Azure HDInsight'ta Apache Hive yetersiz bellek hatasını düzeltme
Hive bellek ayarlarını yapılandırarak büyük tabloları işlerken Apache Hive bellek yetersiz (OOM) hatasını düzeltmeyi öğrenin.
Büyük tablolarda Apache Hive sorgusu çalıştırma
Müşteri bir Hive sorgusu çalıştırmıştı:
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
Bu sorgunun bazı nüansları:
- T1, çok sayıda STRING sütun türüne sahip olan TABLE1 adlı büyük bir tablonun diğer adıdır.
- Diğer tablolar o kadar büyük değildir, ancak çok fazla sütunu vardır.
- Bazı durumlarda TABLE1 ve diğer tablolarda birden çok sütun içeren tüm tablolar birbirine katılır.
Hive sorgusunun 24 düğüm A3 HDInsight kümesinde bitme süresi 26 dakikadır. Müşteri aşağıdaki uyarı iletilerini fark etti:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
Apache Tez yürütme altyapısını kullanarak. Aynı sorgu 15 dakika boyunca çalıştı ve aşağıdaki hatayı attı:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
Hata, daha büyük bir sanal makine (örneğin, D12) kullanılırken kalır.
Bellek yetersiz hatasında hata ayıklama
Destek ve mühendislik ekiplerimiz birlikte bellek yetersiz hatasına neden olan sorunlardan birinin Apache JIRA'da açıklanan bilinen bir sorun olduğunu buldu:
"Hive.auto.convert.join.noconditionaltask = true olduğunda noconditionaltask.size değerini denetleriz ve harita birleştirmesindeki tablo boyutlarının toplamı noconditionaltask.size değerinden küçükse plan bir Harita birleştirmesi oluşturur, Bununla ilgili sorun, giriş boyutlarının toplamı küçük bir kenar boşluğu sorgularının OOM'a isabet edeceği koşulsuz görev boyutundan küçükse, hesaplamanın farklı HashTable uygulaması tarafından ortaya çıkan ek yükü sonuç olarak hesaba katmamasıdır."
hive-site.xml dosyasındaki hive.auto.convert.join.noconditionaltask true olarak ayarlandı:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
Java Yığın Alanı bellek yetersiz hatasının nedeni büyük olasılıkla harita birleştirmesiydi. HDInsight'taki Hadoop Yarn bellek ayarları blog gönderisinde açıklandığı gibi, Tez yürütme altyapısı kullanıldığında kullanılan yığın alanı aslında Tez kapsayıcısına aittir. Tez kapsayıcı belleğini açıklayan aşağıdaki görüntüye bakın.
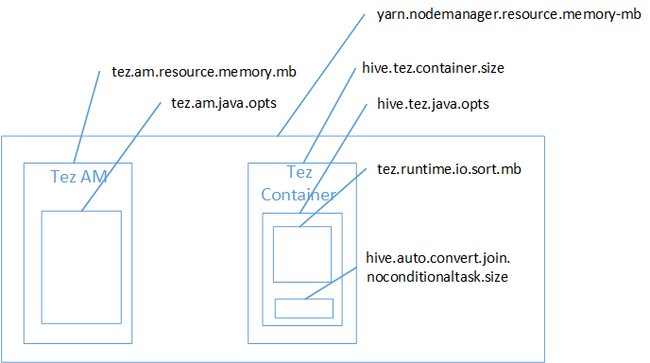
Blog gönderisinde de belirtildiği gibi, aşağıdaki iki bellek ayarı yığın için kapsayıcı belleğini tanımlar: hive.tez.container.size ve hive.tez.java.opts. Deneyimimize göre yetersiz bellek özel durumu, kapsayıcı boyutunun çok küçük olduğu anlamına gelmez. Bu, Java yığın boyutunun (hive.tez.java.opts) çok küçük olduğu anlamına gelir. Bu nedenle, belleğin yetersiz olduğunu gördüğünüzde hive.tez.java.opt'leri artırmayı deneyebilirsiniz. Gerekirse hive.tez.container.size dosyasını artırmanız gerekebilir. java.opts ayarı container.size değerinin yaklaşık %80'i olmalıdır.
Not
hive.tez.java.opts ayarı her zaman hive.tez.container.size değerinden küçük olmalıdır.
D12 makinesinde 28 GB bellek olduğundan 10 GB (10240 MB) kapsayıcı boyutu kullanmaya ve java.opts dosyasına %80 atamaya karar verdik:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
Yeni ayarlarla, sorgu 10 dakikanın altında başarıyla çalıştı.
Sonraki adımlar
OOM hatası almak, kapsayıcı boyutunun çok küçük olduğu anlamına gelmez. Bunun yerine, yığın boyutunun artırılması ve kapsayıcı bellek boyutunun en az %80'i olması için bellek ayarlarını yapılandırmanız gerekir. Hive sorgularını iyileştirmek için bkz . HDInsight'ta Apache Hadoop için Apache Hive sorgularını iyileştirme.