รวม OneLake เข้ากับ Azure Synapse Analytics
Azure Synapse เป็นบริการด้านการวิเคราะห์แบบไร้ขีดจำกัดที่รวมการสร้างคลังข้อมูลองค์กรกับการวิเคราะห์ข้อมูลขนาดใหญ่ไว้ด้วยกัน บทช่วยสอนนี้แสดงวิธีการเชื่อมต่อกับ OneLake โดยใช้ Azure Synapse Analytics
เขียนข้อมูลจาก Synapse โดยใช้ Apache Spark
ทําตามขั้นตอนเหล่านี้เพื่อใช้ Apache Spark เพื่อเขียนข้อมูลตัวอย่างไปยัง OneLake จาก Azure Synapse Analytics
เปิดพื้นที่ทํางาน Synapse ของคุณและ สร้างพูล Apache Spark ด้วยพารามิเตอร์ที่คุณต้องการ
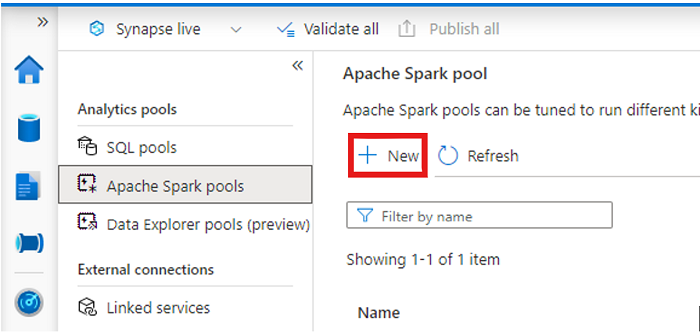
สร้างสมุดบันทึก Apache Spark ใหม่
เปิดสมุดบันทึก ตั้งค่าภาษาเป็น PySpark (Python) และเชื่อมต่อกับพูล Spark ที่สร้างขึ้นใหม่ของคุณ
ในแท็บแยกต่างหาก ให้นําทางไปยัง Microsoft Fabric lakehouse ของคุณ และค้นหาโฟลเดอร์ ตาราง ระดับบนสุด
คลิกขวาบนโฟลเดอร์ ตาราง และเลือก คุณสมบัติ
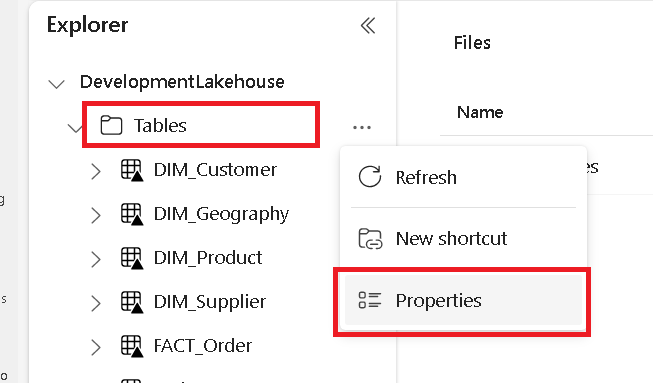
คัดลอกเส้นทาง ABFS จากบานหน้าต่างคุณสมบัติ
กลับไปในสมุดบันทึก Azure Synapse ในเซลล์โค้ดใหม่แรก ให้ระบุเส้นทางของเลคเฮ้าส์ เลคเฮาส์แห่งนี้เป็นที่ที่ข้อมูลของคุณจะถูกเขียนในภายหลัง เรียกใช้เซลล์
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'ในเซลล์รหัสใหม่ ให้โหลดข้อมูลจากชุดข้อมูลเปิดของ Azure ลงใน dataframe ชุดข้อมูลนี้เป็นข้อมูลที่คุณโหลดลงในเลคเฮ้าส์ของคุณ เรียกใช้เซลล์
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))ในเซลล์โค้ดใหม่ กรอง แปลง หรือเตรียมข้อมูลของคุณ สําหรับสถานการณ์นี้ คุณสามารถตัดแต่งชุดข้อมูลของคุณสําหรับการโหลดได้เร็วขึ้น รวมกับชุดข้อมูลอื่น ๆ หรือกรองไปยังผลลัพธ์ที่เฉพาะเจาะจง เรียกใช้เซลล์
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))ในเซลล์โค้ดใหม่ โดยใช้เส้นทาง OneLake ของคุณ ให้เขียนกรอบข้อมูลที่กรองแล้วของคุณไปยังตาราง Delta-Parquet ใหม่ใน Fabric lakehouse ของคุณ เรียกใช้เซลล์
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')สุดท้าย ในเซลล์โค้ดใหม่ ให้ทดสอบว่าข้อมูลของคุณถูกเขียนเรียบร้อยแล้วโดยการอ่านไฟล์ที่โหลดใหม่ของคุณจาก OneLake เรียกใช้เซลล์
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
ขอแสดงความยินดี ตอนนี้คุณสามารถอ่านและเขียนข้อมูลใน OneLake โดยใช้ Apache Spark ใน Azure Synapse Analytics ได้แล้ว
อ่านข้อมูลจาก Synapse โดยใช้ SQL
ทําตามขั้นตอนเหล่านี้เพื่อใช้ SQL serverless เพื่ออ่านข้อมูลจาก OneLake จาก Azure Synapse Analytics
เปิด Fabric lakehouse และระบุตารางที่คุณต้องการสอบถามจาก Synapse
คลิกขวาบนตาราง และเลือก คุณสมบัติ
คัดลอกเส้นทาง ABFS สําหรับตาราง
เปิดพื้นที่ทํางาน Synapse ของคุณใน Synapse Studio
สร้างสคริปต์ SQL ใหม่
ในตัวแก้ไขคิวรี SQL ให้ใส่คิวรีต่อไปนี้ โดย
ABFS_PATH_HEREแทนที่ด้วยเส้นทางที่คุณคัดลอกไว้ก่อนหน้านี้SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;เรียกใช้คิวรีเพื่อดู 10 แถวบนสุดของตารางของคุณ
ขอแสดงความยินดี ตอนนี้คุณสามารถอ่านข้อมูลจาก OneLake โดยใช้ SQL serverless ใน Azure Synapse Analytics ได้แล้ว
เนื้อหาที่เกี่ยวข้อง
คำติชม
เร็วๆ นี้: ตลอดปี 2024 เราจะขจัดปัญหา GitHub เพื่อเป็นกลไกคำติชมสำหรับเนื้อหา และแทนที่ด้วยระบบคำติชมใหม่ สำหรับข้อมูลเพิ่มเติม ให้ดู: https://aka.ms/ContentUserFeedback
ส่งและดูข้อคิดเห็นสำหรับ