HDInsight üzerinde Apache Spark ile Uygulama Analizler telemetri günlüklerini analiz etme
HdInsight üzerinde Apache Spark kullanarak Application Insight telemetri verilerini analiz etmeyi öğrenin.
Visual Studio Application Analizler, web uygulamalarınızı izleyen bir analiz hizmetidir. Uygulama Analizler tarafından oluşturulan telemetri verileri Azure Depolama'a aktarılabilir. Veriler Azure Depolama'a eklendikten sonra HDInsight, verileri analiz etmek için kullanılabilir.
Önkoşullar
Uygulama Analizler kullanacak şekilde yapılandırılmış bir uygulama.
Linux tabanlı HDInsight kümesi oluşturma hakkında bilgi. Daha fazla bilgi için bkz . HDInsight üzerinde Apache Spark oluşturma.
Bir web tarayıcısı.
Bu belgenin geliştirilmesi ve test edilmesinde aşağıdaki kaynaklar kullanılmıştır:
Uygulama Analizler telemetri verileri, Application Analizler kullanmak üzere yapılandırılmış bir Node.js web uygulaması kullanılarak oluşturuldu.
Verileri analiz etmek için HDInsight kümesi sürüm 3.5 üzerinde Linux tabanlı spark kullanıldı.
Mimari ve planlama
Aşağıdaki diyagramda bu örneğin hizmet mimarisi gösterilmektedir:
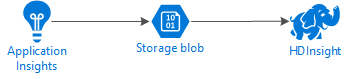
Azure Depolama
Uygulama Analizler, telemetri bilgilerini sürekli olarak bloblara aktaracak şekilde yapılandırılabilir. HDInsight daha sonra bloblarda depolanan verileri okuyabilir. Ancak, uymanız gereken bazı gereksinimler vardır:
Konum: Depolama Hesabı ve HDInsight farklı konumlardaysa gecikme süresini artırabilir. Ayrıca, bölgeler arasında hareket eden verilere çıkış ücretleri uygulandığı için maliyeti de artırır.
Uyarı
HDInsight'tan farklı bir konumda Depolama Hesabı kullanılması desteklenmez.
Blob türü: HDInsight yalnızca blok bloblarını destekler. Uygulama Analizler varsayılan olarak blok bloblarını kullanır, bu nedenle HDInsight ile varsayılan olarak çalışmalıdır.
Var olan bir kümeye depolama alanı ekleme hakkında bilgi için Ek depolama hesapları ekleme belgesine bakın.
Veri şeması
Uygulama Analizler, bloblara aktarılan telemetri veri biçimi için dışarı aktarma veri modeli bilgileri sağlar. Bu belgedeki adımlarda verilerle çalışmak için Spark SQL kullanılır. Spark SQL, Application Analizler tarafından günlüğe kaydedilen JSON veri yapısı için otomatik olarak bir şema oluşturabilir.
Telemetri verilerini dışarı aktarma
Telemetri bilgilerini Bir Azure Depolama blob'unda dışarı aktarmak üzere Uygulama Analizler yapılandırmak için Sürekli Dışarı Aktarmayı Yapılandırma başlığındaki adımları izleyin.
HDInsight'ı verilere erişecek şekilde yapılandırma
HDInsight kümesi oluşturuyorsanız, küme oluşturma sırasında depolama hesabını ekleyin.
Azure Depolama Hesabını mevcut bir kümeye eklemek için Ek Depolama Hesapları ekle belgesindeki bilgileri kullanın.
Verileri analiz etme: PySpark
Web tarayıcısından CLUSTERNAME'in kümenizin adı olduğu yere gidin
https://CLUSTERNAME.azurehdinsight.net/jupyter.Jupyter sayfasının sağ üst köşesinde Yeni'yi ve ardından PySpark'ı seçin. Python tabanlı Jupyter Notebook içeren yeni bir tarayıcı sekmesi açılır.
Sayfadaki ilk alana (hücre olarak adlandırılır) aşağıdaki metni girin:
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')Bu kod Spark'ı giriş verilerinin dizin yapısına özyinelemeli olarak erişecek şekilde yapılandırır. Uygulama Analizler telemetrisi, benzeri bir dizin yapısına
/{telemetry type}/YYYY-MM-DD/{##}/kaydedilir.Kodu çalıştırmak için SHIFT+ENTER tuşlarını kullanın. Hücrenin sol tarafında köşeli ayraçlar arasında bu hücredeki kodun yürütülmekte olduğunu belirten bir '*' görüntülenir. İşlem tamamlandıktan sonra '*' bir sayıya dönüşür ve hücrenin altında aşağıdaki metne benzer bir çıkış görüntülenir:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...İlk hücrenin altında yeni bir hücre oluşturulur. Yeni hücreye aşağıdaki metni girin. ve
STORAGEACCOUNTdeğerini Application Analizler verilerini içeren Azure Depolama hesap adı ve blob kapsayıcı adıyla değiştirinCONTAINER.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Bu hücreyi yürütmek için SHIFT+ENTER tuşlarını kullanın. Aşağıdaki metne benzer bir sonuç görürsünüz:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Döndürülen wasbs yolu, Uygulama Analizler telemetri verilerinin konumudur.
hdfs dfs -lsDöndürülen wasbs yolunu kullanmak için hücredeki satırı değiştirin ve sonra hücreyi yeniden çalıştırmak için SHIFT+ENTER tuşlarını kullanın. Bu kez, sonuçlar telemetri verilerini içeren dizinleri görüntülemelidir.Not
Bu bölümdeki
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requestsadımların geri kalanında dizin kullanılmıştır. Dizin yapınız farklı olabilir.Sonraki hücreye şu kodu girin: değerini önceki adımdaki yol ile değiştirin
WASB_PATH.jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)Bu kod, sürekli dışarı aktarma işlemi tarafından dışarı aktarılan JSON dosyalarından bir veri çerçevesi oluşturur. Bu hücreyi çalıştırmak için SHIFT+ENTER tuşlarını kullanın.
Sonraki hücreye aşağıdakileri girerek Spark'ın JSON dosyaları için oluşturduğu şemayı görüntüleyin:
jsonData.printSchema()Her telemetri türü için şema farklıdır. Aşağıdaki örnek, web istekleri için oluşturulan şemadır (alt dizinde
Requestsdepolanan veriler):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Veri çerçevesini geçici bir tablo olarak kaydetmek ve verilere karşı bir sorgu çalıştırmak için aşağıdakileri kullanın:
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()Bu sorgu, context.location.city dosyasının null olmadığı ilk 20 kaydın şehir bilgilerini döndürür.
Not
Bağlam yapısı, Uygulama Analizler tarafından günlüğe kaydedilen tüm telemetrilerde bulunur. Şehir öğesi günlüklerinizde doldurulamayabilir. Günlükleriniz için veri içerebilecek sorgulayabileceğiniz diğer öğeleri tanımlamak için şemayı kullanın.
Bu sorgu aşağıdaki metne benzer bilgiler döndürür:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Verileri analiz etme: Scala
Web tarayıcısından CLUSTERNAME'in kümenizin adı olduğu yere gidin
https://CLUSTERNAME.azurehdinsight.net/jupyter.Jupyter sayfasının sağ üst köşesinde Yeni'yi ve ardından Scala'yı seçin. Scala tabanlı Jupyter Notebook içeren yeni bir tarayıcı sekmesi görüntülenir.
Sayfadaki ilk alana (hücre olarak adlandırılır) aşağıdaki metni girin:
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")Bu kod Spark'ı giriş verilerinin dizin yapısına özyinelemeli olarak erişecek şekilde yapılandırır. Uygulama Analizler telemetrisi, benzeri bir dizin yapısına
/{telemetry type}/YYYY-MM-DD/{##}/kaydedilir.Kodu çalıştırmak için SHIFT+ENTER tuşlarını kullanın. Hücrenin sol tarafında köşeli ayraçlar arasında bu hücredeki kodun yürütülmekte olduğunu belirten bir '*' görüntülenir. İşlem tamamlandıktan sonra '*' bir sayıya dönüşür ve hücrenin altında aşağıdaki metne benzer bir çıkış görüntülenir:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...İlk hücrenin altında yeni bir hücre oluşturulur. Yeni hücreye aşağıdaki metni girin. ve
STORAGEACCOUNTdeğerini Application Analizler günlüklerini içeren Azure Depolama hesap adı ve blob kapsayıcı adıyla değiştirinCONTAINER.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Bu hücreyi yürütmek için SHIFT+ENTER tuşlarını kullanın. Aşağıdaki metne benzer bir sonuç görürsünüz:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Döndürülen wasbs yolu, Uygulama Analizler telemetri verilerinin konumudur.
hdfs dfs -lsDöndürülen wasbs yolunu kullanmak için hücredeki satırı değiştirin ve sonra hücreyi yeniden çalıştırmak için SHIFT+ENTER tuşlarını kullanın. Bu kez, sonuçlar telemetri verilerini içeren dizinleri görüntülemelidir.Not
Bu bölümdeki
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requestsadımların geri kalanında dizin kullanılmıştır. Telemetri verileriniz bir web uygulamasına ait olmadığı sürece bu dizin mevcut olmayabilir.Sonraki hücreye şu kodu girin: değerini önceki adımdaki yol ile değiştirin
WASB\_PATH.var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)Bu kod, sürekli dışarı aktarma işlemi tarafından dışarı aktarılan JSON dosyalarından bir veri çerçevesi oluşturur. Bu hücreyi çalıştırmak için SHIFT+ENTER tuşlarını kullanın.
Sonraki hücreye aşağıdakileri girerek Spark'ın JSON dosyaları için oluşturduğu şemayı görüntüleyin:
jsonData.printSchemaHer telemetri türü için şema farklıdır. Aşağıdaki örnek, web istekleri için oluşturulan şemadır (alt dizinde
Requestsdepolanan veriler):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Veri çerçevesini geçici bir tablo olarak kaydetmek ve verilere karşı bir sorgu çalıştırmak için aşağıdakileri kullanın:
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()Bu sorgu, context.location.city dosyasının null olmadığı ilk 20 kaydın şehir bilgilerini döndürür.
Not
Bağlam yapısı, Uygulama Analizler tarafından günlüğe kaydedilen tüm telemetrilerde bulunur. Şehir öğesi günlüklerinizde doldurulamayabilir. Günlükleriniz için veri içerebilecek sorgulayabileceğiniz diğer öğeleri tanımlamak için şemayı kullanın.
Bu sorgu aşağıdaki metne benzer bilgiler döndürür:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Sonraki adımlar
Azure'daki veri ve hizmetlerle çalışmak için Apache Spark kullanma hakkında daha fazla örnek için aşağıdaki belgelere bakın:
- BI ile Apache Spark: BI araçlarıyla HDInsight'ta Spark kullanarak etkileşimli veri analizi gerçekleştirme
- Machine Learning ile Apache Spark: HVAC verilerini kullanarak bina sıcaklığını analiz etmek için HDInsight'ta Spark kullanma
- Machine Learning ile Apache Spark: Gıda denetimi sonuçlarını tahmin etmek için HDInsight'ta Spark kullanma
- HDInsight'ta Apache Spark kullanarak web sitesi günlük analizi
Spark uygulamaları oluşturma ve çalıştırma hakkında bilgi için aşağıdaki belgelere bakın: