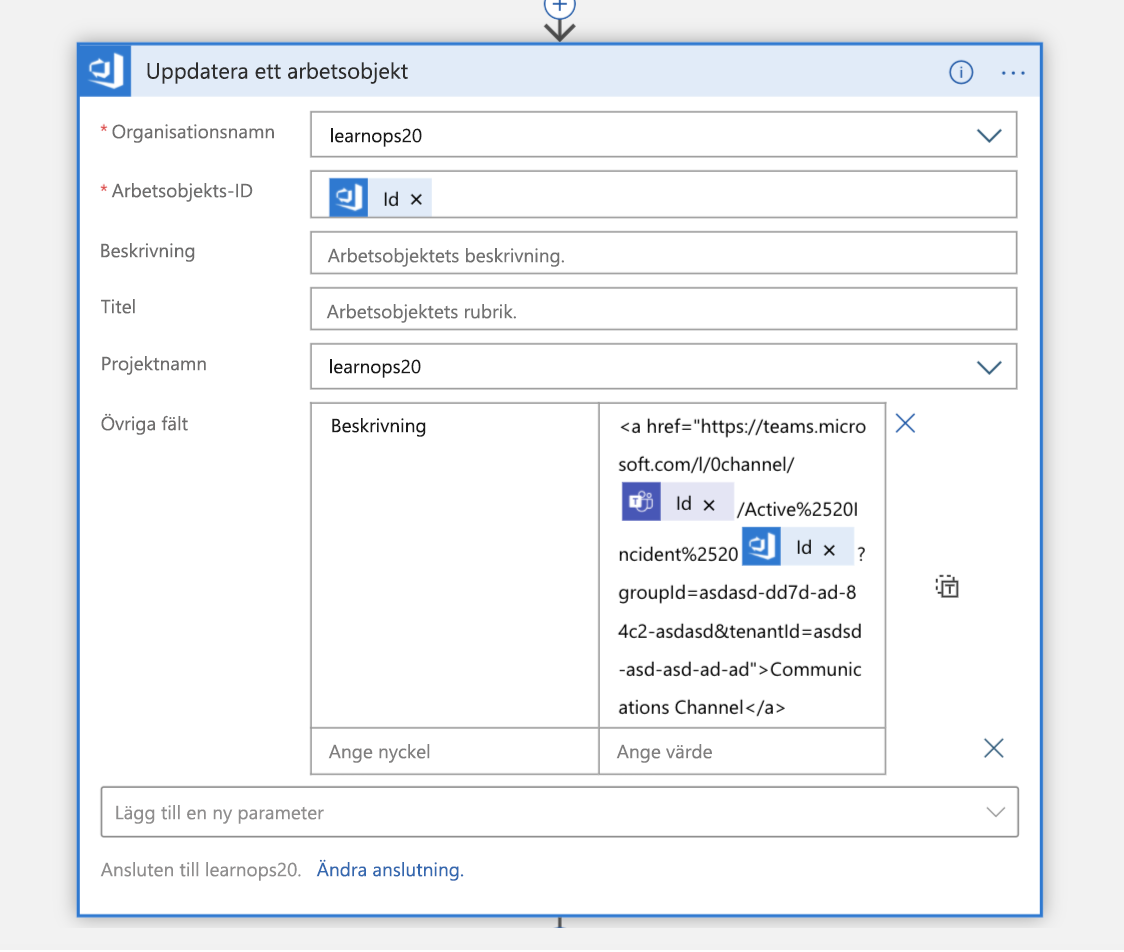
När kanalen har skapats uppdateras arbetsobjektet som vi skapade för en stund sedan med en länk till den nya kanalen. Det gör att all information finns på samma plats (arbetsobjektet) och gör det möjligt för personer att titta på den senare för att veta vart de ska gå om de vill gå med i kanalen.
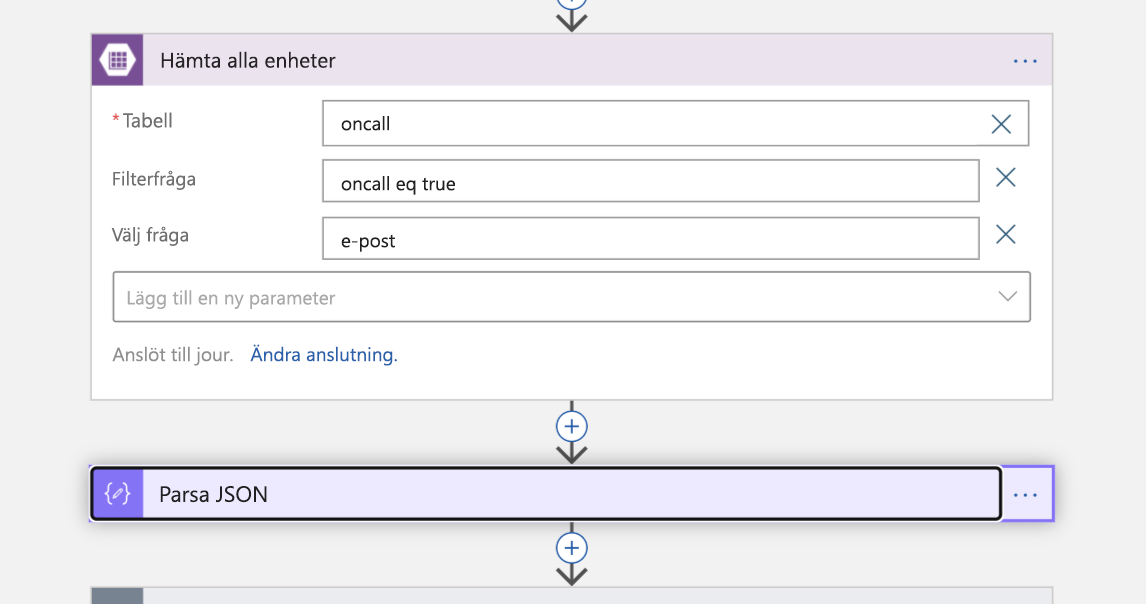
Nu är det dags att ta med jourpersonen i bilden. Vi utför en sökning i Azure Table Storage för e-postadressen till teknikern som anges som jour. Detta returnerar ett JSON-svar som vi sedan parsar.
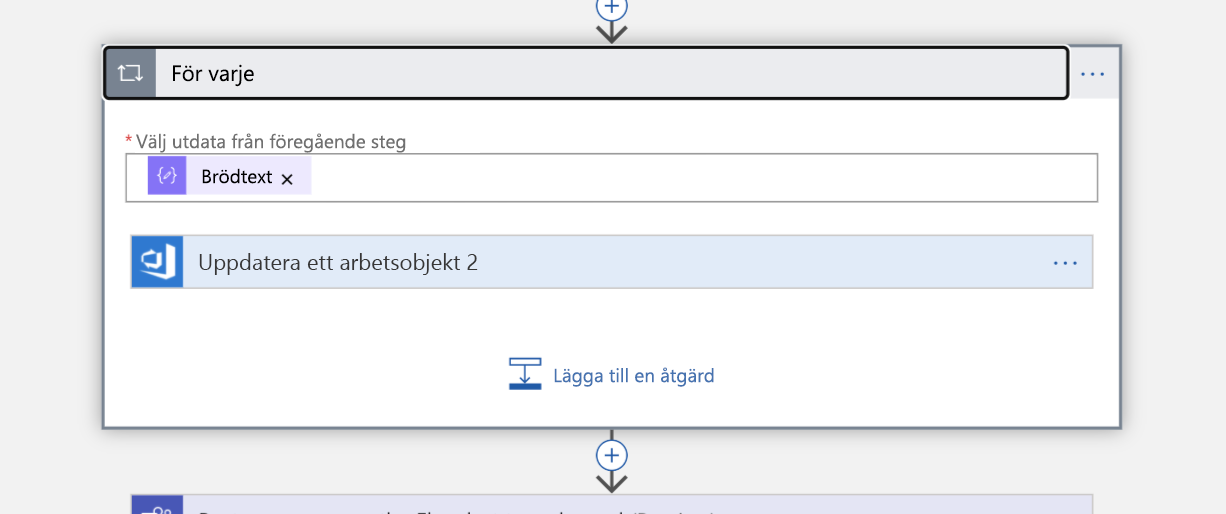
Eftersom vår fråga returnerar en lista måste vi iterera över varje objekt i listan som nästa steg. Vi tilldelar arbetsobjektet till respektive person (de är nu "ägare" av incidenten).
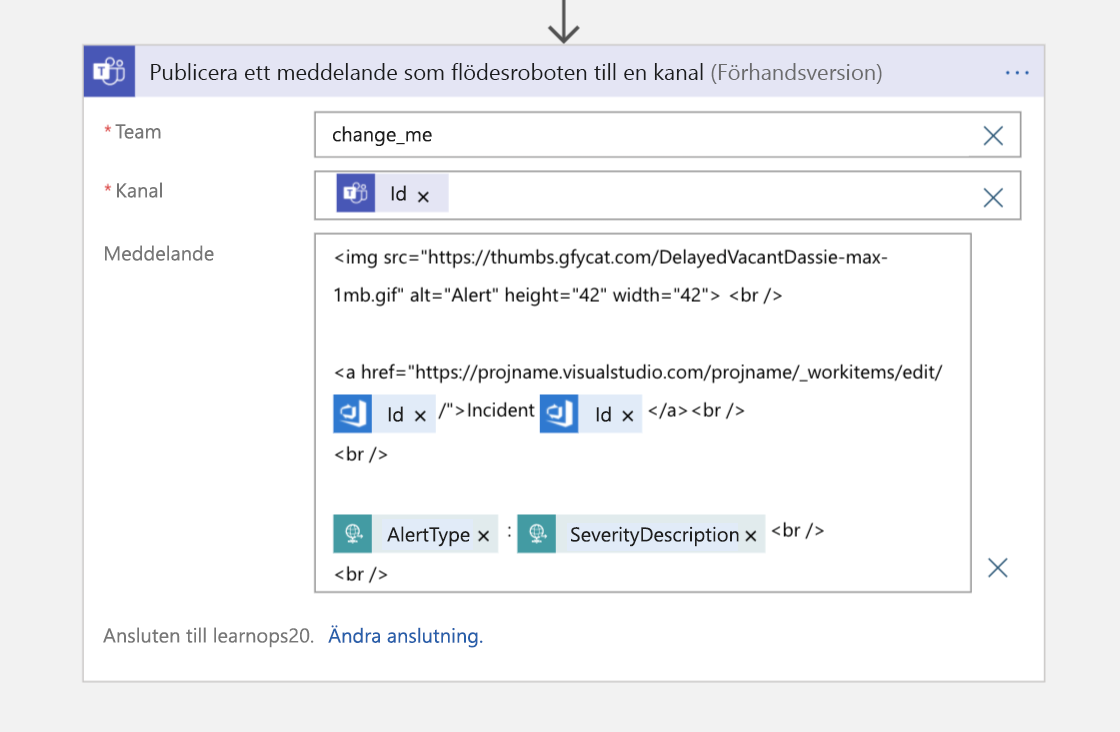
Som ett sista steg skickar vi sedan ett meddelande till Teams-kanalen med en pekare tillbaka till arbetsobjektet för personer som ansluter till kanalen och vill veta var den auktoritativa informationen för incidenten lagras.
Det är bara ett exempel på hur vi kan automatisera konfigurationen av mekanismerna för incidentspårning och kommunikation. I nästa enhet går vi mer på djupet i kommunikationen kring en incident.