İlişkisel olmayan veritabanı , çoğu geleneksel veritabanı sisteminde bulunan satır ve sütunların tablo şemasını kullanmayan bir veritabanıdır. Bunun yerine ilişkisel olmayan veritabanları, depolanmakta olan veri türünün belirli gereksinimleri için iyileştirilmiş bir depolama modeli kullanır. Örneğin, veriler basit anahtar/değer çiftleri, JSON belgeleri veya kenar ve köşelerden oluşan bir grafik olarak depolanabilir.
Bu veri depolarının ortak yanı, ilişkisel model kullanmamalarıdır. Ayrıca, destekledikleri veri türü ve verilerin nasıl sorgulanabileceği konusunda daha belirgin olma eğilimindedirler. Örneğin, zaman serisi veri depoları zaman tabanlı veri dizileri içindeki sorgular için iyileştirilmiştir. Ancak, grafik veri depoları varlıklar arasındaki ağırlıklı ilişkileri keşfetmek için iyileştirilmiştir. her iki biçim de işlem verilerini yönetme görevine iyi genelleştirilemez.
NoSQL terimi, sorgular için SQL kullanmayan veri depolarını ifade eder. Bunun yerine, veri depoları verileri sorgulamak için diğer programlama dillerini ve yapılarını kullanır. Uygulamada, "NoSQL" "ilişkisel olmayan veritabanı" anlamına gelir, ancak bu veritabanlarının çoğu SQL uyumlu sorguları destekler. Ancak temel alınan sorgu yürütme stratejisi genellikle geleneksel RDBMS'nin aynı SQL sorgusunu yürütme yönteminden çok farklıdır.
Aşağıdaki bölümlerde ilişkisel olmayan veya NoSQL veritabanının ana kategorileri açıklanmaktadır.
Belge veri depoları
Belge veri deposu, belge olarak adlandırılan bir varlıktaki adlandırılmış dize alanları ve nesne veri değerleri kümesini yönetir. Bu veri depoları genellikle verileri JSON belgeleri biçiminde depolar. Her alan değeri sayı gibi bir skaler öğe ya da liste ya da üst-alt koleksiyon gibi bileşik bir öğe olabilir. Belgenin alanlarındaki veriler XML, YAML, JSON, BSON gibi çeşitli yollarla kodlanabilir, hatta düz metin olarak depolanabilir. Belgeler içindeki alanlar depolama yönetim sistemine sunulur ve bu sayede bir uygulamanın bu alanlardaki değerleri kullanarak verileri sorgulaması ve filtrelemesi sağlanır.
Belgelerde genellikle bir varlığa ait verilerin tamamı bulunur. Bir varlığı oluşturan öğeler uygulamaya göre farklılık gösterir. Örneğin bir varlık, tek bir müşteriyle veya siparişle ilgili bilgileri içerebileceği gibi ikisini birden de içerebilir. Tek bir belge, ilişkisel veritabanı yönetim sistemindeki (RDBMS) çeşitli ilişkisel tablolara yayılacak bilgiler içerebilir. Belge deposundaki tüm belgelerin yapısının aynı olması şart değildir. Bu serbest biçimli yaklaşım yüksek esneklik sunar. Örneğin, uygulamalar iş gereksinimlerindeki bir değişikliğe yanıt olarak belgelerde farklı veriler depolayabilir.
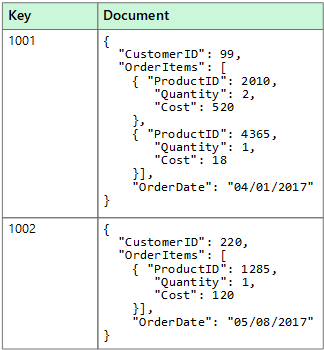
Uygulama, belgeleri belge anahtarını kullanarak alabilir. Anahtar, verilerin eşit dağıtıldığına yardımcı olmak için belgenin genellikle karma olarak dağıtılan benzersiz bir tanımlayıcısıdır. Bazı belge veritabanları, belge anahtarını otomatik olarak oluşturur. Diğerlerinde anahtar olarak kullanmak istediğiniz belge özniteliğini belirtebilirsiniz. Uygulama, belgeleri bir veya daha fazla alanın değerine göre de sorgulayabilir. Bazı belge veritabanları, belgeleri bir veya daha fazla dizine eklenmiş alana göre hızlı bir şekilde aramak için dizinleme desteği sunar.
Birçok belge veritabanı yerinde güncelleştirmeyi destekler ve bir uygulamanın tüm belgeyi yeniden yazması gerekmeden belgedeki belirli alanların değerlerini değiştirmesine olanak verir. Tek bir belgedeki birden çok alan üzerinde yapılan okuma ve yazma işlemleri genellikle atomik olur.
İlgili Azure hizmeti:
Sütunlu veri depoları
Sütunlu veya sütun ailesi veri deposu, verileri sütunlar ve satırlar halinde düzenler. En basit haliyle, sütun ailesi veri deposu en azından kavramsal olarak ilişkisel bir veritabanına çok benzer görünebilir. Sütun ailesi veritabanının gerçek gücü, seyrek verileri yapılandırmaya yönelik normalleştirilmiş yaklaşımındadır ve bu yaklaşım, verileri depolamaya yönelik sütun odaklı yaklaşımdan kaynaklanır.
Sütun ailesi veri depolarını satırlar ve sütunlar içeren tablosal verileri tutmak olarak düşünebilirsiniz, ancak sütunlar sütun aileleri olarak bilinen gruplara ayrılır. Her sütun ailesi mantıksal olarak ilişkili olan ve genellikle birim olarak alınan veya işlenen bir sütun kümesine sahiptir. Ayrı olarak erişilen diğer veriler ayrı sütun ailelerinde depolanabilir. Bir sütun ailesi içinde yeni sütunlar dinamik olarak eklenebilir ve satırlar seyrek olabilir (diğer bir deyişle, bir satırın her sütun için bir değere sahip olması gerekmez).
Aşağıdaki diyagramda iki sütun ailesi (Identity ve Contact Info) içeren bir örnek gösterilmektedir. Tek bir varlığın verileri her sütun ailesinde aynı satır anahtarına sahiptir. Sütun ailesindeki herhangi bir nesnenin satırlarının dinamik olarak değişebildiği bu yapı, sütun ailesi yaklaşımının önemli bir avantajıdır ve bu da bu veri deposu biçimini değişen şemalara sahip verileri depolamak için son derece uygundur.

Anahtar/değer deposu veya belge veritabanından farklı olarak, sütun ailesi veritabanlarının çoğu verileri karma hesaplama yerine fiziksel olarak anahtar sırada depolar. Satır anahtarı birincil dizin olarak kabul edilir ve belirli bir anahtar veya anahtar aralığı aracılığıyla anahtar tabanlı erişimi etkinleştirir. Bazı uygulamalar, sütun ailesindeki belirli sütunlar üzerinde ikincil dizinler oluşturmanıza olanak sağlar. İkincil dizinler, verileri satır anahtarı yerine sütunlara göre almanıza olanak sağlar.
Diskte, bir sütun ailesi içindeki tüm sütunlar aynı dosyada birlikte depolanır ve her dosyada belirli sayıda satır bulunur. Büyük veri kümelerinde bu yaklaşım, aynı anda yalnızca birkaç sütun birlikte sorgulandığında diskten okunması gereken veri miktarını azaltarak bir performans avantajı oluşturur.
Bir satır için okuma ve yazma işlemleri genellikle tek bir sütun ailesi içinde atomiktir, ancak bazı uygulamalar birden çok sütun ailesini kapsayan satırın tamamında bölünmezlik sağlar.
İlgili Azure hizmeti:
Anahtar/değer veri depoları
Bir anahtar/değer deposu temelde büyük bir karma tablodur. Her bir veri değerini benzersiz bir anahtar ile ilişkilendirirsiniz ve anahtar/değer deposu uygun bir karma işlevi kullanarak verileri depolamak için bu anahtarı kullanır. Karma işlevi, veri depolama alanında karma anahtarların eşit dağıtımı için seçilir.
Çoğu anahtar/değer deposu yalnızca basit sorgu, ekleme ve silme işlemlerini destekler. Bir değeri kısmen veya tamamen değiştirmek için, uygulamanın tüm değerde mevcut verilerin üzerine yazması gerekir. Çoğu uygulamada tek bir değerin okunması veya yazılması atomik bir işlemdir. Değer büyükse, yazma biraz zaman alabilir.
Bazı anahtar/değer depoları değerlerin en büyük boyutunda sınırları zorunlu tutsa da bir uygulama rasgele verileri bir değerler dizisi olarak depolayabilir. Depolanan değerler, depolama sistemi için donuk değerlerdir. Tüm şema bilgileri uygulama tarafından sağlanır ve yorumlanır. Esas olarak, değerler bloblardır ve anahtar/değer deposu yalnızca anahtara göre değeri alır veya depolar.

Anahtar/değer depoları, anahtarın değerini kullanarak veya bir anahtar aralığıyla basit aramalar gerçekleştiren uygulamalar için yüksek oranda iyileştirilir, ancak verileri birden çok tablo arasında birleştirme gibi farklı anahtar/değer tablolarında veri sorgulaması gereken sistemler için daha az uygundur.
Anahtar/değer depoları, yalnızca anahtarlara dayalı aramalar gerçekleştirmek yerine anahtar olmayan değerlere göre sorgulamanın veya filtrelemenin önemli olduğu senaryolar için de iyileştirilmemiştir. Örneğin, ilişkisel bir veritabanıyla, anahtar olmayan sütunları filtrelemek için WHERE yan tümcesini kullanarak bir kayıt bulabilirsiniz, ancak anahtar/değer depoları genellikle değerler için bu tür arama özelliğine sahip değildir veya varsa, tüm değerlerin yavaş taranması gerekir.
Veri deposu, ayrı makinelerde birden çok düğüm arasında verileri kolayca dağıtabileceğinden tek anahtar/değer deposu son derece ölçeklenebilir olabilir.
İlgili Azure hizmetleri:
Graf veri depoları
Graf veri deposu iki tür bilgiyi, düğümleri ve kenarları yönetir. Düğümler varlıkları temsil eder ve kenarlar bu varlıklar arasındaki ilişkileri belirtir. Hem düğümler ve hem de kenarlar, bir tablodaki sütunlar gibi ilgili düğüm veya kenar hakkında bilgi sağlayan özelliklere sahip olabilir. Kenarlar ayrıca ilişkinin yapısını gösteren bir yöne sahip olabilir.
Graf veri deposunun amacı, bir uygulamanın düğümler ve kenarlar ağından geçiş yapan sorguları verimli bir şekilde gerçekleştirmesine ve varlıklar arasındaki ilişkileri analiz etmesine izin vermektir. Aşağıdaki diyagramda, bir kuruluşun grafik olarak yapılandırılmış personel verileri gösterilmektedir. Varlıklar çalışanlar ve departmanlardır, kenarlar çalışanlar arasındaki ilişkileri ve çalışanların bulunduğu departmanları gösterir. Bu grafta kenarların üzerindeki oklar ilişkilerin yönünü göstermektedir.

Bu yapı, "Doğrudan veya dolaylı olarak Sarah'a rapor veren tüm çalışanları bul" veya "John ile aynı departmanda kimler çalışıyor?" gibi sorguların gerçekleştirilmesini kolaylaştırır. Çok sayıda varlık ve ilişki içeren büyük grafikler için karmaşık analizleri hızla gerçekleştirebilirsiniz. Pek çok grafik veritabanı, ilişkiler ağını verimli bir şekilde işlemenizi sağlayan bir sorgu dili sağlar.
İlgili Azure hizmeti:
Zaman serisi veri depoları
Zaman serisi verileri zamana göre düzenlenmiş bir değer kümesidir ve zaman serisi veri deposu bu tür veriler için iyileştirilir. Zaman serisi veri depoları, genellikle çok sayıda kaynaktan gerçek zamanlı olarak büyük miktarda veri topladıkları için çok fazla sayıda yazmayı desteklemelidir. Zaman serisi veri depoları telemetri verilerini depolamak için iyileştirilmiştir. Kullanım senaryoları IOT algılayıcılarını veya uygulama/sistem sayaçlarını içerir. Güncelleştirmeler nadirdir ve silme işlemleri genellikle toplu işlemler halinde yapılır.
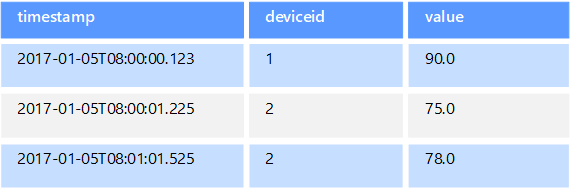
Zaman serisi veritabanına yazılan kayıtlar genellikle küçük olsa da, genellikle çok sayıda kayıt vardır ve toplam veri boyutu hızla büyüyebilir. Zaman serisi veri depoları ayrıca sıra dışı ve geç gelen verileri, veri noktalarının otomatik dizinini oluşturmayı ve zaman pencereleri açısından açıklanan sorgular için iyileştirmeleri işler. Bu son özellik, zaman serisi verilerinin yaygın olarak tüketildiği zaman serisi görselleştirmelerini desteklemek için sorguların milyonlarca veri noktasında ve birden çok veri akışında hızla çalışmasını sağlar.
İlgili Azure hizmetleri:
Nesne veri depoları
Nesne veri depoları görüntüler, metin dosyaları, video ve ses akışları, büyük uygulama veri nesneleri ve belgeleri ve sanal makine disk görüntüleri gibi büyük ikili nesneleri veya blobları depolamak ve almak için iyileştirilmiştir. Nesne, depolanan verilerden, bazı meta verilerden ve nesneye erişmek için benzersiz bir kimlikden oluşur. Nesne depoları, ayrı ayrı çok büyük dosyaları destekleyecek ve tüm dosyaları yönetmek için büyük miktarda toplam depolama alanı sağlayacak şekilde tasarlanmıştır.
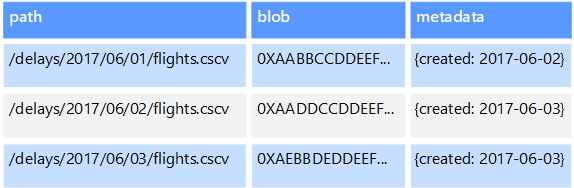
Bazı nesne veri depoları, belirli bir blobu birden çok sunucu düğümü arasında çoğaltarak hızlı paralel okumalar sağlar. Genellikle farklı sunucularda çalışan birden çok işlem büyük veri dosyasını aynı anda sorgulayabildiğinden, bu işlem büyük dosyalarda yer alan verilerin ölçeğini genişletme sorgusunu etkinleştirir.
Nesne veri depolarının özel durumlarından biri, ağ dosya paylaşımıdır. Dosya paylaşımlarının kullanılması, sunucu ileti bloğu (SMB) gibi standart ağ protokolleri kullanılarak dosyalara ağ üzerinden erişilmesine olanak tanır. Uygun güvenlik ve eşzamanlı erişim denetimi mekanizmaları göz önüne alındığında, verilerin bu şekilde paylaşılması, dağıtılmış hizmetlerin basit okuma ve yazma istekleri gibi temel, düşük düzeyli işlemler için yüksek oranda ölçeklenebilir veri erişimi sağlamasına olanak sağlayabilir.
İlgili Azure hizmetleri:
Dış dizin veri depoları
Dış dizin veri depoları, diğer veri depolarında ve hizmetlerde tutulan bilgileri arama olanağı sağlar. Dış dizin, herhangi bir veri deposu için ikincil dizin işlevi görür ve çok büyük hacimli verilerin dizinini oluşturmak ve bu dizinlere neredeyse gerçek zamanlı erişim sağlamak için kullanılabilir.
Örneğin, bir dosya sisteminde depolanan metin dosyalarınız olabilir. Bir dosyayı dosya yoluna göre bulmak hızlı bir işlemdir, ancak dosyanın içeriğine göre arama yapılması için tüm dosyaların taranarak yavaş olması gerekir. Dış dizin, ikincil arama dizinleri oluşturmanıza ve ardından ölçütlerinizle eşleşen dosyaların yolunu hızla bulmanıza olanak tanır. Dış dizinin başka bir örnek uygulaması, yalnızca anahtara göre dizin oluşturan anahtar/değer depolarıdır. Verilerdeki değerleri temel alan ikincil bir dizin oluşturabilir ve eşleşen her öğeyi benzersiz olarak tanımlayan anahtarı hızla arayabilirsiniz.
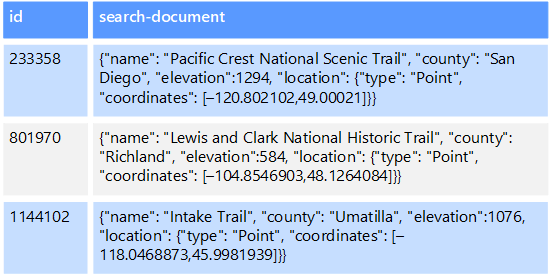
Dizinler bir dizin oluşturma işlemi çalıştırılarak oluşturulur. Bu, veri deposu tarafından tetiklenen bir çekme modeli kullanılarak veya uygulama kodu tarafından başlatılan bir gönderme modeli kullanılarak gerçekleştirilebilir. Dizinler çok boyutlu olabilir ve büyük hacimli metin verilerinde serbest metin aramalarını destekleyebilir.
Dış dizin veri depoları genellikle tam metin ve web tabanlı aramayı desteklemek için kullanılır. Bu gibi durumlarda arama tam veya belirsiz olabilir. Benzer arama, bir terimler kümesiyle eşleşen belgeleri bulur ve ne kadar yakından eşleştiğini hesaplar. Bazı dış dizinler eş anlamlılar, tür genişletmeleri (örneğin, "köpekler" ile "evcil hayvanlar" arasında eşleştirme) ve kök oluşturma (örneğin, "çalıştır" araması da "çalıştır" ve "çalışıyor" ile eşleşir) temelinde eşleşme döndürebilen dil analizini de destekler.
İlgili Azure hizmeti:
Tipik gereksinimler
İlişkisel olmayan veri depoları genellikle ilişkisel veritabanları tarafından kullanılandan farklı bir depolama mimarisi kullanır. Özellikle, sabit bir şemaya sahip olma eğilimindedir. Ayrıca, işlemleri desteklememe veya işlemlerin kapsamını kısıtlama eğilimindedirler ve ölçeklenebilirlik nedeniyle genellikle ikincil dizinler içermezler.
Aşağıdakiler ilişkisel olmayan veri depolarının her birinin gereksinimlerini karşılaştırır:
| Gereksinim | Belge verileri | Sütun ailesi verileri | Anahtar/değer verileri | Grafik verileri |
|---|---|---|---|---|
| Normalleştirme | Normalleştirilmemiş | Normalleştirilmemiş | Normalleştirilmemiş | Normalleştirilmiş |
| Şema | Şema okundu | Yazmada tanımlanan sütun aileleri, okumada sütun şeması | Şema okundu | Şema okundu |
| Tutarlılık (eşzamanlı işlemler arasında) | Ayarlanabilir tutarlılık, belge düzeyinde garantiler | Sütun ailesi düzeyinde garantiler | Anahtar düzeyi garantileri | Graf düzeyi garantileri |
| Bölünmezlik (işlem kapsamı) | Koleksiyon | Tablo | Tablo | Grafik |
| Kilitleme Stratejisi | İyimser (kilitsiz) | Kötümser (satır kilitleri) | İyimser (ETag) | |
| Erişim düzeni | Rastgele erişim | Uzun/geniş verilerde toplamalar | Rastgele erişim | Rastgele erişim |
| Dizinleme | Birincil ve ikincil dizinler | Birincil ve ikincil dizinler | Yalnızca birincil dizin | Birincil ve ikincil dizinler |
| Veri şekli | Belge | Sütun içeren sütun aileleri içeren tablosal | Anahtar ve değer | Kenarları ve köşeleri içeren grafik |
| Seyrek | Evet | Evet | Evet | Hayır |
| Geniş (çok sayıda sütun/öznitelik) | Evet | Evet | Hayı | Hayır |
| Datum boyutu | Küçük (KB) - orta (düşük MB) | Orta (MB) - Büyük (düşük MB) | Küçük (KB) | Küçük (KB) |
| Genel Maksimum Ölçek | Çok Büyük (FIB) | Çok Büyük (FIB) | Çok Büyük (FIB) | Büyük (TB) |
| Gereksinim | Zaman serisi verileri | Nesne verileri | Dış dizin verileri |
|---|---|---|---|
| Normalleştirme | Normalleştirilmiş | Normalleştirilmemiş | Normalleştirilmemiş |
| Şema | Şema okundu | Şema okundu | Yazmada şema |
| Tutarlılık (eşzamanlı işlemler arasında) | Geçersiz | Yok | Geçersiz |
| Bölünmezlik (işlem kapsamı) | Yok | Object | Yok |
| Kilitleme Stratejisi | Yok | Kötümser (blob kilitleri) | Yok |
| Erişim düzeni | Rastgele erişim ve toplama | Sıralı erişim | Rastgele erişim |
| Dizinleme | Birincil ve ikincil dizinler | Yalnızca birincil dizin | Yok |
| Veri şekli | Tablosal | Blob ve meta veriler | Belge |
| Seyrek | No | Yok | No |
| Geniş (çok sayıda sütun/öznitelik) | Hayır | Evet | Evet |
| Datum boyutu | Küçük (KB) | Büyük (GB) ile Çok Büyük (TB) | Küçük (KB) |
| Genel Maksimum Ölçek | Büyük (düşük TB) | Çok Büyük (FIB) | Büyük (düşük TB) |
Katkıda Bulunanlar
Bu makale Microsoft tarafından yönetilir. Başlangıçta aşağıdaki katkıda bulunanlar tarafından yazılmıştır.
Asıl yazar:
- Zoiner Tejada | CEO ve Mimar
Sonraki adımlar
- İlişkisel ve NoSQL verileri karşılaştırması
- Dağıtılmış NoSQL veritabanlarını anlama
- Microsoft Azure Veri temelleri: Azure'da ilişkisel olmayan verileri keşfetme
- İlişkisel olmayan veri modeli uygulama