Automatiska aggregeringar
Automatiska aggregeringar använder toppmodern maskininlärning (ML) för att kontinuerligt optimera DirectQuery-semantiska modeller för maximal rapportfrågeprestanda. Automatiska aggregeringar bygger på befintlig användardefinierad sammansättningsinfrastruktur som först introducerades med sammansatta modeller för Power BI. Till skillnad från användardefinierade aggregeringar kräver automatiska aggregeringar inte omfattande datamodellering och frågeoptimeringskunskaper för att konfigurera och underhålla. Automatiska aggregeringar är både självträning och självoptimering. De gör det möjligt för modellägare på valfri kompetensnivå att förbättra frågeprestanda, vilket ger snabbare rapportvisualiseringar för stora modeller.
Med automatiska aggregeringar:
- Rapportvisualiseringar är snabbare – En optimal procentandel av rapportfrågor returneras av en automatiskt underhålls minnesintern aggregeringscache i stället för serverdelsdatakällans system. Avvikande frågor som inte returneras av minnesintern cache skickas direkt till datakällan med DirectQuery.
- Balanserad arkitektur – Jämfört med rent DirectQuery-läge returneras de flesta frågeresultat av Power BI-frågemotorn och minnesintern sammansättningscache. Frågebearbetningsbelastningen på datakällans system vid högsta rapporteringstider kan minskas avsevärt, vilket innebär ökad skalbarhet i datakällans serverdel.
- Enkel konfiguration – Modellägare kan aktivera automatisk aggregeringsträning och schemalägga en eller flera uppdateringar för modellen. Med den första träningen och uppdateringen börjar automatiska aggregeringar skapa ett aggregeringsramverk och optimala aggregeringar. Systemet justerar sig automatiskt över tid.
- Finjustering – Med ett enkelt och intuitivt användargränssnitt i modellinställningarna kan du uppskatta prestandaökningarna för en annan procentandel frågor som returneras från minnesinterna aggregeringar och göra justeringar för ännu större vinster. Med en enda bildlistkontroll kan du enkelt finjustera din miljö.
Behov
Planer som stöds
Automatiska aggregeringar stöds för Power BI Premium per kapacitet, Premium per användare och Power BI Embedded-modeller.
Datakällor som stöds
Automatiska aggregeringar stöds för följande datakällor:
- Azure SQL Database
- Dedikerad SQL-pool i Azure Synapse
- SQL Server 2019 eller senare
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
Lägen som stöds
Automatiska aggregeringar stöds för DirectQuery-lägesmodeller. Sammansatta modellmodeller med både importtabeller och DirectQuery-anslutningar stöds. Automatiska aggregeringar stöds endast för DirectQuery-anslutningen.
Behörigheter
Om du vill aktivera och konfigurera automatiska aggregeringar måste du vara modellägare. Arbetsyteadministratörer kan ta över som ägare för att konfigurera inställningar för automatiska sammansättningar.
Konfigurera automatiska aggregeringar
Automatiska aggregeringar konfigureras i modell Inställningar. Det är enkelt att konfigurera – aktivera automatisk aggregeringsträning och schemalägga en eller flera uppdateringar. Innan du konfigurerar automatiska aggregeringar för din modell bör du läsa igenom den här artikeln helt. Det ger en god förståelse för hur automatiska aggregeringar fungerar och kan hjälpa dig att avgöra om automatiska aggregeringar är rätt för din miljö. När du är redo för stegvisa instruktioner om hur du aktiverar automatisk aggregeringsträning, konfigurerar ett uppdateringsschema och finjusterar för din miljö kan du läsa Konfigurera automatiska aggregeringar.
Förmåner
Varje gång en modellanvändare öppnar en rapport eller interagerar med en rapportvisualisering skickas DAX-frågor (Data Analysis Expressions) till frågemotorn och sedan till serverdelsdatakällan som SQL-frågor. Datakällan måste beräkna och returnera resultat för varje fråga. Jämfört med importlägesmodeller som lagras i minnet kan DirectQuery-datakällans rundresor vara både tids- och processintensiva, vilket ofta orsakar långsamma svarstider för frågor i rapportvisualiseringar.
När den är aktiverad för en DirectQuery-modell kan automatiska aggregeringar öka rapportens frågeprestanda genom att undvika resor med datakällans frågor. Föraggregerade frågeresultat returneras automatiskt av en minnesintern aggregeringscache i stället för att skickas till och returneras av datakällan. Mängden föraggregerade data i minnesintern aggregeringscache är en liten del av mängden data som lagras i fakta- och detaljtabeller i datakällan. Resultatet är inte bara bättre prestanda för rapportfrågor, utan även minskad belastning på serverdelsdatakällans system. Med automatiska aggregeringar skickas endast en liten del av rapport- och ad hoc-frågor som kräver sammansättningar som inte ingår i minnesintern cache till serverdelsdatakällan, precis som med rent DirectQuery-läge.
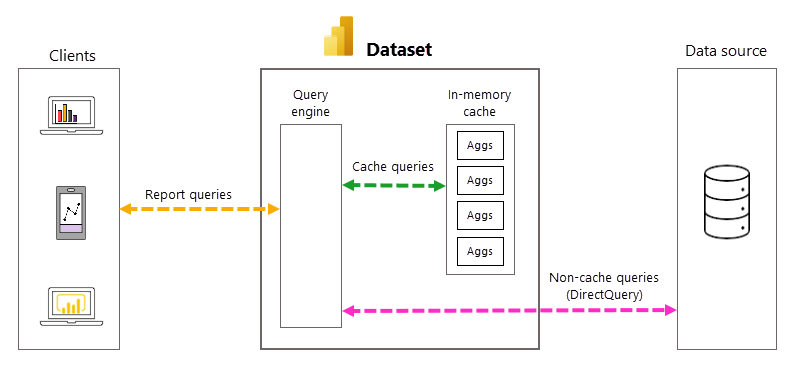
Automatisk hantering av frågor och sammansättningar
Även om automatiska aggregeringar eliminerar behovet av att skapa användardefinierade aggregeringstabeller och avsevärt förenkla implementeringen av en föraggregerad datalösning, är en djupare kunskap om de underliggande processerna och beroendena användbar för att förstå hur automatiska aggregeringar fungerar. Power BI förlitar sig på följande för att skapa och hantera automatiska aggregeringar.
Frågelogg
Power BI spårar modell- och användarrapportfrågor i en frågelogg. För varje modell har Power BI sju dagars frågeloggdata. Frågeloggdata distribueras varje dag. Frågeloggen är säker och visas inte för användare eller via XMLA-slutpunkten.
Träningsåtgärder
Som en del av den första schemalagda modelluppdateringsåtgärden för den valda frekvensen (dag eller vecka) initierar Power BI först en träningsåtgärd som utvärderar frågeloggen för att säkerställa att sammansättningar i minnesintern sammansättningscachen anpassas till förändrade frågemönster. Minnesinterna sammansättningstabeller skapas, uppdateras eller tas bort och särskilda frågor skickas till datakällan för att fastställa sammansättningar som ska ingå i cacheminnet. Beräknade aggregeringsdata läses dock inte in i minnesintern cache under träning – de läses in under den efterföljande uppdateringsåtgärden.
Om du till exempel väljer en Dag-frekvens och schemat uppdateras kl. 04:00, 09:00, 14:00 och 19:00 kommer endast uppdatering 04:00 varje dag att innehålla både en träningsåtgärd och en uppdateringsåtgärd. De efterföljande schemalagda uppdateringarna 09:00, 14:00 och 19:00 för den dagen är endast uppdateringsåtgärder som uppdaterar de befintliga aggregeringarna i cacheminnet.

Träningsåtgärder utvärderar tidigare frågor från frågeloggen, men resultaten är tillräckligt korrekta för att säkerställa att framtida frågor omfattas. Det finns dock ingen garanti för att framtida frågor returneras av minnesintern sammansättningscache eftersom dessa nya frågor kan skilja sig från de som härleds från frågeloggen. De frågor som inte returneras av cacheminnet för sammansättningar skickas till datakällan med hjälp av DirectQuery. Beroende på frekvensen och rangordningen för dessa nya frågor kan sammansättningar för dem ingå i minnesintern sammansättningscache med nästa träningsåtgärd.
Träningsåtgärden har en tidsgräns på 60 minuter. Om träningen inte kan bearbeta hela frågeloggen inom tidsgränsen loggas ett meddelande i modellen Uppdateringshistorik och träningen återupptas nästa gång den startas. Träningscykeln slutförs och ersätter de befintliga automatiska aggregeringarna när hela frågeloggen bearbetas.
Uppdateringsåtgärder
Som vi beskrev tidigare, när träningsåtgärden har slutförts som en del av den första schemalagda uppdateringen för den valda frekvensen, utför Power BI en uppdateringsåtgärd som frågar efter och läser in nya och uppdaterade aggregeringsdata i minnesintern sammansättningscache och tar bort eventuella aggregeringar som inte längre rankas tillräckligt högt (enligt träningsalgoritmen). Alla efterföljande uppdateringar för den valda frekvensen Dag eller Vecka är endast uppdateringsåtgärder som frågar datakällan för att uppdatera befintliga aggregeringsdata i cacheminnet. Med vårt tidigare exempel är de schemalagda uppdateringarna 09:00, 14:00 och 19:00 schemalagda uppdateringar för den dagen endast uppdateringsåtgärder.

Regelbundet schemalagda uppdateringar under hela dagen (eller veckan) säkerställer att aggregeringsdata i cacheminnet är mer uppdaterade med data i serverdelsdatakällan. Via modell Inställningar kan du schemalägga upp till 48 uppdateringar per dag för att säkerställa att rapportfrågor som returneras av aggregeringscachen får resultat baserat på de senaste uppdaterade data från serverdelsdatakällan.
Varning
Tränings- och uppdateringsåtgärder är process- och resursintensiva för både Power BI-tjänst och datakällans system. Om du ökar procentandelen frågor som använder aggregeringar måste fler aggregeringar efterfrågas och beräknas från datakällor under tränings- och uppdateringsåtgärder, vilket ökar sannolikheten för överdriven användning av systemresurser och potentiellt orsakar timeouter. Mer information finns i Finjustering.
Utbildning på begäran
Som tidigare nämnts kanske en träningscykel inte slutförs inom tidsgränserna för en enskild datauppdateringscykel. Om du inte vill vänta till nästa schemalagda uppdateringscykel som innehåller träning kan du också utlösa automatisk aggregeringsträning på begäran genom att välja Träna och uppdatera nu i modell Inställningar. Genom att använda Träna och Uppdatera nu utlöser både en träningsåtgärd och en uppdateringsåtgärd. Kontrollera modelluppdateringshistoriken för att se om den aktuella åtgärden är klar innan du kör en annan tränings- och uppdateringsåtgärd på begäran, om det behövs.
Uppdatera historik
Varje uppdateringsåtgärd registreras i modellen Uppdateringshistorik. Viktig information om varje uppdatering visas, inklusive antalet minnesaggregeringar i cacheminnet som används för den konfigurerade frågeprocenten. Om du vill visa uppdateringshistorik går du till sidan modell Inställningar och väljer Uppdateringshistorik. Om du vill öka detaljnivån ytterligare väljer du Visa information.

Genom att regelbundet kontrollera uppdateringshistoriken kan du se till att dina schemalagda uppdateringsåtgärder slutförs inom en acceptabel period. Kontrollera att uppdateringsåtgärderna slutförs innan nästa schemalagda uppdatering påbörjas.
Tränings- och uppdateringsfel
Power BI utför tränings- och uppdateringsåtgärder som en del av den första schemalagda uppdateringen för den dag eller vecka som du väljer, men dessa åtgärder implementeras som separata transaktioner. Om en träningsåtgärd inte kan bearbeta frågeloggen helt inom sina tidsgränser kommer Power BI att fortsätta uppdatera de befintliga aggregeringarna (och vanliga tabeller i en sammansatt modell) med hjälp av det tidigare träningstillståndet. I det här fallet anger uppdateringshistoriken att uppdateringen har slutförts och att träningen återupptar bearbetningen av frågeloggen nästa gång träningen startas. Frågeprestanda kan vara mindre optimerade om frågemönstren för klientrapporter ändras och sammansättningarna inte har justerats ännu, men den uppnådda prestandanivån bör fortfarande vara mycket bättre än en ren DirectQuery-modell utan några aggregeringar.

Om en träningsåtgärd kräver för många cykler för att slutföra bearbetningen av frågeloggen bör du överväga att minska procentandelen frågor som använder minnesintern sammansättningscache i modell Inställningar. Detta minskar antalet aggregeringar som skapats i cacheminnet, men ger mer tid för träning och uppdatering att slutföras. Mer information finns i Finjustering.
Om träningen lyckas men uppdateringen misslyckas markeras hela uppdateringen som Misslyckad eftersom resultatet är en otillgänglig minnesintern sammansättningscache.
När du schemalägger uppdateringen kan du ange e-postaviseringar om det uppstår uppdateringsfel.
Användardefinierade och automatiska aggregeringar
Användardefinierade aggregeringar i Power BI kan konfigureras manuellt baserat på dolda aggregerade tabeller i modellen. Att konfigurera användardefinierade aggregeringar är ofta komplext, vilket kräver en högre nivå av datamodellering och frågeoptimering. Automatiska aggregeringar å andra sidan eliminerar den här komplexiteten som en del av ett AI-drivet system. Till skillnad från användardefinierade aggregeringar som förblir statiska underhåller Power BI kontinuerligt frågeloggar och från dessa loggar avgörs frågemönster baserat på algoritmer för förutsägande modellering av maskininlärning (ML). Föraggregerade data beräknas och lagras i minnet baserat på frågemönsteranalys. Med automatiska aggregeringar är modeller både självträning och självoptimering. När frågemönstren för klientrapporter ändras justeras de automatiska aggregeringarna, prioriterar och cachelagrar de aggregeringar som används oftast.
Eftersom automatiska aggregeringar bygger på den befintliga användardefinierade aggregeringsinfrastrukturen är det möjligt att använda både användardefinierade och automatiska aggregeringar tillsammans i samma modell. Skickliga datamodellerare kan definiera aggregeringar för tabeller med directquery, import (med eller utan inkrementell uppdatering) eller dubbla lagringslägen, samtidigt som de har fördelarna med fler automatiska aggregeringar för frågor över DirectQuery-anslutningar som inte når de användardefinierade aggregeringstabellerna. Den här flexibiliteten möjliggör balanserade arkitekturer som kan minska frågebelastningen och undvika flaskhalsar.
Sammansättningar som skapats i minnesintern cache av träningsalgoritmen för automatiska sammansättningar identifieras som System aggregeringar. Träningsalgoritmen skapar och tar bara bort dessa System aggregeringar när rapporteringsfrågor analyseras och justeringar görs för att upprätthålla optimala sammansättningar för modellen. Både användardefinierade och automatiska aggregeringar uppdateras med uppdatering. Endast de aggregeringar som skapats av automatiska aggregeringar och markerats som systemgenererade aggregeringar ingår i automatisk aggregeringsbearbetning.
Cachelagring av frågor och automatiska aggregeringar
Power BI Premium har också stöd för cachelagring av frågor i Power BI Premium/Embedded för att upprätthålla frågeresultat. Cachelagring av frågor är en annan funktion än automatiska aggregeringar. Med cachelagring av frågor använder Power BI Premium sin lokala cachelagringstjänst för att implementera cachelagring, medan automatiska aggregeringar implementeras på modellnivå. Med cachelagring av frågor cachelagrar tjänsten endast frågor för den första inläsningen av rapportsidan. Därför förbättras inte frågeprestanda när användarna interagerar med en rapport. Däremot optimerar automatiska aggregeringar de flesta rapportfrågor genom att cachelagra aggregerade frågeresultat före cachelagring, inklusive de frågor som genereras när användare interagerar med rapporter. Cachelagring av frågor och automatiska aggregeringar kan båda aktiveras för en modell, men det är förmodligen inte nödvändigt.
Övervaka med Azure Log Analytics
Azure Log Analytics (LA) är en tjänst i Azure Monitor som Power BI kan använda för att spara aktivitetsloggar. Med Azure Monitor-paketet kan du samla in, analysera och agera på telemetridata från dina Azure- och lokala miljöer. Den erbjuder långsiktig lagring, ett ad hoc-frågegränssnitt och API-åtkomst för att tillåta dataexport och integrering med andra system. Mer information finns i Använda Azure Log Analytics i Power BI.
Om Power BI har konfigurerats med ett Azure LA-konto, enligt beskrivningen i Konfigurera Azure Log Analytics för Power BI, kan du analysera framgångsgraden för dina automatiska aggregeringar. Du kan bland annat avgöra om rapportfrågor besvaras från minnesintern cache.
Om du vill använda den här möjligheten laddar du ned PBIT-mallen och ansluter den till ditt Log Analytics-konto enligt beskrivningen i det här Power BI-blogginlägget. I rapporten kan du visa data på tre olika nivåer: Sammanfattningsvy, DAX-frågenivåvy och SQL-frågenivåvy.
Följande bild visar sammanfattningssidan för alla frågor. Som du ser visar det markerade diagrammet procentandelen av de totala frågor som uppfylldes av aggregeringar jämfört med de som var tvungna att använda datakällan.

Nästa steg för att gå djupare är att titta på användningen av aggregeringar på DAX-frågenivå. Högerklicka på en DAX-fråga från listan (längst ned till vänster) >Granska frågehistoriken>.

På så sätt får du en lista över alla relevanta frågor. Gå vidare till nästa nivå för att visa mer aggregeringsinformation.

Hantering av programmets livscykel
Från utveckling till test och från test till produktion har modeller med automatiska aggregeringar aktiverade särskilda krav för ALM-lösningar.
Distributionspipelines
Med distributionspipelines kan Power BI kopiera modellerna med sin modellkonfiguration från den aktuella fasen till målfasen. Automatiska aggregeringar måste dock återställas i målfasen eftersom inställningarna inte överförs från aktuell till målfas. Du kan också distribuera innehåll programmatiskt med hjälp av REST API:er för distributionspipelines. Mer information om den här processen finns i Automatisera din distributionspipeline med API:er och DevOps.
Anpassade ALM-lösningar
Om du använder en anpassad ALM-lösning baserat på XMLA-slutpunkter bör du tänka på att din lösning kanske kan kopiera systemgenererade och användarskapade sammansättningstabeller som en del av modellmetadata. Du måste dock aktivera automatiska aggregeringar efter varje distributionssteg i målfasen manuellt. Power BI behåller konfigurationen om du skriver över en befintlig modell.
Kommentar
Om du laddar upp eller publicerar om en modell som en del av en Power BI Desktop-fil (.pbix) går systemskapade sammansättningstabeller förlorade eftersom Power BI ersätter den befintliga modellen med alla dess metadata och data på målarbetsytan.
Ändra en modell
När du har ändrat en modell med automatiska aggregeringar aktiverade via XMLA-slutpunkter, till exempel att lägga till eller ta bort tabeller, bevarar Power BI alla befintliga aggregeringar som kan vara och tar bort de som inte längre behövs eller är relevanta. Frågeprestanda kan påverkas tills nästa träningsfas utlöses.
Metadataelement
Modeller med automatiska aggregeringar aktiverade innehåller unika systemgenererade sammansättningstabeller. Sammansättningstabeller är inte synliga för användare i rapporteringsverktyg. De visas via XMLA-slutpunkten med hjälp av verktyg med Analysis Services-klientbibliotek version 19.22.5 och senare. När du arbetar med modeller med automatiska aggregeringar aktiverade måste du uppgradera dina datamodellerings- och administrationsverktyg till den senaste versionen av klientbiblioteken. För SQL Server Management Studio (SSMS) uppgraderar du till SSMS version 18.9.2 eller senare. Tidigare versioner av SSMS kan inte räkna upp tabeller eller skripta ut dessa modeller.
Automatiska sammansättningstabeller identifieras av en SystemManaged tabellegenskap, som är ny för tabellobjektmodellen (TOM) i Analysis Services-klientbibliotek version 19.22.5 och senare. Följande kodfragment visar egenskapen inställd true på SystemManaged för automatiska sammansättningstabeller och false för vanliga tabeller.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
Om du kör det här kodfragmentet genereras automatiska sammansättningstabeller som för närvarande ingår i modellen i en konsol.

Kom ihåg att sammansättningstabeller ständigt förändras när träningsåtgärder avgör de optimala sammansättningar som ska inkluderas i cacheminnet för sammansättningar.
Viktigt!
Power BI hanterar fullständigt systemgenererade tabellobjekt med automatiska sammansättningar. Ta inte bort eller ändra tabellerna själv. Detta kan orsaka försämrade prestanda.
Power BI underhåller modellkonfigurationen utanför modellen. Förekomsten av en systemhanterad sammansättningstabell i en modell betyder inte nödvändigtvis att modellen faktiskt är aktiverad för automatisk aggregeringsträning. Med andra ord, om du skriptar ut en fullständig modelldefinition för en modell med automatiska aggregeringar aktiverade och skapar en ny kopia av modellen (med ett annat namn/arbetsyta/kapacitet), är den nya resulterande modellen inte aktiverad för automatisk aggregeringsträning. Du måste fortfarande aktivera automatisk aggregeringsträning för den nya modellen i modell Inställningar.
Beaktanden och begränsningar
Tänk på följande när du använder automatiska aggregeringar:
- Sammansättningar stöder inte dynamiska M-frågeparametrar.
- SQL-frågorna som genereras under den inledande träningsfasen kan generera betydande belastning för informationslagret. Om träningen fortsätter att slutföras ofullständig och du kan kontrollera på informationslagersidan att frågorna överskrider tidsgränsen kan du överväga att tillfälligt skala upp informationslagret för att uppfylla utbildningsbehovet.
- Sammansättningar som lagras i cacheminnet för sammansättningar kanske inte beräknas på de senaste data i datakällan. Till skillnad från ren DirectQuery, och mer som vanliga importtabeller, finns det en svarstid mellan uppdateringar vid datakällan och aggregeringsdata som lagras i minnesintern sammansättningscache. Det kommer alltid att finnas en viss fördröjning, men det kan minimeras genom ett effektivt uppdateringsschema.
- Om du vill optimera prestanda ytterligare ställer du in alla dimensionstabeller på Dubbelt läge och lämnar faktatabeller i DirectQuery-läge.
- Automatiska aggregeringar är inte tillgängliga med Power BI Pro, Azure Analysis Services eller SQL Server Analysis Services.
- Power BI stöder inte nedladdning av modeller med automatiska aggregeringar aktiverade. Om du har laddat upp eller publicerat en Power BI Desktop-fil (.pbix) till Power BI och sedan aktiverat automatiska aggregeringar kan du inte längre ladda ned PBIX-filen. Se till att du behåller en kopia av PBIX-filen lokalt.
- Automatiska aggregeringar med externa tabeller i Azure Synapse Analytics stöds inte. Du kan räkna upp externa tabeller i Synapse med hjälp av följande SQL-fråga:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables. - Automatiska aggregeringar är endast tillgängliga för modeller med förbättrade metadata. Om du vill aktivera automatiska aggregeringar för en äldre modell uppgraderar du modellen till förbättrade metadata först. Mer information finns i Använda förbättrade modellmetadata.
- Aktivera inte automatiska aggregeringar om DirectQuery-datakällan har konfigurerats för enkel inloggning och använder dynamiska datavyer eller säkerhetskontroller för att begränsa de data som en användare har åtkomst till. Automatiska aggregeringar känner inte till dessa kontroller på datakällnivå, vilket gör det omöjligt att se till att rätt data tillhandahålls per användare. Träningen loggar en varning i uppdateringshistoriken om att den har identifierat en datakälla som konfigurerats för enkel inloggning och hoppat över tabellerna som använder den här datakällan. Om möjligt inaktiveraR du enkel inloggning för dessa datakällor för att dra full nytta av de optimerade frågeprestanda som automatiska aggregeringar kan ge.
- Aktivera inte automatiska aggregeringar om modellen endast innehåller hybridtabeller för att undvika onödiga bearbetningskostnader. En hybridtabell använder både importpartitioner och en DirectQuery-partition. Ett vanligt scenario är inkrementell uppdatering med realtidsdata där en DirectQuery-partition hämtar transaktioner från datakällan som inträffade efter den senaste datauppdateringen. Power BI importerar dock aggregeringar under uppdateringen. Automatiska aggregeringar kan inte inkludera transaktioner som inträffade efter den senaste datauppdateringen. Träningen loggar en varning i uppdateringshistoriken om att den identifierade och hoppades över hybridtabeller.
- Beräknade kolumner beaktas inte för automatiska aggregeringar. Om du använder en beräknad kolumn i DirectQuery-läge, till exempel genom att använda
COMBINEVALUESDAX-funktionen för att skapa en relation baserat på flera kolumner från två DirectQuery-tabeller, når motsvarande rapportfrågor inte cacheminnet för sammansättningar i minnet. - Automatiska aggregeringar är endast tillgängliga i Power BI-tjänst. Power BI Desktop skapar inte systemgenererade sammansättningstabeller.
- Om du ändrar metadata för en modell med automatiska aggregeringar aktiverade kan frågeprestanda försämras tills nästa träningsprocess utlöses. Som bästa praxis bör du släppa de automatiska aggregeringarna, göra ändringarna och sedan träna om.
- Ändra eller ta inte bort systemgenererade sammansättningstabeller om du inte har inaktiverat automatiska aggregeringar och rensar modellen. Systemet tar ansvar för att hantera dessa objekt.
Community
Power BI har en livlig community där MVP:er, BI-proffs och kollegor delar med sig av expertis i diskussionsgrupper, videor, bloggar med mera. När du lär dig mer om automatiska aggregeringar bör du kolla in följande andra resurser:
Relaterat innehåll
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för