Eşleme veri akışlarında kaynak dönüştürme
UYGULANANLAR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
İpucu
Kuruluşlar için hepsi bir arada analiz çözümü olan Microsoft Fabric'te Data Factory'yi deneyin. Microsoft Fabric , veri taşımadan veri bilimine, gerçek zamanlı analize, iş zekasına ve raporlamaya kadar her şeyi kapsar. Yeni bir deneme sürümünü ücretsiz olarak başlatmayı öğrenin!
Veri akışları hem Azure Data Factory'de hem de Azure Synapse Pipelines'da kullanılabilir. Bu makale, eşleme veri akışları için geçerlidir. Dönüştürmeler hakkında yeniyseniz lütfen eşleme veri akışı kullanarak verileri dönüştürme başlıklı giriş makalesine bakın.
Kaynak dönüştürme, veri akışı için veri kaynağınızı yapılandırıyor. Veri akışları tasarlarken ilk adımınız her zaman bir kaynak dönüşümü yapılandırmaktır. Kaynak eklemek için veri akışı tuvalinde Kaynak Ekle kutusunu seçin.
Her veri akışı için en az bir kaynak dönüşümü gerekir, ancak veri dönüşümlerinizi tamamlamak için gereken kadar kaynak ekleyebilirsiniz. Bu kaynakları birleştirme, arama veya birleşim dönüşümüyle birleştirebilirsiniz.
Her kaynak dönüşümü tam olarak bir veri kümesi veya bağlı hizmetle ilişkilendirilir. Veri kümesi, yazmak veya buradan okumak istediğiniz verilerin şeklini ve konumunu tanımlar. Dosya tabanlı bir veri kümesi kullanıyorsanız, kaynağınızdaki joker karakterleri ve dosya listelerini kullanarak aynı anda birden fazla dosyayla çalışabilirsiniz.
Satır içi veri kümeleri
Kaynak dönüştürme oluştururken ilk karar, kaynak bilgilerinizin bir veri kümesi nesnesi içinde mi yoksa kaynak dönüştürme içinde mi tanımlandığıdır. Çoğu biçim yalnızca birinde veya diğerinde kullanılabilir. Belirli bir bağlayıcıyı kullanmayı öğrenmek için uygun bağlayıcı belgesine bakın.
Hem satır içi hem de veri kümesi nesnesi için bir biçim desteklendiğinde, her ikisinin de avantajları vardır. Veri kümesi nesneleri, diğer veri akışlarında ve Kopyala gibi etkinliklerde kullanılabilen yeniden kullanılabilir varlıklardır. Bu yeniden kullanılabilir varlıklar özellikle sağlamlaştırılmış bir şema kullandığınızda kullanışlıdır. Veri kümeleri Spark'ta temel değildir. Bazen, kaynak dönüştürmede belirli ayarları veya şema projeksiyonunu geçersiz kılmanız gerekebilir.
Esnek şemalar, tek seferlik kaynak örnekleri veya parametreli kaynaklar kullandığınızda satır içi veri kümeleri önerilir. Kaynağınız yoğun parametreliyse, satır içi veri kümeleri bir "kukla" nesnesi oluşturmamanızı sağlar. Satır içi veri kümeleri Spark'ı temel alır ve özellikleri veri akışında yereldir.
Satır içi veri kümesi kullanmak için Kaynak türü seçicisinde istediğiniz biçimi seçin. Kaynak veri kümesi seçmek yerine, bağlanmak istediğiniz bağlı hizmeti seçersiniz.
Şema seçenekleri
Satır içi veri kümesi veri akışının içinde tanımlandığından, satır içi veri kümesiyle ilişkilendirilmiş tanımlı bir şema yoktur. Projeksiyon sekmesinde, kaynak veri şemasını içeri aktarabilir ve bu şemayı kaynak projeksiyonunuz olarak depolayabilirsiniz. Bu sekmede, ADF'nin şema bulma hizmetinin davranışını tanımlamanızı sağlayan bir "Şema seçenekleri" düğmesi bulursunuz.
- Öngörülen şemayı kullan: Bu seçenek, ADF'nin kaynağınız olarak taradiği çok sayıda kaynak dosyanız olduğunda kullanışlıdır. ADF'nin varsayılan davranışı, her kaynak dosyanın şemasını bulmaktır. Ancak, kaynak dönüştürmenizde önceden tanımlanmış bir projeksiyonunuz zaten depolanmışsa, bunu true olarak ayarlayabilirsiniz ve ADF her şemanın otomatik bulma işlemini atlar. Bu seçenek açıkken, kaynak dönüştürme tüm dosyaları çok daha hızlı bir şekilde okuyabilir ve önceden tanımlanmış şemayı her dosyaya uygulayabilir.
- Şema kaymasına izin ver: Veri akışınızın kaynak şemada henüz tanımlanmamış yeni sütunlara izin vermesi için şema kaymasını açın.
- Şemayı doğrula: Projeksiyonda tanımlanan herhangi bir sütun ve tür kaynak verilerin bulunan şemasıyla eşleşmiyorsa bu seçeneğin ayarlanması veri akışının başarısız olmasına neden olur.
- Sürüklenen sütun türlerini çıkar: Yeni sürüklenen sütunlar ADF tarafından tanımlandığında, bu yeni sütunlar ADF'nin otomatik tür çıkarımı kullanılarak uygun veri türüne dönüştürülür.
Çalışma Alanı VERITABANı (yalnızca Synapse çalışma alanları)
Azure Synapse çalışma alanlarında, adlı Workspace DBveri akışı kaynağı dönüştürmelerinde ek bir seçenek vardır. Bu, ek bağlı hizmetlere veya veri kümelerine gerek kalmadan kaynak verileriniz olarak kullanılabilir herhangi bir türde bir çalışma alanı veritabanını doğrudan seçmenize olanak tanır. Çalışma Alanı VERITABANı'nı seçtiğinizde Azure Synapse veritabanı şablonları aracılığıyla oluşturulan veritabanlarına da erişilebilir.

Desteklenen kaynak türleri
Eşleme veri akışı ayıklama, yükleme ve dönüştürme (ELT) yaklaşımını izler ve tümü Azure'da bulunan hazırlama veri kümeleriyle çalışır. Şu anda aşağıdaki veri kümeleri bir kaynak dönüşümünde kullanılabilir.
Bu bağlayıcılara özgü AyarlarKaynak seçenekleri sekmesi. Bu ayarlardaki bilgi ve veri akışı betiği örnekleri bağlayıcı belgelerinde bulunur.
Azure Data Factory ve Synapse işlem hatlarının 90'dan fazla yerel bağlayıcıya erişimi vardır. Veri akışınıza diğer kaynaklardan veri eklemek için Kopyalama Etkinliği'ni kullanarak bu verileri desteklenen hazırlama alanlarından birine yükleyin.
Kaynak ayarları
Kaynak ekledikten sonra Kaynak ayarları sekmesi aracılığıyla yapılandırın. Burada kaynak noktanız olan veri kümesini seçebilir veya oluşturabilirsiniz. Verileriniz için şema ve örnekleme seçeneklerini de belirleyebilirsiniz.
Veri kümesi parametreleri için geliştirme değerleri hata ayıklama ayarlarında yapılandırılabilir. (Hata ayıklama modu açık olmalıdır.)
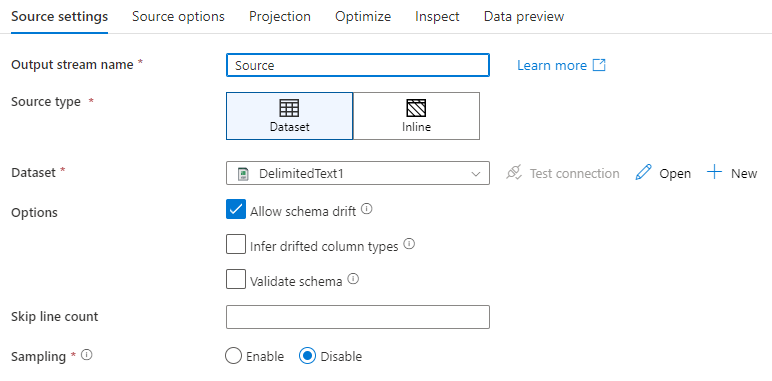
Çıkış akışı adı: Kaynak dönüştürmenin adı.
Kaynak türü: Satır içi veri kümesi mi yoksa var olan bir veri kümesi nesnesi mi kullanmak istediğinizi seçin.
Bağlantıyı test etme: Veri akışının Spark hizmetinin kaynak veri kümenizde kullanılan bağlı hizmete başarıyla bağlanıp bağlanamayacağını test edin. Bu özelliğin etkinleştirilmesi için hata ayıklama modu açık olmalıdır.
Şema kayması: Şema kayması, hizmetin sütun değişikliklerini açıkça tanımlamaya gerek kalmadan veri akışlarınızdaki esnek şemaları yerel olarak işleyebilmesidir.
Kaynak sütunlar sık değişiyorsa Şema kaymasına izin ver onay kutusunu seçin. Bu ayar, tüm gelen kaynak alanlarının havuza dönüştürmeler arasında akmasını sağlar.
Sürüklenen sütun türlerini çıkar seçeneğinin seçilmesi, hizmete bulunan her yeni sütun için veri türlerini algılamasını ve tanımlamasını sağlar. Bu özellik kapalıyken, tüm sürüklenen sütunlar dize türündedir.
Şemayı doğrulama: Şemayı doğrula seçiliyse, gelen kaynak veriler veri kümesinin tanımlı şemasıyla eşleşmiyorsa veri akışı çalıştırılamaz.
Satır sayısını atla: Satır sayısını atla alanı, veri kümesinin başında kaç satırın yoksayılır olduğunu belirtir.
Örnekleme: Kaynağınızdaki satır sayısını sınırlamak için Örneklemeyi etkinleştirin. Hata ayıklama amacıyla kaynağınızdaki verileri test ederken veya örneklerken bu ayarı kullanın. Bu, veri akışlarını bir işlem hattından hata ayıklama modunda yürütürken çok kullanışlıdır.
Kaynağınızın doğru yapılandırıldığını doğrulamak için hata ayıklama modunu açın ve bir veri önizlemesi getirin. Daha fazla bilgi için bkz . Hata ayıklama modu.
Not
Hata ayıklama modu açıldığında, hata ayıklama ayarlarındaki satır sınırı yapılandırması, veri önizlemesi sırasında kaynaktaki örnekleme ayarının üzerine yazılır.
Kaynak seçenekleri
Kaynak seçenekleri sekmesi, seçilen bağlayıcıya ve biçime özgü ayarları içerir. Daha fazla bilgi ve örnek için ilgili bağlayıcı belgelerine bakın. Buna, onu destekleyen veri kaynakları için yalıtım düzeyi (şirket içi SQL Sunucuları, Azure SQL Veritabanı'ler ve Azure SQL Yönetilen örnekleri gibi) ve diğer veri kaynağına özgü ayarlar gibi ayrıntılar da dahildir.
Yansıtma
Veri kümelerindeki şemalar gibi, bir kaynaktaki projeksiyon da kaynak verilerden veri sütunlarını, türlerini ve biçimlerini tanımlar. SQL ve Parquet gibi çoğu veri kümesi türü için bir kaynaktaki projeksiyon, bir veri kümesinde tanımlanan şemayı yansıtacak şekilde sabittir. Kaynak dosyalarınız kesin olarak yazılmadığında (örneğin, Parquet dosyaları yerine düz .csv dosyaları), kaynak dönüştürmedeki her alan için veri türlerini tanımlayabilirsiniz.
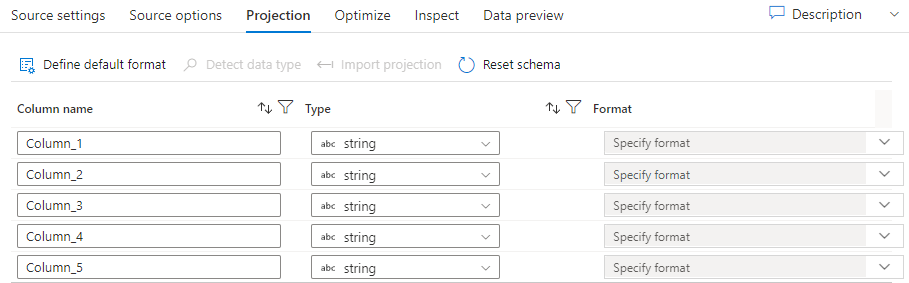
Metin dosyanızda tanımlı şema yoksa, Hizmet örnekleri ve veri türlerini çıkarması için Veri türünü algıla'yı seçin. Varsayılan veri biçimlerini otomatik olarak algılamak için Varsayılan biçimi tanımla'ya tıklayın.
Şemayı sıfırla, projeksiyonu başvuruda bulunan veri kümesinde tanımlanan değere sıfırlar.
Şemanın üzerine yazma, kaynakta öngörülen veri türlerini değiştirmenizi ve şema tanımlı veri türlerinin üzerine yazmanızı sağlar. Alternatif olarak, aşağı akış türetilmiş sütun dönüşümünde sütun veri türlerini değiştirebilirsiniz. Sütun adlarını değiştirmek için bir seçme dönüştürmesi kullanın.
Şemayı içeri aktarma
Şema projeksiyonu oluşturmak için etkin bir hata ayıklama kümesi kullanmak için Projeksiyon sekmesinde şemayı içeri aktar düğmesini seçin. Her kaynak türünde kullanılabilir. Şemanın buraya aktarılması, veri kümesinde tanımlanan projeksiyonu geçersiz kılar. Veri kümesi nesnesi değiştirilmez.
Şemayı içeri aktarmak, veri kümesinde şema tanımlarının olmasını gerektirmeyen karmaşık veri yapılarını destekleyen Avro ve Azure Cosmos DB gibi veri kümelerinde kullanışlıdır. Satır içi veri kümelerinde, şema kaymadan sütun meta verilerine başvurmanın tek yolu şemayı içeri aktarmaktır.
Kaynak dönüştürmeyi iyileştirme
İyileştir sekmesi, her dönüştürme adımında bölüm bilgilerinin düzenlenmesine olanak tanır. Çoğu durumda, geçerli bölümleme iyileştirmelerini bir kaynak için ideal bölümleme yapısı için kullanın.
Azure SQL Veritabanı bir kaynaktan okuyorsanız, özel Kaynak bölümleme büyük olasılıkla verileri en hızlı şekilde okur. Hizmet, veritabanınıza paralel bağlantılar oluşturarak büyük sorguları okur. Bu kaynak bölümleme bir sütunda veya sorgu kullanılarak yapılabilir.
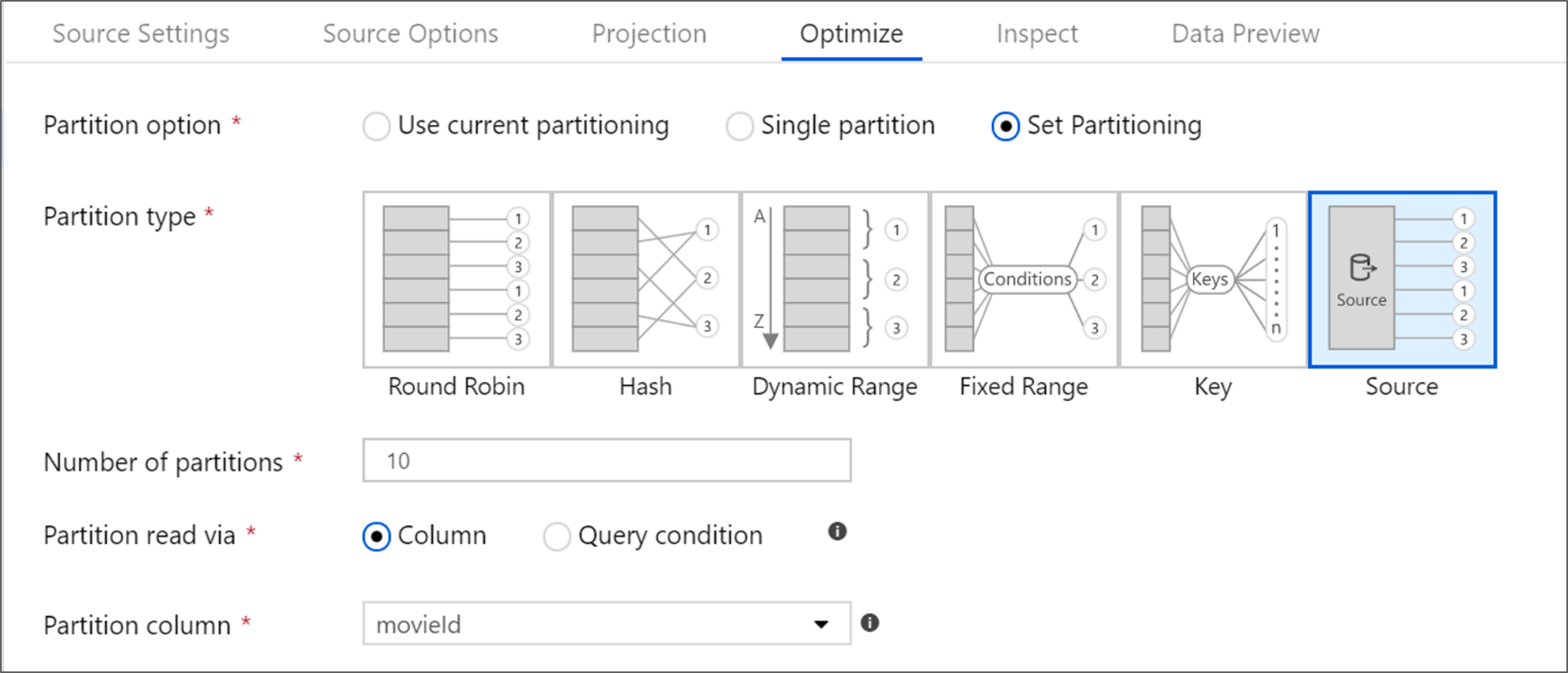
Eşleme veri akışı içinde iyileştirme hakkında daha fazla bilgi için İyileştirme sekmesine bakın.
İlgili içerik
Türetilmiş sütun dönüşümü ve belirli bir dönüştürme ile veri akışınızı oluşturmaya başlayın.